Flink 部署
这里需要提到 Flink 中的几个关键组件:客户端(Client)、作业管理器(JobManager)和任务管理器(TaskManager)。我们的代码,实际上是由客户端获取并做转换,之后提交给 JobManger 的。所以 JobManager 就是 Flink 集群里的“管事人”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的TaskManager。这
这里需要提到 Flink 中的几个关键组件:客户端(
Client)、作业管理器(JobManager)和任务管理器(TaskManager)。我们的代码,实际上是由客户端获取并做转换,之后提交给 JobManger 的。所以 JobManager 就是 Flink 集群里的“管事人”,对作业进行中央调度管理;而它获取到要执行的作业后,会进一步处理转换,然后分发任务给众多的TaskManager。这里的 TaskManager,就是真正“干活的人”,数据的处理操作都是它们来做的,
一、快速启动一个 Flink 集群
1. 环境配置
Flink 是一个分布式的流处理框架,所以实际应用一般都需要搭建集群环境。我们在进行Flink 安装部署的学习时,需要准备 3 台Linux 机器。具体要求如下:
- 系统环境为 CentOS 7.5 版本。
- 安装 Java 8。
- 安装Hadoop 集群,Hadoop 建议选择Hadoop 2.7.5 以上版本。
- 配置集群节点服务器间时间同步以及免密登录,关闭防火墙。本书中三台服务器的具体设置如下:
- 节点服务器 1,IP 地址为 192.168.10.102,主机名为hadoop102。
- 节点服务器 2,IP 地址为 192.168.10.103,主机名为hadoop103。
- 节点服务器 3,IP 地址为 192.168.10.104,主机名为hadoop104。
2. 本地启动
最简单的启动方式,其实是不搭建集群,直接本地启动。本地部署非常简单,直接解压安装包就可以使用,不用进行任何配置;一般用来做一些简单的测试。
具体安装步骤如下:
- 下载安装包
进入 Flink 官网,下载 1.13.0 版本安装包flink-1.13.0-bin-scala_2.12.tgz,注意此处选用对应 scala 版本为 scala 2.12 的安装包。 - 解压
在 hadoop102 节点服务器上创建安装目录/opt/module,将 flink 安装包放在该目录下,并执行解压命令,解压至当前目录。 - 启动
进入解压后的目录,执行启动命令,并查看进程。
$ cd flink-1.13.0/
$ bin/start-cluster.sh Starting cluster.
Starting standalonesession daemon on host hadoop102. Starting taskexecutor daemon on host hadoop102.
$ jps
10369 StandaloneSessionClusterEntrypoint
10680 TaskManagerRunner
10717 Jps
- 访问 Web UI
启动成功后,访问http://hadoop102:8081,可以对 flink 集群和任务进行监控管理。
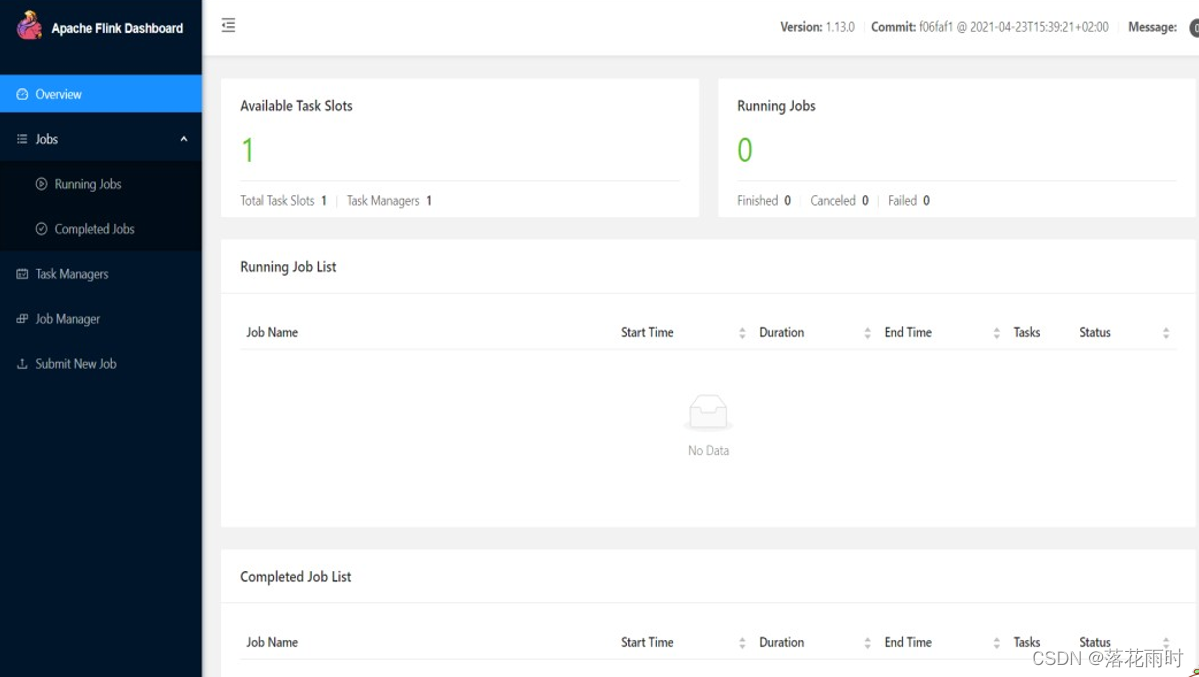
- 关闭集群
如果想要让 Flink 集群停止运行,可以执行以下命令:
bin/stop-cluster.sh
3. 集群启动
可以看到,Flink 本地启动非常简单,直接执行 start-cluster.sh 就可以了。如果我们想要扩展成集群,其实启动命令是不变的,主要是需要指定节点之间的主从关系。
Flink 是典型的 Master-Slave 架构的分布式数据处理框架,其中 Master 角色对应着JobManager,Slave 角色则对应TaskManager。我们对三台节点服务器的角色分配如表所示。
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | JobManager | TaskManager | TaskManager |
具体安装部署步骤如下:
3.1 下载并解压安装包
具体操作与上节相同。
3.2 修改集群配置
(1)进入 conf目录下,修改flink-conf.yaml文件,修改jobmanager.rpc.address 参数为
hadoop102,如下所示:
$ vim flink-conf.yaml
jobmanager.rpc.address: hadoop102 # JobManager 节点地址.
这就指定了hadoop102 节点服务器为 JobManager 节点。
(2) 修改 workers 文件,将另外两台节点服务器添加为本 Flink 集群的TaskManager节点,具体修改如下:
$ vim workers
hadoop103
hadoop104
这样就指定了hadoop103 和 hadoop104 为TaskManager 节点。
(3) 另外,在 flink-conf.yaml文件中还可以对集群中的 JobManager 和 TaskManager 组件进行优化配置,主要配置项如下:
jobmanager.memory.process.size:对 JobManager 进程可使用到的全部内存进行配置, 包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。taskmanager.memory.process.size:对 TaskManager 进程可使用到的全部内存进行配置,包括 JVM 元空间和其他开销,默认为 1600M,可以根据集群规模进行适当调整。taskmanager.numberOfTaskSlots:对每个 TaskManager 能够分配的 Slot 数量进行配置, 默认为 1,可根据 TaskManager 所在的机器能够提供给 Flink 的 CPU 数量决定。所谓Slot 就是TaskManager 中具体运行一个任务所分配的计算资源。parallelism.default:Flink 任务执行的默认并行度,优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
3.3 分发安装目录
配置修改完毕后,将 Flink 安装目录发给另外两个节点服务器。
$ scp -r ./flink-1.13.0 atguigu@hadoop103:/opt/module
$ scp -r ./flink-1.13.0 atguigu@hadoop104:/opt/module
3.4 启动集群
(1)在 hadoop102 节点服务器上执行 start-cluster.sh 启动 Flink 集群:
$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102. Starting taskexecutor daemon on host hadoop103.
Starting taskexecutor daemon on host hadoop104.
(2)查看进程情况:
[atguigu@hadoop102 flink-1.13.0]$ jps
13859 Jps
13782 StandaloneSessionClusterEntrypoint
[atguigu@hadoop103 flink-1.13.0]$ jps
12215 Jps
12124 TaskManagerRunner
[atguigu@hadoop104 flink-1.13.0]$ jps
11602 TaskManagerRunner
11694 Jps
3.5 访问 Web UI
启动成功后,同样可以访问http://hadoop102:8081对 flink 集群和任务进行监控管理,如图所示。
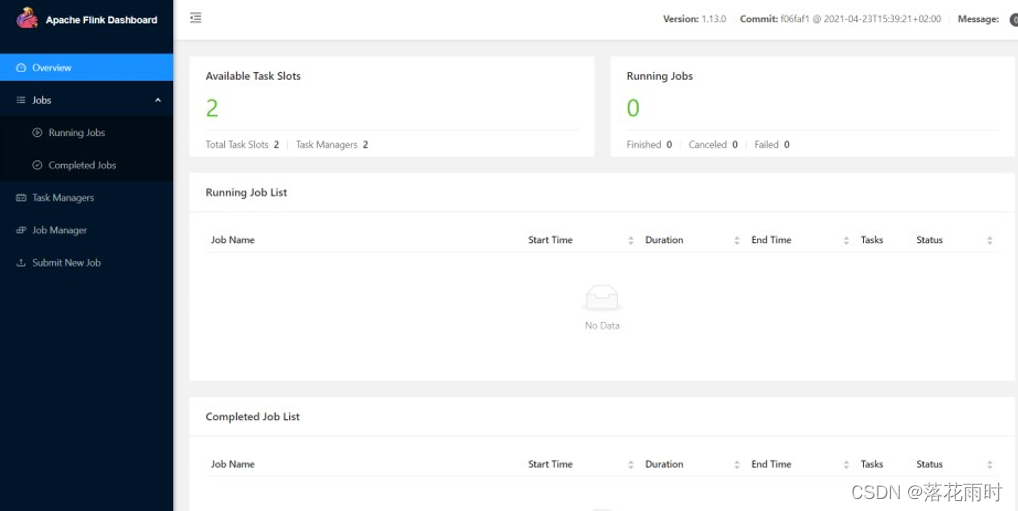
这里可以明显看到,当前集群的 TaskManager 数量为 2;由于默认每个 TaskManager 的 Slot数量为 1,所以总 Slot 数和可用 Slot 数都为 2。
4. 向集群提交作业
4.1 在 Web UI 上提交作业
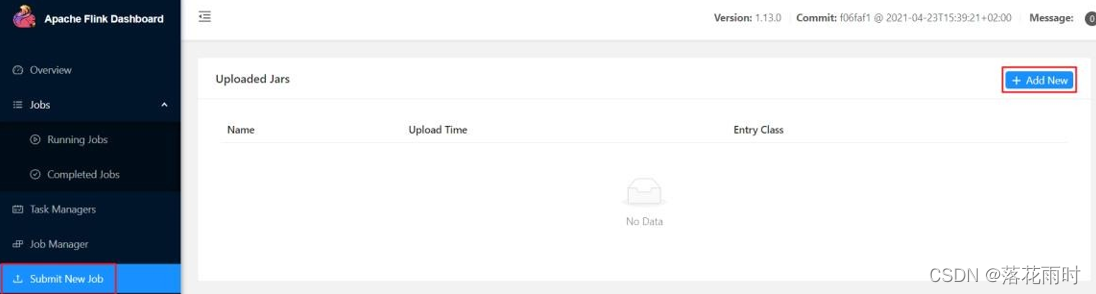
(1)任务打包完成后,我们打开 Flink 的 WEB UI 页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的 JAR 包。

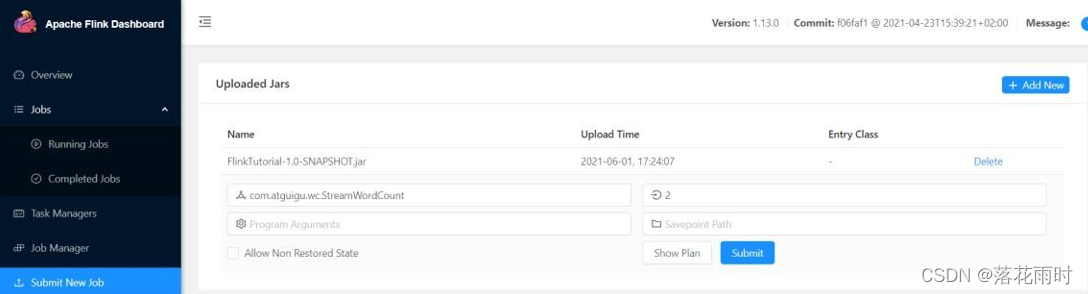
(2) 点击该JAR包,出现任务配置页面,进行相应配置。
主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,如图 所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行
4.2 命令行提交作业
除了通过 WEB UI 界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便起见,我们可以先把 jar 包直接上传到目录 flink-1.13.0 下
(1)首先需要启动集群。
$ bin/start-cluster.sh
(2)在 hadoop102 中执行以下命令启动 netcat。
$ nc -lk 7777
(3)进入到 Flink 的安装路径下,在命令行使用 flink run 命令提交作业。
$ bin/flink run -m hadoop102:8081 -c com.atguigu.wc.StreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
这里的参数
–m指定了提交到的 JobManager,-c指定了入口类。
4.3 关于打包
打包时添加maven-assembly-plugin插件,可以把所有的依赖包打进去,保证jar包可以正常运行(除了flink环境中已经包含的依赖)。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
二、部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink 为各种场景提供了不同的部署模式,主要有以下三种:
- 会话模式(Session Mode)
- 单作业模式(Per-Job Mode)
- 应用模式(Application Mode)
它们的区别主要在于:
- 集群的生命周期以及资源的分配方式;
- 应用的 main 方法到底在哪里执行——客户端(Client)还是 JobManager。接下来我们就做一个展开说明。
1. 会话模式(Session Mode)
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业,如图所示。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
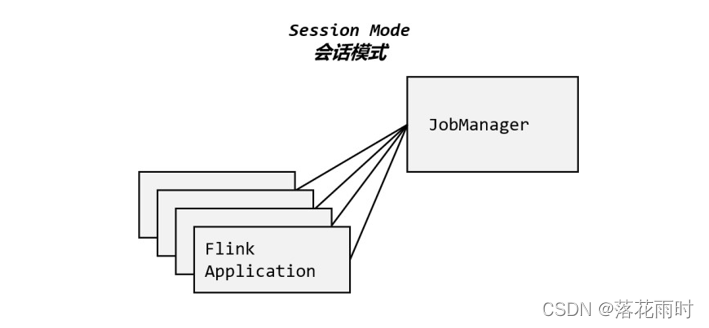
这样的好处很明显,我们只需要一个集群,就像一个大箱子,所有的作业提交之后都塞进去;集群的生命周期是超越于作业之上的,铁打的营盘流水的兵,作业结束了就释放资源,集群依然正常运行。当然缺点也是显而易见的:因为资源是共享的,所以资源不够了,提交新的作业就会失败。另外,同一个 TaskManager 上可能运行了很多作业,如果其中一个发生故障导致 TaskManager 宕机,那么所有作业都会受到影响。
会话模式比较适合于单个规模小、执行时间短的大量作业。\
2. 单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。

单作业模式也很好理解,就是严格的一对一,集群只为这个作业而生。同样由客户端运行应用程序,然后启动集群,作业被提交给 JobManager,进而分发给 TaskManager 执行。作业作业完成后,集群就会关闭,所有资源也会释放。这样一来,每个作业都有它自己的 JobManager 管理,占用独享的资源,即使发生故障,它的 TaskManager 宕机也不会影响其他作业。
这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
需要注意的是,Flink 本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如
YARN、Kubernetes。
3. 应用模式(Application Mode)
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给 JobManager 的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到 JobManger 上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个 JobManager只为执行这一个应用而存在,执行结束之后JobManager也就关闭了,这就是所谓的应用模式。

应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由 JobManager 执行应用程序的,并且即使应用包含了多个作业,也只创建一个集群。
总结一下,在会话模式下,集群的生命周期独立于集群上运行的任何作业的生命周期,并且提交的所有作业共享资源。而单作业模式为每个提交的作业创建一个集群,带来了更好的资源隔离,这时集群的生命周期与作业的生命周期绑定。最后,应用模式为每个应用程序创建一个会话集群,在 JobManager 上直接调用应用程序的main()方法。
我们所讲到的部署模式,相对是比较抽象的概念。实际应用时,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者(Resource Provider)的场景,具体介绍 Flink 的部署方式。
三、YARN 环境下部署(重点)
独立部署模式(Standalone)用的不多,所以此处不做过多介绍,本文关于快速启动一个 Flink 集群的介绍,就是独立部署下的会话模式。
1. 相关准备和配置
在 Flink 1.11.0 版本之后,增加了很多重要新特性,其中就包括增加了对Hadoop3.0.0以及更高版本Hadoop 的支持,不再提供“flink-shaded-hadoop-*” jar 包,而是通过配置环境变量完成与 YARN 集群的对接。
在将 Flink 任务部署至 YARN 集群之前,需要确认集群是否安装有Hadoop,保证 Hadoop版本至少在
2.2以上,并且集群中安装有 HDFS 服务。
具体配置步骤如下:
(1) 下载并解压安装包,并将解压后的安装包重命名为flink-1.13.0-yarn,本节的相关操作都将默认在此安装路径下执行。
(2) 配置环境变量,增加环境变量配置如下(示例):
$ sudo vim /etc/profile.d/my_env.sh
HADOOP_HOME=/opt/module/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
这里必须保证设置了环境变量
HADOOP_CLASSPATH。
官网的描述:
Important Make sure that the HADOOP_CLASSPATH environment variable is set up (it can be checked by running echo $HADOOP_CLASSPATH). If not, set it up using
export HADOOP_CLASSPATH=`hadoop classpath`
(3) 启动Hadoop 集群,包括 HDFS 和 YARN。
[hadoop102 ~]$ start-dfs.sh
[hadoop103 ~]$ start-yarn.sh
(4) 进入 conf 目录,修改flink-conf.yaml文件,修改以下配置,这些配置项的含义在进行 Standalone 模式配置的时候进行过讲解,若在提交命令中不特定指明,这些配置将作为默认配置。
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 8
parallelism.default: 1
2. 会话模式部署
YARN 的会话模式与独立集群略有不同,需要首先申请一个 YARN 会话(YARN session) 来启动 Flink 集群。具体步骤如下:
2.1 启动集群
(1) 启动 hadoop 集群(HDFS, YARN)。
(2) 执行脚本命令向 YARN 集群申请资源,开启一个 YARN 会话,启动 Flink 集群。
bin/yarn-session.sh -nm test
可用参数解读:
- -d:分离模式,如果你不想让 Flink YARN 客户端一直前台运行,可以使用这个参数,即使关掉当前对>话窗口,YARN session 也可以后台运行。
- -jm(–jobManagerMemory):配置 JobManager 所需内存,默认单位 MB。
- -nm(–name):配置在 YARN UI 界面上显示的任务名。
- -qu(–queue):指定 YARN 队列名。
- -tm(–taskManager):配置每个 TaskManager 所使用内存。
注意:Flink1.11.0 版本不再使用-n 参数和-s 参数分别指定 TaskManager 数量和 slot 数量, YARN 会按照需求动态分配TaskManager 和 slot。所以从这个意义上讲,YARN 的会话模式也不会把集群资源固定,同样是动态分配的。
YARN Session 启动之后会给出一个web UI 地址以及一个 YARN application ID,如下所示,用户可以通过web UI 或者命令行两种方式提交作业。
[] - Found Web Interface hadoop104:39735 of application 'application_1622535605178_0003'.
JobManager Web Interface: http://hadoop104:39735
2.2 提交作业
(1) 通过Web UI 提交作业
这种方式比较简单,与上文所述 Standalone 部署模式基本相同。
(2) 通过命令行提交作业
- 将 Standalone 模式讲解中打包好的任务运行 JAR 包上传至集群
- 执行以下命令将该任务提交到已经开启的 Yarn-Session 中运行。
bin/flink run -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
客户端可以自行确定 JobManager 的地址,也可以通过-m 或者-jobmanager参数指定JobManager 的地址,JobManager 的地址在 YARN Session 的启动页面中可以找到。
(3)任务提交成功后,可在 YARN 的Web UI 界面查看运行情况。
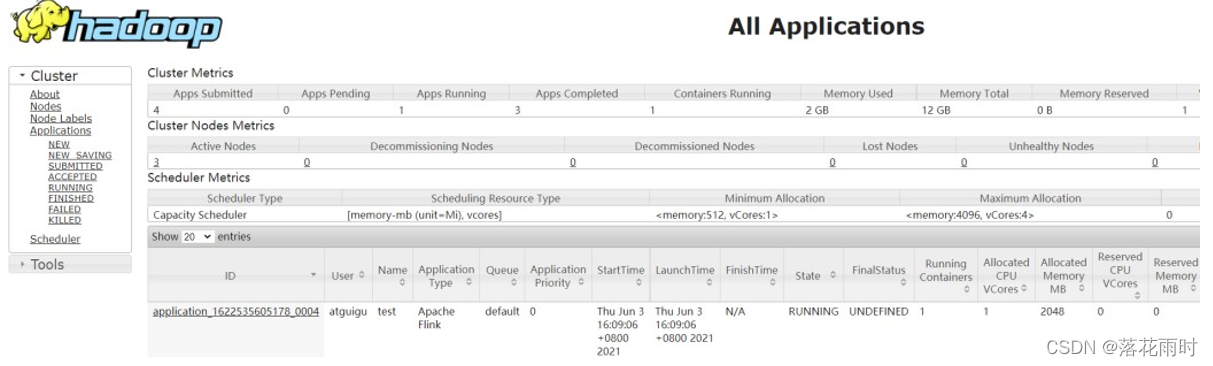
如图所示,从图中可以看到我们创建的 Yarn-Session 实际上是一个 Yarn 的Application,并且有唯一的Application ID。
(5)也可以通过 Flink 的 Web UI 页面查看提交任务的运行情况。
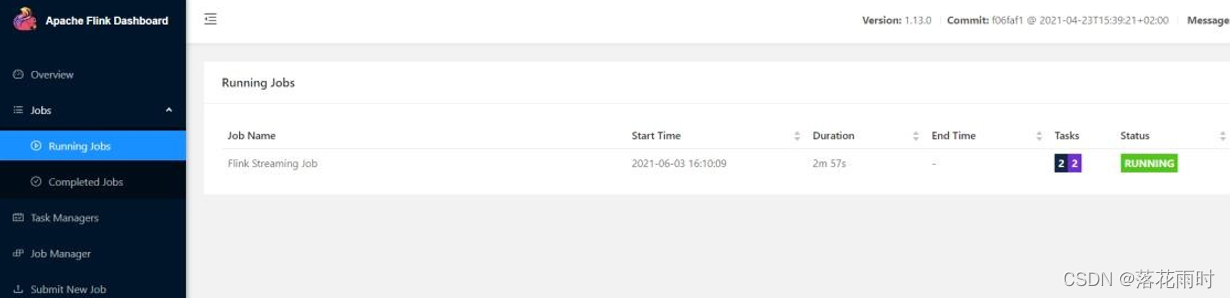
3. 单作业模式部署
在 YARN 环境中,由于有了外部平台做资源调度,所以我们也可以直接向 YARN 提交一个单独的作业,从而启动一个 Flink 集群。
(1)执行命令提交作业。
$ bin/flink run -d -t yarn-per-job -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
早期版本也有另一种写法:
$ bin/flink run -m yarn-cluster -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
注意这里是通过参数-m yarn-cluster指定向 YARN 集群提交任务。
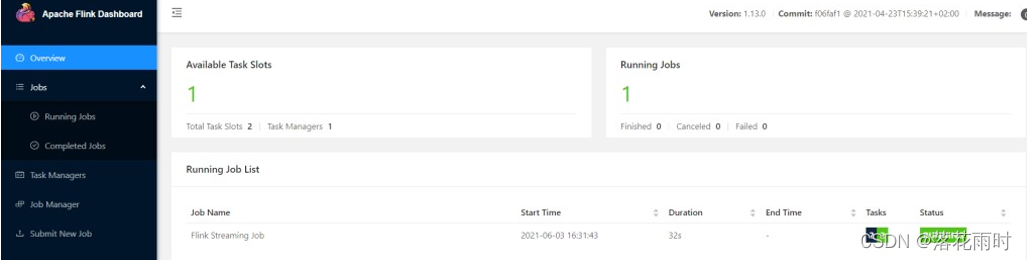
(2)在 YARN 的ResourceManager 界面查看执行情况。

点击可以打开 Flink Web UI 页面进行监控。
(3)可以使用命令行查看或取消作业,命令如下。
$ ./bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
$ ./bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
这里的 application_XXXX_YY 是当前应用的 ID,<jobId>是作业的 ID。注意如果取消作业,整个 Flink 集群也会停掉。
4. 应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行flink run-application命令即可。
(1)执行命令提交作业。
$ bin/flink run-application -t yarn-application -c com.atguigu.wc.StreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
(2)在命令行中查看或取消作业。
$ ./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
$ ./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
(3)也可以通过yarn.provided.lib.dirs 配置选项指定位置,将 jar 上传到远程。
$ ./bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" hdfs://myhdfs/jars/my-application.jar
这种方式下 jar 可以预先上传到 HDFS,而不需要单独发送到集群,这就使得作业提交更
加轻量了。
5. 高可用
YARN 模式的高可用和独立模式(Standalone)的高可用原理不一样。
Standalone 模式中, 同时启动多个 JobManager, 一个为“领导者”(leader),其他为“后备”
(standby), 当 leader 挂了, 其他的才会有一个成为 leader。而 YARN 的高可用是只启动一个 Jobmanager, 当这个 Jobmanager 挂了之后, YARN 会再次启动一个, 所以其实是利用的 YARN 的重试次数来实现的高可用。
(1)在 yarn-site.xml 中配置。
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
注意: 配置完不要忘记分发, 和重启 YARN。
(2)在 flink-conf.yaml 中配置。
yarn.application-attempts: 3
high-availability: zookeeper
high-availability.storageDir: hdfs://hadoop102:9820/flink/yarn/ha
high-availability.zookeeper.quorum:
hadoop102:2181,hadoop103:2181,hadoop104:2181
high-availability.zookeeper.path.root: /flink-yarn
(3)启动 yarn-session。
(4)杀死 JobManager, 查看复活情况。
注意: yarn-site.xml 中配置的是 JobManager 重启次数的上限, flink-conf.xml 中的次数应该
小于这个值
参考资料
Word版:https://download.csdn.net/download/mengxianglong123/85035166
PDF版:https://download.csdn.net/download/mengxianglong123/85035172
需要的可以私信我,免费

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)