springcloud进阶:四种分布式事务模式之AT模式(一)
0.引言之前我们讲解了分布式事务组件seata的快速入门,但是针对分布式事务本身的4种模式还没有详细的介绍,所以我们就针对于4种分布式事务模式详解,并且梳理一下他们的应用场景1. AT模式 (自动事务Auto Transaction)AT模式根据其名称也能反馈出来他的特性,他是自动型的分布式事务解决方案。这个自动提现在他无需代码入侵,也就是说我们不需要再编写多余的代码来实现这个模式,只需要在方法中
0.引言
之前我们讲解了分布式事务组件seata的快速入门,但是针对分布式事务本身的4种模式还没有详细的介绍,所以我们就针对于4种分布式事务模式详解,并且梳理一下他们的应用场景
1. AT模式 (自动事务Auto Transaction)
AT模式根据其名称也能反馈出来他的特性,他是自动型的分布式事务解决方案。这个自动提现在他无需代码入侵,也就是说我们不需要再编写多余的代码来实现这个模式,只需要在方法中添加上指定的注解即可。
那么AT模式是如何实现无代码入侵的呢?他的工作原理是什么?
1.1 AT模式原理总览
AT模式分成两阶段来工作,我们先省略部分细节来整体了解其过程:
- 一阶段:
(1)拦截并解析业务SQL,找到需要在数据表中更新的数据,将其转换为undo_log,并且保存到提前在每个数据库中创建的undo_log表中
打个比方,如果你是在做update product set price = 20 where price=10 and id=1的操作
那么undo_log中保存的就是反向sqlupdate product set price=10 where price=20 and id=1。当然它的存储不会直接这么存,会经过处理。
(2)然后执行业务SQL,这时你会发现数据库中的数据是发生变化了的,同时undo_log中也有对应的新增数据 - 二阶段
(1)因为第一阶段已经提交了本地事务,数据已经更新过了,这个时候如果没有报错,那么直接删除掉undo_log以及行锁的数据即可
(2)但是如果发生了报错,就只需要根据undo_log来回退数据

这个就是AT模式执行的两阶段的整体视角,我们可以体会到的是AT模式下,自动帮助我们生成了undo_log、一阶段、二阶段的提交都是由seata完成的,并不需要我们写代码来实现,所以它的无代码入侵体现在这里。
1.2 AT模式 本地事务与全局事务
但是我们还没有解释本地事务和全局事务之间的联系,接下来我们把多个服务引入进来,进行横向解析
讲解之前我们要明确几个角色,这几个角色不是在AT模式中独有,而是也适用于其他模式
- TM: Transaction Manager 事务管理器
全局事务的管理者,或者说是全局事务的发起方,再通俗一点就是标注了@GlobalTransactional的方法所在的服务 - RM: Resources Manager 资源管理
负责分支(本地)事务注册、提交和回滚。每个服务都是一个RM,负责本地事务的管理 - TC:Transaction Coordinate 事务协调器
全局事务的协调者,TM,RM启动的时候要向TC注册,TM创建的时候要向TC申请一个全局事务ID,所以整个事务的把控是在TC中的,但是各自事务的管理是在RM中
下面我们用一张图来表明各自的作用关系(这张图请大家静下心,跟着标识按序阅读下去你就会明白三个角色之间是如何合作的)

同时基于上图,我们也知道全局事务由TM发起,本地事务由各服务自己管理,本地事务和全局事务之间是通过TC来进行协调
1.3 AT模式 全局锁
那么我们再把锁的概念加入进来进一步理解
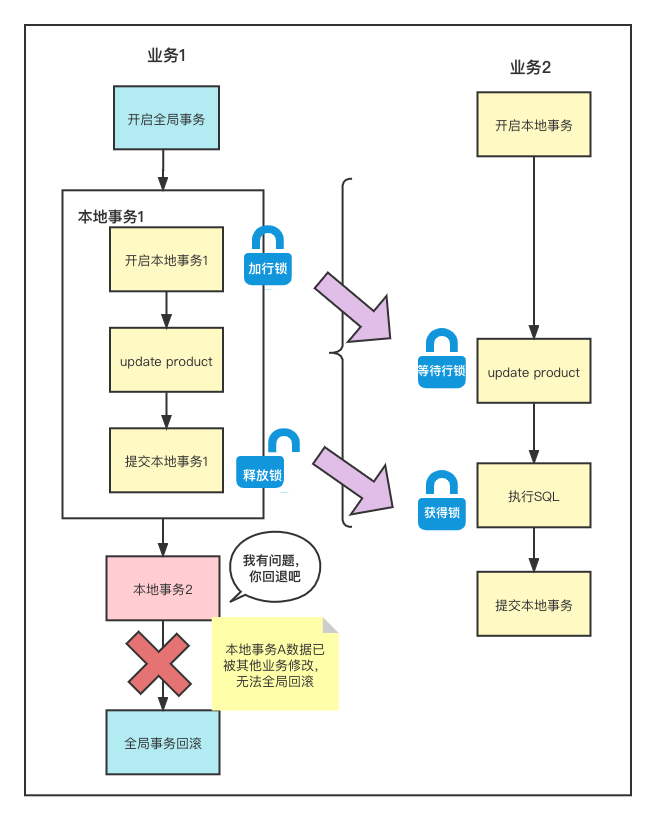
我们先假设一个场景:
- 业务1和业务2同样需要对product表中的同一行数据进行修改
- 业务1先执行,其中本地事务1执行的时候获取到product表的对应行锁
- 这时业务2也开始执行,要更新product时发现锁已被人拿了,那么他就先等着
- 当业务1的本地事务1执行完成并提交后,业务2拿到了行锁,这时他再去修改获取到的是业务1修改过后的数据,他再进行修改提交
- 可这时业务1并没有执行完,它在执行本地事务2时发生了错误,要执行回滚,可就在这时发现,自己事务1中的数据被其他事务篡改过了,他再执行undo_log可能就无法再回滚了
这里想象下为什么不可以再回滚?
我们假设下如果业务1的本地事务1的操作是
update product price = 20 where price=30 and name=1;
那么事务1的undo_log就是
update product price=30 where price=20 and name=1;
而业务2的操作是
update product price=25 where name=1;
那么到业务2操作完,事务1进行回退时就出现问题了,它根本找不到一条price=20 and id=1的数据,也就导致无法回滚。从而出现了脏写

那么这个问题我们要如何解决呢?
解决办法就是加全局行锁
我们的全局事务开启后,会申请全局行锁,同时业务2也添加上全局行锁,如seata实际的处理就是在业务2方法上也添加注解@GlobalTransactional或者@GlobalLock
这样当业务2执行会发现全局行锁被获取了,就会一直等待锁释放。只有到业务1整体提交完成后,全局锁才会释放,这样也就避免了脏写的发生

1.4 AT模式完整流程
我们加入锁,同时也加入了before image和after image的概念,来完整的讲解整个流程
首先理解before image指的是本地事务未开始之前查询出来的原数据的快照。after image指本地事务执行完后生成的事务后数据快照。
通过before image可以反向生成回滚sql并保存到undo_log中
如果事务执行无报错那么就删除掉锁、undo_log、image等中间数据
如果事务执行有报错,那么先比较after image与当前数据库中的数据来判断是否发生了脏读/写,如果发生了说明中间有其他业务操作了这些数据,这时就将报错上报,由人工处理,而避免脏写可以通过如上述所说的在其他业务中添加上@GlobalTransactional或者@GlobalLock注解;如果没有脏读那就通过undo_log回退数据。

如上就是AT模式,核心是理解两阶段提交、本地事务和全局事务之间的关系、以及全局锁的引入
1.5 AT模式应用场景
AT模式是实际开发中最常用的模式,他无代码入侵的特性,适应于不希望对代码进行改造的场景,因为AT模式要求数据库是支持本地事务的数据库,但是因为市面上多数使用的都是支持事务的数据库,所以其应用也十分广泛
同时其性能也还不错,完全满足普通业务,如果对于性能有较高要求的,就要用到我们其他模式的,这个我们也在下一章进行讲解
AT应用场景总结:
- 不希望对代码进行改造
- 数据库支持事务操作
- 对性能没有特别高的要求

华为开发者空间,是为全球开发者打造的专属开发空间,汇聚了华为优质开发资源及工具,致力于让每一位开发者拥有一台云主机,基于华为根生态开发、创新。
更多推荐



 23
23 0
0- 0



 已为社区贡献38条内容
已为社区贡献38条内容

所有评论(0)