005 在Mysql中,事务是如何实现的呢?
hello大家好,我是一个爱看底层的小码,对于每一个学习mysql数据库的同学来说,事务都是一个绕不开的话题,简单的说来事务是指访问并可能更新数据库中各项数据项的一个程序执行单元。事务的四个特征无非就是老生常谈的原子性,一致性,隔离性和持久性。可是如果真的去深究事务的实现原理,你们真的理解吗? 在我看来,一个正常的事务要达到怎么样的效果呢?或者说哪些是它最重要的点呢?无非是可靠和并发处理。 详
学软件技术,读第一手资料,去官方网站:MySQL 5.7参考手册
也可以看看比较经典的书籍,如《高性能MySQL》等
hello大家好,我是一个爱看底层的小码,对于每一个学习mysql数据库的同学来说,事务都是一个绕不开的话题,简单的说来事务是指访问并可能更新数据库中各项数据项的一个程序执行单元。事务的四个特征无非就是老生常谈的原子性,一致性,隔离性和持久性。可是如果真的去深究事务的实现原理,你们真的理解吗?
在我看来,一个正常的事务要达到怎么样的效果呢?或者说哪些是它最重要的点呢?无非是可靠和并发处理。
详细的说,可靠就是指数据库在执行crud操作(主要是c和u)时抛出异常或者数据库crash(崩溃)时需要保障数据库操作前后都是一致的。所以必须要知道在修改前后数据库所处的状态,所以这也是undo/redo log存在的意义(关于回退日志和重做日志的详细说明我可以再写一篇文章~~)。
并发处理从字面意思就可以理解,就是当多个并发的请求过来时,假如其中存在一个请求是对数据进行修改操作,那么这就会对数据造成影响,为了避免读取到脏数据(这也是对数据库进行并发操作时的一种数据不一致的情况),这时候就需要对事务之间进行隔离,实现这个就得用Mysql的隔离级别。这其中牵扯到的技术其实有三个,分别是日志文件,mysql锁技术和MVCC。下面我就介绍一下MySQL锁技术和MVCC基础,然后讲讲MySQL事务的实现原理和MySQL时如何保证事务的原子性和隔离性的。(至于日志文件,我想单独写一篇文章和bin log放在一起讲)。
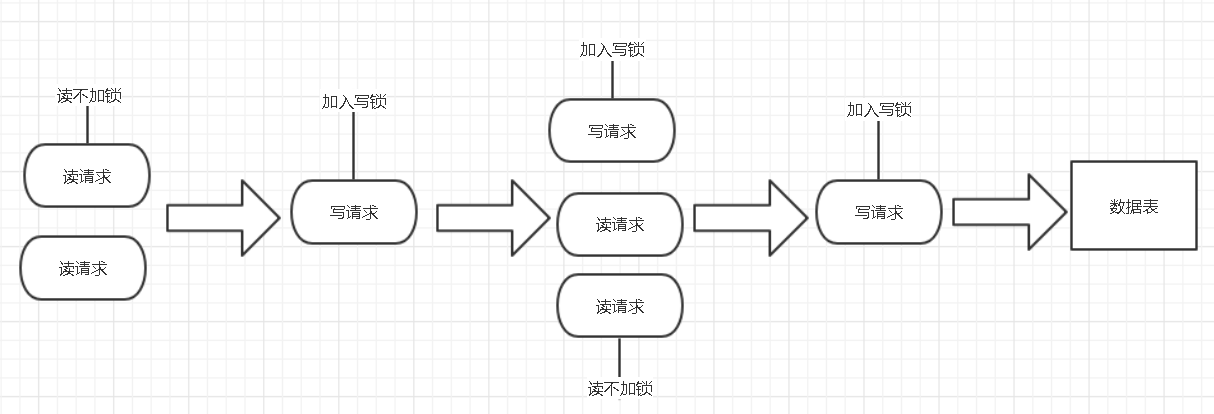
1.MySQL锁技术:当MySQL数据库接收到多个用户的请求时,假使其中一种请求是有修改请求时,就需要有一种措施来实现并发控制,要不非常容易出现数据不一致的情况——读写锁。想要解决这个问题,就需要将两种锁的组合来将读写请求分发控制。这两种锁就叫做读写锁,其中读锁又叫共享锁:读锁是可以共享的,也就是多个读请求可以共享一把锁读数据,不会造成请求的阻塞。写锁又叫做排他锁,写锁会排斥其他所有想要获取锁的请求,并将这些请求阻塞,知道写入完成后释放锁。当这两种锁组合起来时,兼容性如下面所示:

通过读写锁的这个机制,就可以非常完美的实现事务的隔离,这个下面再说。
2.MVCC基础:MVCC(MultiVersion Concurrency Control)叫做多版本并发控制。在小编这个被病毒封在家的冬天,在《高性能MySQL》这本书上看到过一段对于MVCC很详细的解释:“InnoDB(MySQL数据库的引擎之一)的MVCC,是通过在每行记录的后面保存两个隐藏的列来实现的,其中一个列保存行的创建时间,一个列保存了行的过期时间,当然存储的并不是实际的时间值,而是系统的版本号。”简单说来实现是想就是通过数据的多版本来做到读写分离的操作,从而就可以做到不加锁读进而做到读写并行。而MySQL在mysql实现依赖的就是undo log和read view。其中undo log中有记录某行数据的多个版本数据,read view可以用来判断当前版本数据的可见性,关于读写锁在提交读级别下的应用如下图所示:

说了这么多,其实都是为了最后讲出事务是如何实现的。上面讲的锁技术和MVCC机制其实都是事务实现的基础,其中事务的原子性通过undo log‘来实现,事务的持久性是通过redo log来实现,事务的隔离性是通过读写锁和MVCC实现,而事务的一致性就是原子性持久性和隔离性一起实现的。所以总结起来,事务就是为了保障可靠,一致。那么原子性,持久性,隔离性和隔离性具体是如何实现的呢?
首先就是原子性,原子性的定义就不和大家说了,简单理解就是要不全部成功,要不全部失败。不能部分执行,那MySQL是怎么实现的呢?通过undo log将发生错误异常或者显示时,执行rollback语句把数据还原到原先的模样。接下来看一下undo log在实现事务原子性时怎么发挥作用的
undo log 的生成:假设有两个表 bank和finance,表中原始数据如下面图所示:
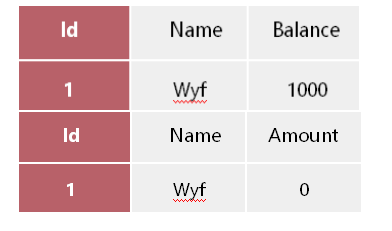
若对表进行更新操作时,比如从账户里取出500到理财账户上,这时就会生成如下的undo log。

这样每一次数据的变化都会引起undo log的的产生,这样每一次数据的变化(cud)都会伴随一条undo log的生成,并且在日志生成之后会先行持久化到磁盘之上,比数据持久化早一些。而回滚操作,就是靠着undo log日志中记载的操作变化进行逆向操作,添加数据变为删除,删除数据变为添加,修改数据变为修改成日志上记载的数据。那么大家知道为什么要先写日志后写数据库?--- 稍后做解释
根据undo log 进行回滚:为了做到同时成功或者失败,当系统发生错误或者执行rollback操作时需要根据undo log 进行回滚。也就是要还原到原来的状态,undo log记录了数据被修改前的信息以及新增和被删除的数据信息,根据undo log生成回滚语句,比如如果在回滚日志里有新增数据记录,则生成删除该条的语句,其他类型的以此类推。
持久性的实现:事务一旦提交之后,所做的修改将永久的保存在数据库里面,即便数据库出现crash的现象也不会丢失相应的数据。MySQL数据库的表数据都是存在磁盘上,因此想要存取数据都要经历磁盘IO,但是这样是非常消耗性能的。所以为了提高性能,InnoDB提供了缓冲池(buffer pool),缓冲池里面包含了磁盘数据页的映射,这样就可以当作缓存来使用。当用户进行读数据操作时,MySQL会先从缓冲池里读取,如果没有该数据的话在从磁盘读取数据放入缓冲池;当用户进行写数据操作时,数据同样会先写入缓冲池当中,之后缓冲池里面的数据才会定期同步到磁盘当中去。但是这样虽然看着方面,也提高了性能,但是加入出现电脑死机或者断电的轻缓,就有可能丢失相应数据,而这时就是redo log出现的时候了

或许看完图片很多人都疑惑,为什么redo log也需要存储并且同样涉及到磁盘IO,为什么还要用它呢?这是因为首先redo log的存储是顺序存储,但缓存同步是随机操作。同样缓存同步是以数据页为单位的,每次传输的数据大小要比redo log大。
隔离性的实现:如果算实现难易程度的话,隔离性应该是最难实现的一个,不知道大家还记不记得SQL的四个隔离级别,每一个级别都规定了一个事务中出现修改时,哪些是事务之间可见的,哪些是事务之间不可见的。级别越低的隔离级别可以执行更高的并发,但是同时实现的复杂度和开销也就越大,MySQL的四个隔离级别从低到高分开是:readuncommited(未提交读),readcommited(提交读),repeatableread(可重复读),serializable(可重复读)。隔离性也因为这四个级别和原子性及持久性有很大区别,原子性和一致性总的来说是为了给数据提供可靠的保障,比如死机之后数据如何恢复,已经数据出错之后进行数据回滚等等,而隔离性则是为了管理当多个并发读写请求访问时,合理的安排好每个请求的顺序,这种顺序包括了串行和并行两种,所以隔离性可以看作是关于数据性能和可靠之间的没有硝烟的战争,所以很容易就能得到当数据可靠性高时,并发性能自然也就低了比如serializable,可靠性低的,并发性能也就高了,比如readunconmmited。所以只有真正掌握了四个隔离级别的优缺点,才能够正确理解隔离性。
readunconmmited:在未提交读的隔离级别下,事务中的修改即使还没提交,对其他事务也是可见的,这样就很容易造成读脏数据的现象。因为读请求是不会添加任何锁的,所以假如写操作在读的过程中修改数据,就会出现数据不一致的情况,但是这种隔离级别读操作不能排斥写请求,也就提高了并发处理的性能,从而做到读写并行。
readcommited:在提交读的隔离级别下,一个事务的修改在他提交之前对其他事务都是不可兼得。其他事务只可以读到已提交的修改数据变化,在很多场景下这种逻辑是可以接受的。InnoDB在readcommited中使用了MVCC机制,或者换句话就是读写分离机制。但是在这个级别下会产生不可重复读(在一个事务中多次读取的结果不一样)的问题,为什么会产生这种问题呢?这个和MVCC的机制有关系,在这个隔离级别下每次进行select操作时都会在其生成一个新的版本号,这样每次select读到的不是一个副本而是不同的副本。这样在每次select之间假使有其他事物更新我们读取的数据并提交后,就出现了不可重复读的现象。
repeatableread(MySQL默认隔离级别):在一个事务中多次读取的数据结果是一样的,这种级别可以有效的避免脏读及不可重复读等查询问题,MySQL有两种机制都可以达到这种隔离级别分别是用读写锁:

这样为什么能够实现重复读呢?是因为只要没释放读锁,在次读的时候都可以读到第一次读到的数据,这样虽然实现简单,但是却无法实现读写并行。另外一种是MVCC实现:

这样为什么可以重复读呢?是因为多次读取到的数据只生成了一个版本,这样自然也就可以读到相同的数据,这样可以实现读写并行,但是实现起来复杂度极高。
serializable:这种序列化读级别下理解起来最简单实现起来也最简单,但是除了不会造成数据不一致的问题,就没有其他任何的优点了。

一致性的实现:对于一个数据库来说,总是从一种状态转移到另外一种状态:比如我要从一个银行卡转出400块钱到另外一个理财的账户中
| 1 2 3 4 5 6 7 |
|
假如执行完 update bank set balance = balance - 400;之后数据库发生了异常了,银行肯定不允许客户钱平白无故的减少,就可以回滚到最初的状态。又或者事务提交之后,缓冲池还没同步到磁盘的时候死机了了,这也是不能接受的,应该在重启的时候恢复并持久化。假如有并发事务请求的时候也应该做好事务之间的可见性问题,避免造成脏读,不可重复读,幻读等。在涉及并发的情况下往往在性能和一致性之间做平衡,做一定的取舍,所以从这个角度看,隔离性也是对一致性的一种逆向削弱。
最后,总的说来实现事务采取了哪些技术以及思想?原子性使用 undo log ,从而达到回滚;持久性:用 redo log,从而达到故障后恢复;隔离性使用锁以及MVCC,运用的优化思想有读写分离,读读并行,读写并行;一致性:通过回滚,以及恢复,和在并发环境下的隔离做到一致性。
原文地址:MySQL中如何实现事务的

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)