数据库面试题:常见面试SQL语句
常见面试SQL语句1. 创建一个表:创建语法为CREATE TABLE table_name (column_name column_type);实例如下:create TABLE student (s_id INT NOT NULL,s_name VARCHAR(20));2. 有一张shop表,有三个字段article,author,price,选出每个author的price的最高的纪录。(
常见面试SQL语句
1. 创建一个表:
创建语法为
CREATE TABLE table_name (column_name column_type);
实例如下:
create TABLE student (
s_id INT NOT NULL,
s_name VARCHAR(20)
);
2. 有一张shop表,有三个字段article,author,price,选出每个author的price的最高的纪录。(要包含所有字段)
思路:使用MAX函数,找到price的最大值,再根据author分类即可
SELECT article,author,MAX(price)
FROM shop
GROUP BY author
我自己尝试了一下,这种方法的确是可以直接实现的,我也不知道为什么别人的博客里用了非常复杂的连接
3.一张company_profit收入表,两个字段id,profit。查询平均收入大于10w的公司id
思路:
- 先查询所有公司的平均收入,作为临时表
- 再将临时表放在主查询中。
- 这里AVG(age)的用法要注意
步骤一:查询所有公司的平均收入
select id, AVG(profit) avg_profit
from company_profit
where avg_profit > 100000
GROUP BY id;
步骤二:主查询,只查询id,与临时表进行id匹配
SELECT company_profit.id
FROM company_profit,(select id, AVG(profit) avg_profit
from company_profit
where avg_profit > 100000
GROUP BY id) temp_table
where company_profit.id= temp_table.id
GROUP BY id;
4. 学生成绩表-课程表例题
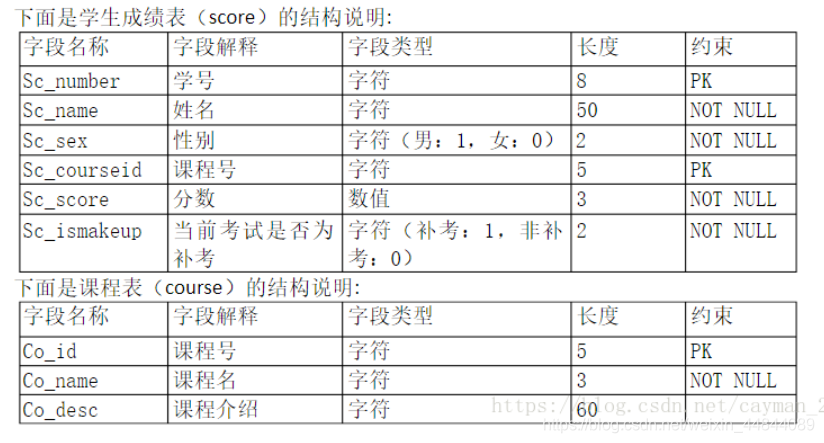
①如果学号的前两位表示年纪,要查找98级女生的姓名,请写出相应SQL语句。
思路:模糊查询 like或者左匹配
解法一:
select Sc_name
from score
where Sc_number like '98%'
解法二:
select Sc_name
from score
where left(Sc_number,2) = '98';
②要查找所有需要补考(小于60分)的学生姓名和课程的名字和成绩,请写出相应SQL语句。
select s1.Sc_name,c1.Co_name,s1.Sc_score
from score as s1,coures as c1
where s1.Sc_score < 60 and s1.crouseid = c1.Co_id;
③查询每个学生需要补考(小于60分)的课程的平均分,并以平均分排序。
select s.Sc_name,c.Co_name,AVG(Sc_score)
from score as s, course as c
where s.crouseid = c.Co_id and s.Sc_score < 60
GROUP BY s.Sc_name
ORDER BY AVG(s.Sc_score)
查所有课程都在80以上的学生姓名

思路:
- 找到分数在80一下的学生
- 在主查询中使用not in即可
select stu_name
from score
WHERE score.stu_name not in (select stu_name from score where score.subject_score < 80)
GROUP BY score.name;
给一个成绩表score,求排名(这里请忽略最后一列)
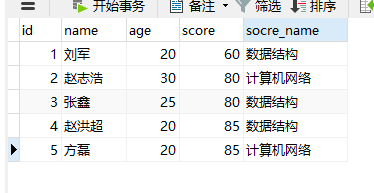
select a.id,a.name, a.score as Score , COUNT(DISTINCT b.score) as Rank
from score a, score b
WHERE b.score >= a.score
GROUP BY a.id
ORDER BY a.score desc;
简单解释:
笛卡尔积:
select *
from score a, score b
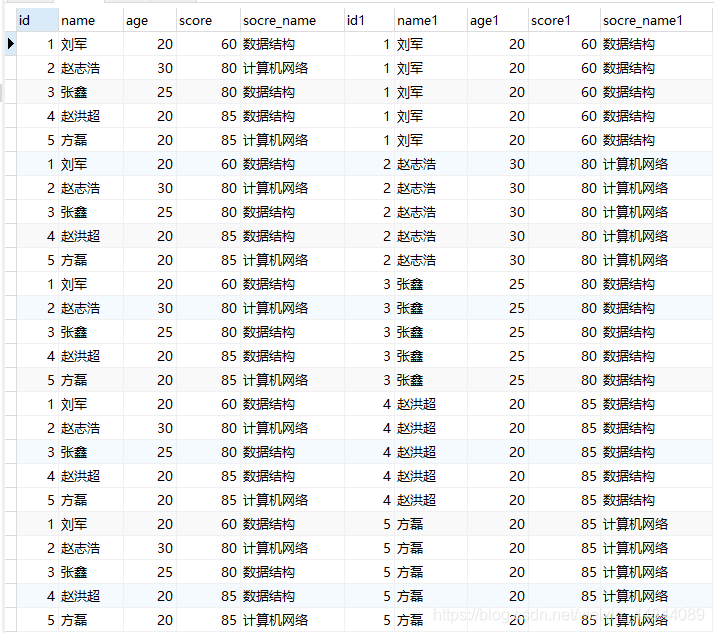
此时对以上结果进行筛选:
select *
from score a, score b
where b.score > a.score
以上结果把"b表"的成绩(score) 大于 "a表"的成绩的记录都筛选出来
此时右边成绩字段全部都是大于等于左边的成绩字段
然后我们再根据id进行一个排序
select *
from score a, score b
where b.score > a.score
ORDER BY a.id
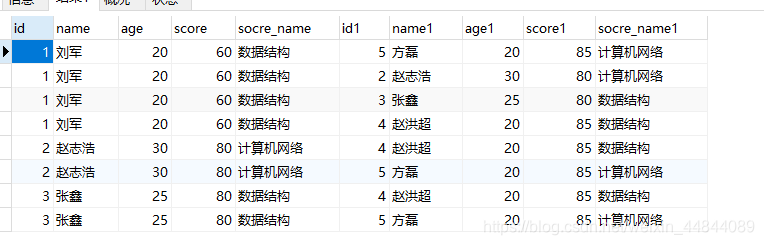
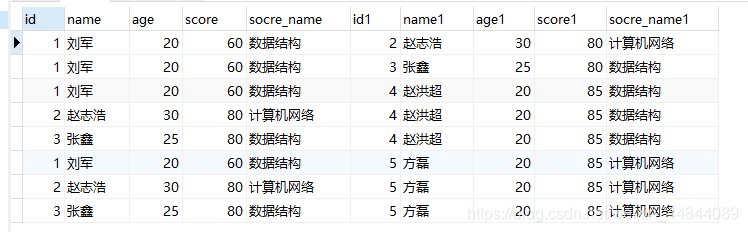
此时我们就可以知道针对a表的中的每一个学生b表中有多少大于他的
最后我们根据id分组(GROUP BY), 再把"b表"的成绩去重(DISTINCT)再记总数(COUNT)
select a.id,a.name, a.score as Score , COUNT(DISTINCT b.score) as Rank
from score a, score b
WHERE b.score >= a.score
GROUP BY a.id
ORDER BY a.score desc;
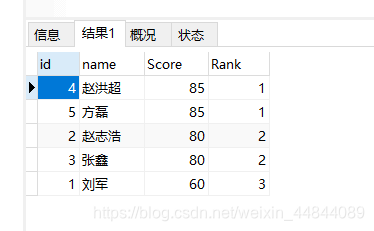
此sql不太好理解的就是" COUNT( DISTINCT b.score ) AS Rank "这段
结合上面的结果 举例一个来理解这句sql:
id为1 成绩60的 大于他的有4条记录, 分别是85 80 80 85
我们看到这4条记录去掉重复后剩下 80 85 这2个, 也就说明成绩60有2个大于等于他的,那么最高只能排名第2
这就是上面去重求和的作用, 求的和就是他的最高排名
但是这里我有个不太懂的事情就是COUNT(DISTINCT b.score) 为什么不用加1,我测试过了,加1的话就多了。。。。
这篇博客解释的很清楚:
https://blog.csdn.net/m0_37928787/article/details/91042728
求某门学科分数最高的前3位
使用order by降序排列,之后用limit限制展示数据行数
select *
from score
WHERE socre_name = "计算机网络"
order by score DESC
LIMIT 2

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)