Oracle sql 执行顺序及原理详解
文章目录1 概述2 执行原理3 执行顺序3.1 语法顺序3.2 整体:从内到外,从下到上,从右到左1 概述2 执行原理1. 第一步:'客户端' 把语句发给 '服务器端' 执行('用户进程' -> '服务器进程')(1) Oracle '客户端'(如:pl/sql Developer, sql*plus) 是不会做任何操作的,它的主要任务就是把 '客户端' 产生的 sql 语句发送给 '服务器
·
1 概述
2 执行原理
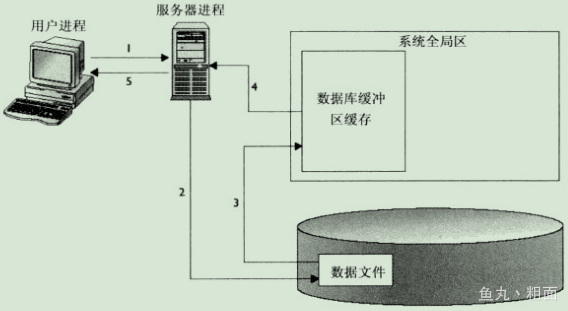
1. 第一步:'客户端' 把语句发给 '服务器端' 执行('用户进程' -> '服务器进程')
(1) Oracle '客户端'(如:pl/sql Developer, sql*plus) 是不会做任何操作的,
它的主要任务就是把 '客户端' 产生的 sql 语句发送给 '服务器端'
(2) Oracle '服务器端' 才会对 sql 语句进行处理
(3) '客户端' 的进程跟 '服务器端' 的进程是 "一一对应" 的
2. 第二步:语句解析
(1) 查询 '库缓存(librart cache)',是否存在 '相同语句的执行计划',
如果存在,服务器进程会 "直接执行(直接到第三步)" 这个 sql 语句('软解析'),省略后续步骤,提高查询效率
如果不存在,服务器进程会从硬盘中读取 '数据文件'('硬解析'),继续后续步骤
(2) '语法检查':是否合乎语法规则
(3) '语义检查':字段、表等内容是否在数据库中
(4) 获得 '对象解析锁':当 语法、语义都正确后,系统会对我们需要查询的对象加锁。
这主要是为了保证数据的一致性('事务特性之一'),防止我们在查询过程中,其他
用户对该对象的结构发生改变
(5) '权限检查':该用户是否拥有权限访问这些数据
(6) 确定 '最佳执行计划':Oracle 数据库对 SQL 语句自我优化
3. 第三步:语句执行
对于 select:首先 '服务器进程' 要判断所需数据是否在 '库缓存(librart cache)'
如果存在,则直接获取该数据而不是从 '数据库文件' 中去查询数据,
同时,根据 LRU(Least Recently Used 最近最少使用)算法增加其访问次数
如果不存在,则 '服务器进程' 将从 '数据库文件' 中查询相关数据,
并且,将这些数据放入到 '库缓存(librart cache)' 中
对于 update、insert、delete:
(1) 检查 sql 是否已经读取到 '库缓存(librart cache)'
如果已存在,则直接执行步骤 3
(2) 如果不存在,则 '服务器进程' 将 '数据块' 从 '数据文件' 读取到 '库缓存'
(3) 对想要修改的表取得数据的行锁定(Row Exclusive Lock)
(4) 将数据的 Redo 记录复制到 '重做日志缓冲区 Redo Log Buffer'
(5) 产生修改的 undo 数据
(6) 修改 '库缓存(librart cache)'
(7) 后台进程 dbwr 将修改写入 '数据文件'
4. 第四步:提取数据
可用到的相关视图:
select * from v$session t;
select * from v$sql t;
3 执行顺序
3.1 语法顺序
sql 查询大致语法结构如下:
(5) SELECT DISTINCT <..>
(1) FROM <..> JOIN <..> ON <..>
(2) WHERE <..>
(3) GROUP BY <..>
(4) HAVING <..>
(6) ORDER BY <..>
sql 语法处理的顺序如下:
1. FROM -- 首位,sql入口
2. ON
3. JOIN
4. WHERE
5. GROUP BY
6. HAVING
7. SELECT
8. DISTINCT
9. ORDER BY
3.2 整体:从内到外,从下到上,从右到左
- 实际开发中,
sql语句一般都挺复杂的,它们之前的执行顺序除了上述语法顺序外,还有一个整体的顺序,如 标题,这点,可通过F5(执行计划)进行查看。
验证:从内到外(子查询优先):

验证:从下到上,从右到左:

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)