mysql 字段相同条数_用sql语句统计数据库某个字段中相同的数据有多少条?
展开全部用分组,组内计数就可以了,意e69da5e6ba9062616964757a686964616f31333366306461思就是根据字段a的取值进行分组,相同的为一组,在用count进行组内计数。select a,count(*)from Agroup by a扩展资料:SQL统计重复数据1、生成表CREATE TABLE TEST1 (COL1 CHAR(2),COL2 INT...
展开全部
用分组,组内计数就可以了,意e69da5e6ba9062616964757a686964616f31333366306461思就是根据字段a的取值进行分组,相同的为一组,在用count进行组内计数。
select a,count(*)
from A
group by a
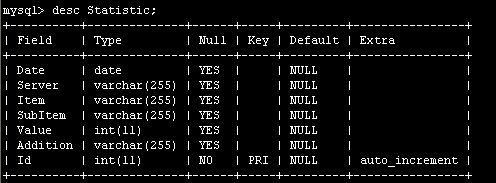
扩展资料:
SQL统计重复数据
1、生成表
CREATE TABLE TEST1 (
COL1 CHAR(2),
COL2 INT
)
GO
2、插入数据
INSERT INTO TEST1 VALUES('AA', 1000);
INSERT INTO TEST1 VALUES('AA', 2000);
INSERT INTO TEST1 VALUES('AA', 3000);
INSERT INTO TEST1 VALUES('BB', 1100);
INSERT INTO TEST1 VALUES('BB', 1200);
INSERT INTO TEST1 VALUES('CC', 1300);
3、统计重复数据(找出有重复的值)
SELECT COL1, COUNT(COL1) 重复数量
FROM TEST1
GROUP BY COL1
HAVING COUNT(COL1) > 1
ORDER BY COL1;
4、查询结果
COL1 重复数量
AA 3
BB 2

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)