sql语句的执行顺序以及流程(最新,最全,直接用)
熟练掌握sql语句的执行顺序,才能避免编程中各种bug和错误。
·
熟练掌握sql语句的执行顺序,才能避免编程中各种bug和错误。
文章目录
一、Select 语句完整的执行顺序
1、from 子句组装来自不同数据源的数据+(ON过滤器)或(JOIN 添加外部行);
FROM子句执行顺序为从后往前、从右到左。+(ON过滤器)或(JOIN 添加外部行)
2、where 子句基于指定的条件对记录行进行筛选;
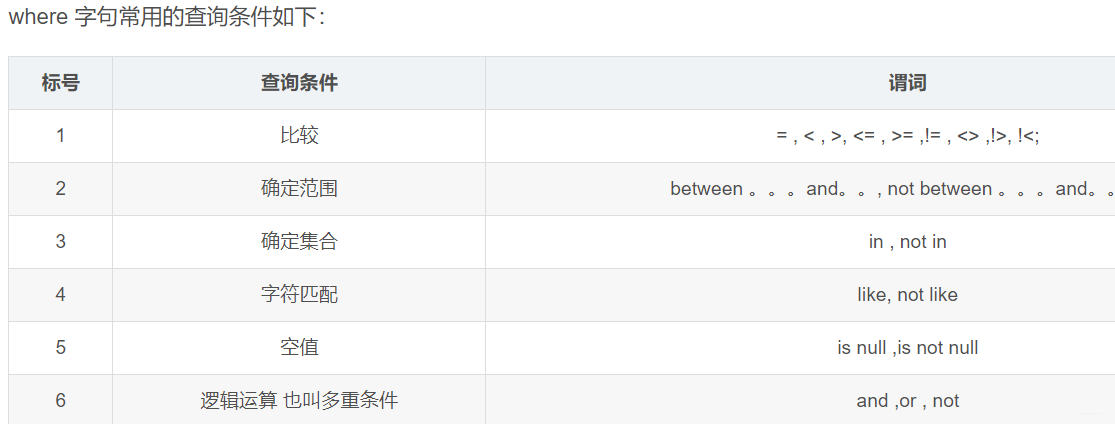
具体用法:
1.between后面是下限,and 后面是上限
--查询Sage 在30-100之间的所有数据
select Sname name ,Sage age from student where Sage between 30 and 1000;
2.in() 括号内是个自定义集合 还可以是结果集
select * from student where Sex in(‘男’,’女’);
3.like用法
select * from student where Sname = ‘xyd’;
--等同
select * from student where Sname like ‘xyd’;
--数据库字符集是ASCII 码字符集 一个汉字用两个_ 如果是gbk 就用一个
select * from student where Sname like ‘x_d’;
--极端情况,查询的内容本身就含有%的字段,如'xy%d'
select * from student where Sname like 'xy%%d' escape '/';
--这样我们定义的转义字符后面的% 或者_ 就不再有通配符的含义了 而是仅仅代表他们本身
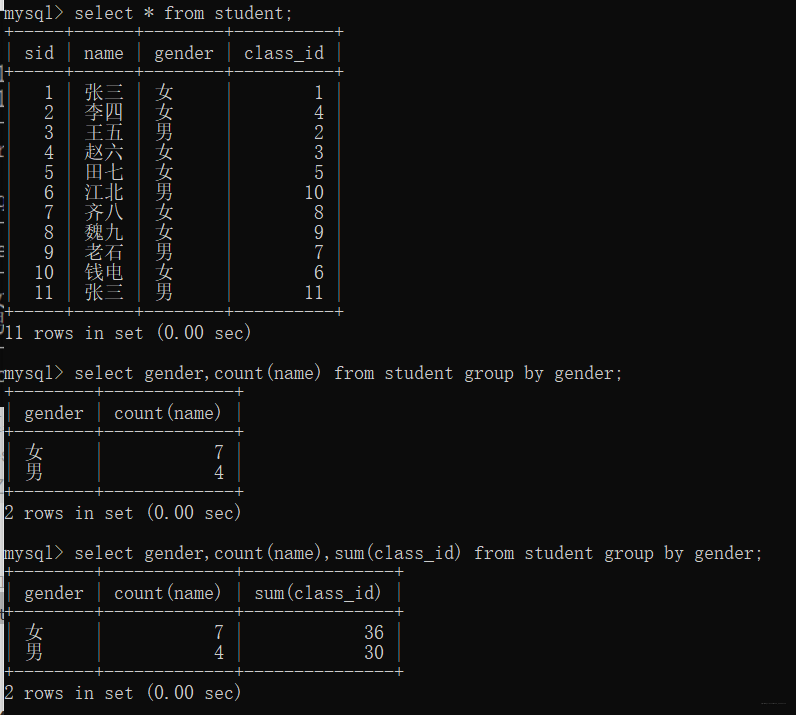
3、group by 子句将数据划分为多个分组;
把结果集按照某一列或者多列进行分组(值相等的一组)
select gender,count(name) from student group by gender;
select gender,count(name),sum(class_id) from student group by gender;
4、使用聚集函数进行计算;
注意:
1.聚集函数只能出现在select 后面或者 having 后面。不能放到WHERE子句中。
2.当聚集函数遇见空值的时候,除了count() 外 其余都跳过不进行处理* 。

select avg(Sage) from student where Sdept like ‘计算机%’;
5、使用 having 子句筛选分组;
如果分组后还要进行筛选 那么就需要having语句(有having,必须有group by)
select gender,count(name),sum(class_id) from student group by gender having gender= '女';

6、计算所有的表达式;
7、select 的字段+(DISTINCT去重);
也包括DISTINCT 去重,窗口函数是 SELECT 语句里,而 SELECT 是在 WHERE 和 GROUP BY 之后。
8、UNION连接的两个SELECT查询语句
UNION连接的两个SELECT查询语句,会重复执行步骤1~7,产生两个虚拟表1,UNION会将这些记录合并到新的虚拟表2中。
9、使用 order by 对结果集进行排序。
select * from student order by Sage asc; 查询结果按 Sage的结果升序排列
select * from student order by Sage desc;查询结果按 Sage的结果降序排列
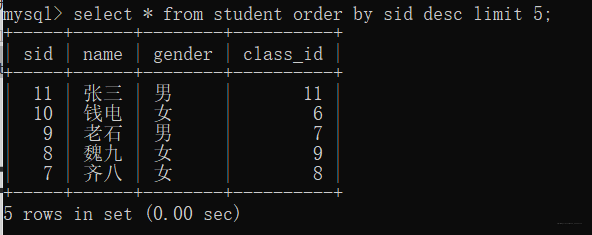
10、Limit
以sid升序排序,显示前5行
select * from student order by sid desc limit 5;
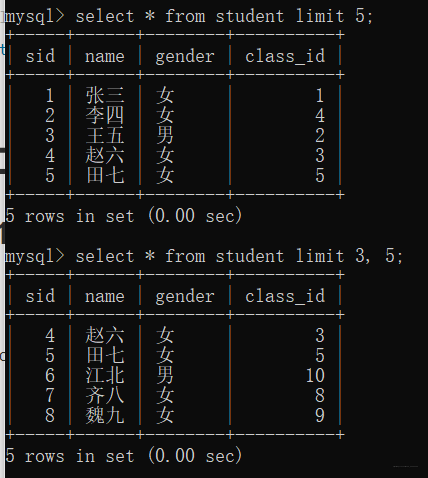
(也可不用order by),跳过第三行显示,前五行
select * from student limit 3, 5;
觉得可以的话,点个赞呗,收藏一下也行

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)