AWR报告解读
分析下这份AWR报告,主要从CPU、IO、内存、语句类型来分析。
0 初步结论
① 数据库CPU资源不够,CPU使用率较高,造成CPU等待时间较长,可适当提升CPU资源;
② 数据库I/O资源消耗不太大,不存在IO瓶颈;
③ 可适当调大SGA空间(增加10G左右),PGA暂不需要调整;
④ sql_id=16dhat4ta7xs9,aw9ttz9acxbc3,d4ujh5yqt1fph三条SQL可以尝试进行优化存储过程。
⑤ 调整CPU资源后,再观察一下log file sync 等待事件是否还会很高,如果还高的话需要进一步跟进处理。
1 概览
1.1 数据库和实例的信息
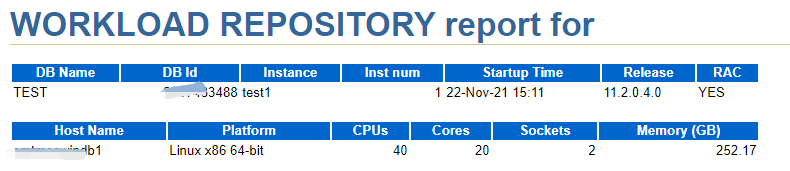
分析结果如下:
版本:11.2.04
RAC:YES
平台:Linux
CPU:2 * 20 cores
内存:252.17GB
1.2 Sessions 和 Cursors/Session
Sessions:实例连接的会话数 -> 并发用户数量 -> 数据库类型
Cussors/Session:每个会话打开的cursor数量 -> 执行SQL的情况

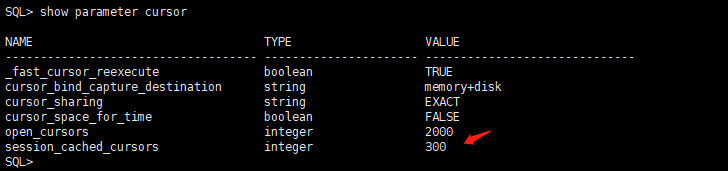
分析结果:当前会话量不是特别多
1.3 Elapsed 和 DB Time
系统负载和等待事件

DB Time : 累积方式记录,如1个CPU处理23.48,那么40个就是939.2分钟。(CPU执行时间+非空闲等待时间)
负载情况 :DB Time / (CPUs * Elapsed) = 1387.55 / (40 * 23.48) = 1397.55 / 939.2 = 148.8%
分析结果:说明当前数据负载较高
2 Load Profile
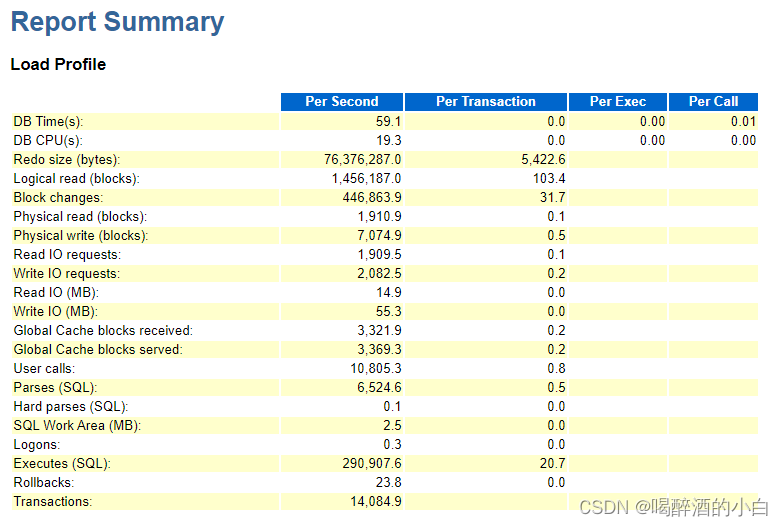
2.1 指标
Redo size: 每秒(每个事务)产生的redo量
Logical reads: 每秒(每个事务)产生的逻辑读(对应于物理读)
Block changes: 每秒(每个事务)改变的数据块数
Physical reads: 每秒(每个事务)产生的物理读
Physical writes: 每秒(每个事务)产生的物理写
User calls: 每秒(每个事务)用户的调用次数
Parses: 每秒(每个事务)分析次数
Hard parses: 每秒(每个事务)硬分析次数 (软 = 总 - 硬)
Sorts: 每秒(每个事务)排序次数
Logons: 每秒(每个事务)登录数据库次数
Executes: 每秒(每个事务)SQL的执行次数
Transactions: 每秒的事务数
2.2 IO
分析结果1:IO吞吐和IOPS都不是很大,对于一体机IO来说可以轻松应对
Physical read * 8K / 1024 = Read IO
Physical write * 8K / 1024 = Write IO

Redo Size = 76376287.0/1024/1024 = 72M
Logical reads = 1456187.0/1024/1024 = 1M
Block changes = 446,863.9

2.3 事务
分析结果2:每秒用户调用次数、解析次数、执行次数以及事务数都很高,初步判断数据库应该为交易型

3 Top 10 Foreground Events by Total Wait Time
DB CPU严格来说不是等待事件,一般排第一
等待事件类型和常见等待事件
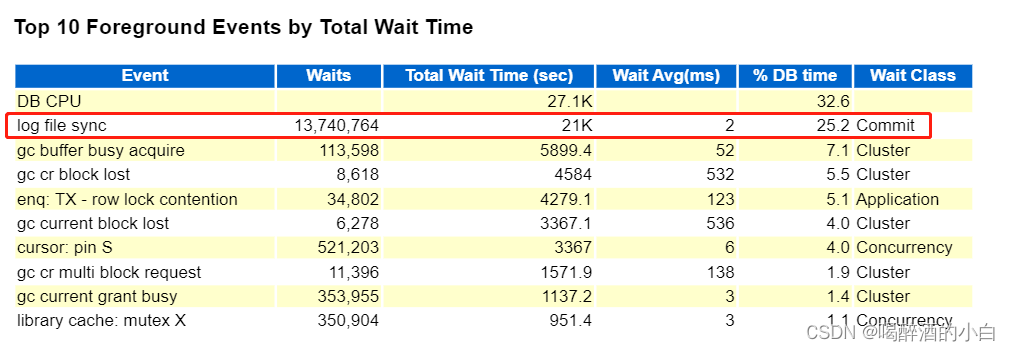
分析结果1:log file sync 等待事件排名第二,且比第三占比过多,猜测应该不太正常。
log file sync等待事件:当用户执行完事务(insert插入数据)执行commit命令后,Oracle后台LGWR进程需要redo log buffer -> online redo log files,写入后返回Commit complete。用户等待返回的这个过程过慢则会发生Log File Sync等待事件。
分析结果2:只有log file sync ,没有 log file parallel write,结合之前事务量过多判断,可能是cpu使用率较高、频繁提交或回滚等原因造成。
分析结果3:可以看到Commit十分频繁,建议使用批量批量提交。
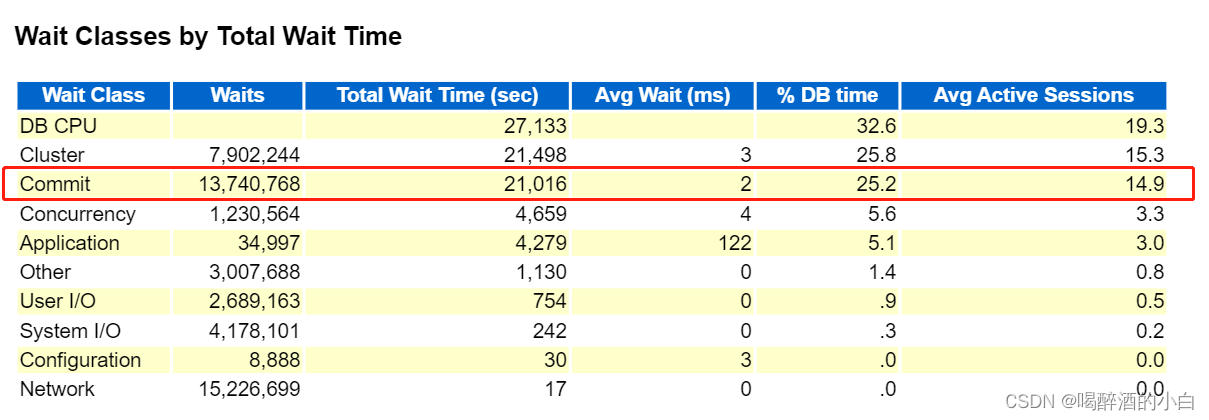
进一步确定redo的大小和组数是否合适。
4 CPU负载、IO、Memory
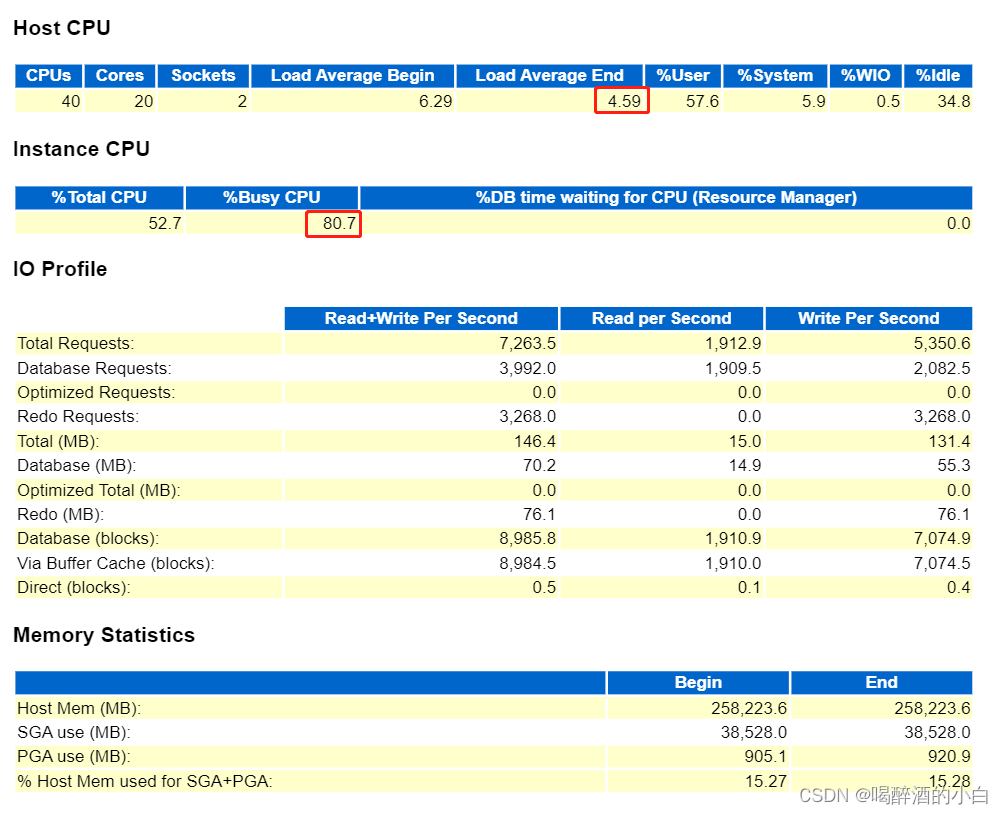
分析结果1:系统平均负载呈现下降趋势,%Idle = 34.8 ,%WIO说明CPU等待IO占比较低,不存在IO瓶颈。
5 SQL Statistics
按照不同类型进行排序


采样间隔:23.48mins

5.1 SQL ordered by Elapsed Time
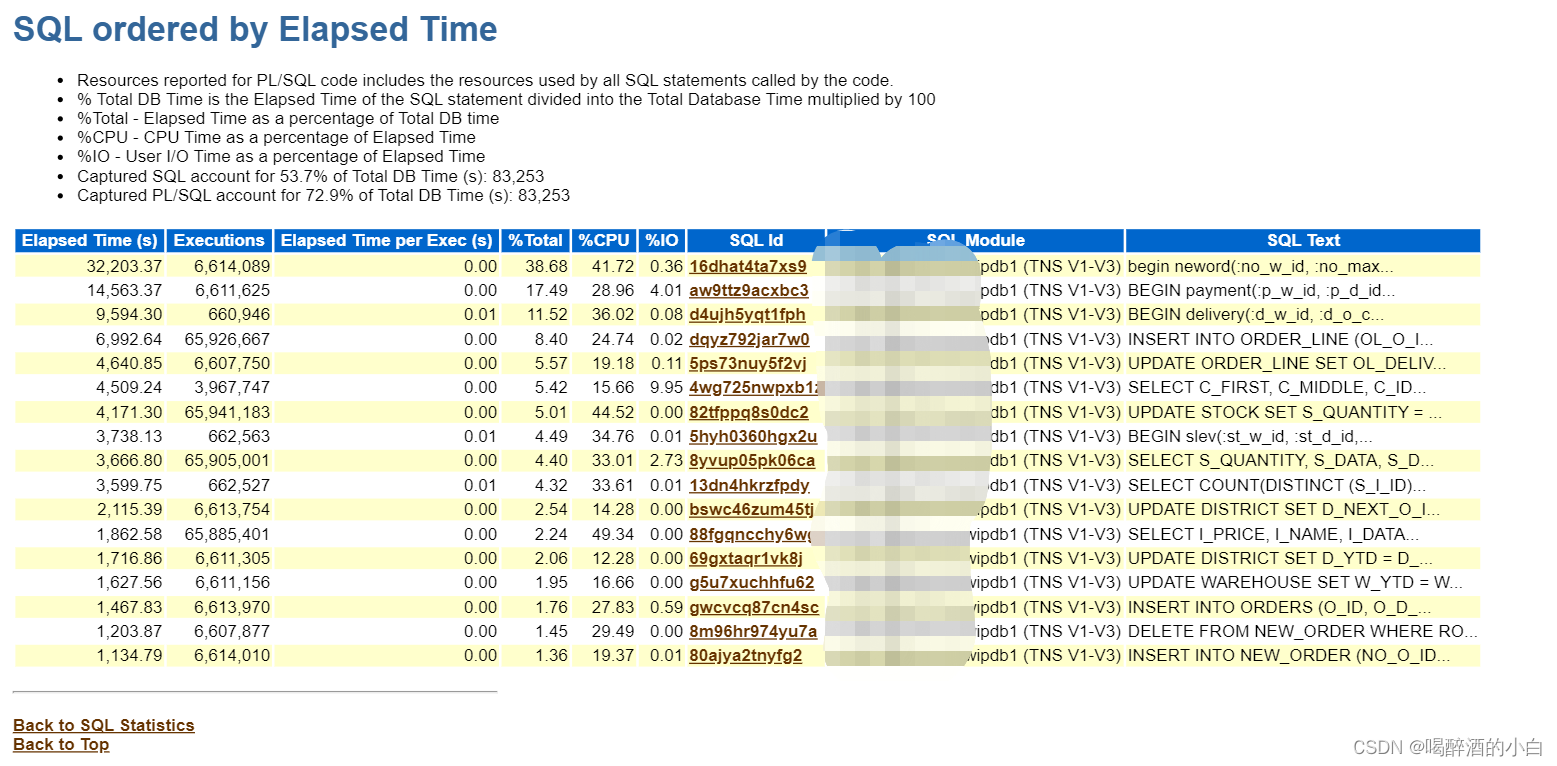
按照SQL的执行时间从长到短的排序,SQL只显示很小一部分,每条SQL语句都有一个SQL_ID,如果我们生成的AWR报告是HTML类型的,那么通过这些SQL_ID上的超级链接,可以在报告中直接定位到完整的SQL。

分析结果1:前三个加起来占整体的67.69%,通过SQL_ID超链接查看并且都是匿名块 begin … end。
分析结果2:前三个CPU等待时间均很长,IO不是很长,说明IO不是瓶颈。

5.2 SQL ordered by CPU Time
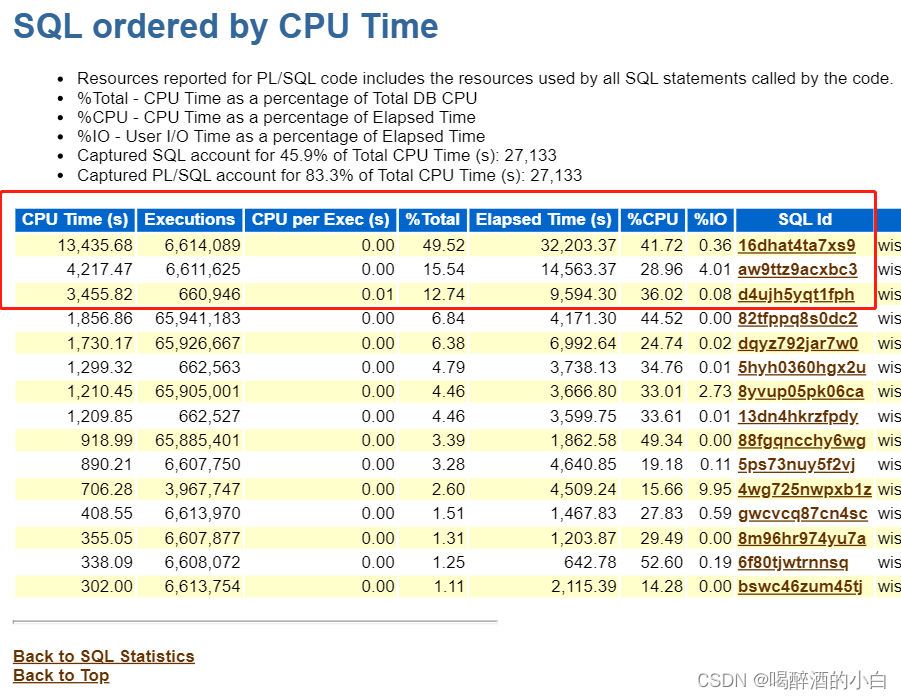
分析结果1:前三个sql和CPU Time 一样,且前三占总体的77.8%。
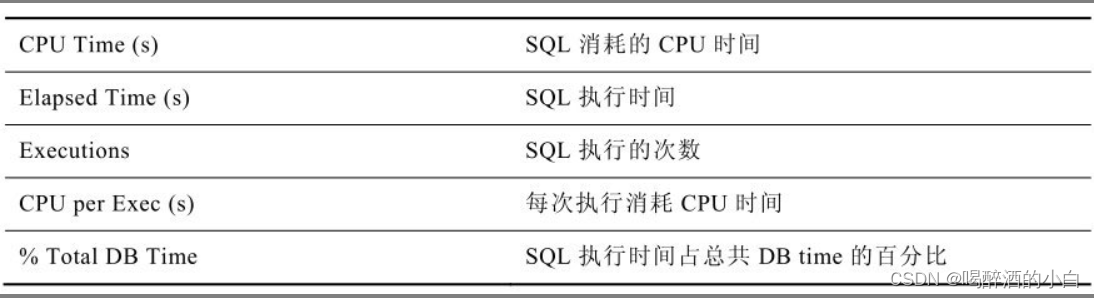
5.3 SQL ordered by User I/O Wait Time
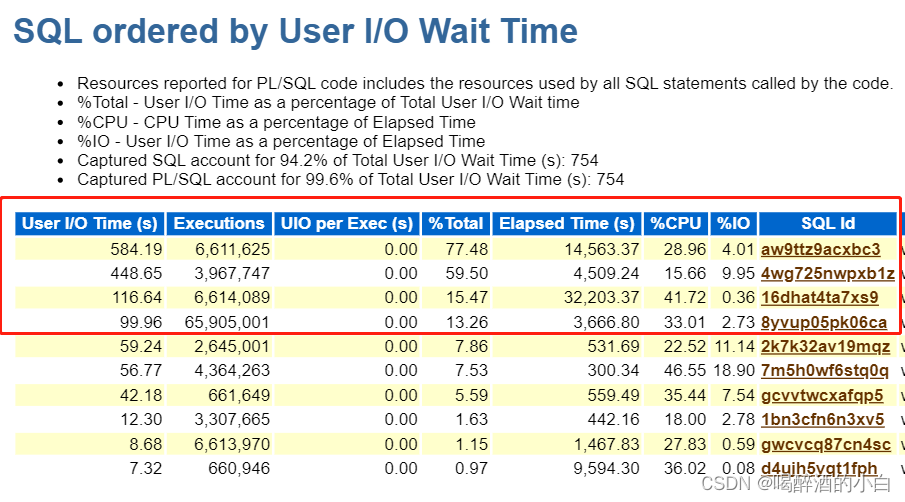
分析结果1:前面几个sql IO占比很高
5.4 SQL ordered by Gets
SQL获取的内存数据块的数量
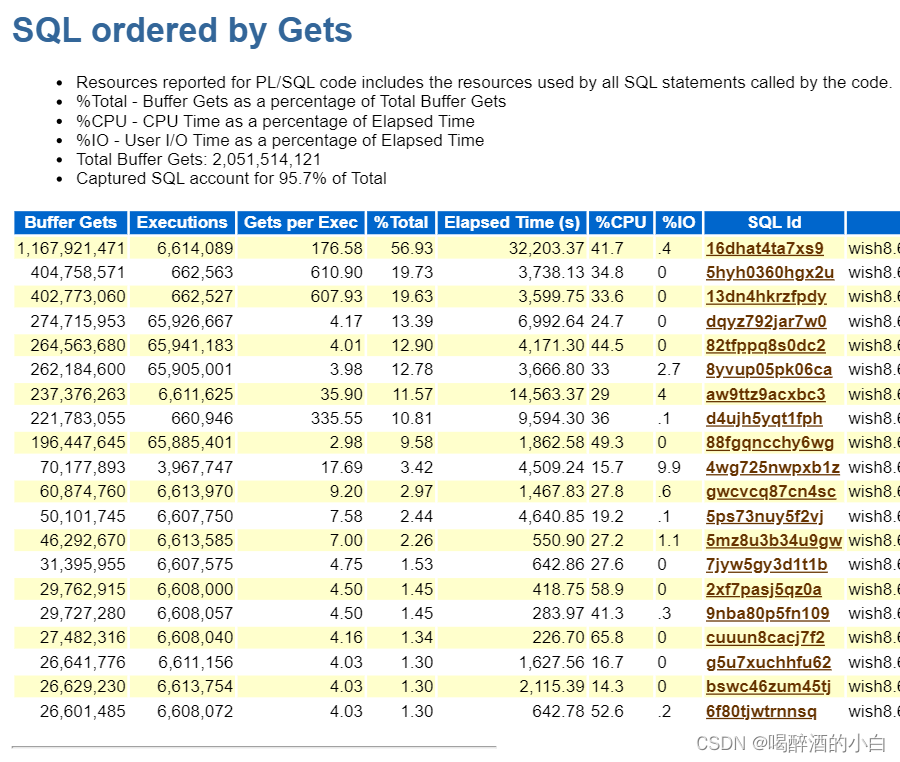
孤立地看这些指标的大小是没有实际意义的,它们是一些相对的数值。比如,我们没有前面的信息做参考,只看这一部分排在第一位的SQL,认为它获取的内存块太多,会有性能问题,这是没有根据的,只要SQL没有长时间地等待,就不能说它有性能问题。我们必须首先确定存在性能问题的SQL,这些数值会给我们一些补充信息。
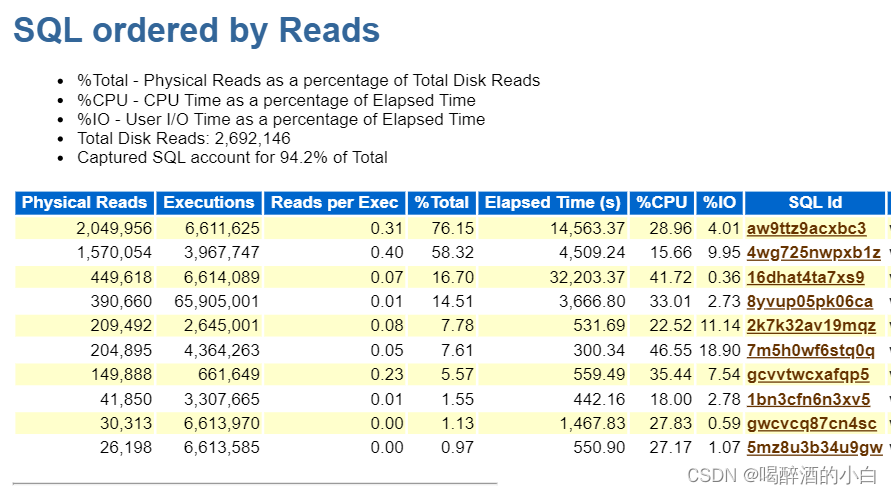
5.5 SQL ordered by Reads
出了SQL执行物理读的信息
5.6 SQL ordered by Physical Reads (UnOptimized)

5.7 SQL ordered by Executions
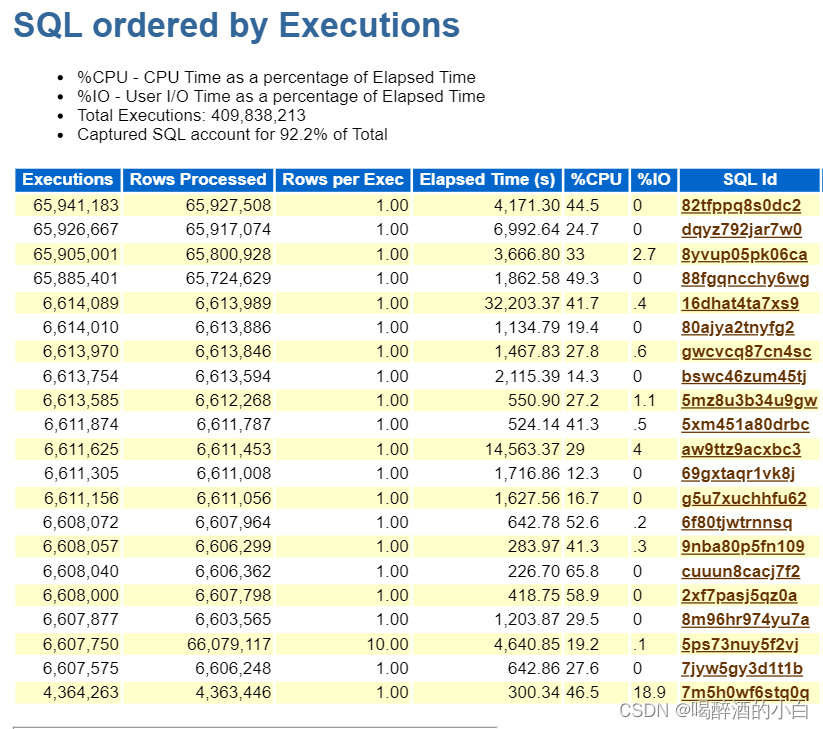
分析结果1:通过不同维度的sql排序我们可以发下,sql_id=16dhat4ta7xs9这条sql在Elapsed Time、CPU Time、User I/O Wait Time(第三)、Gets、Reads(第三)、Physical Reads (UnOptimized)(第三)、Executions(第五)排名均靠前,此外sql_id=aw9ttz9acxbc3和d4ujh5yqt1fph的sql也需要详细查看核对sql语句是否可以优化。
分析结果2:三个sql都是存储过程,需要进一步和开发人员核对。
6 内存
6.1 SGA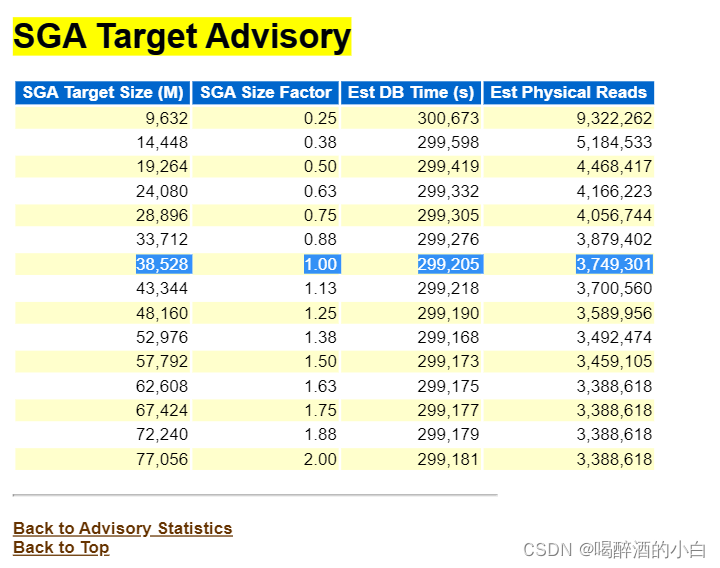
分析结果1:如果内存充裕的情况下可以适当再分配10G内存给SGA。并且调整到62G会达到一个瓶颈。
6.2 PGA
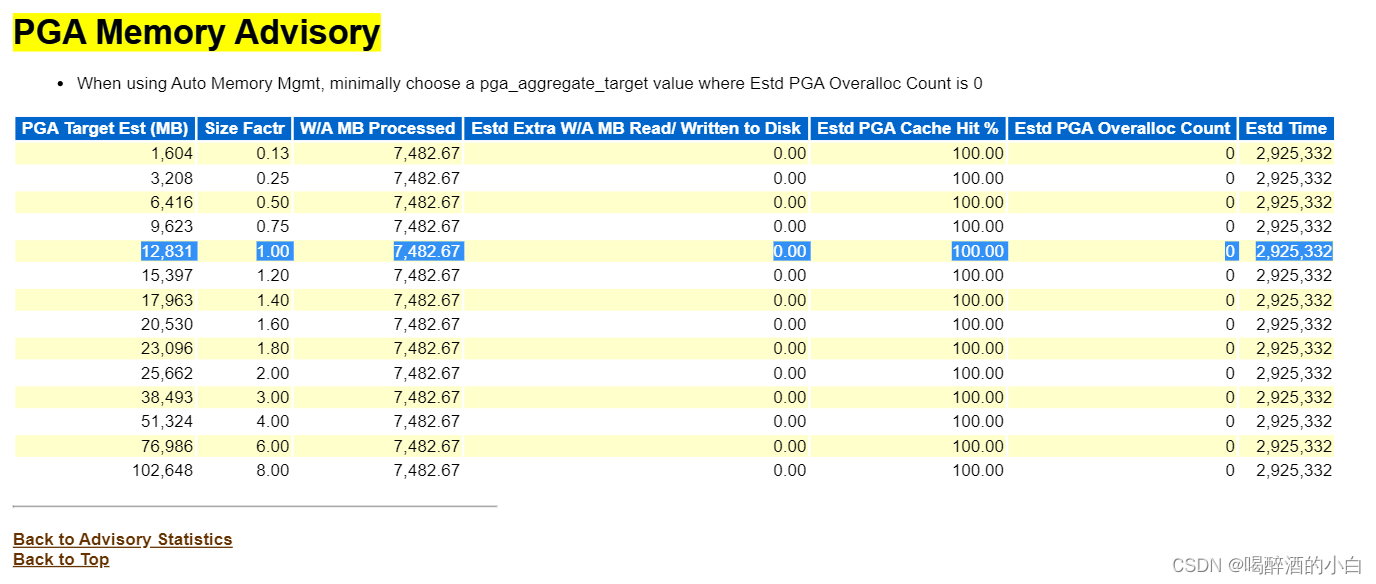
分析结果1:目前来看PGA大小不需要做调整
7 IO
7.1 IOStat by Function summary
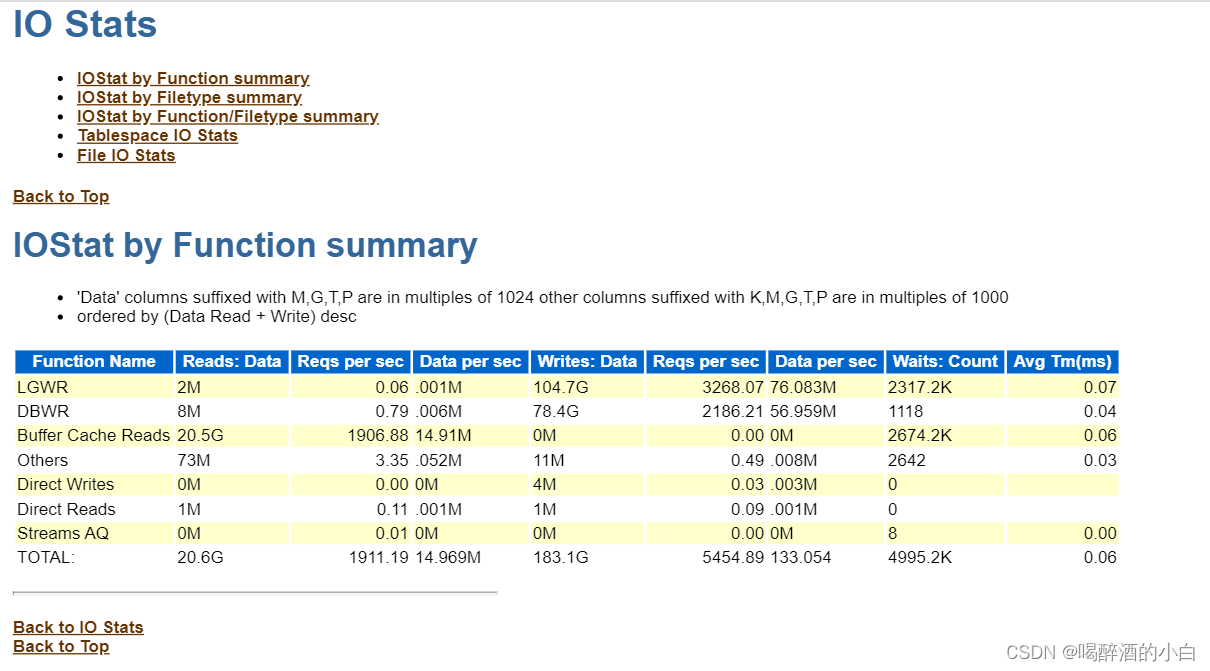
7.2 IOStat by Filetype summary
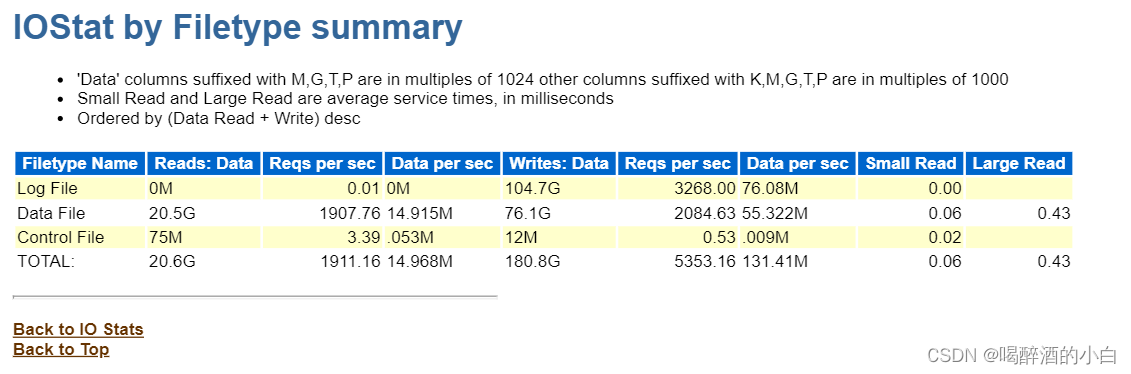
7.3 IOStat by Function/Filetype summary

7.4 Tablespace IO Stats
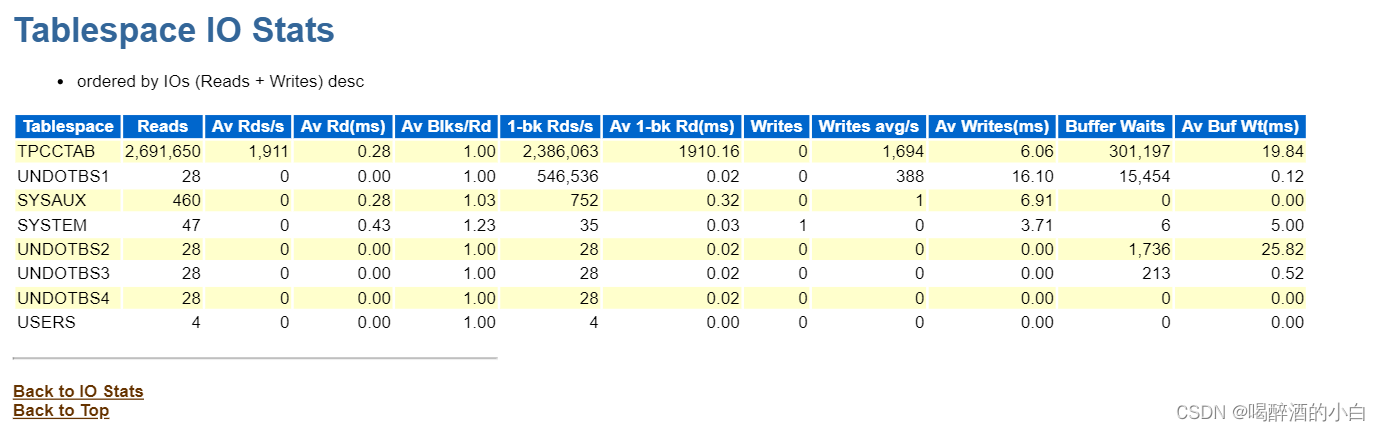
问题1:为什么只有undotbs1 io这么高,其他undo一般呢???
问题2:TPCCTAB表空间I/O延迟很高吗?
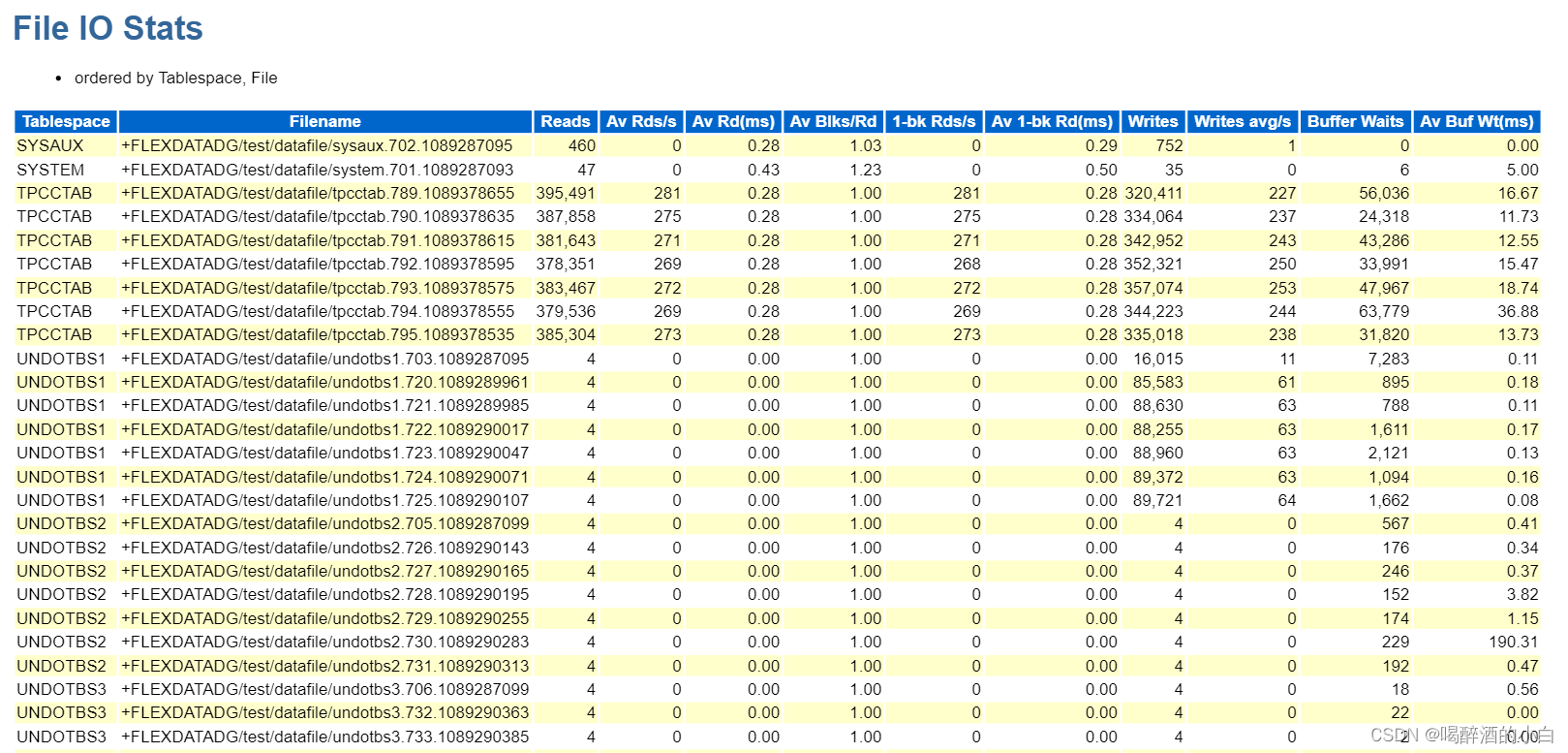
7.5 File IO Stats
8 Time Model Statistics
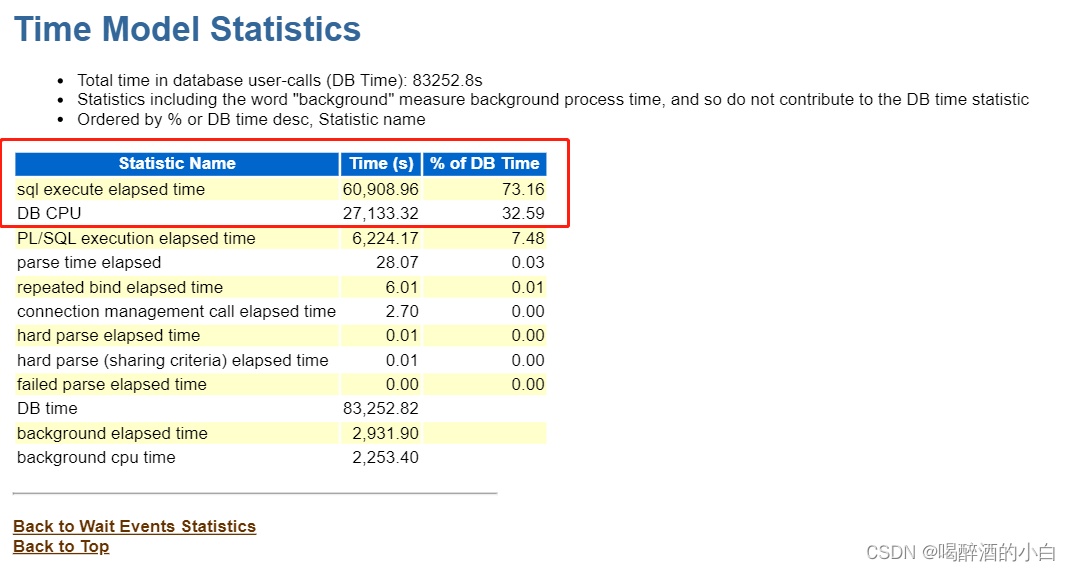
分析结果1:sql execute elpased time 时间占主导,即时间耗用主要是在SQL执行上面,并且DB CPU 也占了很大一部分,说明需要增加CPU资源。
9 参考资料

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献55条内容
已为社区贡献55条内容

{kind=link}
所有评论(0)