Oracle 重做日志(Redo Log)详解
1

Redo Log 特征
- 记录数据库的变化(DML、DDL)
- 用于数据块的 recovery
- 以组的方式管理 redo file ,最少两组 redo ,循环使用
- 和数据文件存放到不同的磁盘上,需读写速度快的磁盘(否则会成为瓶颈)
日志恢复不会用到 INACTIVE 的信息,会用到 CURRENT 的信息,若有处于 ACTIVE 的日志,也会用到ACTIVE的信息。
日志切换
- 归档模式:将历史日志连续的进行保存。
- 非归档: 历史日志被覆盖
- 产生 checkpoint,通知 redo log 所对应的 dirty block 从 data buffer 写入到 datafile,并且更新控制文件
Redo 日志组
最少两组,最好每组有两个成员,并存放到不同的磁盘上,大小相同,互相镜像- 日志在组写满时发生切换,或手工切换: alter system switch logfile ;
- 在归档模式下,日志进行归档,并把相关的信息写入 controlfile
添加日志组
- 查看当前Redo Log 的信息
SQL> select group#, member from v$logfile;
GROUP# MEMBER
---------- --------------------------------------------------
2 /oradata/test/redo02.log
1 /oradata/test/redo01.log
3 /oradata/test/redo03.log
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME
---------- ---------- ---------- ---------- ---------- --- ---------------- ----
1 1 75367 157286400 1 NO INACTIVE 345301777 21-2 月 -12
2 1 75368 157286400 1 NO CURRENT 345347523 21-2 月 -12
3 1 75366 157286400 1 NO INACTIVE 345239280 21-2 月 -12
status 有四种状态:
- UNUSED: 新添加的日志组,还没有使用 ;
- INACTIVE: 日志组对应的脏块已经从 data buffer 写入到 data file ,可以覆盖 ;
- ACTIVE: 日志组对应的脏块还没有从 data buffer 写入到 data file,不能被覆盖 ;
- CURRENT: 当前日志组,日志组对应的脏块还没有从 data buffer 写入到 data file,不能被覆盖 ;
- THREAD: 线程(通过后台进程 lgwr 启动),在单实例的环境下,thread# 永远是 1 ;
- SEQUENCE: 日志序列号。在日志切换时会递增 ;
- FIRST_CHANGE#: 在当前日志中记录的首个数据块的 scn。(当事务完成的时候会在数据块上写入一个 scn,代表数据块的变化)。
- 增加一个组: group4
SQL> alter database add logfile '/oradata/test/redo04.log' size 50m; //注意新添加的文件大小需和其他几个文件保持一致
- 查看添加日志组后Redo Log 的信息
SQL> select group#, member from v$logfile order by group#;
GROUP# MEMBER
---------- --------------------------------------------------
2 /oradata/test/redo02.log
1 /oradata/test/redo01.log
3 /oradata/test/redo03.log
4 /oradata/test/redo04.log
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME
---------- ---------- ---------- ---------- ---------- --- ---------------- ----
1 1 75367 157286400 1 NO INACTIVE 345301777 21-2 月 -12
2 1 75368 157286400 1 NO CURRENT 345347523 21-2 月 -12
3 1 75366 157286400 1 NO INACTIVE 345239280 21-2 月 -12
4 1 0 157286400 1 NO UNUSED 0
新参加的日志组的状态为 UNUSED,说明还未被使用过。
添加日志组成员
现为每个日志组添加一个成员( member )
- 创建目录
$ mkdir -p /data/test/Redo
- 添加成员
SQL> alter database add logfile member
'/data/test/Redo/redo01b.log' to group 1,
'/data/test/Redo/redo02b.log' to group 2,
'/data/test/Redo/redo03b.log' to group 3,
'/data/test/Redo/redo04b.log' to group 4;
- 查询 v$logfile 视图信息
SQL> select group#,member,status from v$logfile;
GROUP# MEMBER STATUS
---------- --------------------------------------------------
3 /oradata/test/redo03.log
2 /oradata/test/redo02.log
1 /oradata/test/redo01.log
4 /oradata/test/redo04.log
1 /data/test/Redo/redo01b.log INVALID
2 /data/test/Redo/redo02b.log INVALID
3 /data/test/Redo/redo03b.log INVALID
4 /data/test/Redo/redo04b.log INVALID //INVALID 表示尚未同步
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME
---------- ---------- ---------- ---------- ---------- --- ---------------- ----
1 1 75367 157286400 2 NO INACTIVE 345301777 21-2 月 -12
2 1 75368 157286400 2 NO CURRENT 345347523 21-2 月 -12
3 1 75366 157286400 2 NO INACTIVE 345239280 21-2 月 -12
4 1 0 157286400 2 NO UNUSED 0
此时 MEMBERS 值为 2
SQL> alter system switch logfile; //多做几次切换,消除 INVALID (同步组里的 member,这步很重要)
- 同步完成后再次查询 v$logfile 视图信息
SQL> select group#,member,status from v$logfile;
GROUP# MEMBER STATUS
---------- --------------------------------------------------
3 /oradata/test/redo03.log
2 /oradata/test/redo02.log
1 /oradata/test/redo01.log
4 /oradata/test/redo04.log
1 /data/test/Redo/redo01b.log
2 /data/test/Redo/redo02b.log
3 /data/test/Redo/redo03b.log
4 /data/test/Redo/redo04b.log
INVALID 已消除,说明同步完成。
日志恢复
场景1:多元化成员中,单个 INACTIVE 成员丢失
场景模拟
- 查询 v$log 视图信息
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME
---------- ---------- ---------- ---------- ---------- --- ---------------- ----
1 1 75367 157286400 1 NO INACTIVE 345301777 21-2 月 -12
2 1 75368 157286400 1 NO CURRENT 345347523 21-2 月 -12
3 1 75366 157286400 1 NO INACTIVE 345239280 21-2 月 -12
4 1 75369 157286400 1 NO INACTIVE 345391243 21-2 月 -12
- 模拟单个 INACTIVE 成员丢失
$ rm /data/test/Redo/redo01b.log
删除文件后,最好不要切换日志,否则容易出问题。
问题处理过程中,最好不要重启数据库!!!
- 再次查询 v$log 视图信息
SQL> select * from v$log;
GROUP# THREAD# SEQUENCE# BYTES MEMBERS ARC STATUS FIRST_CHANGE# FIRST_TIME
---------- ---------- ---------- ---------- ---------- --- ---------------- ----
1 1 75367 157286400 1 NO INACTIVE 345301777 21-2 月 -12
2 1 75368 157286400 1 NO CURRENT 345347523 21-2 月 -12
3 1 75366 157286400 1 NO INACTIVE 345239280 21-2 月 -12
4 1 75369 157286400 1 NO INACTIVE 345391243 21-2 月 -12
OS 中删除文件后, 视图 v$log 中不会立刻体现出来。即使重启数据库,也未必能看出来。
- 查询 v$logfile 视图信息
SQL> select group#,member,status from v$logfile order by member;
GROUP# MEMBER STATUS
---------- --------------------------------------------------
3 /oradata/test/redo03.log
2 /oradata/test/redo02.log
1 /oradata/test/redo01.log
4 /oradata/test/redo04.log
1 /data/test/Redo/redo01b.log INVALID //表明该文本不可访问
2 /data/test/Redo/redo02b.log
3 /data/test/Redo/redo03b.log
4 /data/test/Redo/redo04b.log
重启数据库后 v$logfile 视图信息会更新
处理方法
- 在 open 状态下,把另一个 member 文件 copy 至损坏文件的位置。
$ cp /oradata/test/redo01.log /data/test/Redo/redo01b.log
- 切换日志
SQL> alter system switch logfile;
- 查询 v$logfile 视图信息
SQL> select group#,member,status from v$logfile order by member;
GROUP# MEMBER STATUS
---------- --------------------------------------------------
3 /oradata/test/redo03.log
2 /oradata/test/redo02.log
1 /oradata/test/redo01.log
4 /oradata/test/redo04.log
1 /data/test/Redo/redo01b.log //INACTIVE被消除
2 /data/test/Redo/redo02b.log
3 /data/test/Redo/redo03b.log
4 /data/test/Redo/redo04b.log
场景2:某一非当前日志组所有成员丢失
场景模拟
- 在 OS 删除 group 4 的两个 member
$ rm /oradata/test/redo04.log
$ rm /data/test/Redo/redo04b.log
删除文件后,最好不要切换日志,否则容易出问题。
处理方法
- 若实例没有崩溃,使用 clear 命令重建 group 4
SQL> alter database clear logfile group 4; //重建刚才OS里删掉的两个文件
重建后,最好手动切换几下日志,让它们都用上。
场景3:CURRENT 日志组损坏
场景模拟
- 模拟数据库open状态下,CURRENT日志组group2损坏。
$ rm /oradata/test/redo02.log
$ rm /data/test/Redo/redo02b.log
SQL> alter system switch logfile; 切换几次触动它
告警日志会记录有关信息 ,暂时好像没有什么问题发生。继续切换,当 CURRENT 又转回到 group2 时,死机!
此时,其他 session 可以连上,但是做不了操作。
处理方法
1)如果数据库是 archived 的,因当前日志损坏无法归档,数据库可能挂起但没有崩溃。
- 尝试在数据库open 状态下做强制消除
SQL> alter database clear unarchived logfile group 2; //当前日志不归档了,然后clear命令重建group 1
数据库此时为打开状态,这步若能成功,一定要做一个新的数据库全备。因为当前日志没有归档,归档日志 sequence 已无法保持连续性。
2)如果数据库已经崩溃,准备做传统的基于日志的不完全恢复或闪回数据库。
SQL> recover database until cancel;
SQL> alter database open resetlogs;
3)以上方法都不能 resetlogs 打开数据库
- 修改 pfile 文件,第一行添加_allow_resetlogs_corruption=TRUE
该 参 数 的 含 义 是 : 允 许 在 破 坏 一 致 性 的 情 况 下 强 制 重 置 日 志 , 打 开 数 据 库 。
_allow_resetlogs_corruption 将使用所有数据文件最旧的 SCN 打开数据库,所以通常来讲需要保证 SYSTEM 表空间拥有最旧的 SCN。在强制打开数据库之后,可能因为各种原因会有ora-600 错误。
$ vi inittest11g.ora
_allow_resetlogs_corruption=TRUE
*.audit_file_dest='/u01/admin/timran11g/adump'
*.audit_trail='db'
*.compatible='11.1.0.0.0'
- 以 pfile 启动 instance 到 mount 状态,执行命令
alter database open resetlogs
这是在不一致状态下强行打开了数据库,建议处理完后做一个逻辑全备。
场景4:ACTIVE 日志组损坏
场景模拟
- 假设此时group 3处于 ACTIVE状态,在 OS 删除 group 3 的两个 member
$ rm /oradata/test/redo03.log
$ rm /data/test/Redo/redo03b.log
处理方法
- 先做做一个完全检查点,将 db buffer 中的所有 dirty buffer 全部刷新到磁盘上。
SQL> alter system checkpoint;
如果状态转为 INACTIVE 了,则使用 clear 命令重建 group 3
SQL> alter database clear logfile group 3; //重建group 3
重建后,最好手动切换几下日志,让它们都用上。
如果 halt 了,尝试在数据库open 状态下做强制消除
SQL> alter database clear unarchived logfile group 3;
数据库此时为打开状态,这步若能成功,一定要做一个新的数据库全备。因为当前日志没有归档,归档日志 sequence 已无法保持连续性。
补充知识:
Restore 和 Recovery 的区别
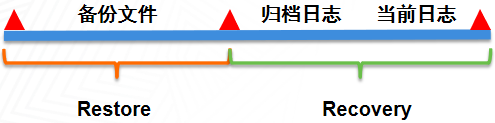
- Restore(还原):备份的逆操作,是静态的,还原到备份时间点的数据,不会用到日志。
- Recovery(恢复):从Restore 还原的位置前滚,可还原到最后一次提交的事务,会用到日志(先用归档日志还原,然后再用当前日志往前滚)。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)