Mysql 批量插入大量数据的两种方案以及优缺点(分别是 5W 条数据和 10W 条数据)
Mysql 批量插入大量数据的两种方案以及优缺点(分别是 5W 条数据和 10W 条数据)
Mysql 批量插入(5W 条数据和 10W 条数据)
1、批量插入思路
一般是有两种不同的思路:
1、for 循环批量插入
2、生成一条 SQL 语句,比如 insert into user(id,username) values(1,“zs”),(2,“ls”)…
2、两种思路的优缺点
a、for循环的优劣势
如果是 for 循环,那么优势是:
- PreparedStatement 有预编译功能。
劣势:
- 要插入 10W 次,需要 10W 次网络 IO。
b、SQL 语句的优劣势
如果是单条 SQL 语句,那么优势是:
- 一条 SQL 搞定,只需要一次网络 IO。
劣势:
- 单条 SQL 过大,需要对数据分片。比如 10W 条数据,就分成两条包含 5W 数据的 SQL 语句。
- 单条 SQL 语句过大,MySQL 解析速度降低。
- 无法充分发挥 PreparedStatement 的预编译功能。
3、开始测试(这里测试 5W 条数据)
先在数据库中创建一张表。这个可以自行创建。
本来是打算测试 10W 条数据的插入。但因为单条 SQL 语句过大,会报错,需要分片,虽然分片不是难事,但是跟主题无关,所以这里采用 5W 条的数据进行测试。效果是一样的。结论也是一样的。
a、前期准备
这里用的是 SpringBoot 项目。
这里展示测试所用到的依赖:

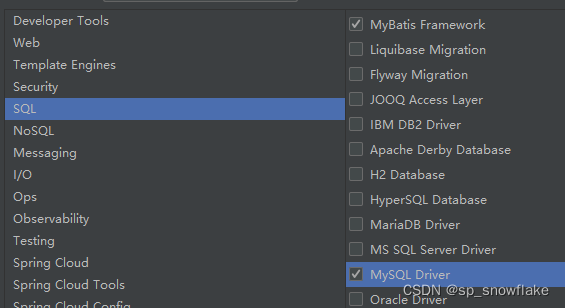
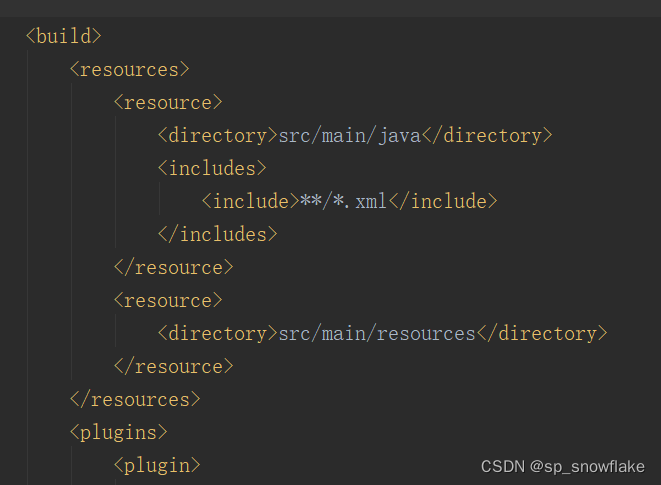
pom.xml 加这么一段:
数据库:

然后是 mapper:
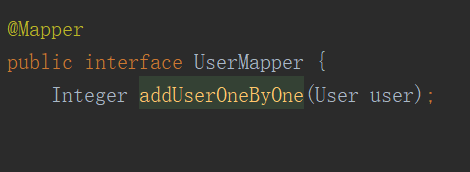
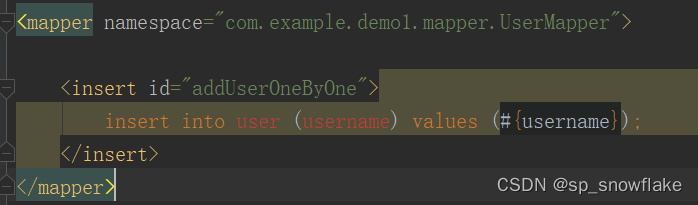
实体类自己看情况写;
然后是 service:
为了切实看到效果,这里先演示一遍错误的写法:
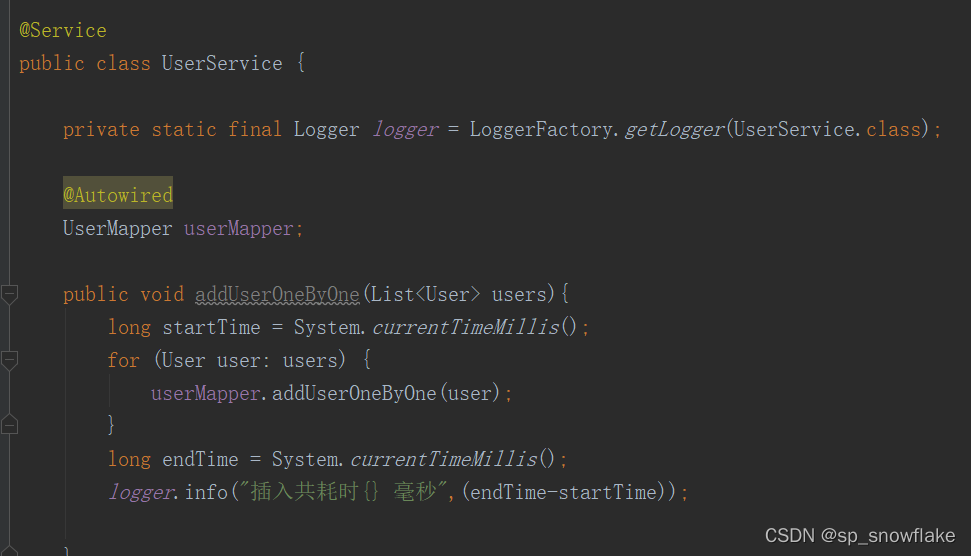
b、开始测试(最原始的 for 循环)
测试代码:

结果:

这里其实演示的是非常原始的 for 循环,并没有利用到 jdbc 里面提供的批处理。
b、第二次测试(使用 jdbc 的批处理)
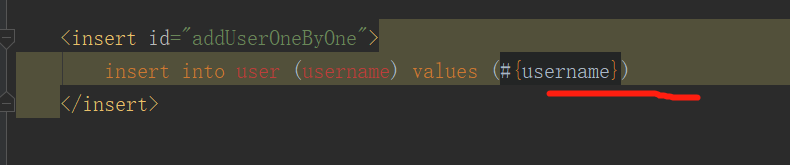
如果想要使用 jdbc 提供的批处理功能,那么有个强制性的要求就是 sql 语句最后不能有分号。 看下图:
但是这样还不够,如果只是这样还是用不上批处理。还需要在配置文件数据库 url 那一块的最后面需要加一个参数, 如果不加这个参数,即便代码使用了批处理,jdbc 也会忽略掉,这个参数特别重要,看下图:

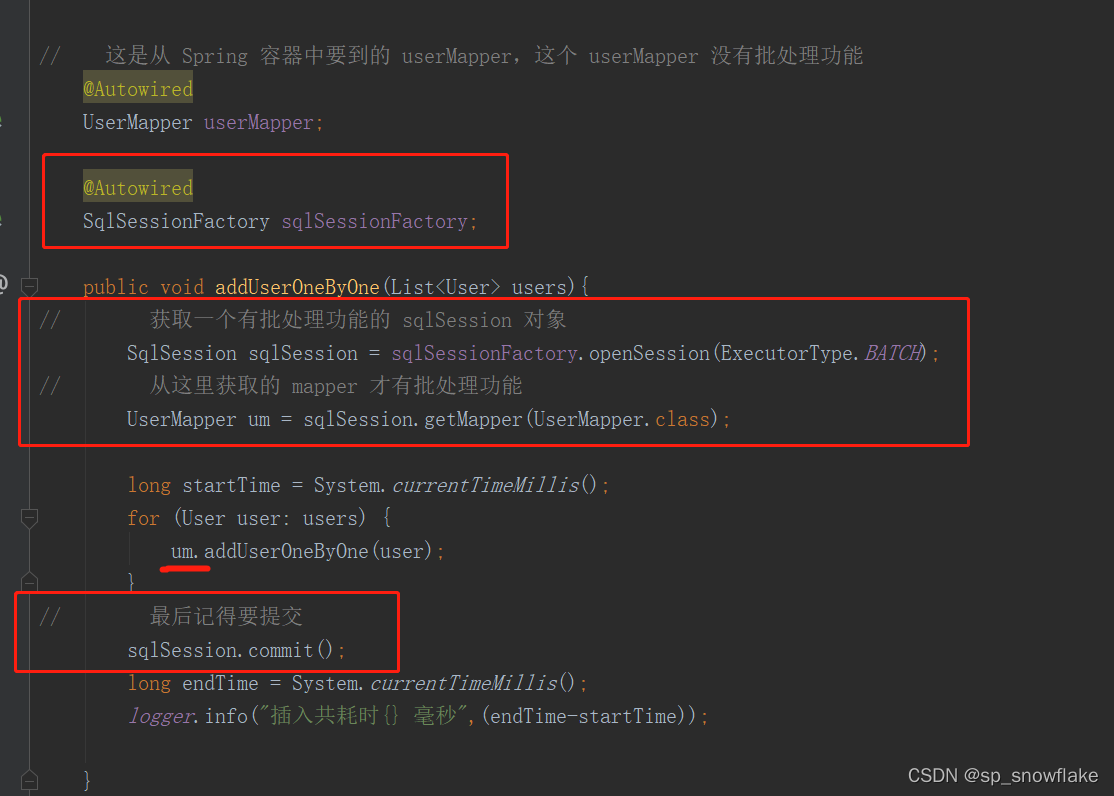
还不够,不能使用 mapper,因为这玩意不具备使用批处理的功能,这就是一个很普通的 mapper。这玩意先获取数据库链接,然后执行插入,插入需要开启事务,数据插入完后再提交事务,提交完后又去开启事务插入;就这样执行 5W 次,这样效率能不慢吗。
所以要获取带有批处理的功能的 mapper;修改 service 的代码即可:
到这里就搞完了。
接着清空数据,再执行:

最后测试效果:
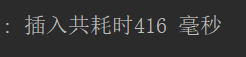
可以看到,非常明显,效率快了非常多。能这么快的原因除了开启了批处理功能,还有就是博主这个机子的性能太好了,所以会相当快。
c、第三次测试(单条 SQL)
mapper :

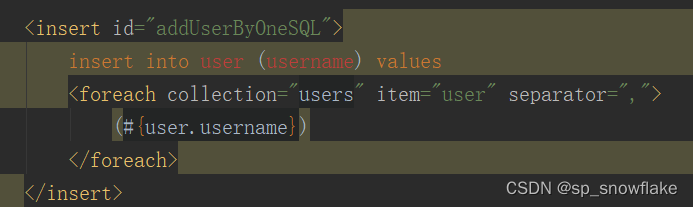
server:
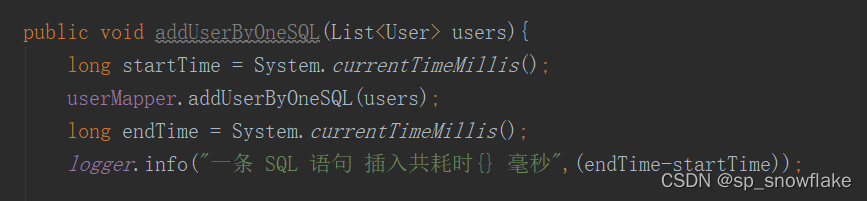
测试代码:

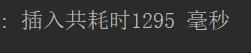
最终效果:

可以看到明显是比批处理的 for 循环慢的。
4、测试 10W 条数据
这里直接上结论
a、批处理 for 循环

b、单条 SQL 语句
注意,这里有可能会报这个错误:

单条 SQL 语句过大。
这里有两个解决办法:一是分片,分片成更小的 SQL 语句去执行插入,但是这本来效率就比上面的慢, 还要分片,那就更慢了。
二是去 C盘下的 mysql 的配置文件 my.ini(这里自行百度路径)里面的 max_allowed_packet 。如果没有,可以自行添加在 [ mysqld ] 下面。去修改里面的默认大小,默认缓存是 1M,这里为了方便测试改成了 16M(16 * 1024 * 1024)。
然后最终结果:
5、最终结论
最终结论就是:
批处理的 for 循环比 单条 SQL 语句更快。
如果是慢的,要检查数据库 url 那里有没有参数,或者有没有打错。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)