Flink SQL之ProcessTime与EventTime的使用
目录(1)时间属性(2)ProcessTime(2.1)在创建表的 DDL 中定义(2.2)在 DataStream 到 Table 转换时定义(3)EventTime(3.1)在创建表的 DDL 中定义(3.2)在 DataStream 到 Table 转换时定义(1)时间属性处理时间 指的是执行具体操作时的机器时间事件时间 指的是数据本身携带的时间。这个时间是在事件产生时的时间。时间属性可以是
目录
(1)时间属性
- 处理时间 指的是执行具体操作时的机器时间
- 事件时间 指的是数据本身携带的时间。这个时间是在事件产生时的时间。
时间属性可以是每个表模式的一部分。当通过CREATETABLE DDL或创建表格时定义。一旦定义了时间属性,就可以将其引用为字段并在基于时间的操作中使用。只要时间属性没有被修改,并且只是从查询的一部分转发到另一部分,它仍然是有效的时间属性。时间属性的行为类似于常规时间戳,可用于计算
(2)ProcessTime
- 在创建表的 DDL 中定义
- 在 DataStream 到 Table 转换时定义
- 使用 TableSource 定义(Flink1.12中不建议使用)
(2.1)在创建表的 DDL 中定义
- 处理时间属性可以在创建表的 DDL 中用计算列的方式定义,用 PROCTIME() 就可以定义处理时间。
- 处理时间是基于机器的本地时间来处理数据,它既不需要从数据里获取时间,也不需要生成watermark。
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time AS PROCTIME() -- 声明一个额外的列作为处理时间属性
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
数据源:
100,技术部
200,市场部
300,营销部
400,采购部
代码演示:
package com.aikfk.flink.sql;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @author :caizhengjie
* @description:TODO
* @date :2021/4/5 10:32 下午
*/
public class ProcessTimeSQL {
public static void main(String[] args) throws Exception {
// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.创建TableEnvironment(Blink planner)
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env , settings);
// 3.文件path
String filePath = "/Users/caizhengjie/IdeaProjects/aikfk_flink/src/main/java/resources/dept.csv";
// 4.DDL-- 声明一个额外的列作为处理时间属性
String ddl = "create table dept (\n" +
" dept_id STRING,\n" +
" dept_name STRING,\n" +
" user_action_time AS PROCTIME()\n" +
") WITH (\n" +
" 'connector.type' = 'filesystem',\n" +
" 'connector.path' = '"+filePath+"',\n" +
" 'format.type' = 'csv'\n" +
")";
// 5.创建一个带processtime字段的表
tableEnvironment.executeSql(ddl);
// 6.通过SQL对表的查询,生成结果表
Table table = tableEnvironment.sqlQuery("select * from dept");
// 7.将table表转换为DataStream
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnvironment.toRetractStream(table, Row.class);
retractStream.print();
env.execute();
/**
* 5> (true,100,技术部,2021-04-08T08:06:49.792)
* 15> (true,400,采购部,2021-04-08T08:06:49.797)
* 8> (true,200,市场部,2021-04-08T08:06:49.817)
* 11> (true,300,营销部,2021-04-08T08:06:49.818)
*/
}
}
(2.2)在 DataStream 到 Table 转换时定义
处理时间属性可以在 schema 定义的时候用 .proctime 后缀来定义。时间属性一定不能定义在一个已有字段上,所以它只能定义在 schema 定义的最后。
// 声明一个额外的字段作为时间属性字段
Table table = tEnv.fromDataStream(stream, $("user_name"), $("data"), $("user_action_time").proctime());
代码演示:
package com.aikfk.flink.sql;
import com.aikfk.flink.sql.pojo.WC;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import static org.apache.flink.table.api.Expressions.$;
/**
* @author :caizhengjie
* @description:TODO
* @date :2021/4/5 10:32 下午
*/
public class ProcessTimeTable {
public static void main(String[] args) throws Exception {
// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.创建TableEnvironment(Blink planner)
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env , settings);
// 3.stream数据源
DataStream<WC> dataStream = env.fromElements(
new WC("java", 1),
new WC("spark", 1),
new WC("hive", 1),
new WC("hbase", 1),
new WC("hbase", 1),
new WC("hadoop", 1),
new WC("java", 1));
// 4.将dataStream转换为视图
// 声明一个额外的字段作为时间属性字段
tableEnvironment.createTemporaryView("wordcount" ,
dataStream,
$("wordName"),
$("freq"),
$("user_action_time").proctime());
// 5.通过SQL对表的查询,生成结果表
Table table = tableEnvironment.sqlQuery("select * from wordcount");
// 6.将table表转换为DataStream
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnvironment.toRetractStream(table, Row.class);
retractStream.print();
env.execute();
/**
* 9> (true,java,1,2021-04-08T08:06:13.485)
* 4> (true,spark,1,2021-04-08T08:06:13.485)
* 6> (true,hbase,1,2021-04-08T08:06:13.485)
* 8> (true,hadoop,1,2021-04-08T08:06:13.485)
* 5> (true,hive,1,2021-04-08T08:06:13.485)
* 7> (true,hbase,1,2021-04-08T08:06:13.485)
* 3> (true,java,1,2021-04-08T08:06:13.483)
*/
}
}
(3)EventTime
- 事件时间允许程序按照数据中包含的时间来处理,这样可以在有乱序或者晚到的数据的情况下产生一致的处理结果。
- 它可以保证从外部存储读取数据后产生可以复现(replayable)的结果。
(3.1)在创建表的 DDL 中定义
事件时间属性可以用 WATERMARK 语句在 CREATE TABLE DDL 中进行定义。WATERMARK 语句在一个已有字段上定义一个 watermark 生成表达式,同时标记这个已有字段为时间属性字段。
CREATE TABLE user_actions (
user_name STRING,
data STRING,
user_action_time TIMESTAMP(3),
-- 声明 user_action_time 是事件时间属性,并且用 延迟 5 秒的策略来生成 watermark
WATERMARK FOR user_action_time AS user_action_time - INTERVAL '5' SECOND
) WITH (
...
);
SELECT TUMBLE_START(user_action_time, INTERVAL '10' MINUTE), COUNT(DISTINCT user_name)
FROM user_actions
GROUP BY TUMBLE(user_action_time, INTERVAL '10' MINUTE);
数据源:
1,beer,3,2019-12-12 00:00:01
1,diaper,4,2019-12-12 00:00:02
2,pen,3,2019-12-12 00:00:04
2,rubber,3,2019-12-12 00:00:06
3,rubber,2,2019-12-12 00:00:05
4,beer,1,2019-12-12 00:00:08
代码演示:
package com.aikfk.flink.sql;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @author :caizhengjie
* @description:TODO
* @date :2021/4/5 10:32 下午
*/
public class EventTimeSQL {
public static void main(String[] args) throws Exception {
// 1.准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2.创建TableEnvironment(Blink planner)
EnvironmentSettings settings = EnvironmentSettings.newInstance().inStreamingMode().useBlinkPlanner().build();
StreamTableEnvironment tableEnvironment = StreamTableEnvironment.create(env , settings);
// 3.文件path
String filePath = "/Users/caizhengjie/IdeaProjects/aikfk_flink/src/main/java/resources/orders.csv";
// 4.DDL
// 声明 ts 是事件时间属性,并且用 延迟 3 秒的策略来生成 watermark
String ddl = "create table orders (\n" +
" user_id INT,\n" +
" product STRING,\n" +
" amount INT,\n" +
"ts TIMESTAMP(3),\n" +
"WATERMARK FOR ts AS ts - INTERVAL '3' SECOND \n" +
") WITH (\n" +
" 'connector.type' = 'filesystem',\n" +
" 'connector.path' = '"+filePath+"',\n" +
" 'format.type' = 'csv'\n" +
")";
// 5.创建一个带eventtime字段的表
tableEnvironment.executeSql(ddl);
// 6.通过SQL对表的查询,生成结果表
// 基于事件时间根据滚动窗口统计最近5秒product的数量,amount的总数以及订单数
String sql = "select TUMBLE_START(ts ,INTERVAL '5' SECOND)," +
" COUNT(DISTINCT product),\n" +
" SUM(amount) total_amount,\n" +
" COUNT(*) order_nums \n" +
" FROM orders \n" +
" GROUP BY TUMBLE(ts, INTERVAL '5' SECOND)";
Table table = tableEnvironment.sqlQuery(sql);
// 7.将table表转换为DataStream
DataStream<Tuple2<Boolean, Row>> retractStream = tableEnvironment.toRetractStream(table, Row.class);
retractStream.print();
env.execute();
/**
* 14> (true,2019-12-12T00:00,3,10,3)
* 15> (true,2019-12-12T00:00:05,2,6,3)
*/
}
}
(3.2)在 DataStream 到 Table 转换时定义
事件时间属性可以用 .rowtime 后缀在定义 DataStream schema 的时候来定义。时间戳和 watermark 在这之前一定是在 DataStream 上已经定义好了。
在从 DataStream 到 Table 转换时定义事件时间属性有两种方式。取决于用 .rowtime 后缀修饰的字段名字是否是已有字段,事件时间字段可以是:
- 在 schema 的结尾追加一个新的字段
- 替换一个已经存在的字段。
不管在哪种情况下,事件时间字段都表示 DataStream 中定义的事件的时间戳。
// Option 1:
// 基于 stream 中的事件产生时间戳和 watermark
DataStream<Tuple2<String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 声明一个额外的逻辑字段作为事件时间属性
Table table = tEnv.fromDataStream(stream, $("user_name"), $("data"), $("user_action_time").rowtime());
// Option 2:
// 从第一个字段获取事件时间,并且产生 watermark
DataStream<Tuple3<Long, String, String>> stream = inputStream.assignTimestampsAndWatermarks(...);
// 第一个字段已经用作事件时间抽取了,不用再用一个新字段来表示事件时间了
Table table = tEnv.fromDataStream(stream, $("user_action_time").rowtime(), $("user_name"), $("data"));
// Usage:
WindowedTable windowedTable = table.window(Tumble
.over(lit(10).minutes())
.on($("user_action_time"))
.as("userActionWindow"));
关于Flink SQL之ProcessTime与EventTime的使用详见官网:
(4)基于时间的查询
基于时间查询的场景
- Smoothing and aggregating data based on time
- 计算最近一分钟平均值
- Enriching streaming data with data from other sources
- 关联最近汇率变化表
- Stream monitoring, pattern matching, and alerting
- 五分钟内如果三次尝试失败则触发报警
- Common types of data
- 用户交互数据:点击,app埋点采集数据
- Logs:应用,服务器,网络日志
- Transactions:信用卡,支付宝
- Sensors:移动电话,车辆,1OT等
基于时间查询的特征
- 输入表为append一only类型,也就是插入的Rows记录不再更新.
- 查询条件中含有时间关联条件和算子
- Filter,Projection,Windowedaggregations,Intervaljoin,Temporal一tablejoin,Pattern matching
- 查询结果也是append一only类型,输出的结果永远都不会被更新
基于时间的算子
- 基于时间条件查询的算子:
- GROUP BY window aggregation
- OVER window aggregation
- Time一windowed join
- Join with a temporal table (enrichment join)
- Pattern matching (MATCH_RECOGNIZE)
- Temporaloperators必须要指定时间属性
- Event一Time和Processing一Time
- Temporal Operator 根据输入数据是否已经完成,决定下列操作:
- Operator输出最终的计算结果,并且该结果不支持更新
- Operator根据状态是否还需要,从而决定是否丢弃转态数据(Records和Results)
基于时间的Aggregation
Flink SQL支持两种类型的TemporalAggregation
- Group By Window Aggregation
- Over Window Aggregation
Group By Window Aggregation:统计计算每个小时中,每个用户的点击次数
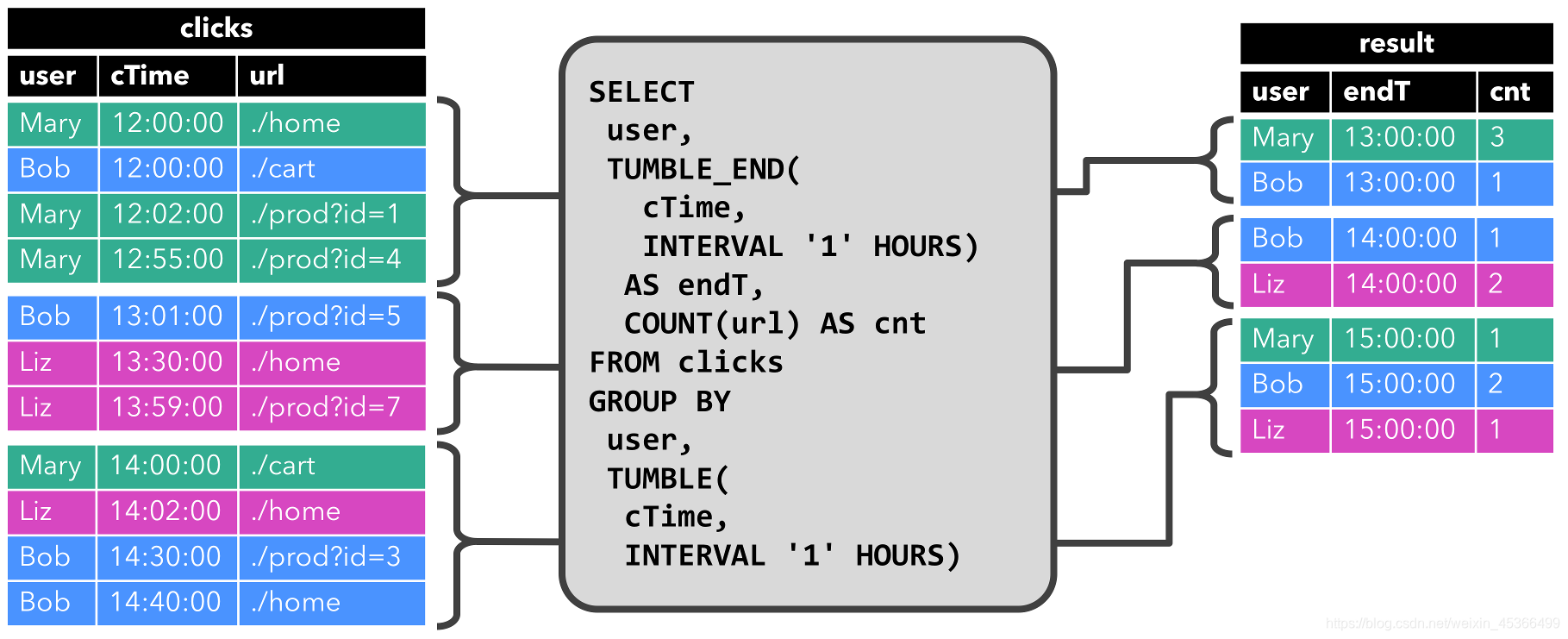

Over Window Aggregation:计算每次点击之前两个小时内的点击总数,每条数据都会触发计算前两个小时的数据

以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)