Mysql重复数据查重保留一条
例如:t_user 用户表中 username 重复。将username重复的用户查询出来,保留一条数据。先附上查重的sql以供验证:SELECT username, count(*) as num FROM t_user GROUP BY username HAVING count(*)>1;查询结果为:接下来,就需要将username重复的用户删除到只剩一条记录。第一步:查询出重复记录中
·
例如:t_user 用户表中 username 重复。将username重复的用户查询出来,保留一条数据。
先附上查重的sql以供验证:
SELECT username, count(*) as num FROM t_user GROUP BY username HAVING count(*)>1;查询结果为:

接下来,就需要将username重复的用户删除到只剩一条记录。
第一步:查询出重复记录中id最小的记录。
SELECT min(id) id, username FROM t_user GROUP BY username HAVING count(*) > 1结果为:

接下来,以此结果为条件,进行关联查询,将重复数据中,id大于上述结果中id的数据删除。就意味着重复数据只保留了一条。也就是保留下来id最小的那条数据。
最终sql:
delete t_user
from
t_user,
(
SELECT
min(id) id,
username
FROM
t_user
GROUP BY
username
HAVING
count(*) > 1
) t2
where t_user.username = t2.username
and t_user.id > t2.id最后通过查重sql验证。重复数据为空。
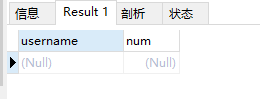
实现了想要的效果~!
如果是多条件的话,只需要在查询条件中添加多个过滤条件就可以了。
例如:用户名、性别、电话同时重复的记录查重保留一条记录。
delete t_user
from
t_user,
(
SELECT
min(id) id,
username,
sex,
phone
FROM
t_user
GROUP BY
username,
sex,
phone
HAVING
count(*) > 1
) t2
where t_user.username = t2.username
and t_user.sex= t2.sex
and t_user.phone= t2.phone
and t_user.id > t2.id结束~!
一切美好的遇见都是命中注定~!

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)