postgresql数据库 查询慢的原因之一(死元祖太多) postgresql表清理收缩
postgresql数据库 查询慢的原因之一(死元祖太多) postgresql表清理收缩文章目录postgresql数据库 查询慢的原因之一(死元祖太多) postgresql表清理收缩前言一、元组是什么?二、postgresql的解决方法自动清理自动清理相关参数2.查询当前正在进行自动清理的表及相关信息3、查询自动清理的历史统计信息手动清理数据表收缩总结前言在使用postgresql数据库时,
postgresql数据库 查询慢的原因之一(死元祖太多问题) postgresql表清理收缩
文章目录
前言
在使用postgresql数据库时,有时往往会发现有时候查询速度非常慢,以往十几秒就查询出来的,结果需要20多秒才行,看了看发现没有锁,这时候一般都是表的死元祖太多导致的。
我们知道postgresql数据库通过数据多版本实现mvcc,pg又没有undo段,老版本的数据元组直接存放在数据页面中,这样带来的问题就是旧元组需要不断地进行清理以释放空间,这也是数据库膨胀的根本原因
一、元组是什么?
元组,也叫tuple,这个叫法是很学术的叫法,但是现在数据库中一般叫行或者记录。
二、postgresql的解决方法
在postgresql数据库中既可以手动去清理。也可以运用自动清理参数
自动清理
自动清理相关参数
在PostgreSQL数据库系统配置文件中,与系统自动清理相关的主要相关参数如下:
autovacuum:是否启动系统自动清理功能,默认值为on。
autovacuum_max_workers:设置系统自动清理工作进程的最大数量。
autovacuum_naptime:设置两次系统自动清理操作之间的间隔时间。
autovacuum_vacuum_threshold和autovacuum_analyze_threshold:设置当表上被更新的元组数的阈值超过这些阈值时分别需要执行vacuum和analyze。
autovacuum_vacuum_scale_factor和autovacuum_analyze_scale_factor:设置表大小的缩放系数。
autovacuum_freeze_max_age:设置需要强制对数据库进行清理的XID上限值。
### 1.查询元祖 和那些表需要清理 查询当前数据库表已经达到自动清理条件的表及相关信息
SELECT
c.relname 表名,
(current_setting('autovacuum_analyze_threshold')::NUMERIC(12,4))+(current_setting('autovacuum_analyze_scale_factor')::NUMERIC(12,4))*reltuples AS 自动分析阈值,
(current_setting('autovacuum_vacuum_threshold')::NUMERIC(12,4))+(current_setting('autovacuum_vacuum_scale_factor')::NUMERIC(12,4))*reltuples AS 自动清理阈值,
reltuples::DECIMAL(19,0) 活元组数,
n_dead_tup::DECIMAL(19,0) 死元组数
FROM
pg_class c
LEFT JOIN pg_stat_all_tables d
ON C.relname = d.relname
WHERE
c.relname LIKE'tb%' AND reltuples > 0
AND n_dead_tup > (current_setting('autovacuum_analyze_threshold')::NUMERIC(12,4))+(current_setting('autovacuum_analyze_scale_factor')::NUMERIC(12,4))*reltuples;
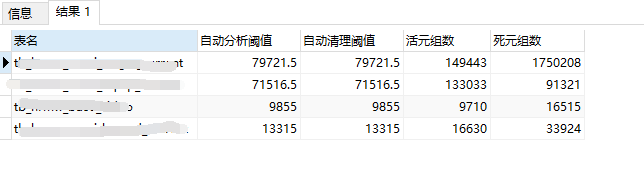
这里可以看这个数据库有4张表需要清理
2.查询当前正在进行自动清理的表及相关信息
查询当前正在进行自动清理的表及相关信息
SELECT
c.relname 对象名称,
l.pid 进程id,
psa.STATE 查询状态,
psa.query 执行语句,
now( ) - query_start 持续时间
FROM
pg_locks l
INNER JOIN pg_stat_activity psa ON ( psa.pid = l.pid )
LEFT OUTER JOIN pg_class C ON ( l.relation = C.oid )
WHERE psa.query like 'autovacuum%' and l.fastpath='f'
ORDER BY query_start asc;
3、查询自动清理的历史统计信息
查询自动清理的历史统计信息
SELECT
relname 表名,
seq_scan 全表扫描次数,
seq_tup_read 全表扫描记录数,
idx_scan 索引扫描次数,
idx_tup_fetch 索引扫描记录数,
n_tup_ins 插入的条数,
n_tup_upd 更新的条数,
n_tup_del 删除的条数,
n_tup_hot_upd 热更新条数,
n_live_tup 活动元组估计数,
n_dead_tup 死亡元组估计数,
-- last_vacuum 最后一次手动清理时间,
last_autovacuum 最后一次自动清理时间,
-- last_analyze 最后一次手动分析时间,
last_autoanalyze 最后一次自动分析时间,
-- vacuum_count 手动清理的次数,
autovacuum_count 自动清理的次数,
-- analyze_count 手动分析此表的次数,
autoanalyze_count 自动分析此表的次数,
( CASE WHEN n_live_tup > 0 THEN n_dead_tup :: float8 / n_live_tup :: float8 ELSE 0 END ) :: NUMERIC ( 12, 2 ) AS "死/活元组的比例"
FROM
pg_stat_all_tables
WHERE
schemaname = 'public'
ORDER BY n_dead_tup::float8 DESC;


因保密需要,部分数据是虚构的
手动清理
手动清理往往在自动清理占时太长 ,清理不彻底的时候才进行手动清理
数据表收缩
VACUUM FULL VERBOSE 表名;
VACUUM FULL VERBOSE ANALYZE 表名;
总结
清理完之后会提高查询效率,那是经常需要进行插入,update的表需要时刻关注,这种表的所占的空间比较大,需要时常收缩清理 ,当然自动清理会堵塞部分数据库进程。最后补一张大佬1_bit做的饭


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐


 7
7 1
1- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)