(一)spark是什么?
1.spark是什么?spark是一个用来实现快速,通用的集群计算平台spark适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理,迭代算法,交互式查询,流处理。通过在一个统一的框架下支持这些不同的计算,spark使我们可以简单而低耗地把各种处理流程整合在一起。2.spark的用途(1):数据科学任务具备 SQL、统计、预测建模(机器学习)等方面的经验,以及一定的python,matla
1.spark是什么?
spark是一个用来实现快速,通用的集群计算平台
spark适用于各种各样原先需要多种不同的分布式平台的场景,包括批处理,迭代算法,交互式查询,流处理。通过在一个统一的框架下支持这些不同的计算,spark使我们可以简单而低耗地把各种处理流程整合在一起。

2.spark的用途
(1):数据科学任务
具备 SQL、统计、预测建模(机器学习)等方面的经验,以及一定的python,matlab,R语言能力的数据科学家对数据进行分析,以回答问题或发现一些潜在规律。
(2):数据处理任务
Spark 的另一个主要用例是针对工程师的。在这里,我们把工程师定义为使用 Spark 开发
生产环境中的数据处理应用的软件开发者。这些开发者一般有基本的软件工程概念,比如
封装、接口设计以及面向对象的编程思想,他们通常有计算机专业的背景,并且能使用工
程技术来设计和搭建软件系统,以实现业务用例。
- Spark 为开发用于集群并行执行的程序提供了一条捷径。通过封装,Spark不需要开发者关注如何在分布式系统上编程这样的复杂问题,也无需过多关注网络通信和 程序容错性。
- Spark已经为工程师提供了足够的接口来快速实现常见的任务,以及对应用 进行监视、审查和性能调优。其
3.spark简史
Spark 是由一个强大而活跃的开源社区开发和维护的,社区中的开发者们来自许许多多不 同的机构。如果你或者你所在的机构是第一次尝试使用
Spark,也许你会对 Spark 这个项 目的历史感兴趣。Spark 是于 2009 年作为一个研究项目在加州大学伯克利分校 RAD 实验
室(AMPLab 的前身)诞生。实验室中的一些研究人员曾经用过 Hadoop MapReduce。他 们发现 MapReduce
在迭代计算和交互计算的任务上表现得效率低下。因此,Spark 从一开
始就是为交互式查询和迭代算法设计的,同时还支持内存式存储和高效的容错机制。 2009 年,关于 Spark 的研究论文在学术会议上发表,同年
Spark 项目正式诞生。其后不久, 相比于 MapReduce,Spark 在某些任务上已经获得了 10 ~ 20 倍的性能提升。
2011 年,AMPLab 开始基于 Spark 开发更高层的组件,比如 Shark(Spark 上的 Hive)1 和 Spark
Streaming。这些组件和其他一些组件一起被称为伯克利数据分析工具栈(BDAS,
https://amplab.cs.berkeley.edu/software/)。 Spark 最早在 2010 年 3 月开源,并且在
2013 年 6 月交给了 Apache 基金会,现在已经成了 Apache 开源基金会的顶级项目。
4.spark的存储层次
Spark 不仅可以将任何 Hadoop 分布式文件系统(HDFS)上的文件读取为分布式数据集,
也可以支持其他支持 Hadoop 接口的系统,比如本地文件、亚马逊 S3、Cassandra、Hive、
HBase 等。我们需要弄清楚的是,Hadoop 并非 Spark 的必要条件,Spark 支持任何实现
了 Hadoop 接口的存储系统。Spark 支持的 Hadoop 输入格式包括文本文件、SequenceFile、
Avro、Parquet 等
5.spark核心概念简介
每个 Spark 应用都由一个**驱动器程序(driver program)**来发起集群上的各种并行操作。驱动器程序包含应用的 main 函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作。驱动器程序通过一个 SparkContext 对象来访问 Spark。这个对象代表对计算集群的一个连接。shell 启动时已经自动创建了一个 SparkContext 对象,是一个叫作 sc 的变量。我们可以通过例 2-3 中的方法尝试输出 sc 来查看它的类型。
>>> sc
<pyspark.context.SparkContext object at 0x1025b8f90>
一旦有了 SparkContext,你就可以用它来创建 RDD。
要执行这些操作,驱动器程序一般要管理多个执行器(executor)节点。
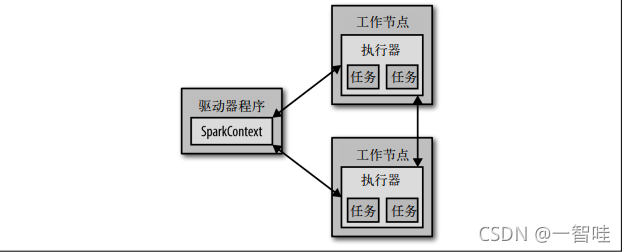
除了交互式运行之外,Spark 也可以在 Java、Scala 或 Python 的独立程序中被连接使用。这与在 shell 中使用的主要区别在于你需要自行初始化 SparkContext。
- 连接spark的过程在各种语言中不同,在java中,只需要添加一个对于spark-core的Maven依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
- 初始化SparkContext
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("My App");
//集群 URL:告诉 Spark 如何连接到集群上。
// local这个特殊值可以让 Spark 运行在单机单线程上而无需连接到集群。
//应用名:My App 集群管理器的用户界面中
JavaSparkContext sc = new JavaSparkContext(conf);
参考文献:
- 《Spark快速大数据分析》

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)