
大数据学习——Hadoop本地模式搭建
大数据学习之Hadoop本地模式搭建。
一.Centos7的安装
1.安装Centos7
前提需要安装好VMware16.2x
下载地址:
[https://download3.vmware.com/software/WKST-1624-WIN/VMware-workstation-full-16.2.4-20089737.exe](https://download3.vmware.com/software/WKST-1624-WIN/VMware-workstation-full-16.2.4-20089737.ex
2.网络配置
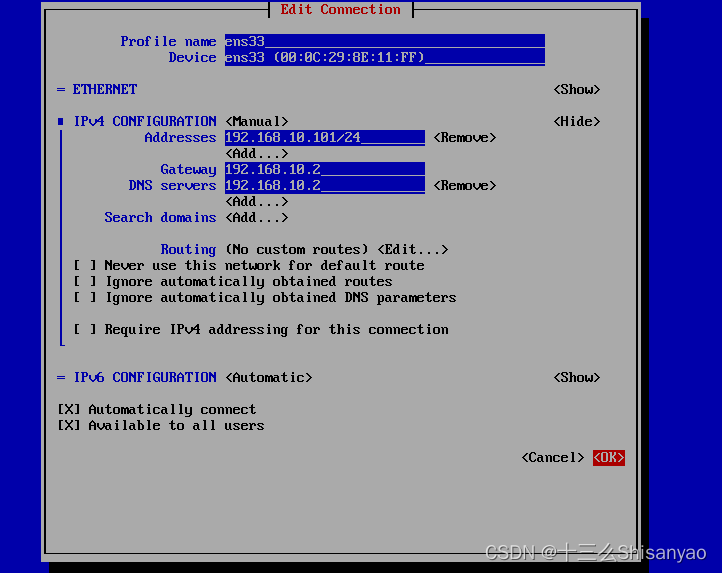
打开VMware16,点击左上角编辑——>点击虚拟网络编辑——>点击VMnet8 配置NET模式——在最下方配置子网IP和子网掩码——>点击NET模式 NET设置——>配置网关IP——>应用,确定

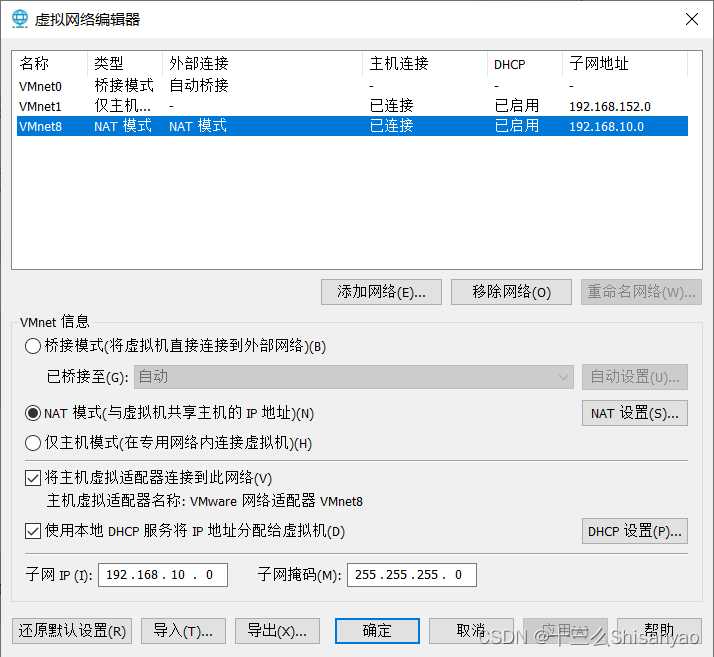
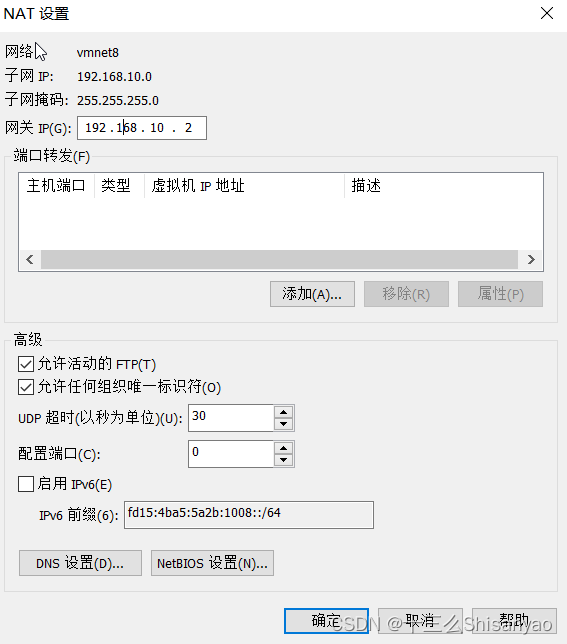
以win10为例:
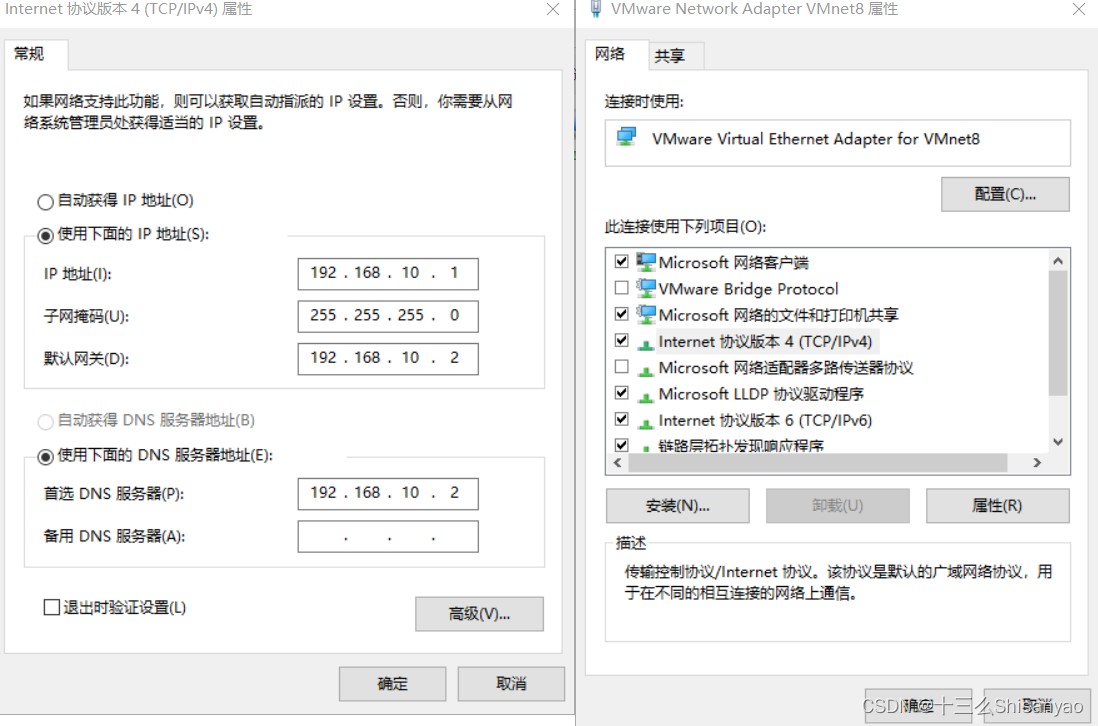
打开适配器选项——>鼠标点击VMware Network Adapter VMnet8——>属性——>双击Internet协议版本(TCP/IPv4)——>手动修改IP地址(如图所示)
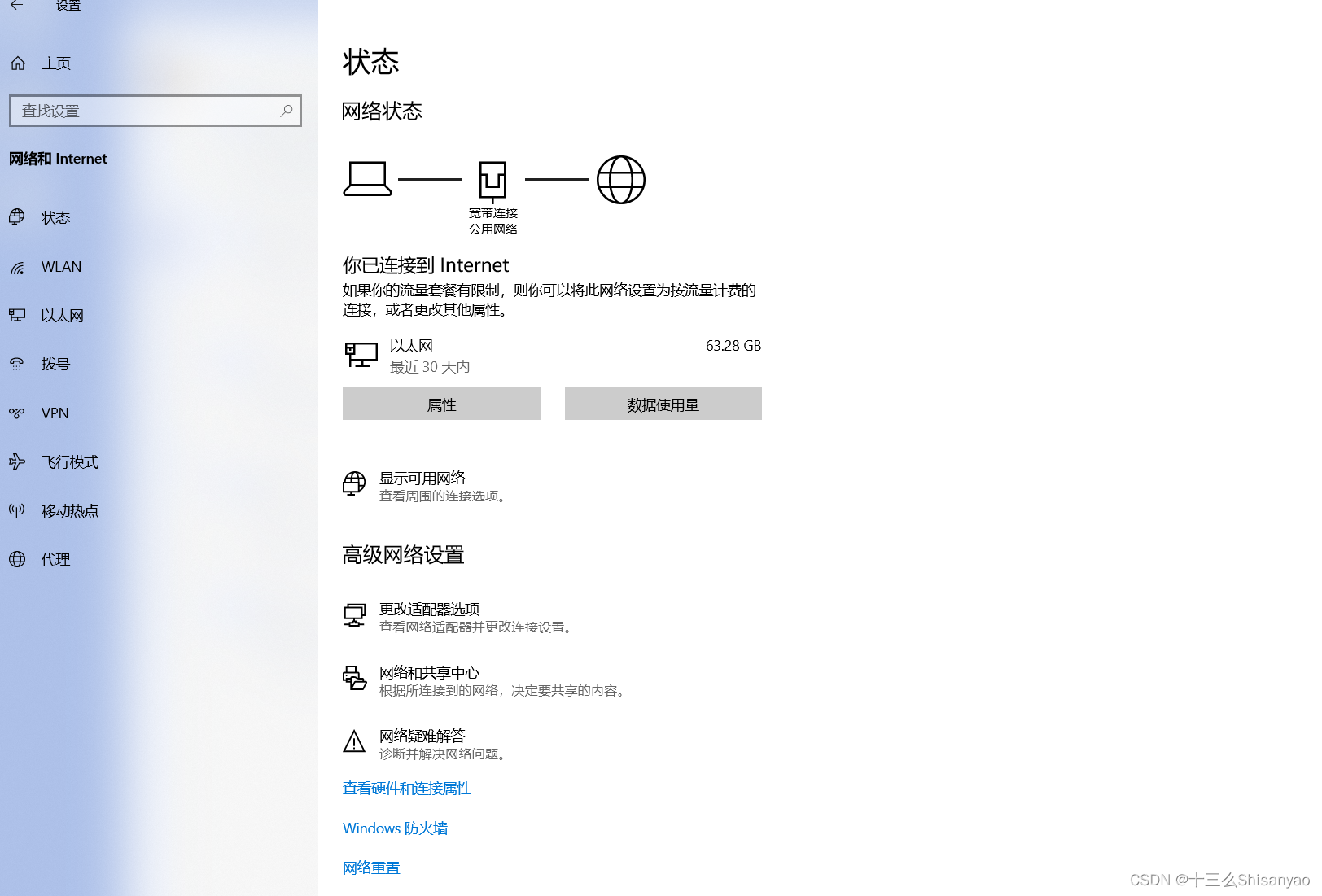
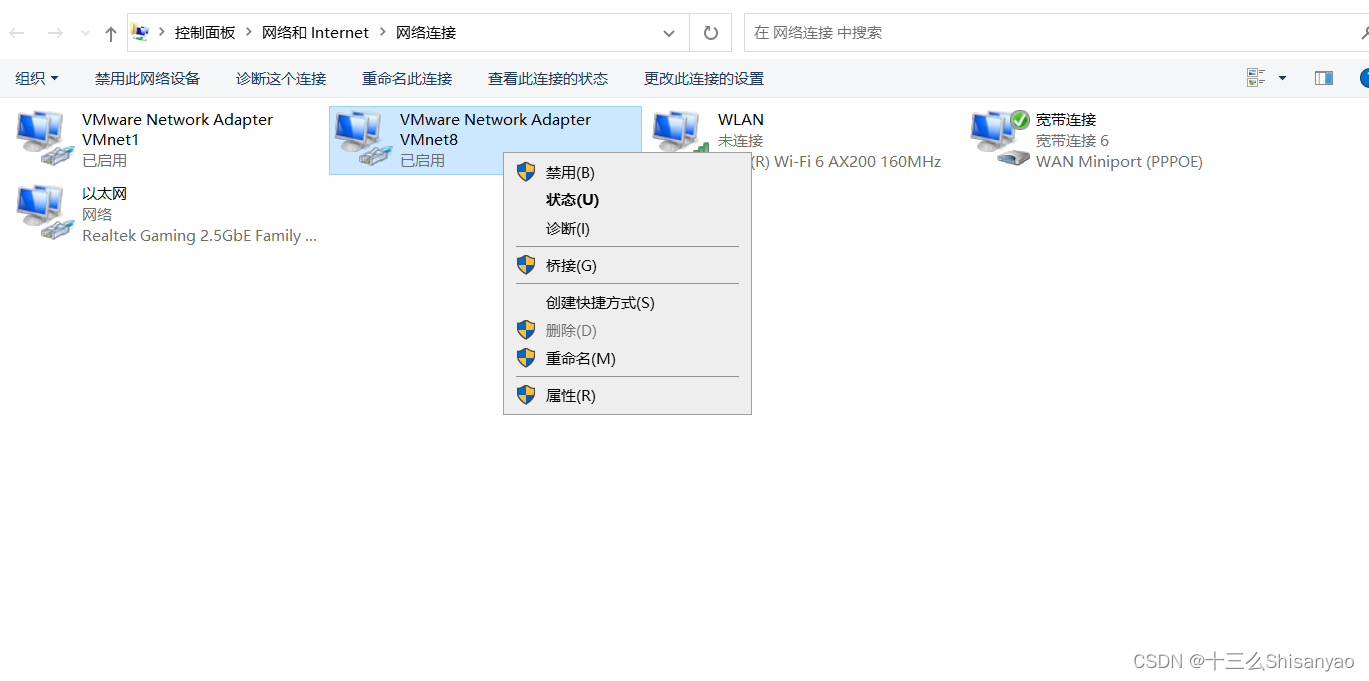
3.安装Centos
1)下载centos7镜像
下载后创建一个独立的目录,在目录下创建5个文件夹,分别是centos(固定存放centos7镜像,方便寻找)、hadoop100(模板机)、hadoop101、hadoop102、hadoop103(在之后搭建Hadoop集群需要)。
2)安装镜像
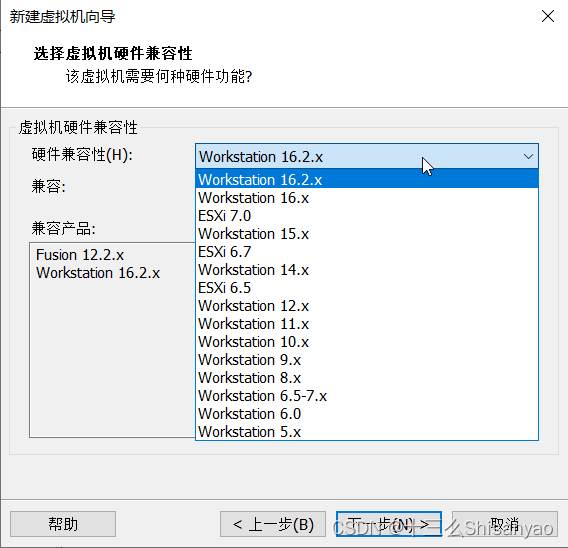
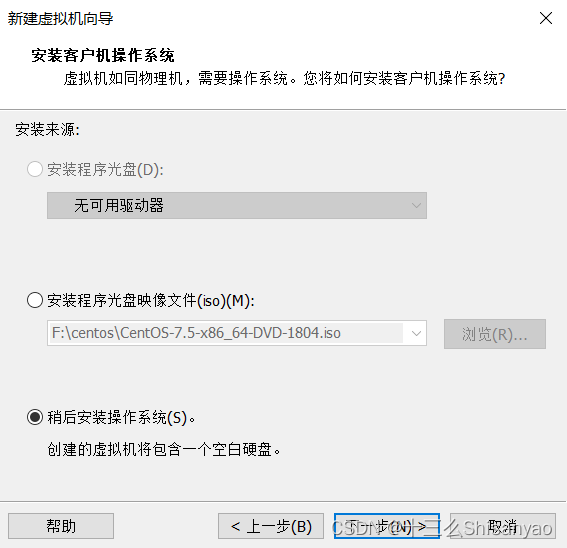
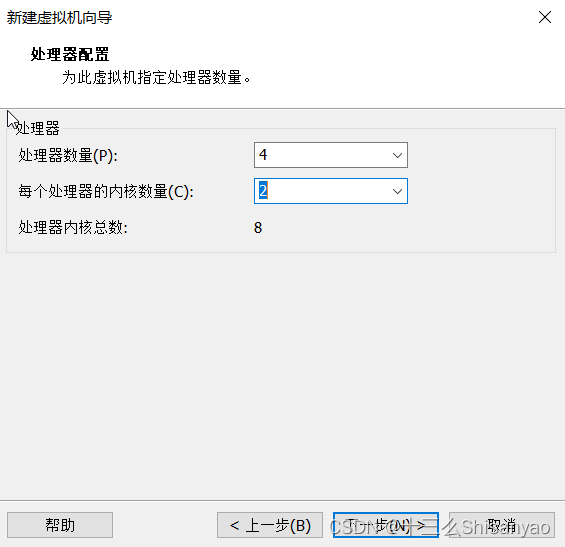
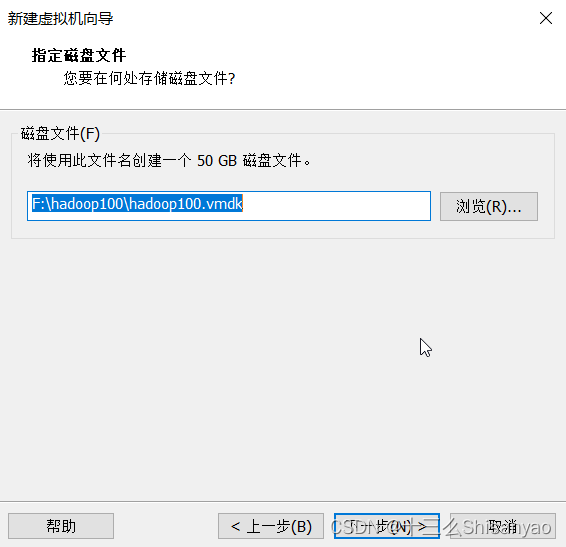
创建新的虚拟机——>自定义——>硬件兼容性选择最上面的——>选择稍后安装操作系统——>客户机操作系统选择Linux,版本选择CentOS 7 64 位——>虚拟机名称hadoop100,位置选择我们创建好的hadoop100文件夹下——>处理器配置(以8核心16线程为例)处理器数量4,每个核心数2,内核总数8(不能超过自己电脑的核心总数)——>内存设置为4g(三台机器总内存不要超过机带内存3/4),——>网络连接类型选取NAT模式——>下两步按照推荐来——>选择磁盘选取创建新虚拟磁盘——>最大磁盘大小分配50g,选择将虚拟磁盘拆分成多个文件——>指定磁盘文件保存到之前创建的hadoop100中——自定义硬件——>新CD/DVD选择镜像,使用ISO映像文件,浏览选择之前创建的centos目录下的centos7镜像——>关闭,点击完成,镜像已经安装OK


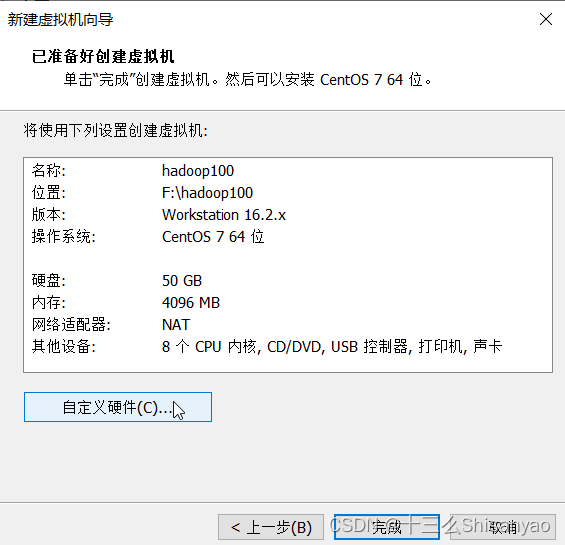
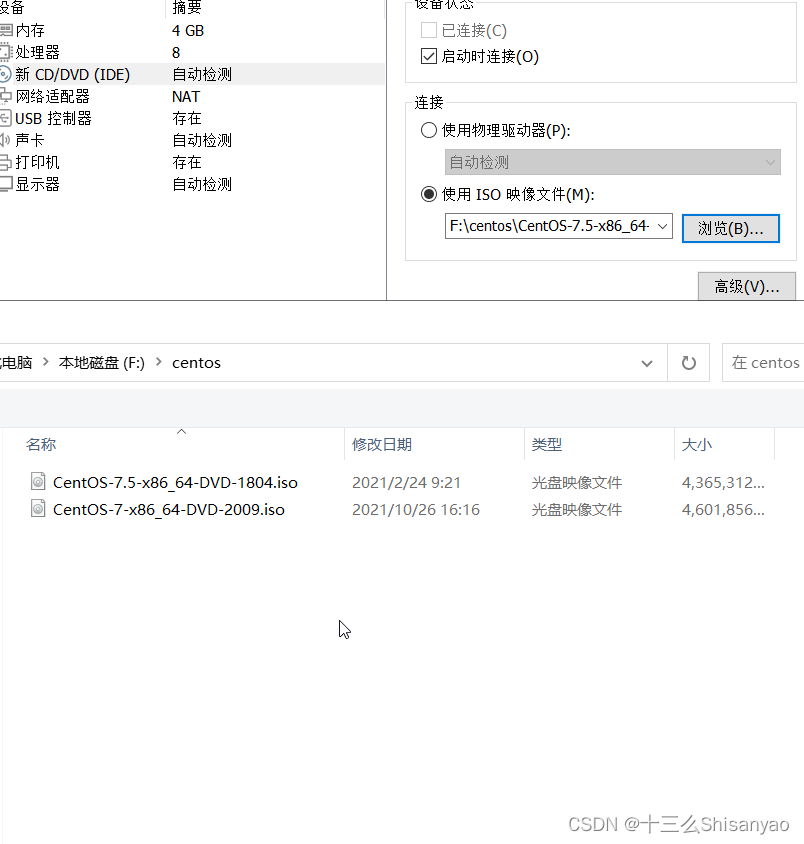
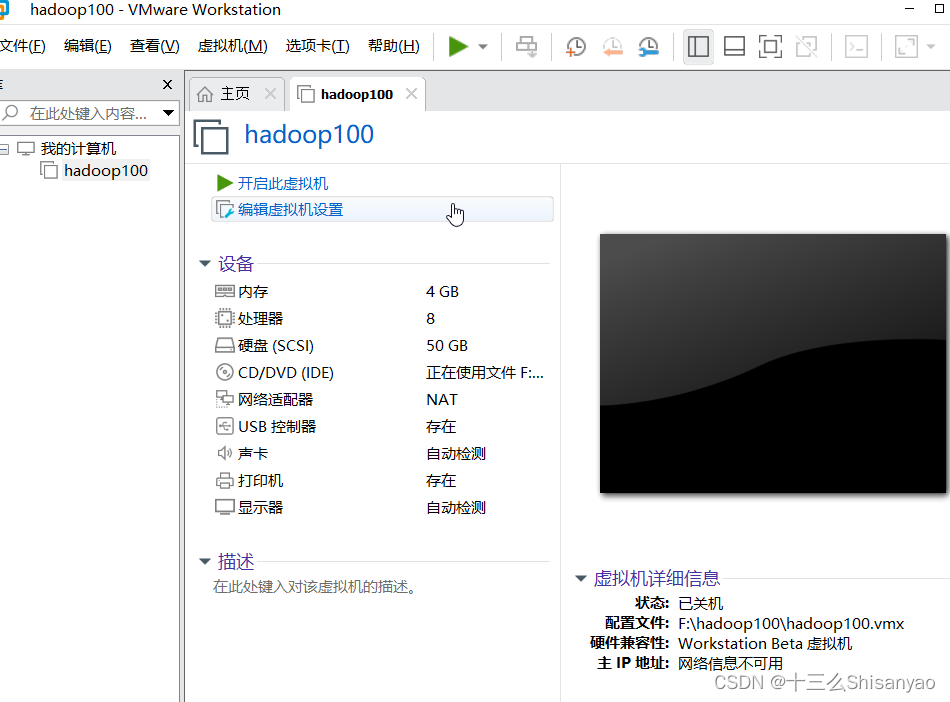
3)centos7装配
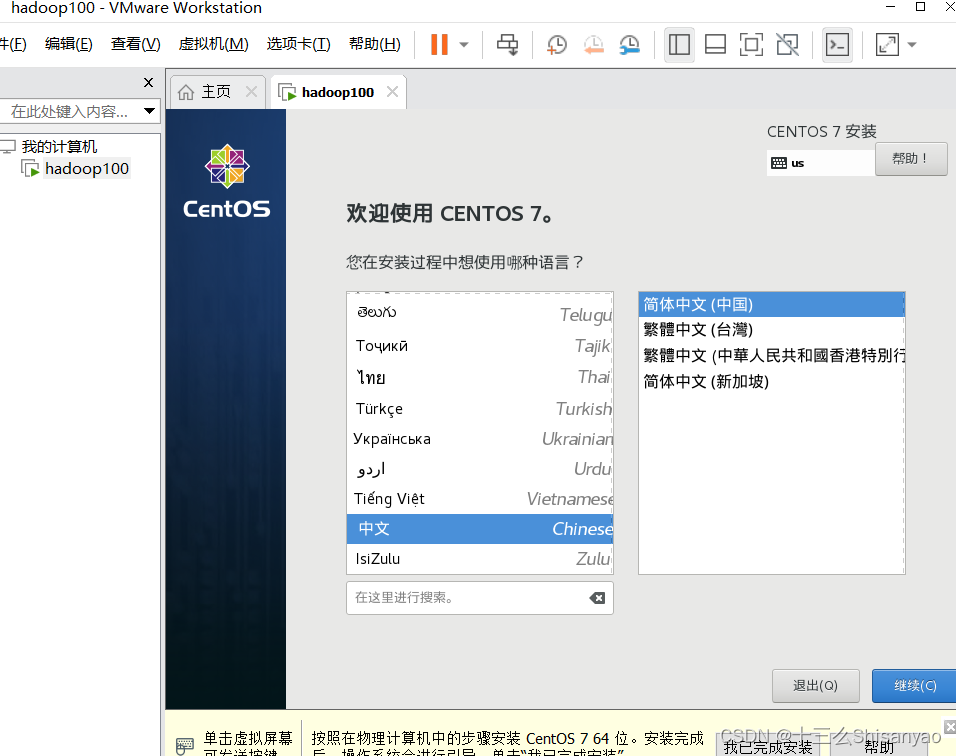
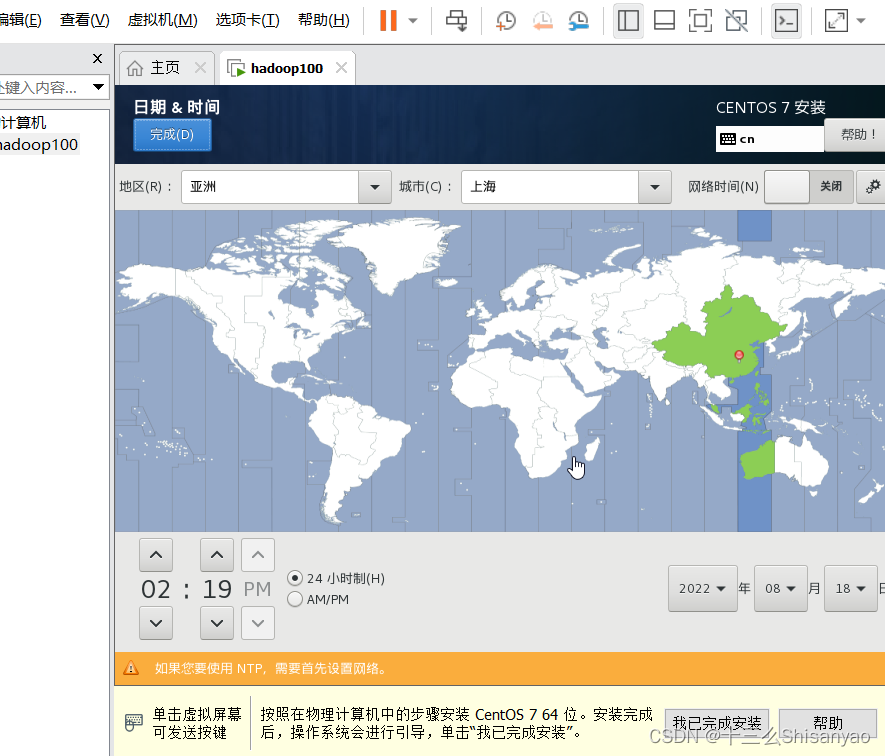
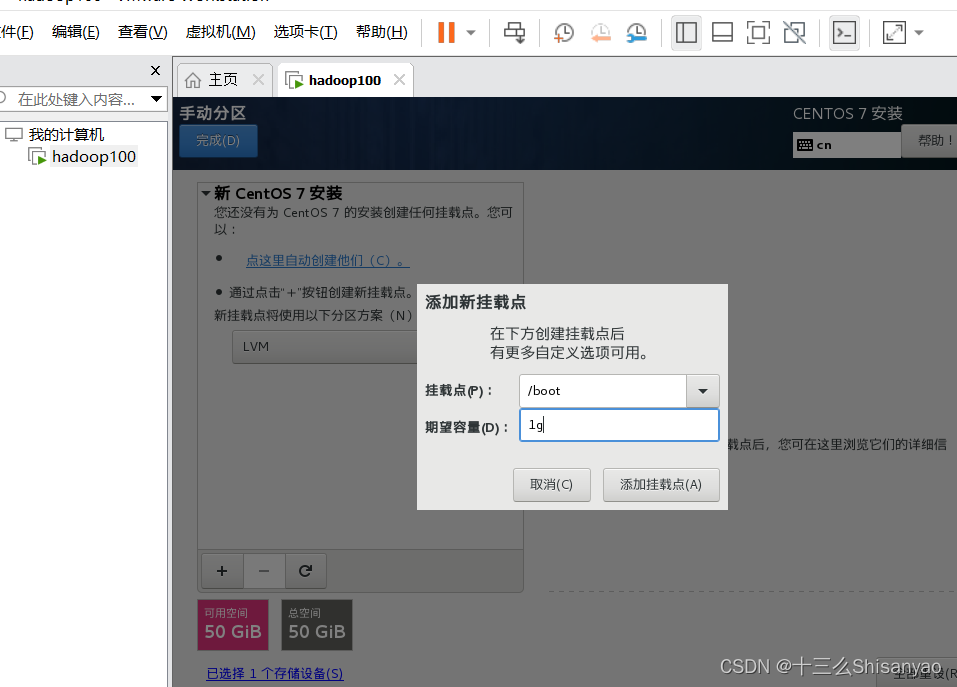
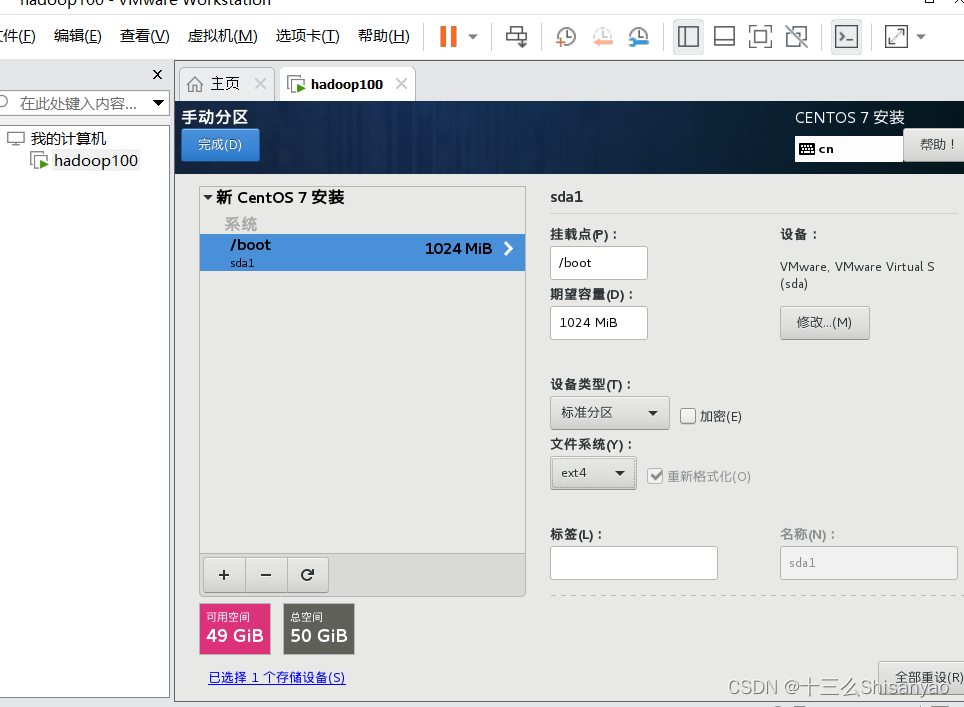
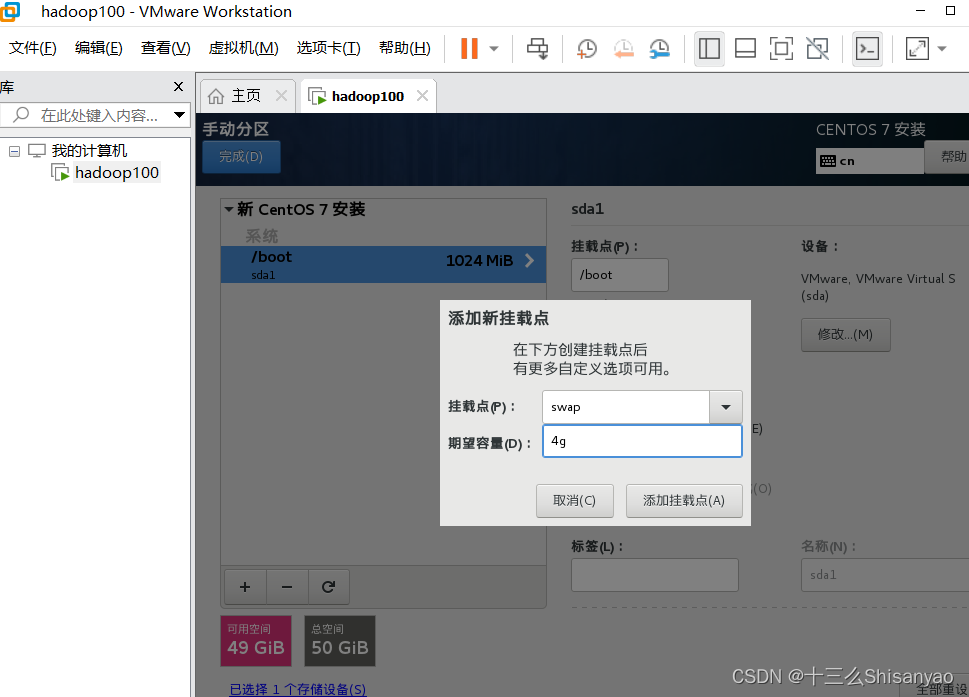
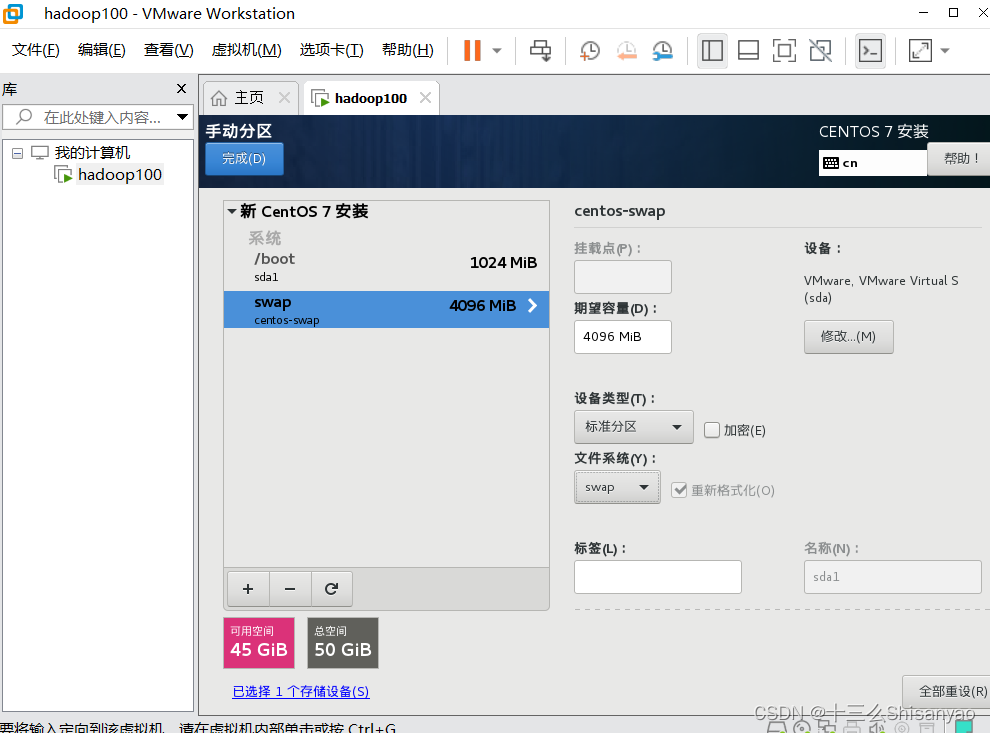
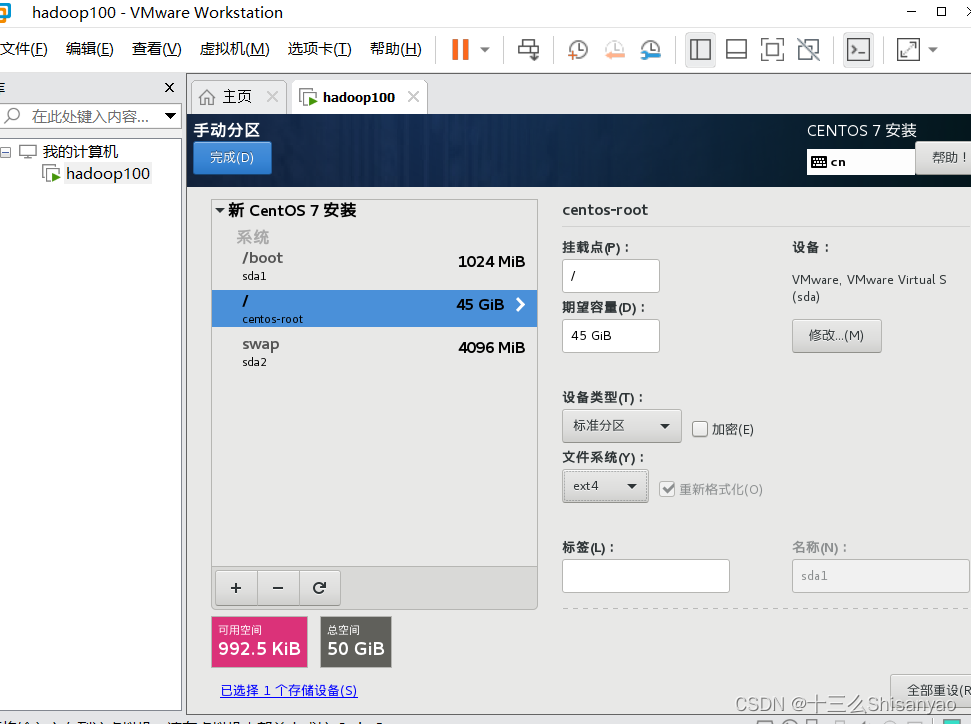
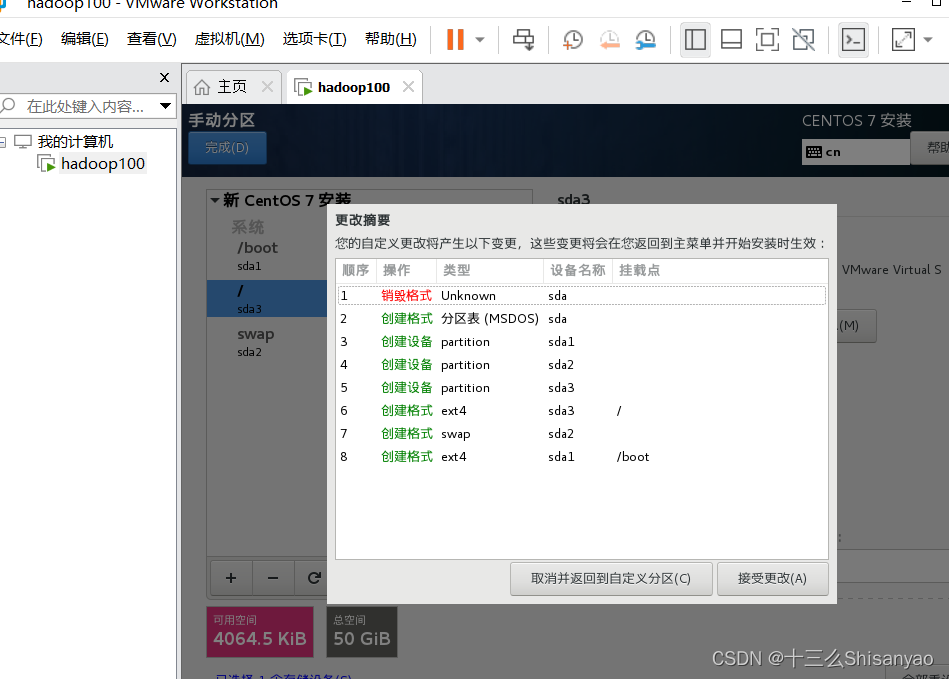
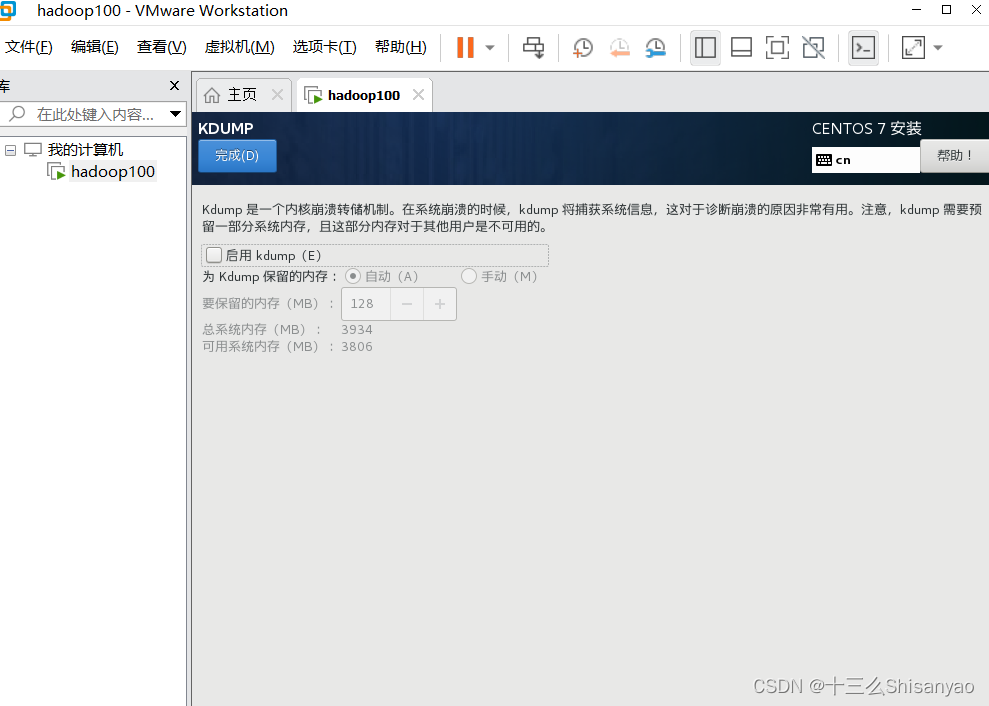
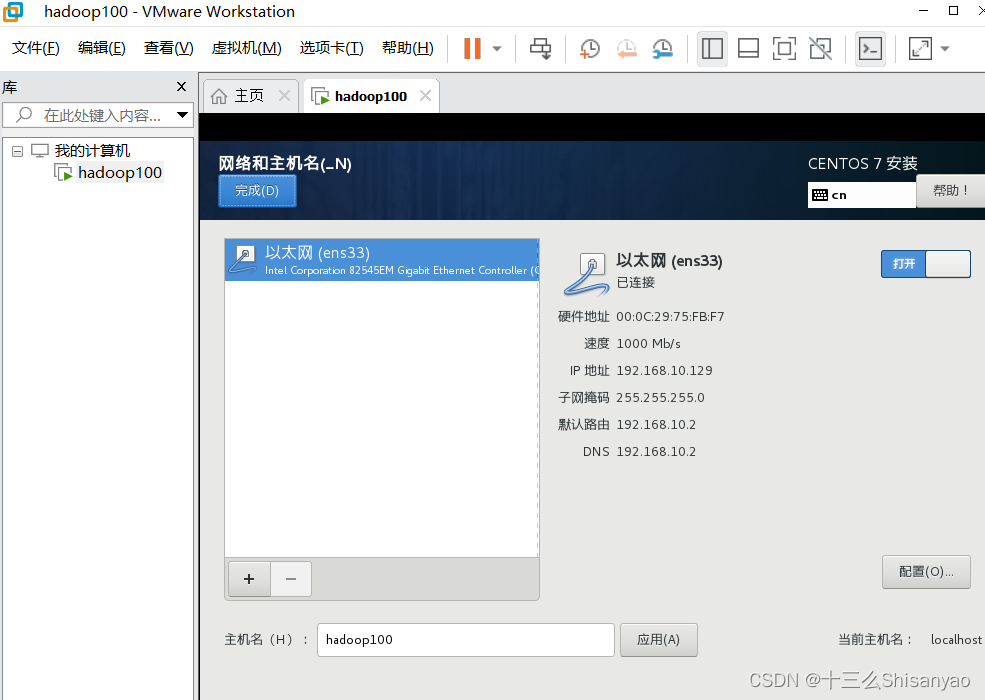
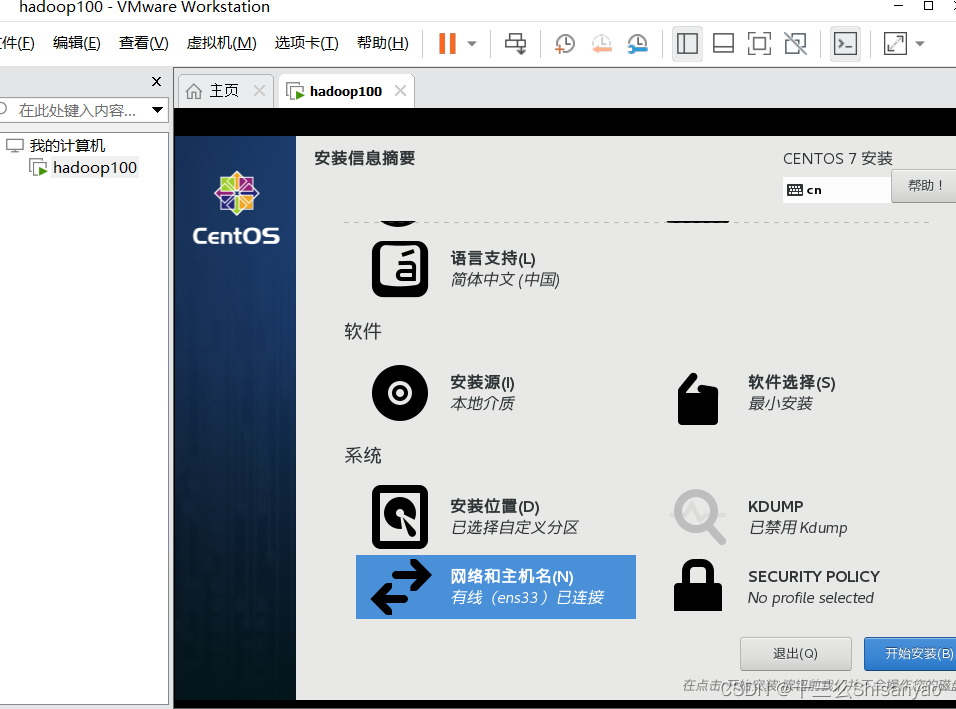
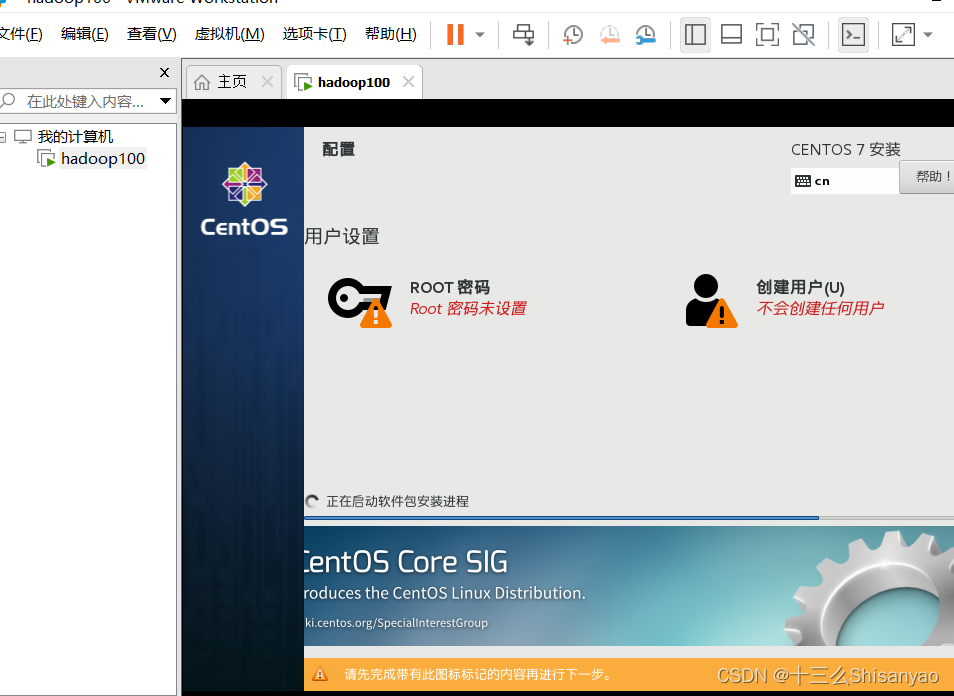
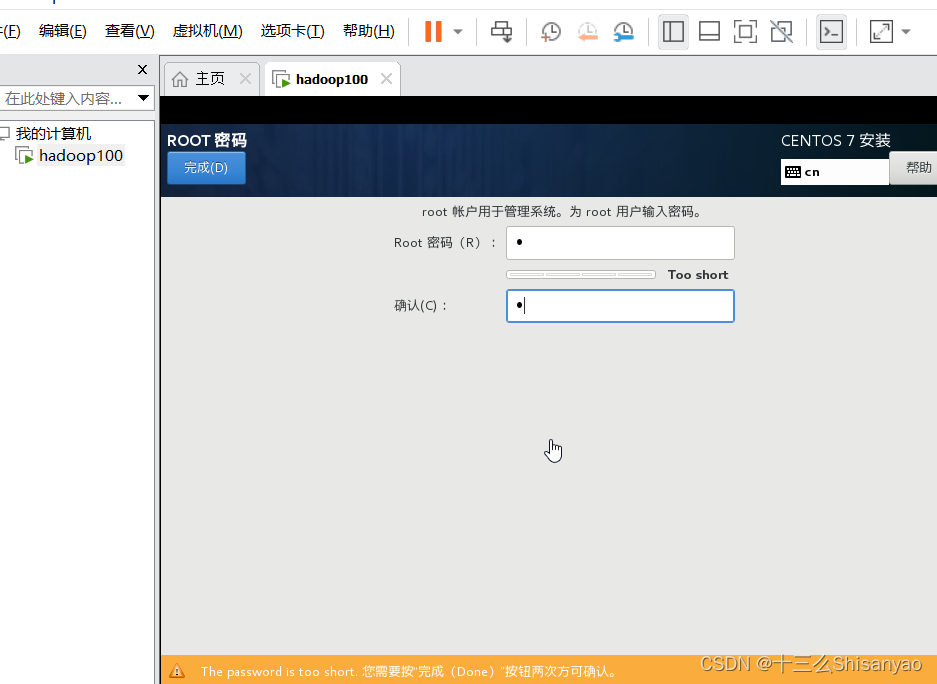
开启此虚拟机——>鼠标点进黑色窗口,不要做其他选择,直接回车,等待——>进入语言选择,鼠标选择中文——>进入安装配置页面,按顺序先设置时间,城市选择上海,时间调整与本机同步——>键盘、语言支持、安装源和软件选择都不用动(默认最小安装,节约磁盘和内存)——点击右下角+号,先添加/boot,分配1G,然后设置设备类型为标准分区,文件系统为ext4,继续添加swap分区,分配4G,设置设备类型为标准分区,文件系统为swap,继续添加/分区,分配45G,设置设备类型为标准分区,文件系统为ext4,点击完成,然后接受更改——>KDUMP默认是启用,我们将它关闭——>进行网络配置,首先打开右上角以太网,左下角将主机名改成hadoop100,完成——>点击开始安装,在等待安装过程中配置一下root密码,自己记住就行,不用创建用户(后期创建hadoop用户市创建)——>重启,安装结束
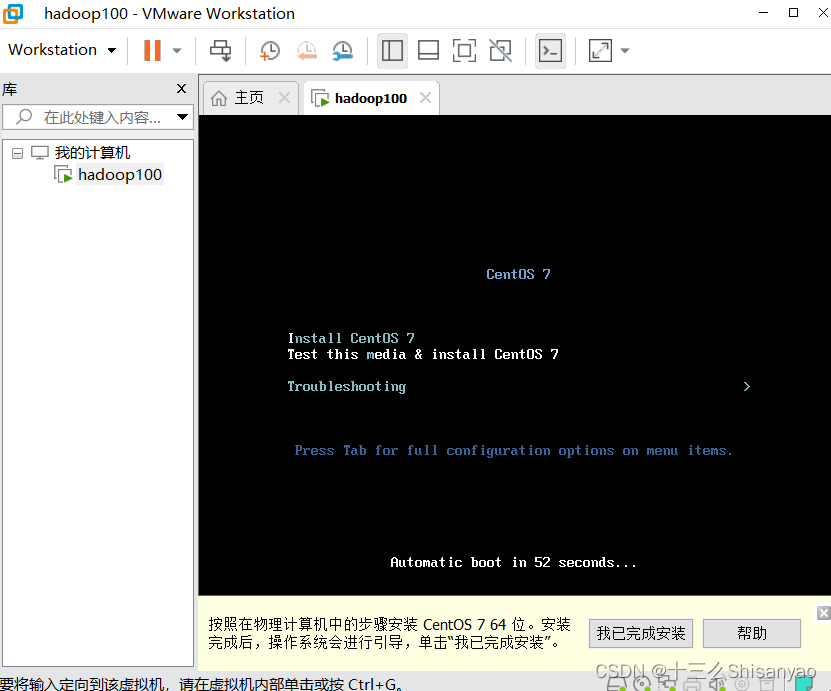
二.Hadoop模板机配置
1.基础配置
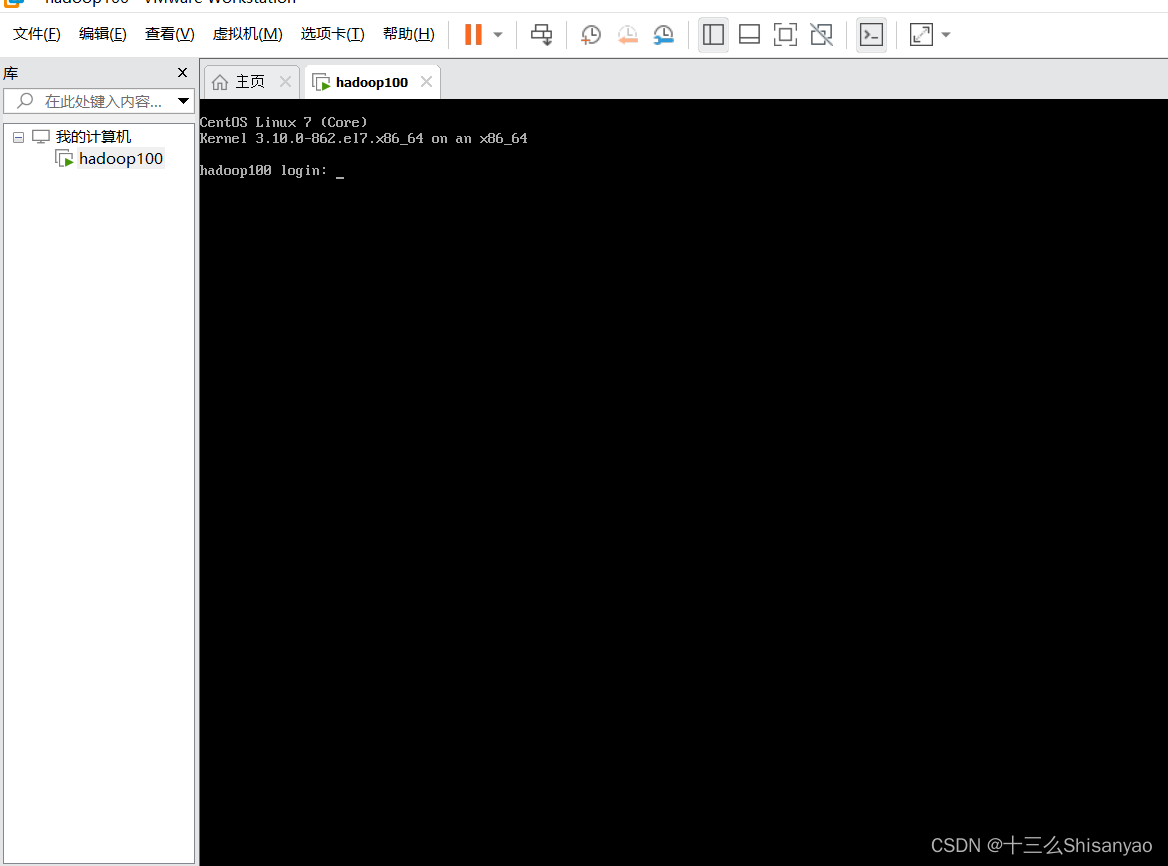
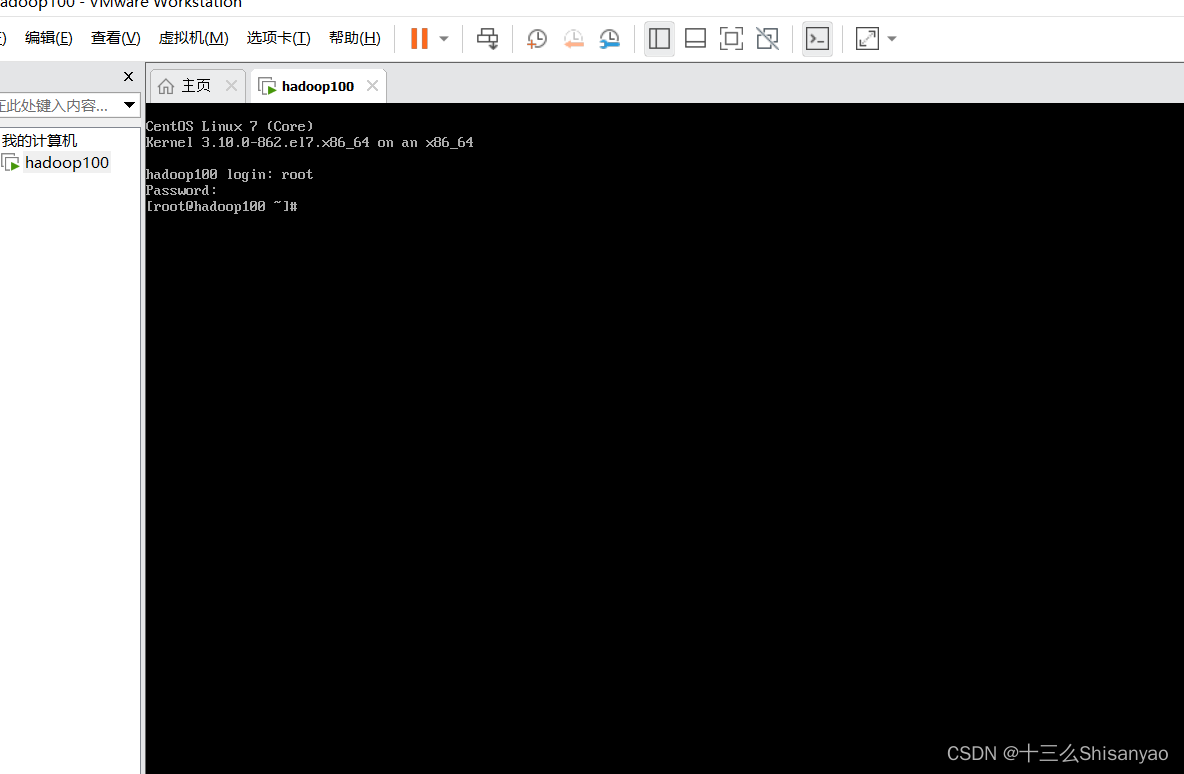
1)重启后进入登录页面,安装是为最小安装,没有图形化界面——>使用root用户登录——>登陆成功
2)网络配置
方式1:
[root@hadoop100 ~]# nmtui
-
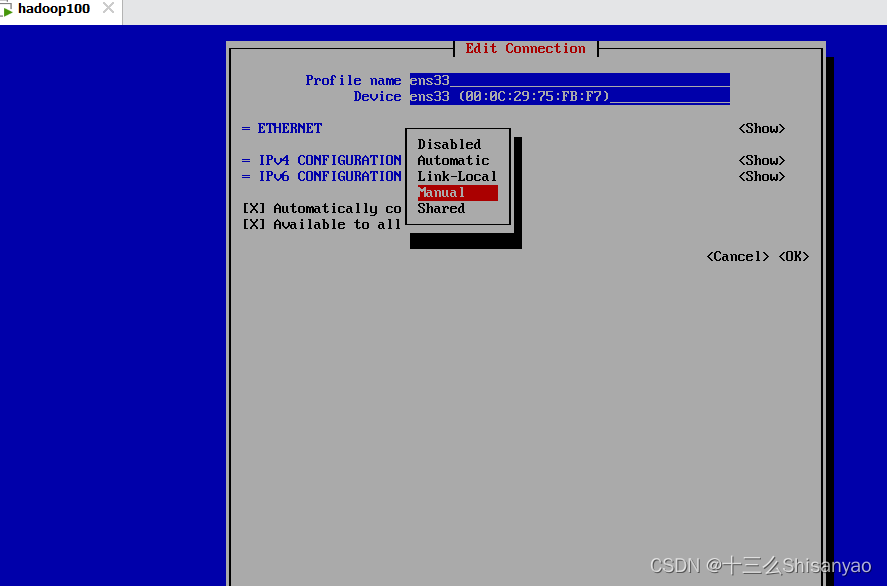
(使用上下左右进行选择)回车 Edit a connection,继续回车,选择IPv4 的Automatic回车,选择Manual,选择右侧的Show回车,选择Addresses 后的Add,填写IP地址,网段要与本机网络适配器配置的网络在同一个网段,然后修改Gateway和DNS servers都为192.168.10.2(与细腻网络配置的网关相同),右下角ok保存,back退出
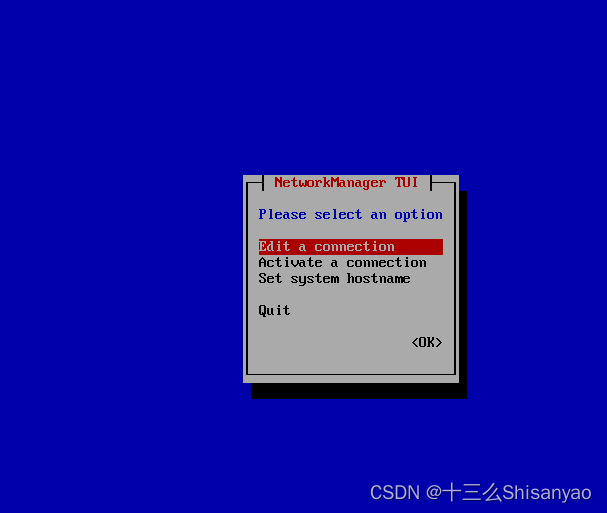
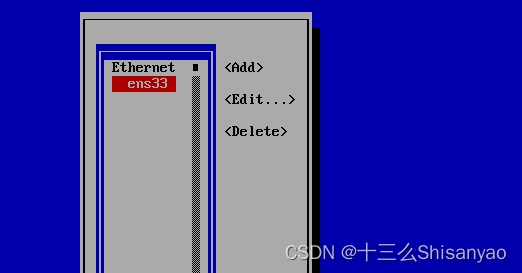

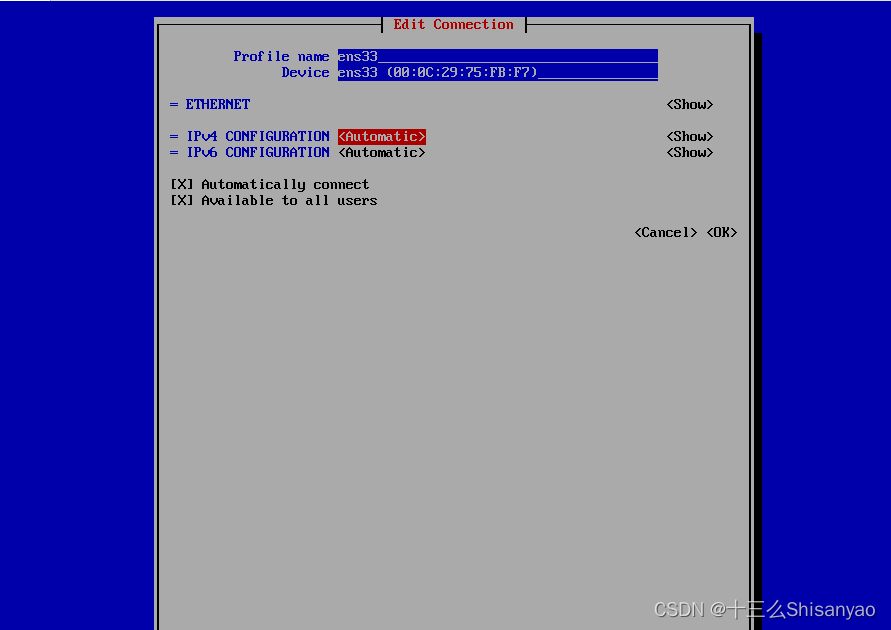

-
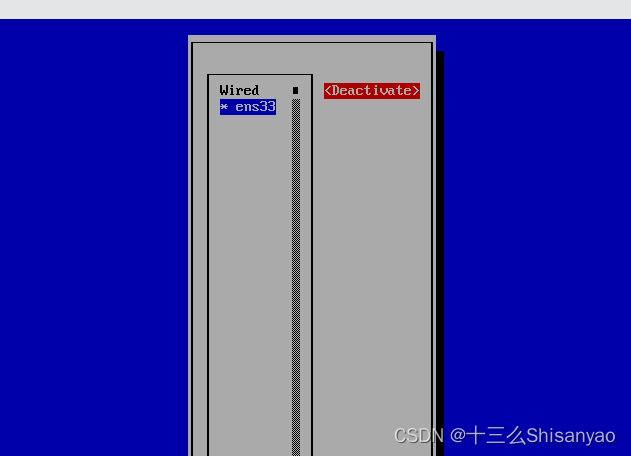
选择Active a connection 激活网络,选择Deactivate回车,变成Activate后再回车,back退出,重启机器

[root@hadoop100 ~]# reboot
- 使用命令查看网络状态,可以看到本机ip为192.168.10.100/24
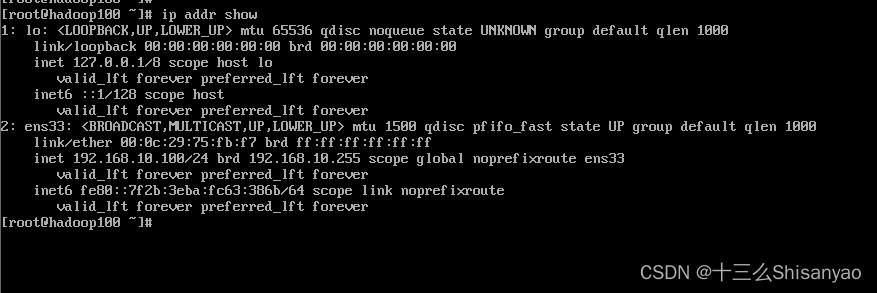
[root@hadoop100 ~]# ip addr show
检测是否可以链接外网,可以看到可以与百度ping通
ping www.baidu.com
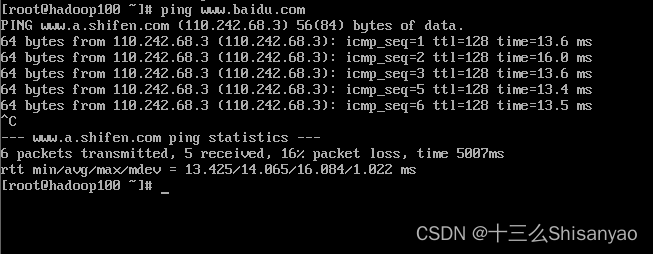
方式二:
打开网络配置文件,手动添加配置,将BOOTPROTO修改成static,在最后添加

IPADDR=192.168.10.100
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2
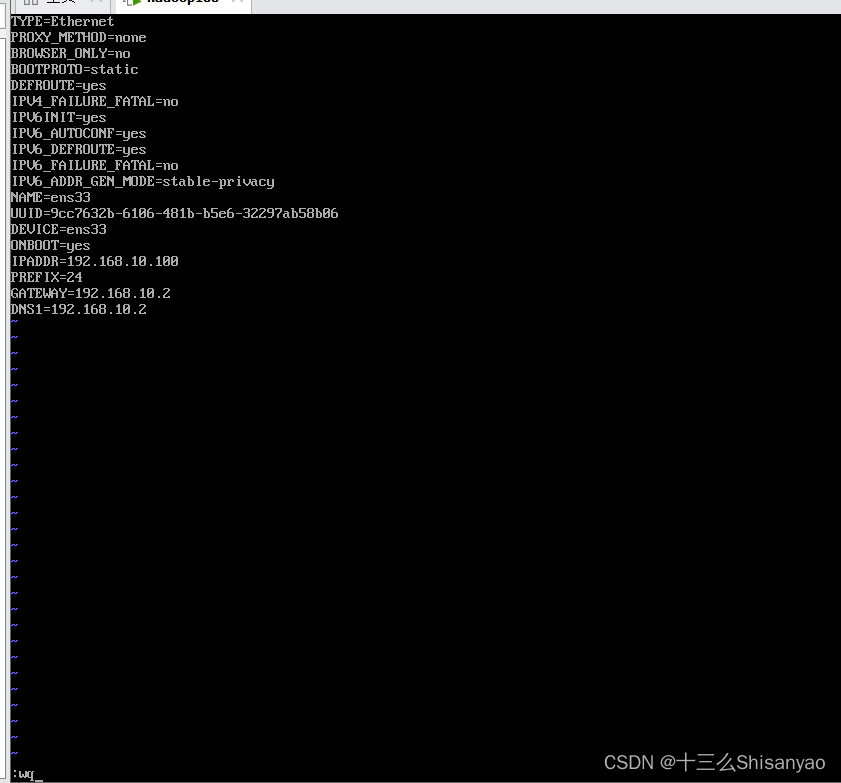
wq保存退出,reboot重启机器
2.网络配置好后,虚拟机内部操作不方便,我们使用远程工具链接虚拟机操作
先下载xshell工具https://www.xshellcn.com/xiazai.html下载Xmanger Power,随便填写下载后百度破解
先修改window和centos中的hosts文件
使用记事本打开windows中C:\Windows\System32\drivers\etc\hosts,添加如下内容
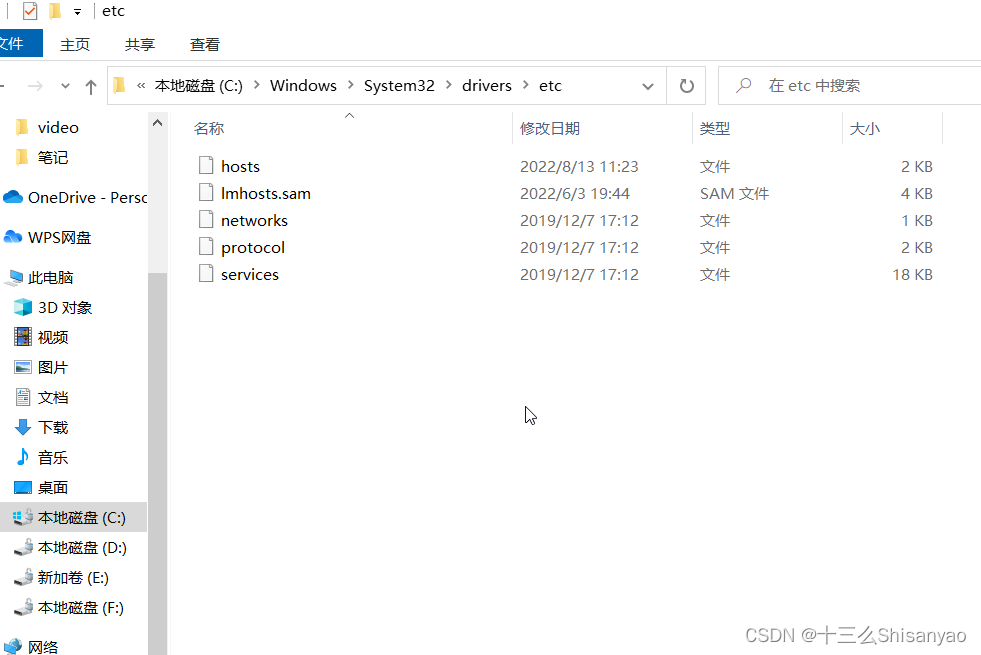
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.106 hadoop102
192.168.10.103 hadoop103

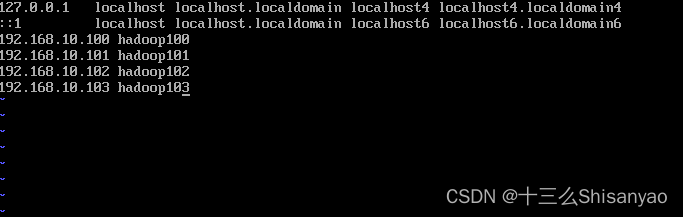
使用命令打开centos中的hosts文件,在文件最下面添加
[root@hadoop100 ~]# vi /etc/hosts

192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.106 hadoop102
192.168.10.103 hadoop103
重启机器
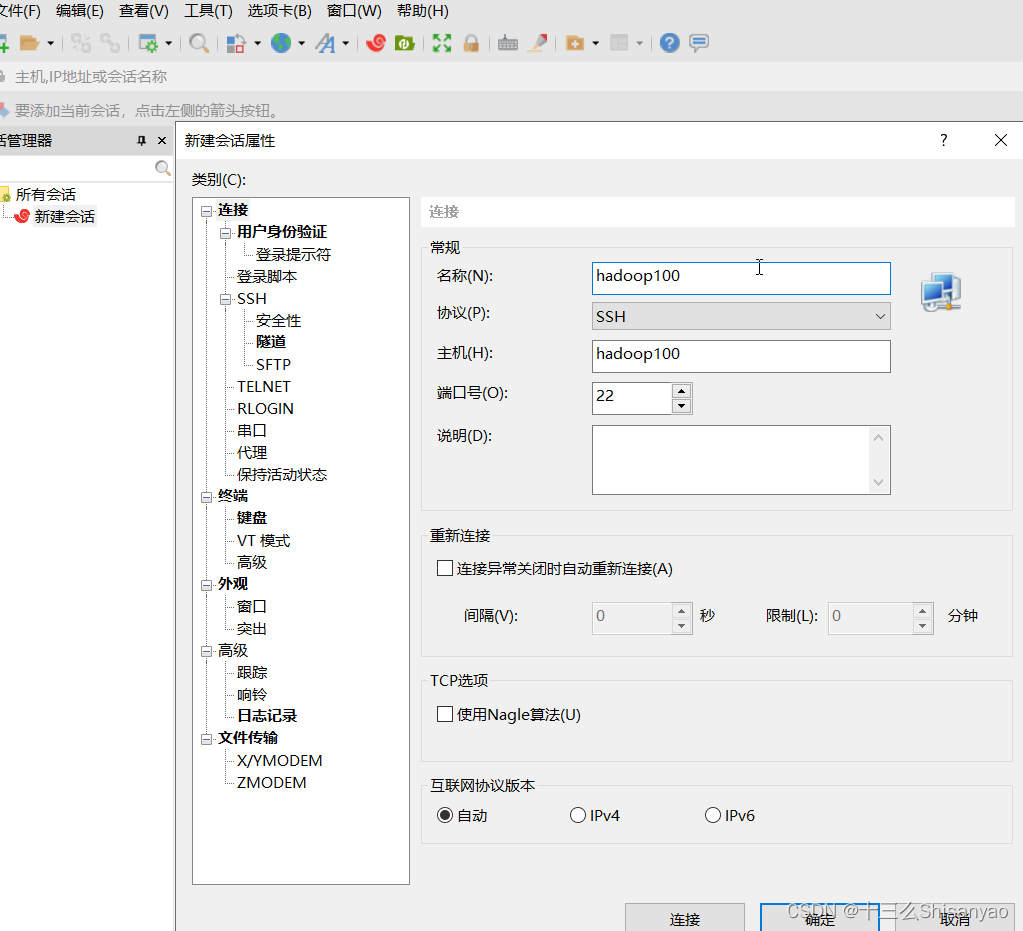
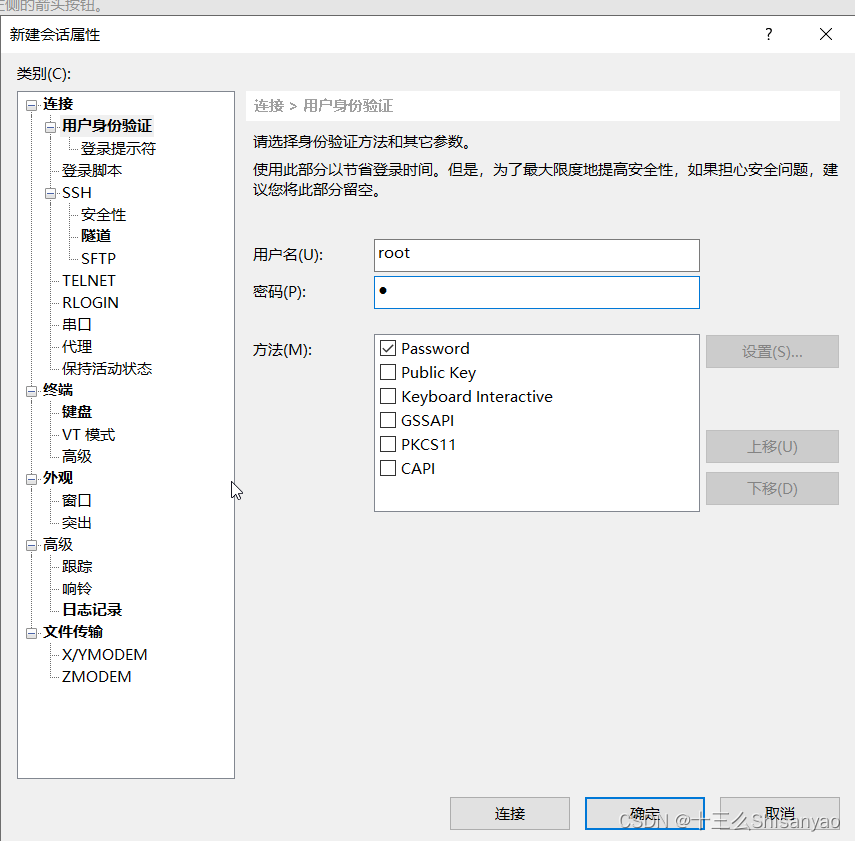
重启后,回到windows中打开Xshell工具,左上角新建会话,因为上边配置了hosts,所以windows和hadoop机器产生了映射关系,直接在主机输入hadoop100就可以了知道hadoop100的ip,点击用户身份验证输入root用户名密码,连接,跳出验证主机秘钥,选择接受并保存,登陆成功
3.模板虚拟机依赖工具下载
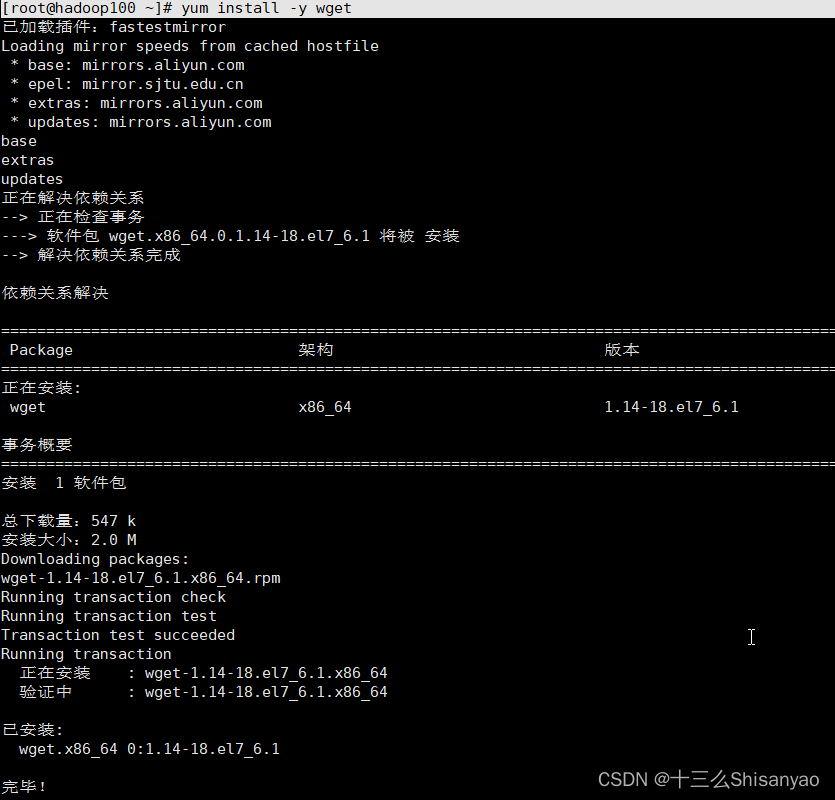
1)先下载wget,方便修改yum源
[root@hadoop100 ~]# yum install -y wget
2)修改网络YUM源
备份原来的yum文件
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo_bak
下载阿里云的 CentOS-Base.repo 到/etc/yum.repos.d/
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
或
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
清空原本yum缓存
yum clean all
生成新的阿里云的yum缓存,加速下载预热数据
yum makecache
3)安装epel-release
Extra Packages for Enterprise Linux是为“红帽系”的操作系统提供额外的软件包,相当于是一个软件仓库,大多数rpm包在官方 repository 中是找不到的
[root@hadoop100 ~]# yum install -y epel-release
4)安装后期学习使用的工具包,如vim,ntp,nc…
[root@hadoop100 ~]# yum install -y net-tools vim psmisc nc rsync lrzsz ntp libzstd openssl-static tree iotop git nano
4.关闭防火墙,关闭防火墙开机自启
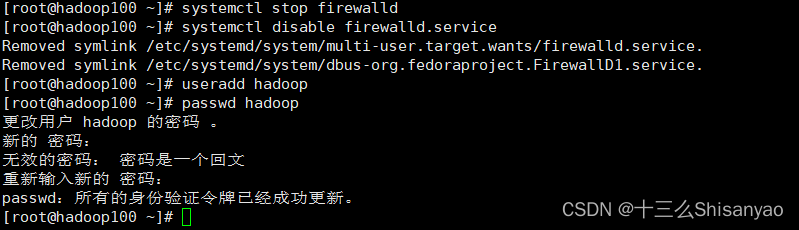
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld.service

5.创建hadoop用户,并修改hadoop用户的密码
[root@hadoop100 ~]# useradd hadoop
[root@hadoop100 ~]# passwd hadoop
6.配置atguigu用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers
在root ALL=(ALL) ALL下添加
hadoop ALL=(ALL) NOPASSWD:ALL
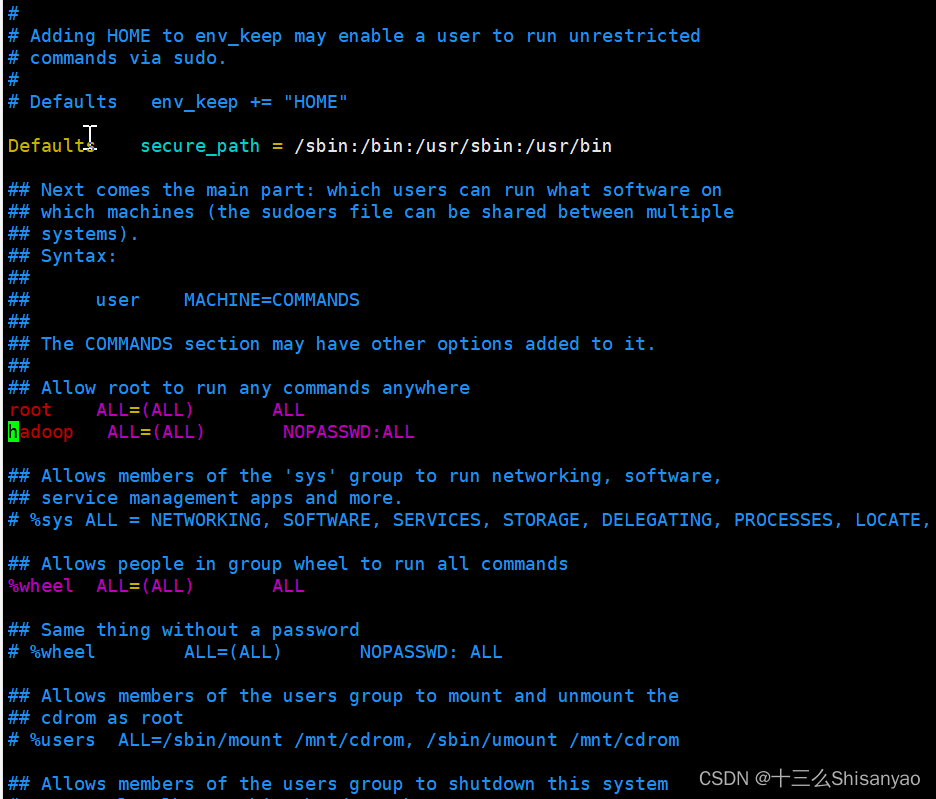
此文件为只读文件,所以退出时用wq!强制执行保存退出
7.创建软件安装目录
在/opt目录下创建文件夹,并修改所属主和所属组
1)在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
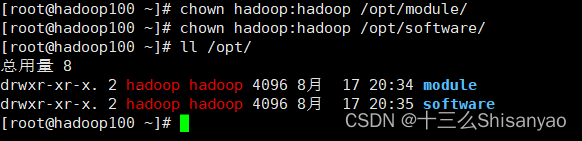
2)修改module、software文件夹的所有者和所属组均为hadoop用户,查看module、software文件夹的所有者和所属组
[root@hadoop100 ~]# chown hadoop:hadoop /opt/module/
[root@hadoop100 ~]# chown hadoop:hadoop /opt/software/
[root@hadoop100 ~]# ll /opt/
注:如果 安装的是桌面版的,需要先卸载虚拟机自带的java
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
环境配置好之后,关机。
三.Hadoop单机版搭建
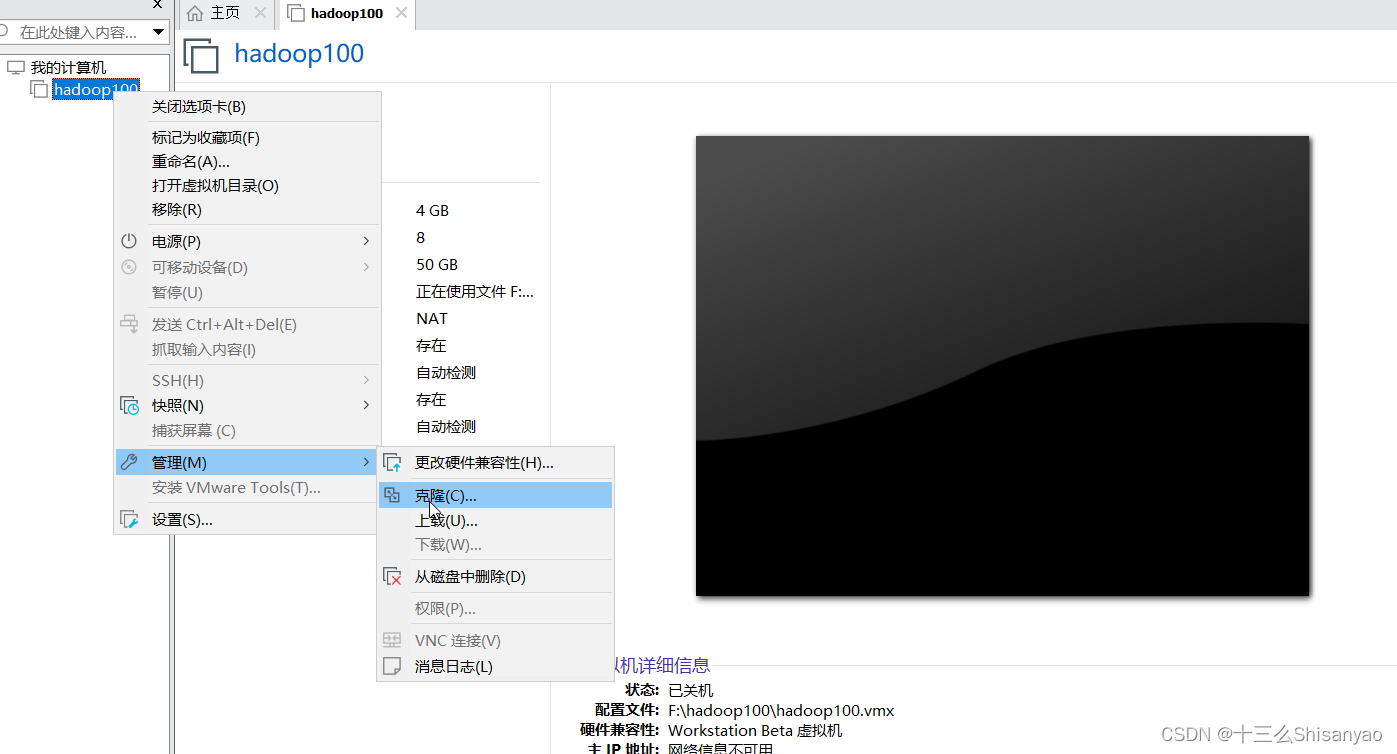
1.根据模板机hadoop100克隆虚拟机hadoop101——>创建完整克隆——>修改克隆机名称为hadoop101,保存位置为之前创建的hadoop101目录下
2.克隆后开启hadoop101,修改克隆机配置,和之前的hadoop100同理
要设置主机名(hadoop100在创建时就直接改了),Set system hostname 回车,ok保存,修改IP并激活,重启机器,使用命令查看机器网络配置
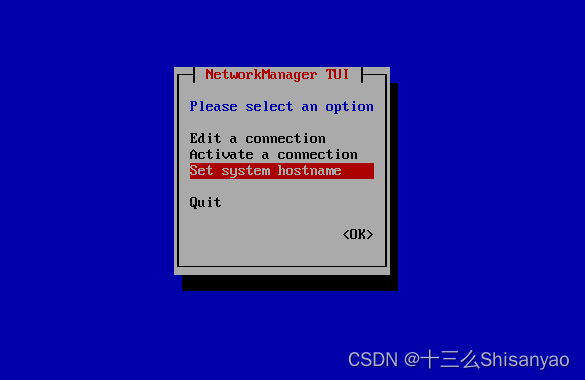
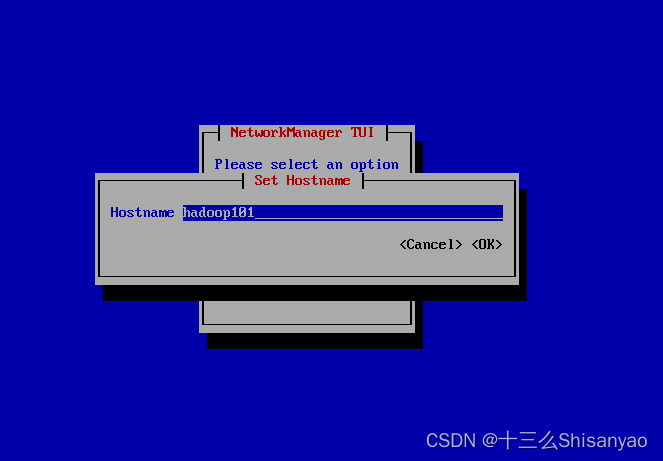
[root@hadoop100 ~]# ifconfig
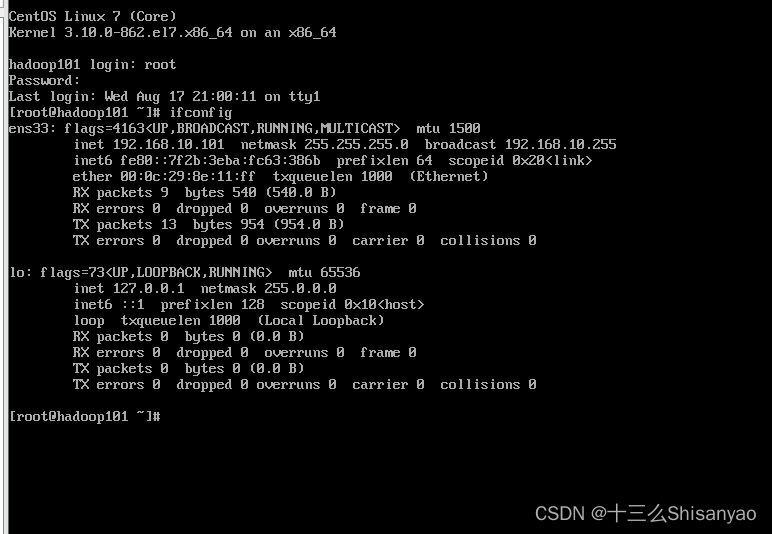
可以看到主机名和ip已经更新
3.在hadoop101安装JDK
1)用Xftp传输工具将JDK导入到opt目录下面的software文件夹下面
Xftp链接虚拟机连接虚拟机和Xshell相同
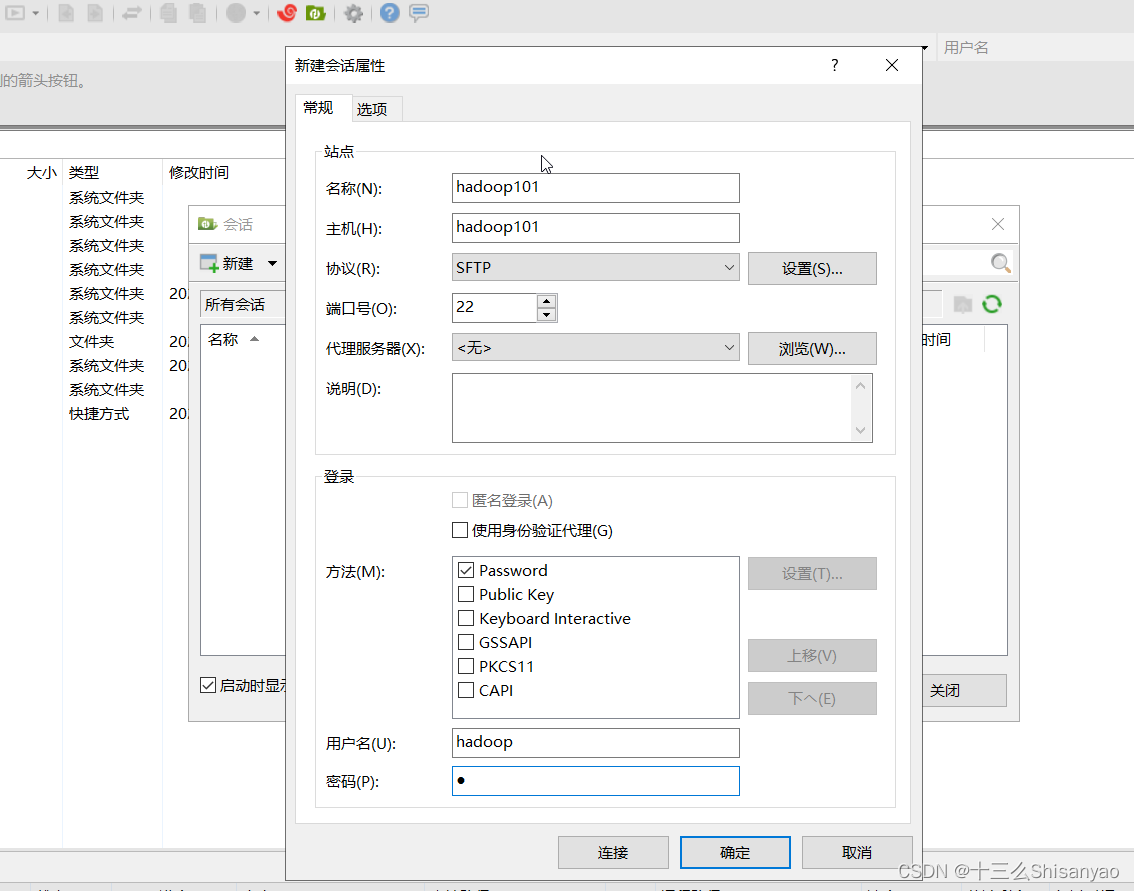
下载JDK和Hadoop的tar包
JDK1.8下载地址:https://www.oracle.com/java/technologies/downloads/#license-lightbox
Hadoop3下载地址:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.4/hadoop-3.2.4-src.tar.gz
直接拖动tar包到/opt/software下
Xshell中使用hadoop账户登录hadoop101,查看目录下是否有文件

[hadoop@hadoop101 software]$ ll
2)安装JDK
先解压JDK tar包到/opt/module下
[hadoop@hadoop101 software]$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
3)配置JDK环境变量
1)新建/etc/profile.d/my_env.sh文件
[hadoop@hadoop101 ~]$ sudo touch /etc/profile.d/my_env.sh
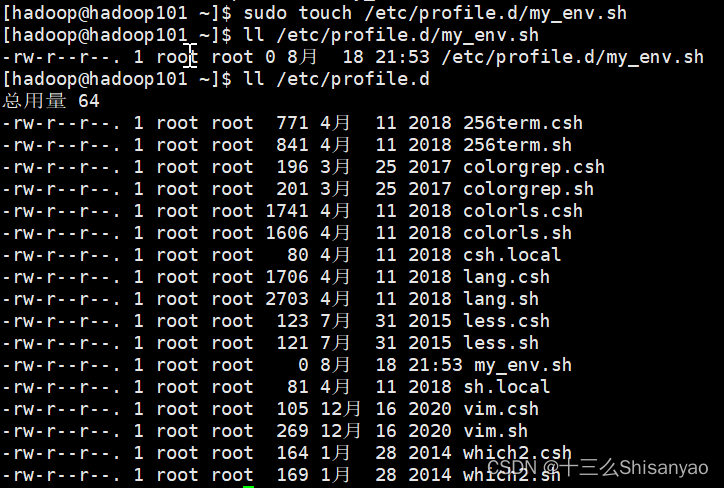
在新建的my_env.sh中配置java环境变量
[hadoop@hadoop101 ~]$ sudo vim /etc/profile.d/my_env.sh
添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
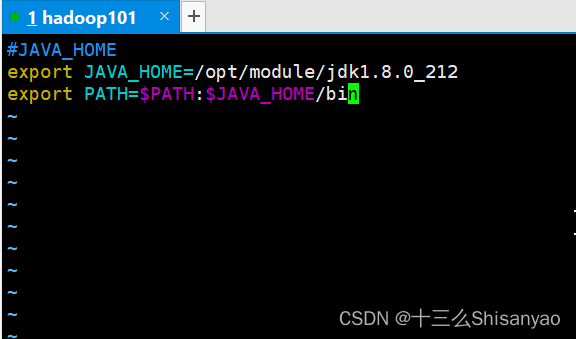
2)source一下/etc/profile文件,让新的环境变量PATH生效
[hadoop@hadoop101 ~]$ source /etc/profile

3)测试JDK是否安装成功
[hadoop@hadoop101 ~]$ java -version

4.在hadoop101安装Hadoop
将Hadoop和JDK将tar包放到/opt/software下
1)安装Hadoop
先解压JDK tar包到/opt/module下
[hadoop@hadoop101 ~]$ tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/

2)配置Hadoop环境变量
1)打开/etc/profile.d/my_env.sh文件
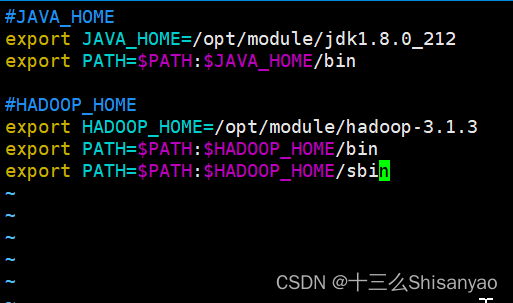
[hadoop@hadoop101 ~]$ sudo vim /etc/profile.d/my_env.sh
在my_env.sh文件末尾添加如下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
2)source一下/etc/profile文件,让新的环境变量PATH生效
[hadoop@hadoop101 ~]$ source /etc/profile
3)测试是否安装成功
[hadoop@hadoop101 ~]$ hadoop version

四.测试Hadoop本地运行模式
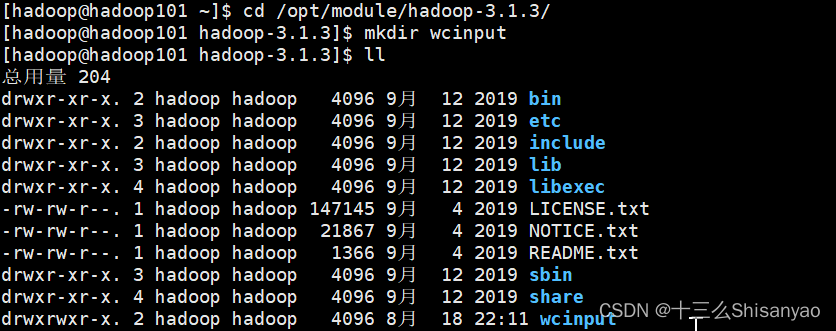
1.创建在hadoop-3.1.3文件下面创建一个wcinput文件夹
[hadoop@hadoop101 ~]$ cd /opt/module/hadoop-3.1.3/
[hadoop@hadoop101 hadoop-3.1.3]$ mkdir wcinput
[hadoop@hadoop101 hadoop-3.1.3]$ ll
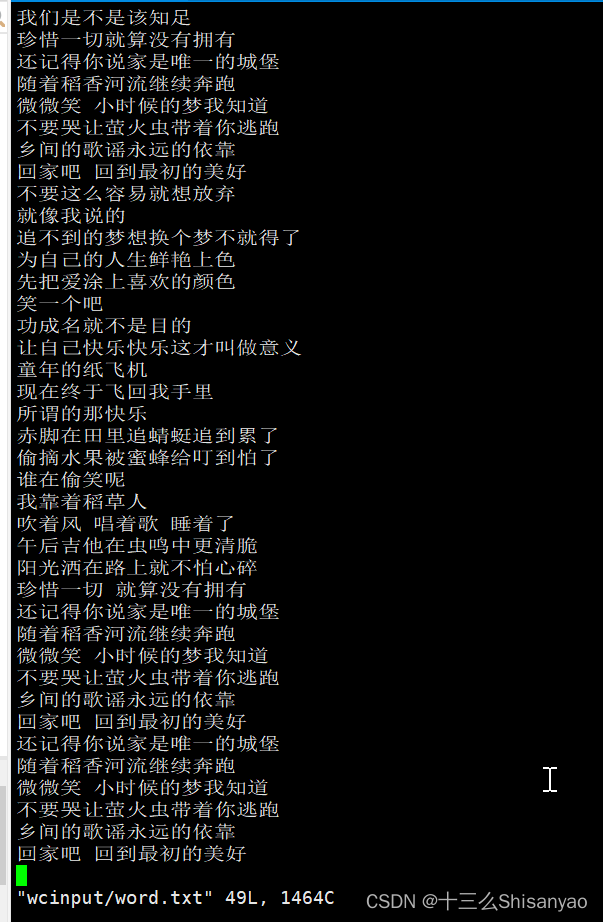
2.在wcinput文件下创建一个word.txt文件
[hadoop@hadoop101 hadoop-3.1.3]$ touch wcinput/word.txt
[hadoop@hadoop101 hadoop-3.1.3]$ vim wcinput/word.txt

在文件中输入如下内容
稻香 - 周杰伦 (Jay Chou)
词:周杰伦
曲:周杰伦
编曲:黄雨勋
对这个世界如果你有太多的抱怨
跌倒了就不敢继续往前走
为什么人要这么的脆弱堕落
请你打开电视看看
多少人为生命在努力勇敢的走下去
我们是不是该知足
珍惜一切就算没有拥有
还记得你说家是唯一的城堡
随着稻香河流继续奔跑
微微笑 小时候的梦我知道
不要哭让萤火虫带着你逃跑
乡间的歌谣永远的依靠
回家吧 回到最初的美好
不要这么容易就想放弃
就像我说的
追不到的梦想换个梦不就得了
为自己的人生鲜艳上色
先把爱涂上喜欢的颜色
笑一个吧
功成名就不是目的
让自己快乐快乐这才叫做意义
童年的纸飞机
现在终于飞回我手里
所谓的那快乐
赤脚在田里追蜻蜓追到累了
偷摘水果被蜜蜂给叮到怕了
谁在偷笑呢
我靠着稻草人
吹着风 唱着歌 睡着了
午后吉他在虫鸣中更清脆
阳光洒在路上就不怕心碎
珍惜一切 就算没有拥有
还记得你说家是唯一的城堡
随着稻香河流继续奔跑
微微笑 小时候的梦我知道
不要哭让萤火虫带着你逃跑
乡间的歌谣永远的依靠
回家吧 回到最初的美好
还记得你说家是唯一的城堡
随着稻香河流继续奔跑
微微笑 小时候的梦我知道
不要哭让萤火虫带着你逃跑
乡间的歌谣永远的依靠
回家吧 回到最初的美好
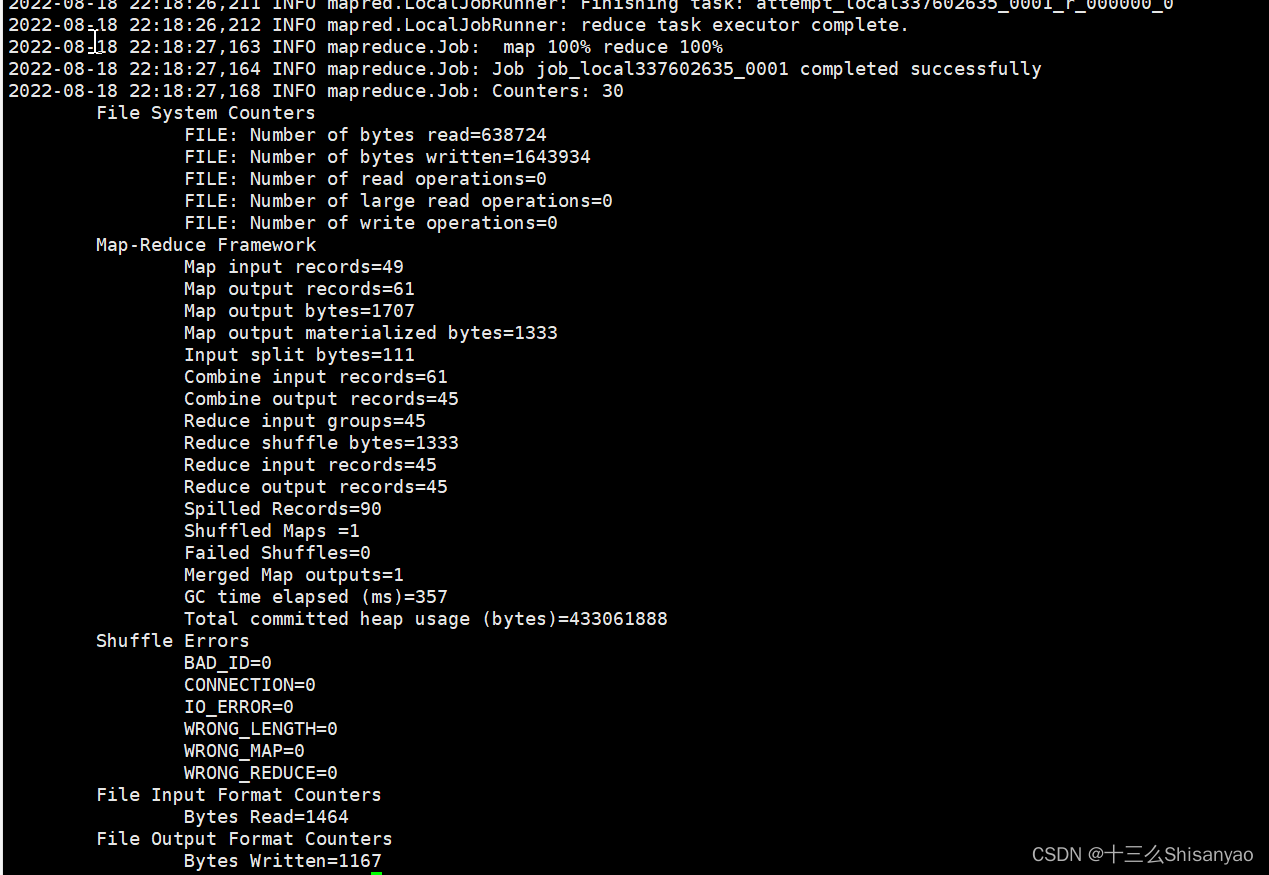
3.执行程序
[hadoop@hadoop101 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput

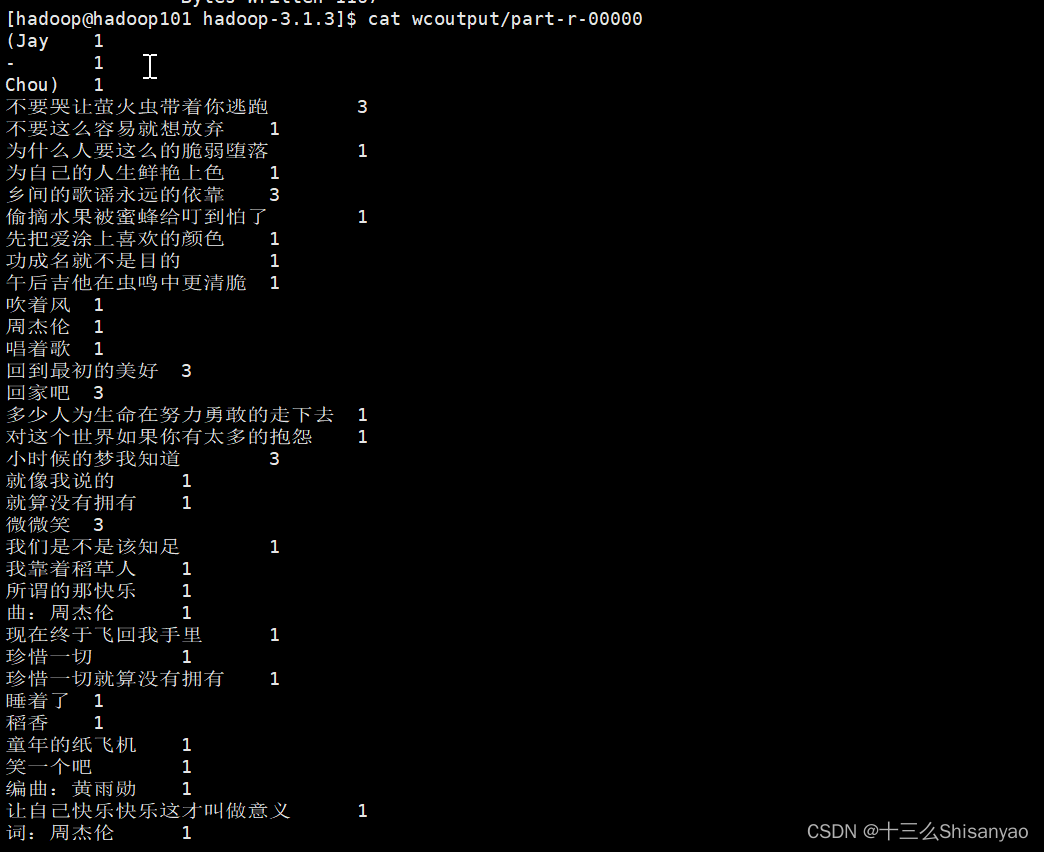
4.查看结果
[hadoop@hadoop101 hadoop-3.1.3]$ cat wcoutput/part-r-00000

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)