RPO和RTO是什么?
在衡量系统高可用的时候,我们经常能看到几个专业词汇,例如RPO和RTO,像OceanBase号称可以做到RPO=0,RTO<30s,RPO和RTO代表了什么?RTO,Recovery...
在衡量系统高可用的时候,我们经常能看到几个专业词汇,例如RPO和RTO,像OceanBase号称可以做到RPO=0,RTO<30s,RPO和RTO代表了什么?

RTO,Recovery Time Objective,他是指灾难发生后,从IT系统当机导致业务停顿之时开始,到IT系统恢复至可以支持各部门运作、恢复运营之时,此两点之间的时间段称为RTO。
RPO,Recovery Point Objective,是指从系统和应用数据而言,要实现能够恢复至可以支持各部门业务运作,系统及生产数据应恢复到怎样的更新程度。这种更新程度可以是上一周的备份数据,也可以是上一次交易的实时数据。
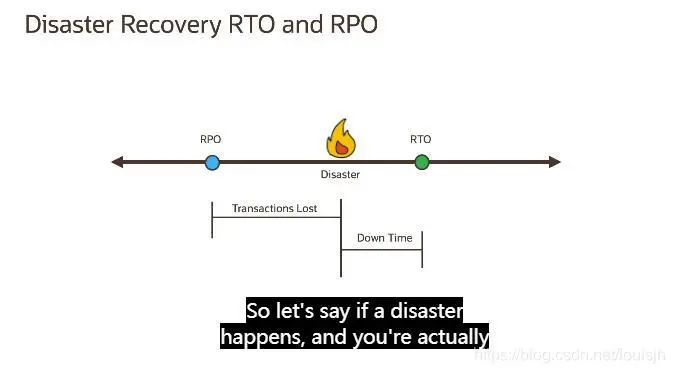
可以看出来,RTO和RPO服务于不同的目标,RTO涉及应用程序和系统,但主要描述应用程序停机时间的限制。RPO主要与失败事件后丢失的数据量有关。
因此,从客户的角度,如果某个服务节点发生了故障,肯定希望数据不丢(RPO=0),而且能尽快恢复(RTO 越小越好)。
理论上讲主从复制技术是可以利用强同步模式(例如Oracle Data Guard中采用Max Protection模式,或者DB2 HADR中采用Sync模式)做到RPO=0,但实际应用中,像银行核心系统这样的关键业务里却不会采用。为什么?因为这种模式将主节点和从节点以及主从节点之间的网络环境紧紧地绑在了一起,主节点的稳定性将不再由他自己决定,而要同时看从节点和网络环境的脸色。一旦从节点或者网络环境稍微抖动一下,主节点的性能就会受到直接影响。如果主节点和从节点之间是跨机房甚至跨城市部署,发生这种问题的概率会更大,影响也会变得更加显著。从某种程度上讲,和单节点模式相比,这种模式下主节点的稳定性不但没有增加,反而是降低了。除非你的业务,只关注RPO,不关注性能的稳定性情况,或者能接受不稳定的可能,但是必须保证RPO=0。
造成这一情况的根本原因,是“主从复制”模式下从节点不具备自动切主的能力。由于“主从复制“模式中缺少第三方仲裁者的角色,当主从节点之间的心跳信号异常时,从节点无法靠自己判断到底是主点故障了,还是主从之间的网络故障了。此时,如果从节点认为是主节点故障而将自己自动切换成主节点,就极容易导致“双主”、“脑裂”(brain-split)的局面,对用户来说这是绝对无法接受的结果。Oracle的DG提供了broker和Fast-Start Failover结合进行主备自动切换的功能,但是可能一般很少直接用,中间还是会穿插人的判断。如果从节点自动切换为主节点的功能,一定要由“人”来确认主节点确实故障了,并手工发起从节点的切主动作,这就大大增加了系统恢复的时间(RTO)。
除了传统数据库的高可用技术,现在逐渐被越来越多的技术厂商所采用的技术,是分布式多副本数据一致性技术,通常是基于Paxos协议或者Raft协议来实现。这种技术会将数据保存在多份副本上,每一次对数据的修改操作都会强同步到多数派副本上,在保证了数据冗余的同时,不再像“主从复制”技术那样依赖某个数据节点的稳定性,从而消除了传统主从复制技术下从节点给主节点带来的风险。同时,在主节点故障的情况下,其余节点会自动选举出新的主节点以实现高可用(个别从节点故障则完全不影响服务),整个过程非常快速且完全无需人工干预。因此,这种技术不仅能保证RPO=0,而且大大减小了RTO,相比传统“主从复制”技术来说可以提供更强大的高可用能力。
另外,为了抵御机房级灾难和城市级灾难,可以将多份副本分散部署在多个机房里甚至多个城市中,以避免机房级灾难或者城市级灾难损毁多数派副本。这样就具备了机房级容灾和城市级容灾的能力,进一步加强了高可用的能力。
之前学习过OBCA教材,其中对OceanBase高可用的介绍,能更好地说明以上的理论和实现。OceanBase利用了Paxos协议中的多数派共识机制来保证数据的可靠性,在高可用方面,OceanBase也利用了同样的机制。首先,根据Paxos协议,在任一时刻只有多数派副本达成一致时,才能推选一个leader,其余的少数派副本则不具备推选leader的资格。其次,如果正在提供服务的leader副本遇到故障而无法继续提供服务,只要其余的follower副本满足多数派并且达成一致,他们就可以推选一个新的leader来接管服务,而正在提供服务的leader自己无法满足多数派条件,将自动失去leader的资格。
因此,我们可以看到Paxos协议在高可用方面有明显的优势:
1) 从理论上保证了任一时刻至多有一个leader,彻底杜绝了脑裂的情况。
2) 由于不再担心脑裂,当leader故障而无法提供服务时,follower便可以自动触发选举来产生新的leader并接管服务,全程无须人工介入。
这样一来,不但从根本上解决了脑裂的问题,还可以利用自动重新选举大大缩短RTO,可以说完美解决了主从热备技术在高可用上所面临的难题。
当然,这里面还有一个很重要的因素,那就是leader出现故障时,follower 能在多长时间内感知到leader的故障并推选出新的leader,这个时间直接决定了RTO的大小。在OceanBase中,为了能够及时感知Paxos组中各个副本(包括leader和follower)的状态,在各个副本之间会有定期探活的消息。另一方面,探活机制虽然能够检测到节点的故障,但是在网络不稳定的情况下,也可能由于偶发的探活消息丢包而产生“误报(False-alarm)”的情况。
为了避免误报对系统稳定性带来的影响,OceanBase也采取了很多应对措施:
1) 首先,探活消息的周期必须要合理。
如果周期太长就不能及时感知到节点故障,如果周期太短就会增大误报的概率,而且也可能会影响性能。目前在OceanBase中的探活总体耗时为10秒左右,确保能及时感知到节点故障,并且也不会频繁产生误报。
2) 其次,要能够容忍偶发性的消息丢包,减小误报的概率。
具体来说,OceanBase不会由于一次探活的失败就认定某个节点发生了故障,而是在连续多次尝试都失败后才确认真正的节点故障。这就有效避免了偶发性消息丢包所导致的误报。
3) 如果真的发生了误报,需要将影响范围降到最小。
OceanBase将Paxos组的粒度下沉到了表的分区一级,也就是每一个分区都会有一个Paxos组,用来维护这个分区的多个副本之间的leader-follower关系,如果由于少量网络丢包导致“某个分区”的探活消息没有收到回复,那么受影响的只是这个分区,同一台机器上的其他分区会照常工作,这就有效地控制了问题的影响范围。
4) 某些特殊情况的处理。
举个例子,如果某台机器出现间歇性故障(例如网卡或者操作系统出了问题),导致这台机器频繁发生网络传输故障,就会使这台机器上所有的leader副本持续受到影响。这种情况下,OceanBase可以通过设置特定参数限制这台机器暂时不参与leader选举,这样就有效地起到了隔离作用,避免了局部故障对整个集群的可用性造成持续影响。
在具备了上述这些处理机制后,OceanBase目前已经能做到最多10秒钟检测到服务节点异常,并在10~30秒内完成服务的自动恢复。需要说明的是,具体的恢复时间和遇到问题的机器个数、表的分区个数、故障类型(机器硬件故障、网络设备故障等)都有密切的关系,所以上面说的服务恢复时间只是作为一个参考值,在某些特殊情况下也可能发生偏差。
因此,分布式多副本数据一致性技术一定程度上可以提供客户所需要的RPO和RTO,尤其在互联网,企业级的实现,已经相对成熟,这算是技术进步给业务带来更高可用性的一个佐证。
近期更新的文章:
《技术分享邀请》
《小白学习MySQL - InnoDB支持optimize table?》
文章分类和索引:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)