Mysql数据库千万级数据查询优化方案
Mysql数据库中一个表里有一千多万条数据,怎么快速的查出第900万条后的100条数据?面试官问:Mysql数据库千万级数据查询优化方案…首先创建一张表,里面模拟了1000w数据:CREATE TABLE `system`.`Untitled`(`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(255) CHAR
·
Mysql数据库中一个表里有一千多万条数据,怎么快速的查出第900万条后的100条数据?
面试官问:Mysql数据库千万级数据查询优化方案…
首先创建一张表,里面模拟了1000w数据:
CREATE TABLE `system`.`sys_person` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '姓名',
`age` int(5) DEFAULT NULL COMMENT '年龄',
`sex` varchar(5) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '性别',
`tel` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '电话',
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '地址',
`email` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '邮箱',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 21000001 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
SELECT * FROM `sys_person` LIMIT 9000000,100;
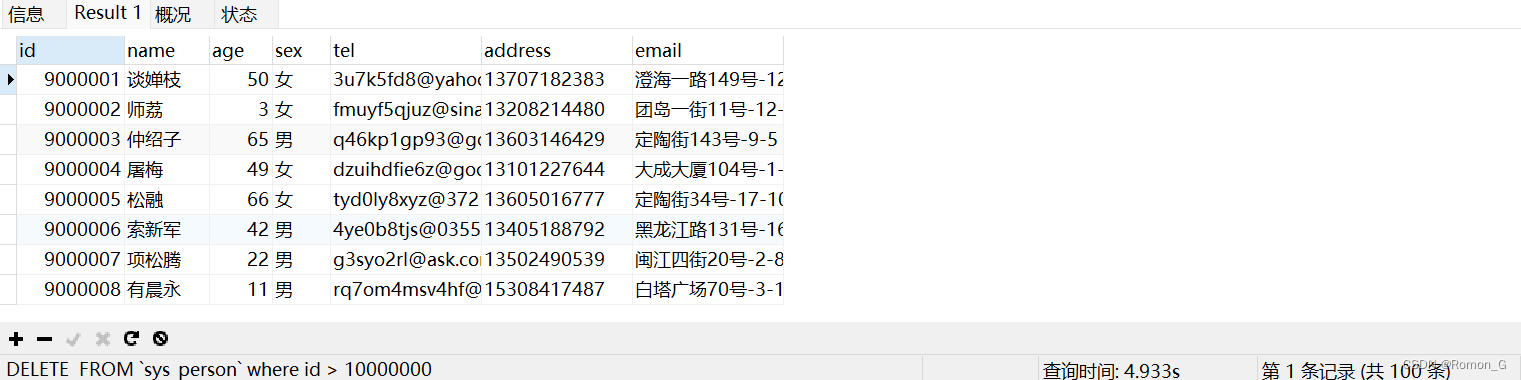
查100条记录使用了4.93s
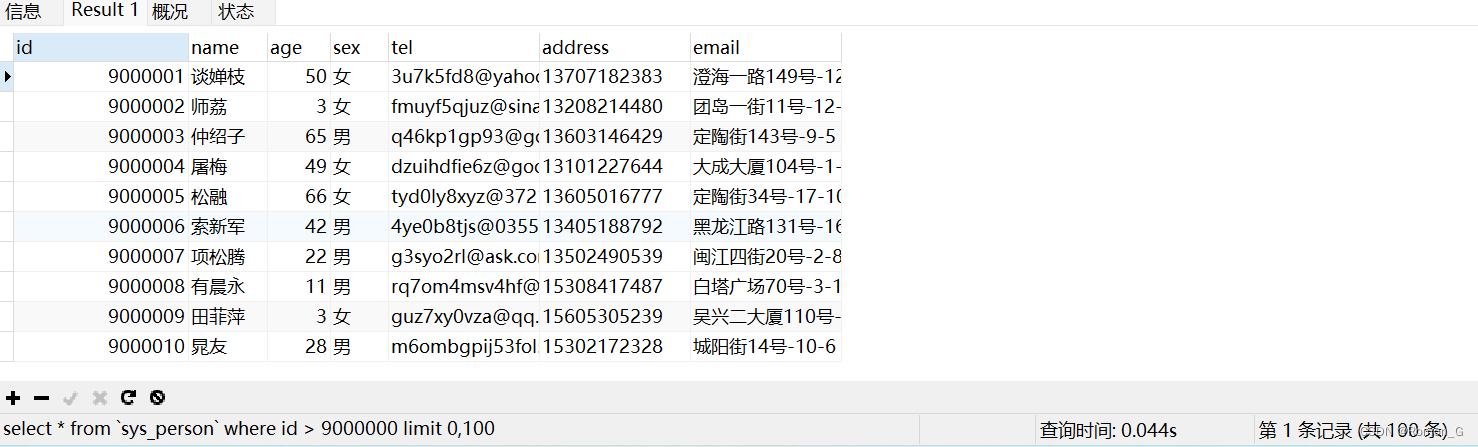
1、id>的方式查询:
select * from `sys_person` where id > 9000000 limit 0,100;
只使用了0.04s,效率提升了100倍左右。
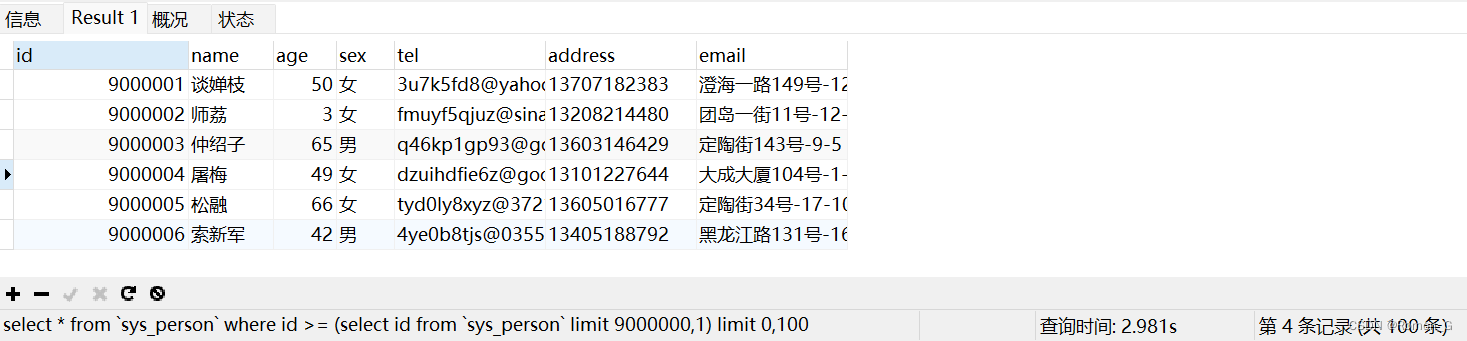
2、id>=的(子查询)形式实现:
select * from `sys_person` where id >= (select id from `sys_person` order by id limit 9000000,1) limit 0,100;
使用了2.98s,有提升,但是不明显
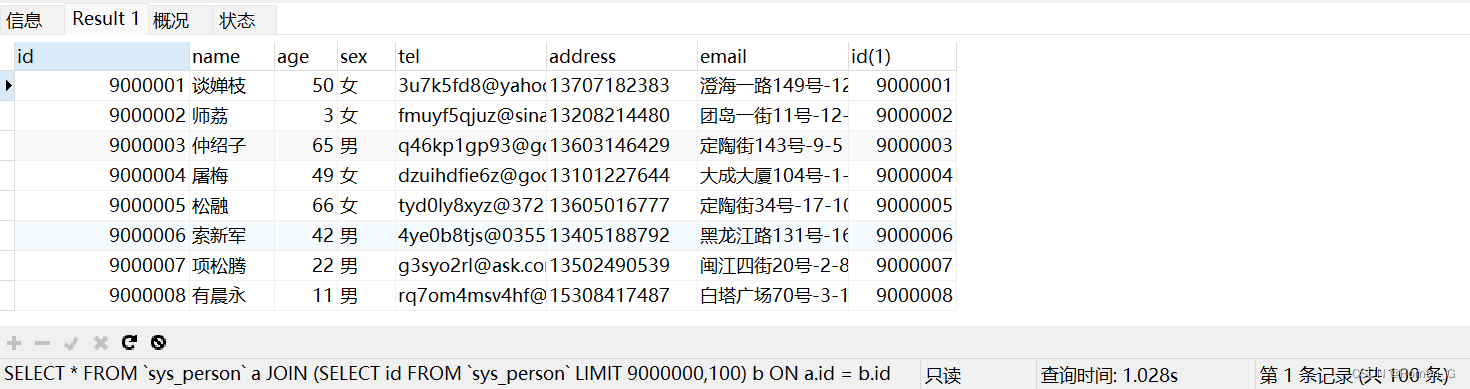
2、使用join的形式:
SELECT * FROM `sys_person` a JOIN (SELECT id FROM `sys_person` LIMIT 9000000,100) b ON a.id = b.id
使用了1s,效率提升了4倍左右

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)