聚簇索引与非聚簇索引详解
概念区分:聚簇索引:将索引与数据放在一起,当你找到索引后,也就找到对应的数据了。每张表只能建立一个聚簇索引,但是该索引可以包含多个列(一般使用的是主键等不经常更新的列)非聚簇索引:数据储存于索引分开,叶节点指向了对应的数据行。Innodb引擎1)主键索引:innodb默认为主键是索引,若想设置其他为聚簇索引的话,需要先删除主键,设置索引,再恢复主键才能生效;如果没有显式指定,则MySQL系统会自动
概念区分:
聚簇索引:将索引与数据放在一起,当你找到索引后,也就找到对应的数据了。每张表只能建立一个聚簇索引,但是该索引可以包含多个列(一般使用的是主键等不经常更新的列)
非聚簇索引:数据储存于索引分开,叶节点指向了对应的数据行。
Innodb引擎
1)主键索引:
innodb默认为主键是索引,若想设置其他为聚簇索引的话,需要先删除主键,设置索引,再恢复主键才能生效;
如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,数据文件叶节点存放着每一行的数据,叶节点前面的key存放的是主键的值。
用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,一般建议使用自增的主键。
2)辅助索引:
InnoDB 表是基于聚簇索引建立的,辅助索引会引用主键作为data域,存放叶节点之中。
这就导致辅助索引查找会进行两次检索:第一次检索到相应的主键,第二次通过主键检索到对应的数据。也就是说,辅助索引是基于主键索引来进行查找的。由此可以判断辅助索引的性能是基于主键的,若主键定义的比较长,那么辅助索引也会相应的收到影响。
示例:
设置一个innodb表,id作为自增主键,name设置为辅助索引。若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISAM引擎
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址
1)主键索引
可以没有主键
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
2)辅助索引
辅助索引和主键索引结构上没有任何区别,唯一限制是主键索引是唯一的,而辅助索引是可以重复的,data域都是储存的是数据地址
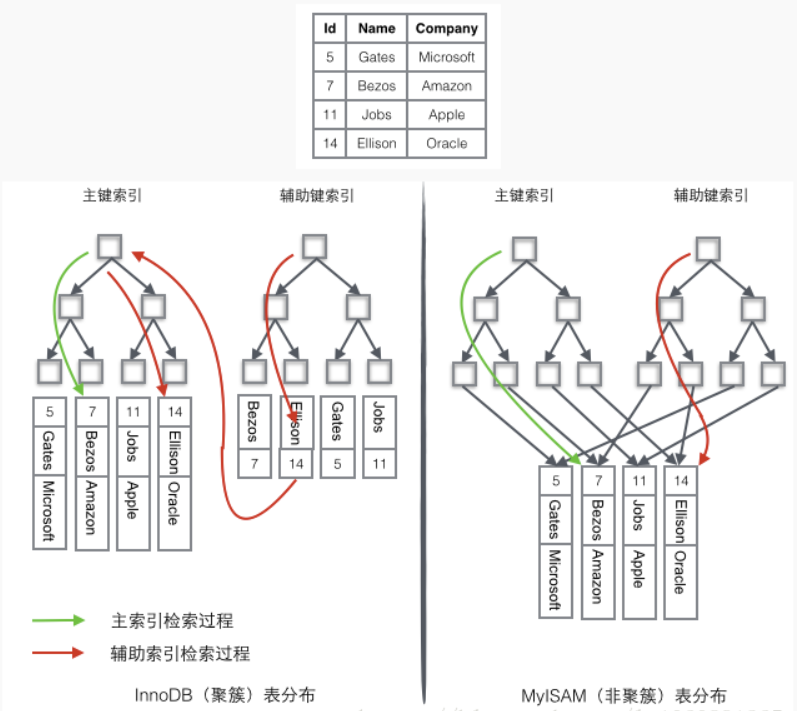
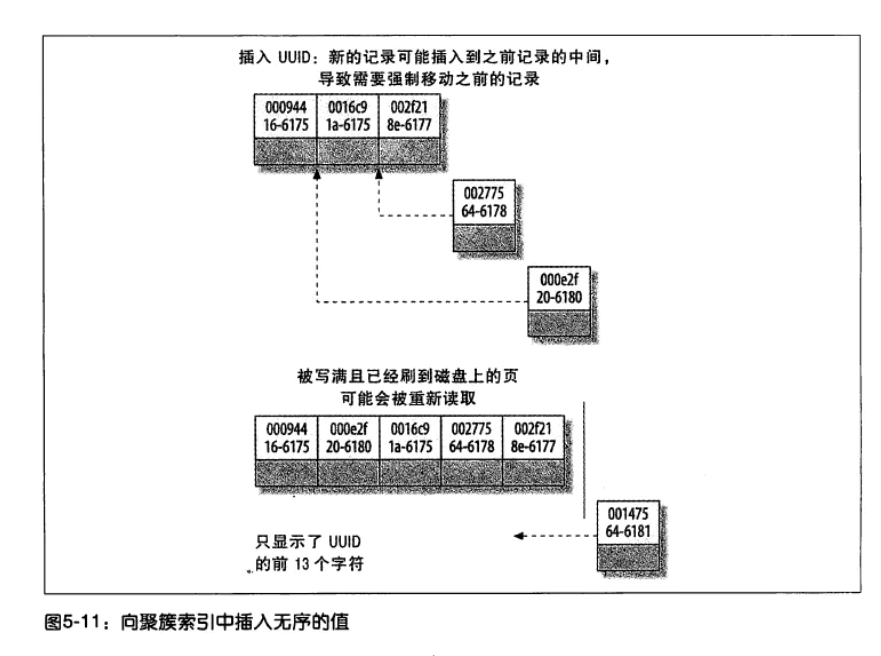
聚簇索引物理储存位置与索引顺序是一致的,也就是说索引相邻,那么物理储存位置也一定是相邻的,存放数据就完全按照顺序进行存放。一般不建议使用uuid随机生成主键作为值(如下图)因为索引的不连续,不得不一直调整数据的物理地址,分页,从而索引相对比较稀疏,磁盘碎片也比较多,可能导致查询时,比全面扫描花费的时间更多
查询时的区别
mylsam查询比innodb速度快的原因
1)innodb不会压缩索引 查询时需要缓存数据块,而mylsam数据和索引是分开的,可以压缩索引,在相同容量的内存加载更多的数据
2) innodb寻址要映射到块,再到行(个人猜想主要是查询行的版本号),MYISAM记录的直接是文件的OFFSET,定位比INNODB要快
(注释: SELECT InnoDB必须每行数据来保证它符合两个条件: 1、InnoDB必须找到一个行的版本,它至少要和事务的版本一样老(也即它的版本号不大于事务的版本号)。这保证了不管是事务开始之前,或者事务创建时,或者修改了这行数据的时候,这行数据是存在的。2、这行数据的删除版本必须是未定义的或者比事务版本要大。这可以保证在事务开始之前这行数据没有被删除)
3)INNODB还需要维护MVCC一致;虽然你的场景没有,但他还是需要去检查和维护MVCC (Multi-Version Concurrency Control)多版本并发控制

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)