
SQL查询速度慢的原因分析及解决方案【案例分享】
本篇简单小结一下项目中遇到的SQL慢查询的问题,以及解决方案,欢迎打卡,阅读,学习交流!
【辰兮要努力】:hello你好我是辰兮,很高兴你能来阅读,昵称是希望自己能不断精进,向着优秀程序员前行!
博客来源于项目以及编程中遇到的问题总结,偶尔会有读书分享,我会陆续更新Java前端、后台、数据库、项目案例等相关知识点总结,感谢你的阅读和关注,希望我的博客能帮助到更多的人,分享获取新知,大家一起进步!
吾等采石之人,应怀大教堂之心,愿我们奔赴在各自的热爱里…
本篇简单小结一下项目中遇到的SQL慢查询的问题,以及解决方案。
一、检测SQL是否执行索引
首先我们要检查SQL是否走索引,或者检查是否出现索引失效的情况
如果是单条sql可以独立拿出来执行,使用explain进行相关分析

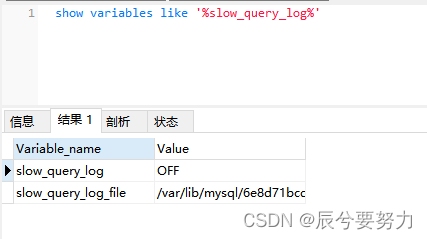
对应MySQL中有慢查询日志对应的功能,MySQL慢查日志功能默认是关闭的,我们配置后可以打开,进行分析相关SQL,系统上线后还是建议关闭,感兴趣的自己可以了解
show variables like '%slow_query_log%'
二、数据分库分表
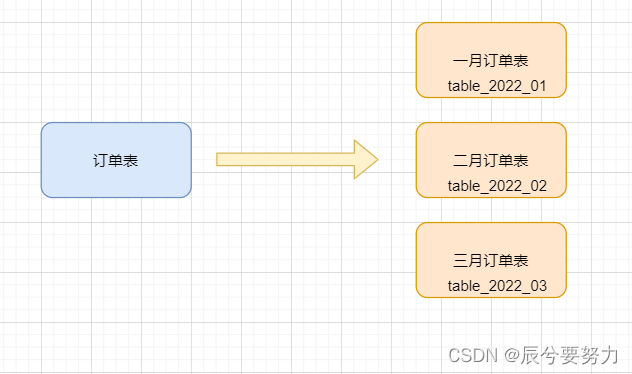
很多时候可能单表的数据量过大会导致,比如订单表达到千万数据,我们可以按月进行水平拆分
如:将一千万的数据,按一定规律,拆分成十张百万数据量的表,如上利用好索引,查询速度会大大提高
分表案例如下
分库分表能有效的缓解了单机和单库带来的性能瓶颈和压力,突破网络IO,硬件资源,连接数的瓶颈,同时也带来了一些问题
- 分库:就是一个数据库分成多个数据库,部署到不同机器。
- 分表:就是一个数据库表分成多个表。
分库分表我理解的是两个概念 后续有机会再单独整理文章
分库是解决数据库性能瓶颈的问题,如并发等等
分表可以解决单表数据量过大,导致查询变慢的问题
三、热点数据问题
对于热点数据涉及到频繁查询,每次查询都会涉及到数据库,我们可以引入Redis缓存
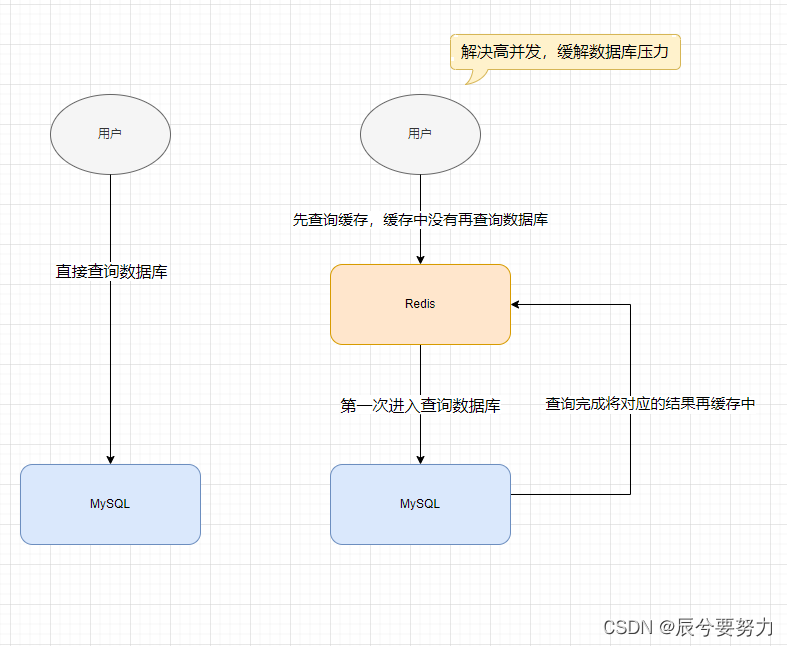
B端产品利用Redis优化查询速度:Redis的使用场景分享(项目实战)
四、性能瓶颈问题
引入读写分离
业务场景:部分时候出现慢查询可能是因为机器负载过高
采用读写分离的方式,提升数据库的整体性能
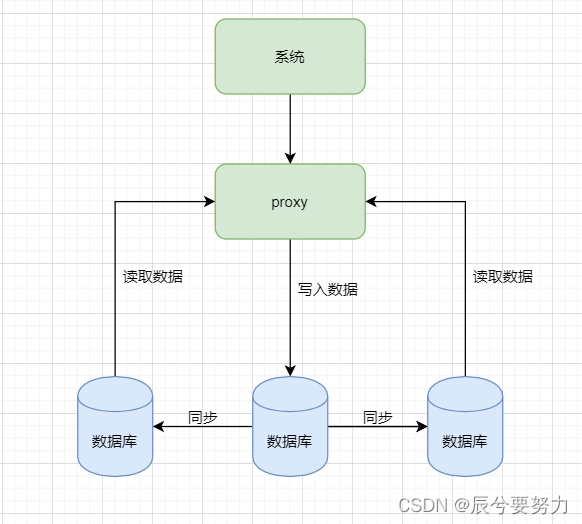
什么是读写分离?
其实就是将数据库分为了主从库,一个主库用于写数据,多个从库用于读数据(读的操作比较多,所以常见设置一个或多个从库),主从数据库之间的数据通过某种机制保持同步,是一种常见的数据架构。
解决了什么问题?
读写分离是用来解决数据库的读性能瓶颈的。
📣非常感谢你阅读到这里,如果这篇文章对你有帮助,希望能留下你的点赞👍 关注❤️ 分享👥 留言💬thanks!!!
📚愿我们奔赴在各自的热爱里!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 12
12 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)