MySQL 查询重复数据只保留最新一条
准备工作创建测试表CREATE TABLE `user` (`id` int(10) unsigned NOT NULL AUTO_INCREMENT,`code` varchar(16) NOT NULL,`name` varchar(32) NOT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;插入数据INSERT IN
·
应用场景
程序实际开发中,总会产生重复的数据,后期优化需要删除重复数据
准备工作
- 创建测试表
CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`code` varchar(16) NOT NULL,
`name` varchar(32) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 插入数据
INSERT INTO user (code,name) VALUES('A','张三'),('A','张三'),('A','张三'),('B','李四'),('B','李四'),('B','李四'),('B','李四');
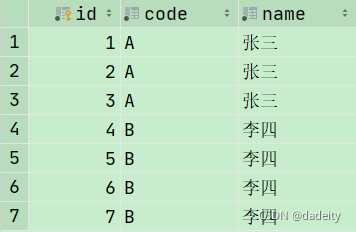
DDL操作
- 查询重复数据及重复条数
SELECT id, code, name, count(code) as count
FROM user
GROUP BY code
HAVING count(code) > 1
ORDER BY count DESC;

- 查询重复数据,保留最新一条
SELECT *
FROM user
WHERE id NOT IN (
# 查询重复数据code对应的最大id
SELECT id
FROM (
# 按id倒序排列
SELECT *
FROM user
ORDER BY id DESC
LIMIT 100000000) r1
GROUP BY r1.code
HAVING COUNT(r1.code) > 1)
and code IN (
# 查询重复的code
SELECT code
FROM user r2
GROUP BY r2.code
HAVING COUNT(r2.code) > 1)
ORDER BY id, code;
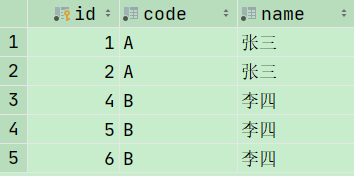
上面操作已经拿到重复数据,把最新的数据过滤掉。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)