Oracle | awr报告分析
awr报告分析awr报告简介awr基本信息Main Report:Oracle重要运维情况指标awr报告简介awr报告大致分为四个部分基本信息,包含数据库实例、版本、是否rac、设备信息、cpu核数、awr报告采集时间、该时间段内时间消耗情况等。Main Report,分多个数据库指标,包括sql运行情况、缓冲池运行情况、io、undo等详细信息,是分析oracle运行情况最常用的部分Rac St
awr报告简介
awr报告大致分为四个部分
- 基本信息,包含数据库实例、版本、是否rac、设备信息、cpu核数、awr报告采集时间、该时间段内时间消耗情况等。
- Main Report,分多个数据库指标,包括sql运行情况、缓冲池运行情况、io、undo等详细信息,是分析oracle运行情况最常用的部分
- Rac Statistics,主要是rac集群的指标
- Wait Events Statistics,监控进程等待时间等。
awr基本信息

如图,awr基本信息中最重要就是Elapsed和DB Time的比较,其中Elapsed就是当前awr报告的时间段,DB Time则是多个CPU的DB总运行时间,因此只要Elapsed大于CPU*DB Time,就可以认为当前数据库负载没那么高。
DB运行时间占总数百分比=DB Time/CPU个数/Elapsed*%.
Main Report:Oracle重要运维情况指标
-
下面列出最常用到的几个指标:
- 1、Report Summary当前数据库运维情况总概况,如前文,此处略。
-
2、Load Profile
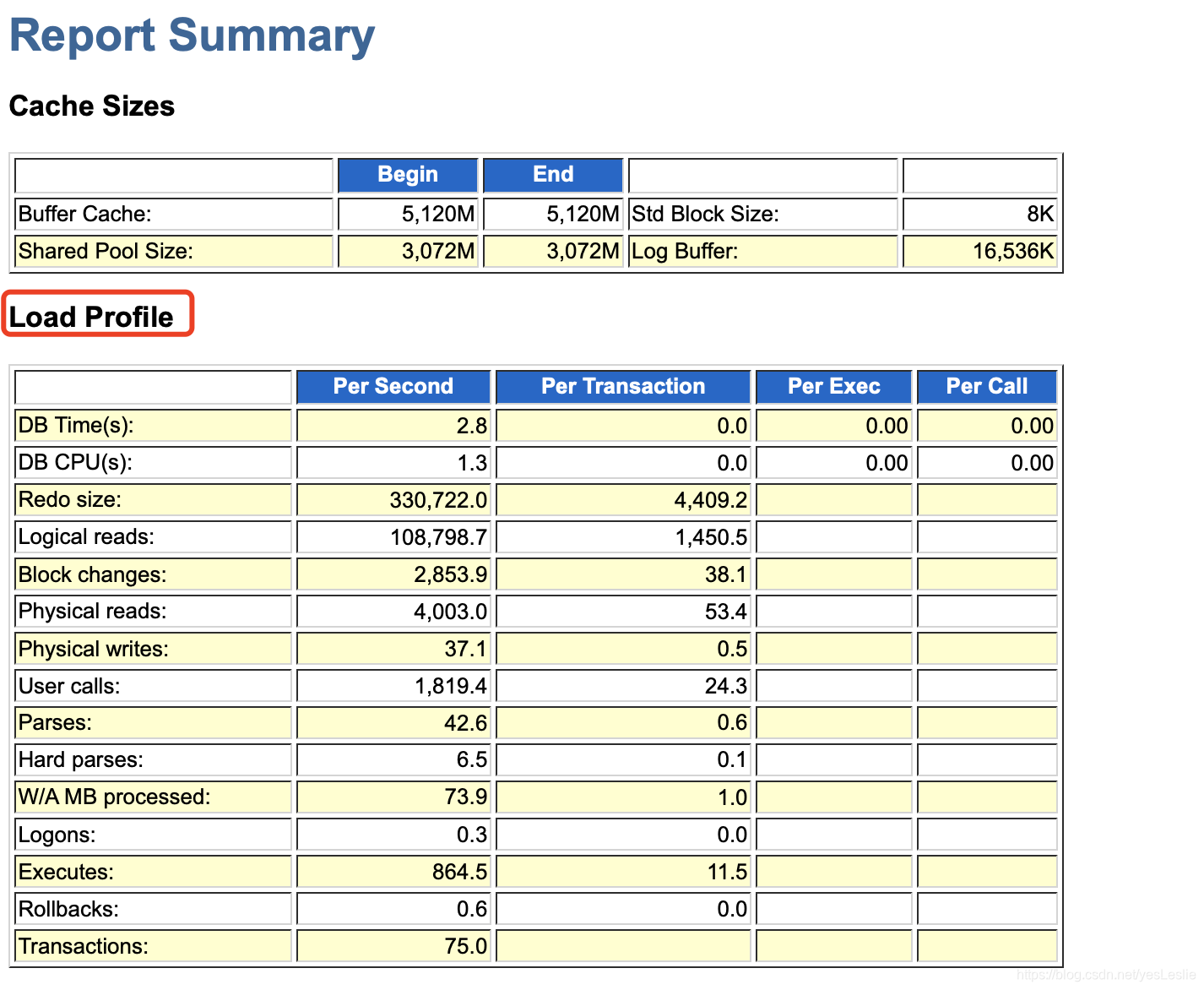
- Redo Size:每秒产生的日志大小,单位字节,可表示数据变更的频率,数据库是否繁忙。
- Logical reads:逻辑读耗CPU,主频和CPU都很重要,逻辑读高一般DB CPU也高,往往会看到 latch:cache buffer chains 等待。
- Physical reads:物理读耗IO,物理读少的话可能消耗逻辑读高。
- Parses:数据库所有解析,包括fast parse,soft parse,hard parse。
- Hard Pases:硬解析。
注:数据库解析sql步骤:
1、将该语句转化成ASCII等效数字码
2、将ASCII等效数字码传递给一个散列算法,由该散列算法产生一个单独的散列
3、搜索当前用户的session缓存中(在PGA中)是否存在相同的散列版本,如果存在,就直接执行该语句。这就是fast parse。
4、如果在PGA中没有命中,查找其他的session中是否有相同的散列,这就需要到共享池的库缓存中对查找。如果在库缓存中找到相同的散列。这就是soft parse。
5、若在3和4中都没有找到相同散列,用户进程进行语法检查过程(Syntax Check)。语法检查主要时检查语法是否符合SQL Reference Manual中给出的SQL语法。
6、语法检查通过之后,再进行语义分析过程(Semantic Analysis)。这个过程就是检查对象的合法性。检查表是否存在,列是否存在,是否有权限访问等等。
7、选择执行计划。准备从可用的执行计划中选择一个执行计划,其中包括存储大纲(srored outline)或物化视图(materialized view)相关的决定。
8、生成该语句的一个编译代码(p-code)。这完整的整个步骤就是hard parse。
-
/
-
3、Instance Efficiency Percentages
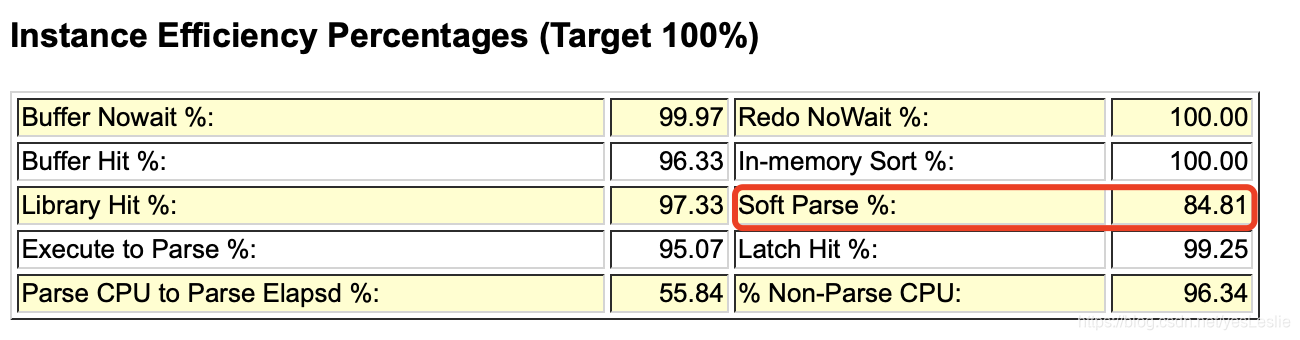
一些命中率指标:- Buffer Nowait:表示在内存获得数据的未等待比例,理想状态是100%,如低于99%,则表示数据库可能存在资源争用情况。
- Buffer Hit:表示进程从内存块中获得数据的比例。
- Library Hit:如上文,软解析就是从库缓冲中获取到sql执行计划,这个比例太低会导致硬解析过多。
- Execute to Parse:是语句执行与分析的比例,如果要SQL重用率高,则这个比例会很高。该值越高表示一次解析后被重复执行的次数越多。
- Parse CPU to Parse Elapsed:解析实际运行时间/(解析实际运行时间+解析中等待资源时间),越高越好。如果该比率为100%,意味着CPU等待时间为0,没有任何等待。
- Redo Nowait:在log缓冲区中不等待比例。
- In-Memory Sort:在内存中排序的比率,如果过低说明有大量的排序在临时表空间中进行。考虑调大PGA(10g)。如果低于95%,可以通过适当调大初始化参数PGA_AGGREGATE_TARGET或者SORT_AREA_SIZE来解决,注意这两个参数设置作用的范围时不同的,SORT_AREA_SIZE是针对每个session设置的,PGA_AGGREGATE_TARGET则时针对所有的sesion的。
- Soft Parse:软解析的百分比(Softs/Softs+Hards),近似当作sql在共享区的命中率,太低则需要调整应用使用绑定变量。sql在共享区的命中率,小于<95%,需要考虑绑定,如果低于80%,那么就可以认为sql基本没有被重用。
- Latch Hit:Latch是一种保护内存结构的锁,可以认为是Server进程获取访问内存数据结构的许可。要确保Latch Hit>99%,否则意味着Shared Pool latch争用,可能由于未共享的SQL,或者Library Cache太小,可使用绑定变更或调大Shared Pool解决。要确保>99%,否则存在严重的性能问题。当该值出现问题的时候,我们可以借助后面的等待时间和latch分析来查找解决问题。
- Non-Parse CPU:SQL实际运行时间/(SQL实际运行时间+SQL解析时间),太低表示解析消耗时间过多。如果这个值比较小,表示解析消耗的CPU时间过多。
-
4、Top 10 Foreground Events by Total Wait Time
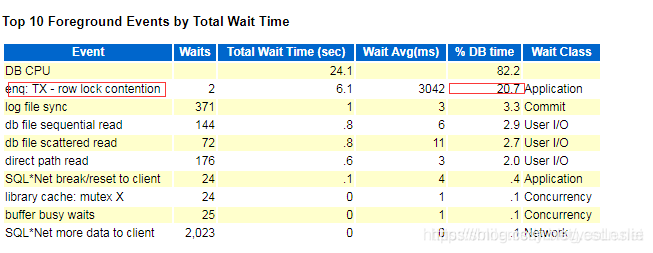
几个常见的top事件:- db file scattered read:文件散列读取等待即多块读等待事件是当SESSION等待multi-block I/O时发生的,通常是由于full table scans或index fast full scans引起,Avg wait>20ms就要注意了,db file scattered read 异常大,可能是由于全表扫描引起
该事件通常与全表扫描或者index fast full scan有关。因为全表扫描是被放入内存中进行的,通常情况下基于性能的考虑,有时候也可能是分配不到足够长的连续内存空间,所以会将数据块分散(scattered)读入Buffer Cache中。该等待过大可能是缺少索引或者没有合适的索引(可以调整optimizer_index_cost_adj) 。这种情况也可能是正常的,因为执行全表扫描可能比索引扫描效率更高。当系统存在这些等待时,需要通过检查来确定全表扫描是否必需的来调整。因为全表扫描被置于LRU(Least Recently Used,最近最少适用)列表的冷端(cold end),对于频繁访问的较小的数据表,可以选择把他们Cache 到内存中,以避免反复读取。当这个等待事件比较显著时,可以结合v$session_longops 动态性能视图来进行诊断,该视图中记录了长时间(运行时间超过6 秒的)运行的事物
- DB file sequential read:单块读等待意味着发生顺序I/O读等待,如果这个等待严重,则应该对大表进行分区以减少I/O量,或者优化执行计划(通过使用存储大纲或执行数据分析)以避免单块读操作引起的sequential read等待,通常由于INDEX FULL SCAN/UNIQUE SCAN 、INDEX RANGE SCAN、行迁移或行链接引起,Avg wait>20ms就要注意了。
这里的sequential指的是将数据块读入到相连的内存空间中(contiguous memory space),而不是指所读取的数据块是连续的。
1、最为常见的是执行计划中包含了INDEX FULL SCAN/UNIQUE SCAN,此时出现”db file sequential read”等待是预料之中的
3、当执行计划包含了INDEX RANGE SCAN-(“TABLE ACCESS BY INDEX ROWID”/”DELETE”/”UPDATE”), 服务进程将按照”访问索引->找到rowid->访问rowid指定的表数据块并执行必要的操作”顺序访问index和table,每次物理读取都会进入”db file sequential read”等待,且每次读取的都是一个数据块;这种情况下clustering_factor将发挥其作用(ALL_INDEXES的CLUSTERING_FACTOR*值来判断数据的离散程度)
3、Extent boundary,假设一个Extent区间中有33个数据块,而一次”db file scattered read”多块读所读取的块数为8,那么在读取这个区间时经过4次多块读取后,还剩下一个数据块,但是请记住多块读scattered read是不能跨越一个区间的(span an extent),此时就会单块读取并出现”db file sequential read”。
4、假设某个区间内有8个数据块,它们可以是块a,b,c,d,e,f,g,h,恰好当前系统中除了d块外的其他数据块都已经被缓存在buffer cache中了,而这时候恰好要访问这个区间中的数据,那么此时就会单块读取d这个数据块,并出现”db file sequential read”等待。注意这种情况不仅于表,也可能发生在索引上。- Buffer Busy Waits:该事件是在一个SESSION需要访问BUFFER CACHE中的一个数据库块而又不能访问时发生的(指的是多个session对于同一个block的写入竞争)
出现在两个session都是写入时。 - read by other session:多个session并发请求相同的数据块,但因该数据块不在buffer_cache中而必须从磁盘读取,处理这种情况,oracle会只让其中一个sesion进行磁盘读取,此时其它session等待块从磁盘上读取进buffer_cache而抛出read by other session等待事件。
- gc buffer busy:相当于rac集群下的Buffer Busy Waits.
- gc buffer busy acquire:与上面一致。
Top Sql分析
- SQL Statistics 从 11 个维度对SQL进行排序并给出了Top SQL的详细内容,可以点击查看具体的SQL内容,进一步分析调优方案。
- SQL ordered by Elapsed Time:记录了执行总和时间的 TOP SQL(请注意是监控范围内该SQL的执行时间总和,而不是单次SQL执行时间 Elapsed Time = CPU Time + Wait Time)。
- SQL ordered by CPU Time:记录了执行占CPU时间总和时间最长的TOP SQL(请注意是监控范围内该SQL的执行占CPU时间总和,而不是单次SQL执行时间)。
- SQL ordered by Gets:记录了执行占总 buffer gets (逻辑IO)的TOP SQL(请注意是监控范围内该SQL的执行占Gets总和,而不是单次SQL执行所占的Gets)。
- SQL ordered by Reads:记录了执行占总磁盘物理读(物理IO)的TOP SQL。
- SQL ordered by Executions:记录了按照SQL的执行次数排序的TOP SQL。该排序可以看出监控范围内的SQL执行次数。
- SQL ordered by Parse Calls:记录了SQL的软解析次数的TOP SQL。
- SQL ordered by Sharable Memory:记录了SQL占用library cache的大小的TOP SQL。Sharable Mem (b):占用library cache的大小,单位是byte。
- SQL ordered by Version Count:记录了SQL的打开子游标的TOP SQL。
- SQL ordered by Cluster Wait Time:记录了集群的等待时间的TOP SQL。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)