Redis哈希槽的概念
slot:称为哈希槽Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。使用哈希槽的好处就在于可以方便的添加或移...
利用阿里云监控平台,监控接口时看到一个非常慢的接口,点了进去,发现了slot标志
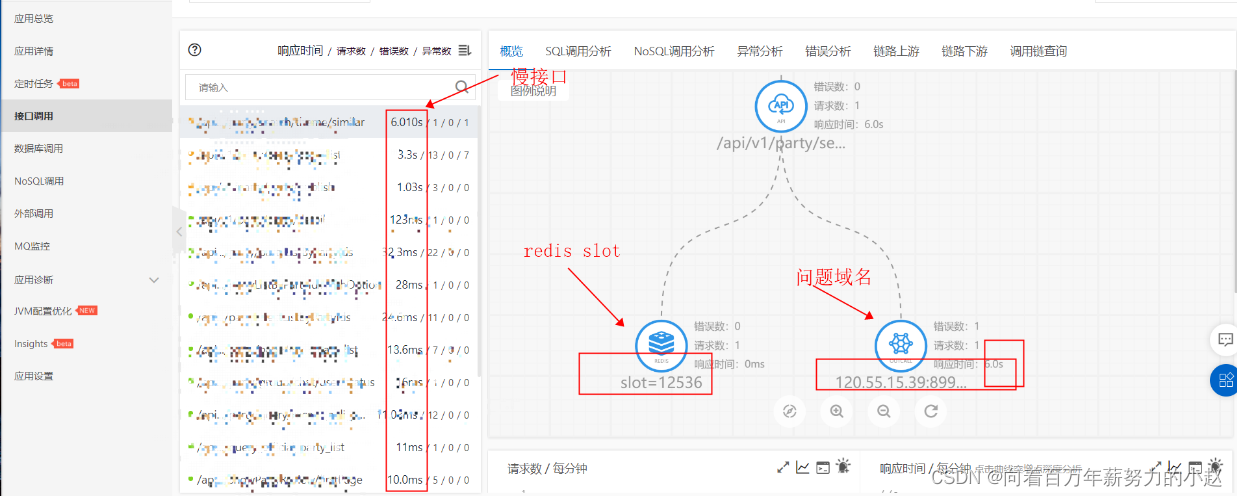
通过查阅资料,习得哈希槽的概念:
slot:称为哈希槽
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
使用哈希槽的好处就在于可以方便的添加或移除节点。
当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了;
在这一点上,我们以后新增或移除节点的时候不用先停掉所有的 redis 服务。
这里有个理解误区,有初学者会想,这个slot是不是存储数据的点?就是只能存16383+1个键?
实际并不是这样,这个slot只是对应节点(Redis服务)的一个存储范围(可以理解为这个Redis的别名)。
现有一个key要insert到Redis,那么根据 CRC16(key) mod 16384的值,比如得到3000,那就把这个key保存在A服务器里面了。读的时候也一样,有个key要去读,就先 CRC16(key) mod 16384 找到对应的slot,然后就去对应的服务器找数据。看起来,很像个索引吧。
想一个面试问题:
高并发的互联网公司中,有1亿条数据需要缓存,请问如何设计存储这批数据?
答:
单台服务器肯定存储不了这么大的数据,一般是分布式存储,就像数据库的分库分表一样存储,那针对缓存redis如何分布式存储这么大的数据?
利用哈希槽的做法:
哈希槽其实就是一个数组,数组[0, 1, 2, …, 2^14-1]形成hash slot空间
- 把哈希槽均匀分段,分配给redis节点
redis节点1,负责存储5461个哈希槽的数据,编号0号至5460号哈希槽
redis节点2,负责存储5462个哈希槽的数据,编号5461号至10922号哈希槽
redis节点3,负责存储5461个哈希槽的数据,编号10923号至16383号哈希槽 - 计算每条数据的slot空间位置
- 将数据key进行哈希取值,映射已经固定大小的hash slot空间上
例如:可以采用spring redis的API
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
例如:我们往redis设置3条数据:
redisTemplate.opsForValue.set(“A”, “agan1”);
redisTemplate.opsForValue.set(“B”, “agan2”);
redisTemplate.opsForValue.set(“C”, “agan3”);
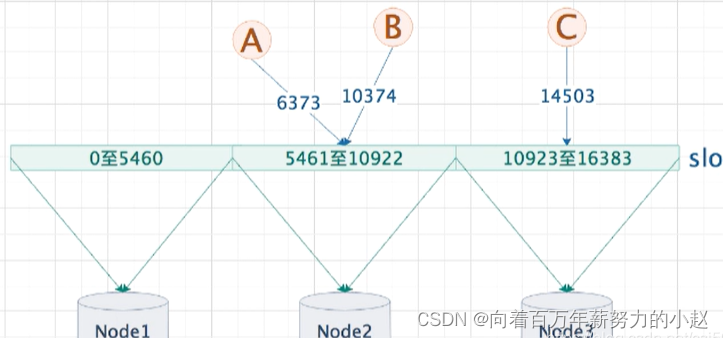
然后计算key,A、B、C的slot槽位置
io.lettuce.core.cluster.SlotHash.getSlot(“A”)=6373
io.lettuce.core.cluster.SlotHash.getSlot(“B”)=10374
io.lettuce.core.cluster.SlotHash.getSlot(“C”)=14503
故,
key A、B落在slot空间的5461至10922区间上,并最终存储在Node 2上
key C落在slot空间的10923至16383区间上,并最终存储在Node 3上
redis哈希槽分区的特点:
1)解耦数据和节点之间的关系,例如:数据的读写只要计算出槽号就可以,节点的扩容和收缩只要重新均衡分配槽区间即可;故简化了节点扩容和收缩难度
2)节点自身维护槽的映射关系,不需要客户端(spring)或者代理服务维护槽分区和数据
3)支持节点、槽、键之间的映射查询,用于数据路由、在线伸缩等场景
数据和槽号是绑在一起的,spring通过槽号找到节点


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 44
44 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)