flink任务常见报错及解决办法
1、flink任务无法从checkpoint启动场景一、flink任务运行过程中出现异常时(如checkpoint失败次数超过配置阈值),自动重启出现算子异常,无法恢复正常运行。场景二、手动下线任务,选择上一次的checkpoint启动时,出现算子异常,无法启动。报错如下:java.lang.Exception: Exception while creating StreamOperatorSta
1、flink任务无法从checkpoint启动
场景一、flink任务运行过程中出现异常时(如checkpoint失败次数超过配置阈值),自动重启出现算子异常,无法恢复正常运行。
场景二、手动下线任务,选择上一次的checkpoint启动时,出现算子异常,无法启动。
报错如下:
java.lang.Exception: Exception while creating StreamOperatorStateContext.
at org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.streamOperatorStateContext(StreamTaskStateInitializerImpl.java:195)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:253)
at org.apache.flink.streaming.runtime.tasks.StreamTask.initializeState(StreamTask.java:881)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:395)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:705)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:530)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.flink.util.FlinkException: Could not restore operator state backend for StreamSource_cbc357ccb763df2852fee8c4fc7d55f2_(1/20) from any of the 1 provided restore options.
at org.apache.flink.streaming.api.operators.BackendRestorerProcedure.createAndRestore(BackendRestorerProcedure.java:135)
at org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.operatorStateBackend(StreamTaskStateInitializerImpl.java:255)
at org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.streamOperatorStateContext(StreamTaskStateInitializerImpl.java:143)
... 6 more
Caused by: org.apache.flink.runtime.state.BackendBuildingException: Failed when trying to restore operator state backend
at org.apache.flink.runtime.state.DefaultOperatorStateBackendBuilder.build(DefaultOperatorStateBackendBuilder.java:86)
at org.apache.flink.contrib.streaming.state.RocksDBStateBackend.createOperatorStateBackend(RocksDBStateBackend.java:537)
at org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.lambda$operatorStateBackend$0(StreamTaskStateInitializerImpl.java:246)
at org.apache.flink.streaming.api.operators.BackendRestorerProcedure.attemptCreateAndRestore(BackendRestorerProcedure.java:142)
at org.apache.flink.streaming.api.operators.BackendRestorerProcedure.createAndRestore(BackendRestorerProcedure.java:121)
... 8 more
Caused by: java.io.EOFException
at java.io.DataInputStream.readFully(DataInputStream.java:197)
at java.io.DataInputStream.readLong(DataInputStream.java:416)
at org.apache.flink.api.common.typeutils.base.LongSerializer.deserialize(LongSerializer.java:74)
at org.apache.flink.api.common.typeutils.base.LongSerializer.deserialize(LongSerializer.java:32)
at org.apache.flink.api.java.typeutils.runtime.TupleSerializer.deserialize(TupleSerializer.java:143)
at org.apache.flink.api.java.typeutils.runtime.TupleSerializer.deserialize(TupleSerializer.java:37)
at org.apache.flink.runtime.state.OperatorStateRestoreOperation.deserializeOperatorStateValues(OperatorStateRestoreOperation.java:191)
at org.apache.flink.runtime.state.OperatorStateRestoreOperation.restore(OperatorStateRestoreOperation.java:165)
at org.apache.flink.runtime.state.DefaultOperatorStateBackendBuilder.build(DefaultOperatorStateBackendBuilder.java:83)
... 12 more
原因:jar包冲突,反序列化时,无法读取之前写入checkpoint的内容,因此无法恢复
解决:在pom.xml文件中修改如下内容
原内容:
<dependency>
<groupId>com.twitter</groupId>
<artifactId>chill-protobuf</artifactId>
<version>0.5.2</version>
</dependency>
修改为:
<dependency>
<groupId>com.twitter</groupId>
<artifactId>chill-protobuf</artifactId>
<version>0.5.2</version>
<exclusions>
<exclusion>
<groupId>com.esotericsoftware.kryo</groupId>
<artifactId>kryo</artifactId>
</exclusion>
</exclusions>
</dependency>
然后直接启动,下次能从checkpoint正常启动。
2、消费kafka报错,详见:
场景:kafka集群扩容一台机器,但是无法从机器的主机名解析到ip,导致消费报错
java.lang.Exception: java.lang.IllegalStateException: No entry found for connection 11
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.checkThrowSourceExecutionException(SourceStreamTask.java:217)
at org.apache.flink.streaming.runtime.tasks.SourceStreamTask.processInput(SourceStreamTask.java:133)
at org.apache.flink.streaming.runtime.tasks.StreamTask.run(StreamTask.java:301)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:406)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:705)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:530)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.IllegalStateException: No entry found for connection 11
at org.apache.kafka.clients.ClusterConnectionStates.nodeState(ClusterConnectionStates.java:339)
at org.apache.kafka.clients.ClusterConnectionStates.disconnected(ClusterConnectionStates.java:143)
at org.apache.kafka.clients.NetworkClient.initiateConnect(NetworkClient.java:926)
at org.apache.kafka.clients.NetworkClient.access$700(NetworkClient.java:67)
at org.apache.kafka.clients.NetworkClient$DefaultMetadataUpdater.maybeUpdate(NetworkClient.java:1090)
at org.apache.kafka.clients.NetworkClient$DefaultMetadataUpdater.maybeUpdate(NetworkClient.java:976)
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:533)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:265)
at org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:236)
at org.apache.kafka.clients.consumer.KafkaConsumer.pollForFetches(KafkaConsumer.java:1256)
at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1200)
at org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1135)
at org.apache.flink.streaming.connectors.kafka.internal.KafkaConsumerThread.run(KafkaConsumerThread.java:253)原因:发送或消费到此机器时,初始化连接时,由于解析ip失败,未将机器信息put到nodeState map中,导致
connectionStates.disconnected时,无法从nodeState中获取到此机器抛异常。无法从机器的主机名解析到ip,导致消费报错。事实上是2.1.1和2.2.0版本的bug,在2.3.0, 2.1.2, 2.2.1版本修复
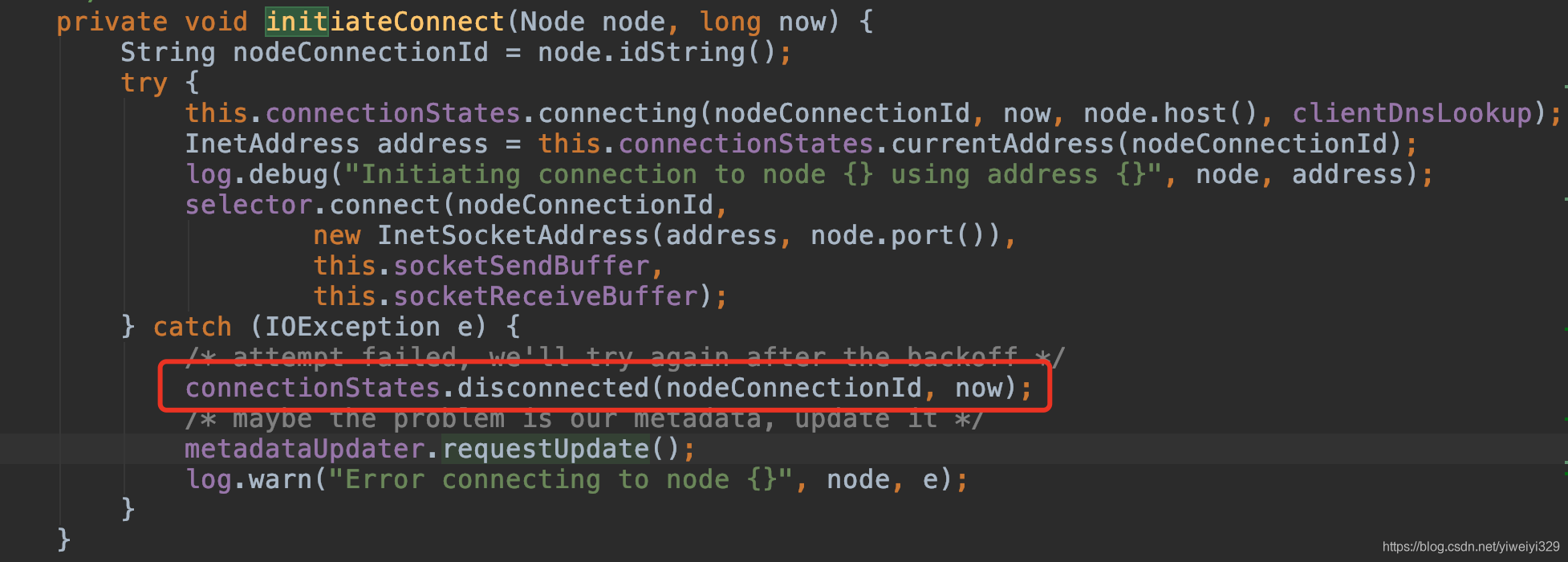
解决:将此机器从集群中剔除或升级kafka版本
3、flink checkpoint的时候报错,导致checkpoint失败
场景:flink checkpoint的时候报错,导致checkpoint失败,并报如下错误:
level: INFO
log: 2020-06-21 09:25:07,573 ultron-test INFO org.apache.flink.runtime.taskmanager.Task - Source: Custom Source -> Map -> Sink: sink2hdfs (2/5) (89d84b420ba89b72fa2989b2ca55edd7) switched from RUNNING to FAILED.
location: org.apache.flink.runtime.taskmanager.Task.transitionState(Task.java:960)
throwable: java.lang.RuntimeException: Error while confirming checkpoint
at org.apache.flink.runtime.taskmanager.Task$2.run(Task.java:1205)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.io.IOException: Cannot clean commit: Staging file does not exist.
at org.apache.flink.runtime.fs.hdfs.HadoopRecoverableFsDataOutputStream$HadoopFsCommitter.commit(HadoopRecoverableFsDataOutputStream.java:244)
at org.apache.flink.streaming.api.functions.sink.filesystem.Bucket.onSuccessfulCompletionOfCheckpoint(Bucket.java:296)
at org.apache.flink.streaming.api.functions.sink.filesystem.Buckets.commitUpToCheckpoint(Buckets.java:210)
at org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink.notifyCheckpointComplete(StreamingFileSink.java:340)
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.notifyCheckpointComplete(AbstractUdfStreamOperator.java:130)
at org.apache.flink.streaming.runtime.tasks.StreamTask.notifyCheckpointComplete(StreamTask.java:822)
at org.apache.flink.runtime.taskmanager.Task$2.run(Task.java:1200)
... 5 more
message: Source: Custom Source -> Map -> Sink: sink2hdfs (2/5) (89d84b420ba89b72fa2989b2ca55edd7) switched from RUNNING to FAILED.原因:由于flink写hdfs会导致很多小文件,尝试小文件合并的时候,误将正在写的小文件合并掉了。因此,flink将inprogress文件转为finished文件时,找不到原来的文件报错,导致checkpoint失败。

解决:合并小文件时注意,正在写的小文件不能合并
4、tm资源不足,报错如下:
java.lang.Exception: Exception from container-launch.
Container id: container_1588838921607_2662_01_000002
Exit code: 255
Stack trace: ExitCodeException exitCode=255:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:604)
at org.apache.hadoop.util.Shell.run(Shell.java:507)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:789)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:213)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Container exited with a non-zero exit code 255
at org.apache.flink.yarn.YarnResourceManager.lambda$onContainersCompleted$0(YarnResourceManager.java:343)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:402)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:195)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:152)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at akka.actor.Actor$class.aroundReceive(Actor.scala:517)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)
at akka.actor.ActorCell.invoke(ActorCell.scala:561)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)
at akka.dispatch.Mailbox.run(Mailbox.scala:225)
at akka.dispatch.Mailbox.exec(Mailbox.scala:235)
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)原因:由于TaskManager内存资源不足导致的
解决办法:增大TaskManagerMem内存,然后重新启动即可;当flink1.9升级到flink1.10报此错误可以调节高级参数(taskmanager.memory.task.off-heap.size为flink1.9下正常运行的TaskManager内存的0.2倍)
5、访问datanode超时问题报错:
level: WARN
log: 2020-08-14 16:37:31,018 log_test WARN org.apache.hadoop.hdfs.DFSClient - Error Recovery for block BP-506007014-XXX.XX.XXX.XXX-1565766978810:blk_2785087488_1711475313 in pipeline DatanodeInfoWithStorage[XXX.XX.XXX.XXX:61004,DS-c0cfa83b-264e-438f-b9a3-63a7c3eaa096,DISK], DatanodeInfoWithStorage[XXX.XX.XXX.XXX:61004,DS-9dfb81b9-07e9-48b5-9725-c9b142fe6f83,DISK]: datanode 0(DatanodeInfoWithStorage[XXX.XX.XXX.XXX:61004,DS-c0cfa83b-264e-438f-b9a3-63a7c3eaa096,DISK]) is bad.
location: org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.setupPipelineForAppendOrRecovery(DFSOutputStream.java:1234)
message: Error Recovery for block BP-506007014-XXX.XX.XXX.XXX-1565766978810:blk_2785087488_1711475313 in pipeline DatanodeInfoWithStorage[XXX.XX.XXX.XXX:61004,DS-c0cfa83b-264e-438f-b9a3-63a7c3eaa096,DISK], DatanodeInfoWithStorage[XXX.XX.XXX.XXX:61004,DS-9dfb81b9-07e9-48b5-9725-c9b142fe6f83,DISK]: datanode 0(DatanodeInfoWithStorage[XXX.XX.XXX.XXX:61004,DS-c0cfa83b-264e-438f-b9a3-63a7c3eaa096,DISK]) is bad.
flink任务消费变弱,出现延迟,报错中显示很多机器ip bad,并不是真的bad,从datanode
020-08-14 16:37:31,557 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: opWriteBlock BP-506007014-XXX.XX.XXX.XXX-1565766978810:blk_2785087464_1711475324 received exception java.net.SocketTimeoutException: 60000 millis timeout while waiting for channel to be ready for read. ch : java.nio.channels.SocketChannel[connected local=/XXX.XX.XXX.XXX:61004 remote=/XXX.XX.XXX.XXX:52038]日志能看出(如上)只是集群抖动下超时导致的
6、flink任务启动失败,报错如下:
java.lang.Exception: Exception while creating StreamOperatorStateContext.
at org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.streamOperatorStateContext(StreamTaskStateInitializerImpl.java:191)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:255)
at org.apache.flink.streaming.runtime.tasks.StreamTask.initializeStateAndOpen(StreamTask.java:989)
at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$beforeInvoke$0(StreamTask.java:453)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$SynchronizedStreamTaskActionExecutor.runThrowing(StreamTaskActionExecutor.java:94)
at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:448)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:460)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:708)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:533)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.flink.util.FlinkException: Could not restore keyed state backend for WindowOperator_366d561ddc4c82c27066ecdf81fd015c_(1/1) from any of the 1 provided restore options.
at org.apache.flink.streaming.api.operators.BackendRestorerProcedure.createAndRestore(BackendRestorerProcedure.java:135)
at org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.keyedStatedBackend(StreamTaskStateInitializerImpl.java:304)
at org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.streamOperatorStateContext(StreamTaskStateInitializerImpl.java:131)
... 9 more
Caused by: java.io.IOException: Failed to acquire shared cache resource for RocksDB
at org.apache.flink.contrib.streaming.state.RocksDBOperationUtils.allocateSharedCachesIfConfigured(RocksDBOperationUtils.java:212)
at org.apache.flink.contrib.streaming.state.RocksDBStateBackend.createKeyedStateBackend(RocksDBStateBackend.java:516)
at org.apache.flink.streaming.api.operators.StreamTaskStateInitializerImpl.lambda$keyedStatedBackend$1(StreamTaskStateInitializerImpl.java:288)
at org.apache.flink.streaming.api.operators.BackendRestorerProcedure.attemptCreateAndRestore(BackendRestorerProcedure.java:142)
at org.apache.flink.streaming.api.operators.BackendRestorerProcedure.createAndRestore(BackendRestorerProcedure.java:121)
... 11 more
Caused by: org.apache.flink.runtime.memory.MemoryAllocationException: Could not created the shared memory resource of size 373125288. Not enough memory left to reserve from the slot's managed memory.
at org.apache.flink.runtime.memory.MemoryManager.lambda$getSharedMemoryResourceForManagedMemory$8(MemoryManager.java:603)
at org.apache.flink.runtime.memory.SharedResources.createResource(SharedResources.java:130)
at org.apache.flink.runtime.memory.SharedResources.getOrAllocateSharedResource(SharedResources.java:72)
at org.apache.flink.runtime.memory.MemoryManager.getSharedMemoryResourceForManagedMemory(MemoryManager.java:617)
at org.apache.flink.runtime.memory.MemoryManager.getSharedMemoryResourceForManagedMemory(MemoryManager.java:566)
at org.apache.flink.contrib.streaming.state.RocksDBOperationUtils.allocateSharedCachesIfConfigured(RocksDBOperationUtils.java:208)
... 15 more
Caused by: org.apache.flink.runtime.memory.MemoryReservationException: Could not allocate 373125288 bytes. Only 0 bytes are remaining.
at org.apache.flink.runtime.memory.MemoryManager.reserveMemory(MemoryManager.java:461)
at org.apache.flink.runtime.memory.MemoryManager.lambda$getSharedMemoryResourceForManagedMemory$8(MemoryManager.java:601)
... 20 more原因:内存不足,导致任务启动失败
解决办法:增大taskmanager内存;当flink1.9迁移到1.10遇到这个问题,可以调节高级参数(state.backend.rocksdb.memory.managed = false)
7、flink任务算子异常,报错如下:
java.lang.Exception: Container [pid=65042,containerID=container_1598160640580_0436_01_000002] is running beyond physical memory limits. Current usage: 5.0 GB of 5 GB physical memory used; 7.0 GB of 24.4 TB virtual memory used. Killing container.
Dump of the process-tree for container_1598160640580_0436_01_000002 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 65203 65042 65042 65042 (java) 19277834 1975228 7447101440 1310371 /usr/lib/jvm/java-1.8.0/bin/java -Xms3456m -Xmx3456m -XX:MaxDirectMemorySize=1664m -Dlog.file=/mnt/disk3/log/hadoop-yarn/containers/application_1598160640580_0436/container_1598160640580_0436_01_000002/taskmanager.log -Djob.name=kafka2hive_ireport -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner --configDir .
|- 65042 65025 65042 65042 (bash) 0 1 115855360 355 /bin/bash -c /usr/lib/jvm/java-1.8.0/bin/java -Xms3456m -Xmx3456m -XX:MaxDirectMemorySize=1664m -Dlog.file=/mnt/disk3/log/hadoop-yarn/containers/application_1598160640580_0436/container_1598160640580_0436_01_000002/taskmanager.log -Djob.name=kafka2hive_ireport -Dlogback.configurationFile=file:./logback.xml -Dlog4j.configuration=file:./log4j.properties org.apache.flink.yarn.YarnTaskExecutorRunner --configDir . 1> /mnt/disk3/log/hadoop-yarn/containers/application_1598160640580_0436/container_1598160640580_0436_01_000002/taskmanager.out 2> /mnt/disk3/log/hadoop-yarn/containers/application_1598160640580_0436/container_1598160640580_0436_01_000002/taskmanager.err
Container killed on request. Exit code is 143
Container exited with a non-zero exit code 143
at org.apache.flink.yarn.YarnResourceManager.lambda$onContainersCompleted$0(YarnResourceManager.java:370)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRunAsync(AkkaRpcActor.java:397)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:190)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:152)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at akka.actor.Actor$class.aroundReceive(Actor.scala:517)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)
at akka.actor.ActorCell.invoke(ActorCell.scala:561)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)
at akka.dispatch.Mailbox.run(Mailbox.scala:225)
at akka.dispatch.Mailbox.exec(Mailbox.scala:235)
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)原因:内存不足,导致任务运行过程中,算子异常,出现自动重启现象
解决办法:增大taskmanager内存或增大Task Managers数;
8、flink消费kafka时,解析数据出错:
Caused by: java.lang.UnsupportedOperationException
at java.util.Collections$UnmodifiableCollection.add(Collections.java:1055)
at com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:109)
at com.esotericsoftware.kryo.serializers.CollectionSerializer.read(CollectionSerializer.java:22)
at com.esotericsoftware.kryo.Kryo.readObject(Kryo.java:679)
at com.esotericsoftware.kryo.serializers.ObjectField.read(ObjectField.java:106)
... 54 more解决办法:数据无法序列化出来,在获取flink环境时,加上配置(
env.getConfig().registerTypeWithKryoSerializer(Message.class, ProtobufSerializer.class);)此时Message.class改为自己实现的类。
9、flink消费数据,提交不了offset到kafka,报错如下:
throwable:org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:1151)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.ConsumerCoordinator$OffsetCommitResponseHandler.handle(ConsumerCoordinator.java:1081)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:1026)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.AbstractCoordinator$CoordinatorResponseHandler.onSuccess(AbstractCoordinator.java:1006)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.RequestFuture$1.onSuccess(RequestFuture.java:204)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.RequestFuture.fireSuccess(RequestFuture.java:167)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.RequestFuture.complete(RequestFuture.java:127)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient$RequestFutureCompletionHandler.fireCompletion(ConsumerNetworkClient.java:599)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.firePendingCompletedRequests(ConsumerNetworkClient.java:409)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:294)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.internals.ConsumerNetworkClient.poll(ConsumerNetworkClient.java:233)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.KafkaConsumer.pollForFetches(KafkaConsumer.java:1300)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1240)
at org.apache.flink.kafka.shaded.org.apache.kafka.clients.consumer.KafkaConsumer.poll(KafkaConsumer.java:1168)
at org.apache.flink.streaming.connectors.kafka.internal.KafkaConsumerThread.run(KafkaConsumerThread.java:253)
message:Consumer subtask 80 failed async Kafka commit场景:消费kafka写入hdfs时,要从spark任务迁移为flink任务消费,为保证不丢数据,用同一个groupid消费数据
原因:kafka的消费模式分为subscribe()和assign(),spark消费kafka的模式为subscribe(),flink的消费模式为assign()。此种场景会发生standalone consumer(assign()消费模式)与consumer group冲突。当用户系统中同时出现了standalone consumer和consumer group,并且它们的group id相同时,此时standalone consumer手动提交位移时就会立刻抛出此异常。原因:当来自 assign 模式的请求, group 的状态不为 Empty(!group.has(memberId)),也就是说,这个 group 已经处在活跃状态,assign 模式下的 group 是不会处于的活跃状态的,可以认为是 assign 模式使用的 group.id 与 subscribe 模式下使用的 group 相同,这种情况下就会拒绝 assign 模式下的这个 offset commit 请求。详情查看:Kafka的CommitFailedException异常和Consumer 两种订阅模式。
解决办法:将旧的spark任务下线后,执行以下脚本,然后用新的groupid去启动flink任务消费。以下脚本的作用是获取旧groupid的offset位置,然后用新的groupid去提交到此位置,启动flink任务就能从旧groupid的位置处开始消费。
from kafka import KafkaAdminClient, KafkaConsumer
client = KafkaAdminClient(bootstrap_servers='localhost:9092')
meta = client.list_consumer_group_offsets('test-1') // 旧的groupid
consumer = KafkaConsumer(bootstrap_servers='localhost:9092', group_id='test-2') //新的groupid
consumer.commit(meta)10、flink任务checkpoint失败,报错如下:
level:WARNlocation:org.apache.flink.runtime.scheduler.SchedulerBase.lambda$acknowledgeCheckpoint$4(SchedulerBase.java:796)log:2021-02-03 15:39:03,447 bigbase_kafka_to_hive_push_push_user_date_active WARN org.apache.flink.runtime.jobmaster.JobMaster - Error while processing checkpoint acknowledgement message
message:Error while processing checkpoint acknowledgement messagethread:jobmanager-future-thread-34throwable:org.apache.flink.runtime.checkpoint.CheckpointException: Could not finalize the pending checkpoint 11096. Failure reason: Failure to finalize checkpoint.
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.completePendingCheckpoint(CheckpointCoordinator.java:863)
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.receiveAcknowledgeMessage(CheckpointCoordinator.java:781)
at org.apache.flink.runtime.scheduler.SchedulerBase.lambda$acknowledgeCheckpoint$4(SchedulerBase.java:794)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.hadoop.fs.FileAlreadyExistsException: /user/flink/checkpoints/140ba889671225dea822a4e1f569379a/chk-11096/_metadata for client 172.xx.xx.xxx already exists
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInternal(FSNamesystem.java:3021)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2908)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2792)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:615)
at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.create(AuthorizationProviderProxyClientProtocol.java:117)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:413)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2278)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2274)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2272)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:73)
at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:1841)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1698)
at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1633)
at org.apache.hadoop.hdfs.DistributedFileSystem$7.doCall(DistributedFileSystem.java:448)
at org.apache.hadoop.hdfs.DistributedFileSystem$7.doCall(DistributedFileSystem.java:444)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:459)
at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:387)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:910)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:891)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:788)
at org.apache.flink.runtime.fs.hdfs.HadoopFileSystem.create(HadoopFileSystem.java:141)
at org.apache.flink.runtime.fs.hdfs.HadoopFileSystem.create(HadoopFileSystem.java:37)
at org.apache.flink.runtime.state.filesystem.FsCheckpointMetadataOutputStream.<init>(FsCheckpointMetadataOutputStream.java:65)
at org.apache.flink.runtime.state.filesystem.FsCheckpointStorageLocation.createMetadataOutputStream(FsCheckpointStorageLocation.java:109)
at org.apache.flink.runtime.checkpoint.PendingCheckpoint.finalizeCheckpoint(PendingCheckpoint.java:274)
at org.apache.flink.runtime.checkpoint.CheckpointCoordinator.completePendingCheckpoint(CheckpointCoordinator.java:854)
... 9 more
Caused by: org.apache.hadoop.ipc.RemoteException: /user/flink/checkpoints/140ba889671225dea822a4e1f569379a/chk-11096/_metadata for client 172.xx.xx.xxx already exists
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInternal(FSNamesystem.java:3021)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2908)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2792)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:615)
at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.create(AuthorizationProviderProxyClientProtocol.java:117)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:413)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2278)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2274)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1924)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2272)
at org.apache.hadoop.ipc.Client.call(Client.java:1476)
at org.apache.hadoop.ipc.Client.call(Client.java:1413)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy25.create(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.create(ClientNamenodeProtocolTranslatorPB.java:296)
at sun.reflect.GeneratedMethodAccessor63.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy26.create(Unknown Source)
at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:1836)
... 25 more场景:很多flink任务运行一段时间后checkpoint失败,多次后能自动恢复
原因:有次flink集群故障,导致很多任务自动重启,重启后旧的checkpoint文件没被删除(非正常重启,集群配置state.checkpoints.num-retained: 10失效),checkpoint文件命名从最初的命名,每次自增1,当自增到和上次未删除的checkpoint文件名称相同时,会报以上错,表示checkpoint文件已经存在,导致checkpoint失败。
解决办法:如果集群中配置checkpoint保留最近的10个,最多失败10次恢复或者下线重新启动恢复。(详见:[FLINK-21250] Failure to finalize checkpoint due to org.apache.hadoop.fs.FileAlreadyExistsException: /user/flink/checkpoints/9e36ed4ec2f6685f836e5ee5395f5f2e/chk-11096/_metadata for client xxx.xx.xx.xxx already exists - ASF JIRA)
11、flink消费kafka,然后生产到kafka,报错:
Caused by: org.apache.kafka.common.KafkaException: org.apache.kafka.common.KafkaException: Unexpected error in InitProducerIdResponse; The transaction timeout is larger than the maximum value allowed by the broker (as configured by transaction.max.timeout.ms).
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) ~[?:1.8.0_121]
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) ~[?:1.8.0_121]
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) ~[?:1.8.0_121]
at java.lang.reflect.Constructor.newInstance(Constructor.java:423) ~[?:1.8.0_121]
at java.util.concurrent.ForkJoinTask.getThrowableException(ForkJoinTask.java:593) ~[?:1.8.0_121]
at java.util.concurrent.ForkJoinTask.reportException(ForkJoinTask.java:677) ~[?:1.8.0_121]
at java.util.concurrent.ForkJoinTask.invoke(ForkJoinTask.java:735) ~[?:1.8.0_121]
at java.util.stream.ForEachOps$ForEachOp.evaluateParallel(ForEachOps.java:160) ~[?:1.8.0_121]
at java.util.stream.ForEachOps$ForEachOp$OfRef.evaluateParallel(ForEachOps.java:174) ~[?:1.8.0_121]
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:233) ~[?:1.8.0_121]
at java.util.stream.ReferencePipeline.forEach(ReferencePipeline.java:418) ~[?:1.8.0_121]
at java.util.stream.ReferencePipeline$Head.forEach(ReferencePipeline.java:583) ~[?:1.8.0_121]
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.abortTransactions(FlinkKafkaProducer.java:1263) ~[stream-sdk-examples-1.3.3-SNAPSHOT-flink-1.12.1.jar:?]
at org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer.initializeState(FlinkKafkaProducer.java:1189) ~[stream-sdk-examples-1.3.3-SNAPSHOT-flink-1.12.1.jar:?]
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.tryRestoreFunction(StreamingFunctionUtils.java:189) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.restoreFunctionState(StreamingFunctionUtils.java:171) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.initializeState(AbstractUdfStreamOperator.java:96) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.api.operators.StreamOperatorStateHandler.initializeOperatorState(StreamOperatorStateHandler.java:111) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:290) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.runtime.tasks.OperatorChain.initializeStateAndOpenOperators(OperatorChain.java:425) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$beforeInvoke$2(StreamTask.java:535) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$SynchronizedStreamTaskActionExecutor.runThrowing(StreamTaskActionExecutor.java:93) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:525) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:565) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:770) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:585) ~[flink-dist_2.11-1.12.1.jar:1.12.1]
at java.lang.Thread.run(Thread.java:745) ~[?:1.8.0_121]
Caused by: org.apache.kafka.common.KafkaException: Unexpected error in InitProducerIdResponse; The transaction timeout is larger than the maximum value allowed by the broker (as configured by transaction.max.timeout.ms).
at org.apache.kafka.clients.producer.internals.TransactionManager$InitProducerIdHandler.handleResponse(TransactionManager.java:1151) ~[kafka-clients-2.4.1.jar:?]
at org.apache.kafka.clients.producer.internals.TransactionManager$TxnRequestHandler.onComplete(TransactionManager.java:1074) ~[kafka-clients-2.4.1.jar:?]
at org.apache.kafka.clients.ClientResponse.onComplete(ClientResponse.java:109) ~[kafka-clients-2.4.1.jar:?]
at org.apache.kafka.clients.NetworkClient.completeResponses(NetworkClient.java:569) ~[kafka-clients-2.4.1.jar:?]
at org.apache.kafka.clients.NetworkClient.poll(NetworkClient.java:561) ~[kafka-clients-2.4.1.jar:?]
at org.apache.kafka.clients.producer.internals.Sender.maybeSendAndPollTransactionalRequest(Sender.java:425) ~[kafka-clients-2.4.1.jar:?]
at org.apache.kafka.clients.producer.internals.Sender.runOnce(Sender.java:311) ~[kafka-clients-2.4.1.jar:?]
at org.apache.kafka.clients.producer.internals.Sender.run(Sender.java:244) ~[kafka-clients-2.4.1.jar:?]
at java.lang.Thread.run(Thread.java:745) ~[?:1.8.0_121]场景:flink写入kafka时,配置EXACTLY_ONCE(flink1.15 DeliveryGuarantee.EXACTLY_ONCE和flink1.12 Semantic.EXACTLY_ONCE )时,报以上错误
原因:默认情况下,Kafka broker 将 transaction.max.timeout.ms 设置为 15 分钟。此属性不允许为大于其值的 producer 设置事务超时时间。 默认情况下,FlinkKafkaProducer 将 producer config 中的 transaction.timeout.ms 属性设置为 1 小时,因此在使用 Semantic.EXACTLY_ONCE 模式之前应该增加 transaction.max.timeout.ms 的值。
解决办法:生产者的超时时间调小或将broker的超时时间调大,修改producer超时时间如:
kafkaProducerConfig.put("transaction.timeout.ms", 15 * 60 * 1000);
12、flink读iceberg报如下错误:
Exception in thread "main" java.lang.NoClassDefFoundError: Lorg/apache/flink/connector/file/src/util/Pool;
at java.lang.Class.getDeclaredFields0(Native Method)
at java.lang.Class.privateGetDeclaredFields(Class.java:2583)
at java.lang.Class.getDeclaredField(Class.java:2068)
at java.io.ObjectStreamClass.getDeclaredSUID(ObjectStreamClass.java:1872)
at java.io.ObjectStreamClass.access$700(ObjectStreamClass.java:79)
at java.io.ObjectStreamClass$3.run(ObjectStreamClass.java:506)
at java.io.ObjectStreamClass$3.run(ObjectStreamClass.java:494)
at java.security.AccessController.doPrivileged(Native Method)
at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:494)
at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:391)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1134)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)
at org.apache.flink.util.InstantiationUtil.serializeObject(InstantiationUtil.java:632)
at org.apache.flink.util.SerializedValue.<init>(SerializedValue.java:62)
at org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator.createJobVertex(StreamingJobGraphGenerator.java:747)
at org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator.createChain(StreamingJobGraphGenerator.java:607)
at org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator.setChaining(StreamingJobGraphGenerator.java:526)
at org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator.createJobGraph(StreamingJobGraphGenerator.java:183)
at org.apache.flink.streaming.api.graph.StreamingJobGraphGenerator.createJobGraph(StreamingJobGraphGenerator.java:121)
at org.apache.flink.streaming.api.graph.StreamGraph.getJobGraph(StreamGraph.java:993)
at org.apache.flink.client.StreamGraphTranslator.translateToJobGraph(StreamGraphTranslator.java:50)
at org.apache.flink.client.FlinkPipelineTranslationUtil.getJobGraph(FlinkPipelineTranslationUtil.java:39)
at org.apache.flink.client.deployment.executors.PipelineExecutorUtils.getJobGraph(PipelineExecutorUtils.java:56)
at org.apache.flink.client.deployment.executors.LocalExecutor.getJobGraph(LocalExecutor.java:104)
at org.apache.flink.client.deployment.executors.LocalExecutor.execute(LocalExecutor.java:82)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.executeAsync(StreamExecutionEnvironment.java:2095)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1983)
at org.apache.flink.streaming.api.environment.LocalStreamEnvironment.execute(LocalStreamEnvironment.java:68)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1969)
at com.iqiyi.iceberg.IcebergSourceTest.main(IcebergSourceTest.java:74)
Caused by: java.lang.ClassNotFoundException: org.apache.flink.connector.file.src.util.Pool
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 42 more场景:flink读iceberg时,由FlinkSource的方式改为IcebergSource时报错
原因:XX
解决办法:添加flink-connector-files包:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
持续更新中...

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)