Redis——》双写一致性
思考:项目为什么要用redis?redis配置集群了吗?怎么配的?几台机器?单台redis的压力多少?一、我们为什么引入redis?一定要根据业务场景来,首先分析读写情况,再来考虑要不要引入redis读少写多:不要引用redis读多写多:适当引用redis(可以减少mysql数据库压力,如果不引用,可以使用数据库的主从复制,读写分离)读少写少:不要引用redis(根本没有必要)读多写少:可以引用r
思考:
项目为什么要用redis?
redis配置集群了吗?怎么配的?几台机器?单台redis的压力多少?
一、我们为什么引入redis?
一定要根据业务场景来,首先分析读写情况,再来考虑要不要引入redis
读少写多:不要引用redis
读多写多:适当引用redis(可以减少mysql数据库压力,如果不引用,可以使用数据库的主从复制,读写分离)
读少写少:不要引用redis(根本没有必要)
读多写少:可以引用redis
1)性能(是我们想到的第一个点)
2)速度快
3)读多写少
4)重复请求:过滤
5)无效请求
总之一个目的,让mysql更快的运行(无它能跑,有它更好)
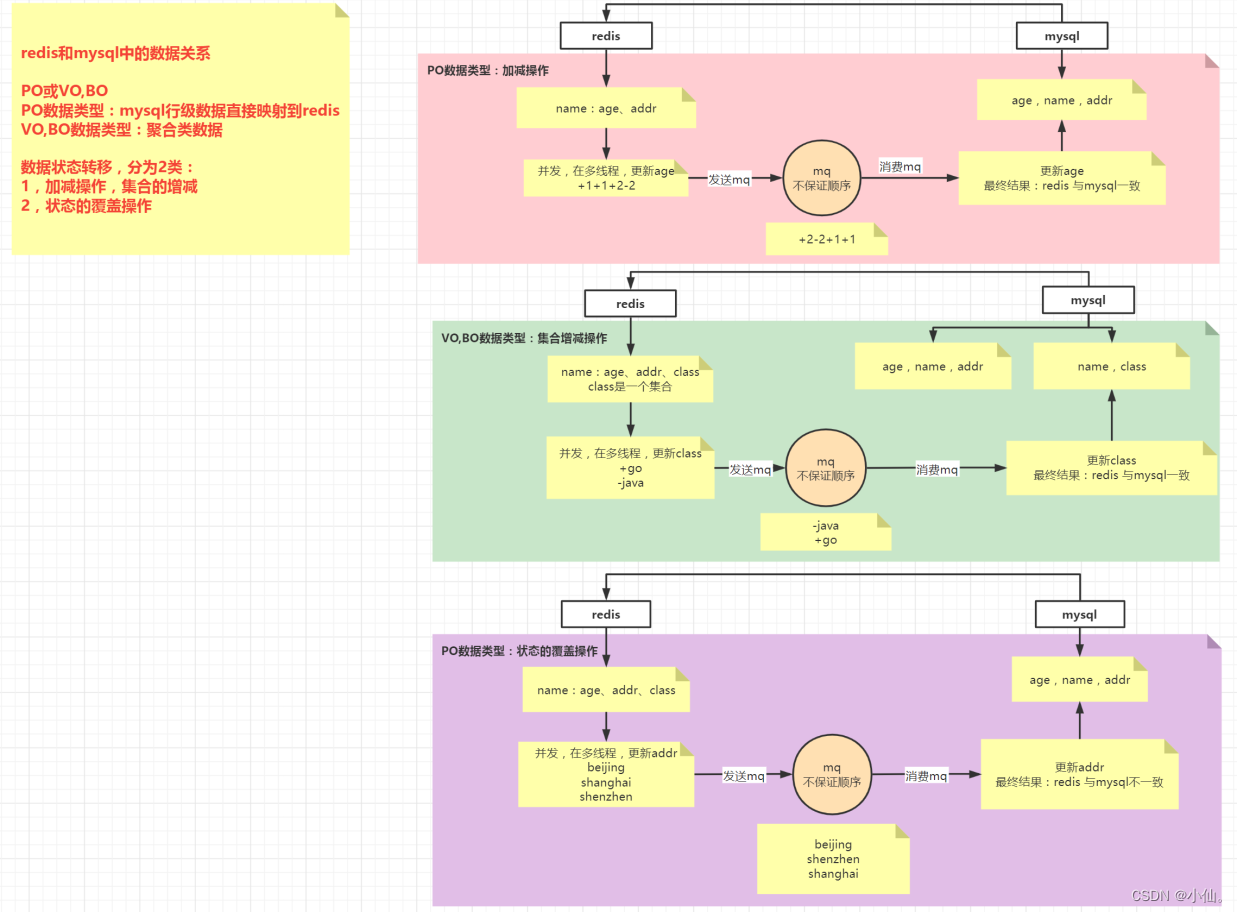
二、redis和mysql中的数据关系
场景:先修改redis,再发送mq,再修改mysql
数据类型:PO、VO(视图对象)、BO(业务对象)
1、数据类型
PO:mysql行级数据可以直接映射到redis上
VO、BO:mysql行级数据不能直接映射到redis,可能来自多张表(多个接口,多个业务组合),属于聚合类数据
2、数据状态的变更/转移
加减操作,集合的增减操作:无顺序要求,redis和mysql结果一致
状态的覆盖操作:如果不按顺序,redis和mysql结果不一致
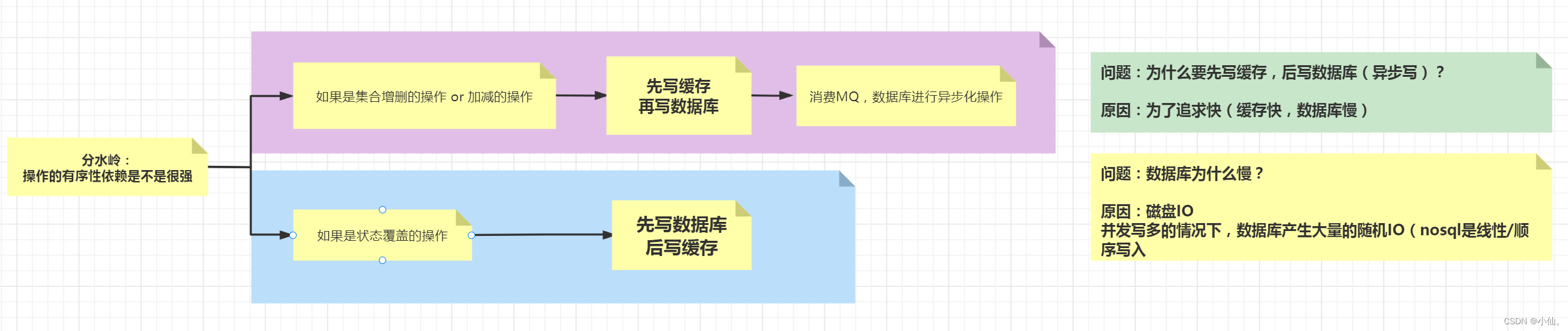
3、如何解决数据双写一致性,常见方式有哪些?
读:先读缓存
1)缓存有,就返回
2)缓存没有,就读取数据,更新缓存
1)先写数据库,后写缓存
并发,多线程下,可能存在的问题:
(1)状态的覆盖操作,如果不按顺序,redis和mysql结果不一致
(2)数据库更新成功,缓存更新失败,redis和mysql结果不一致
可以在缓存上加过期时间,但这个时间段内,结果还是不一致
2)先写数据库,后删缓存
Q:为什么会有删缓存?
A:因为对于VO/BO数据类型,可能来自多张表(多个接口,多个业务组合),属于聚合类数据,是由mysql计算好的,不可能直接更新缓存,所以才会有删除缓存,再从数据库读取最新的数据
并发,多线程下,可能存在的问题:
(1)数据库更新成功,缓存删除失败,redis和mysql结果不一致(读取的依然是老的数据)
3)先删缓存,后写数据库
并发,多线程下,可能存在的问题:
(1)缓存删除成功,但并发读取,在写数据之前又读取老的数据,并更新到缓存,redis和mysql结果不一致(读取的依然是老的数据)
4)延迟双删(进阶版本)
先写数据库,删除redis,延迟一会再删除一次
并发,多线程下,可能存在的问题:
(1)准备更新数据库的时候,缓存里的key已经被lru/lfu淘汰掉了,并发有人访问不到数据,那么就会从数据库读取老的数据,当准备更新到缓存的时候,数据库更新完成,把缓存删除,结果老的数据更新到缓存了,redis和mysql结果不一致(读取的依然是老的数据)
5)先写缓存,后写数据库
并发,多线程下,可能存在的问题:
(1)状态的覆盖操作,如果不按顺序,redis和mysql结果不一致
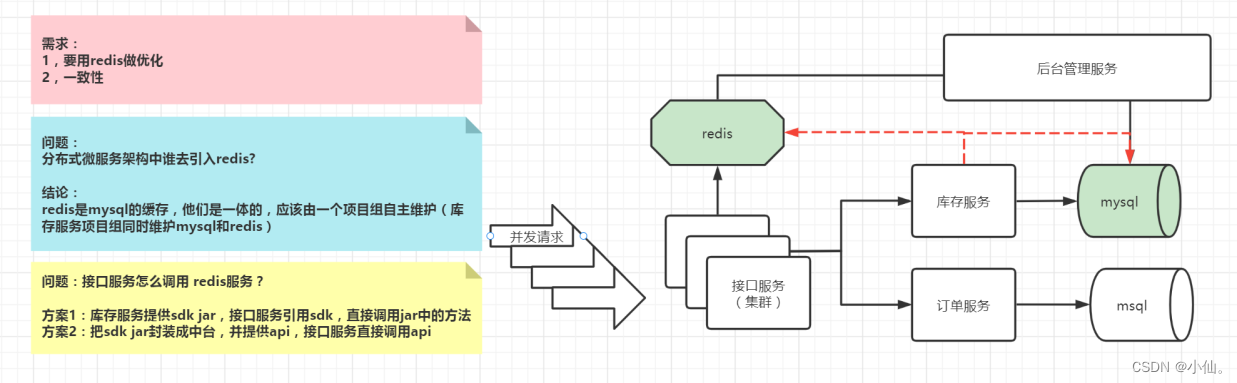
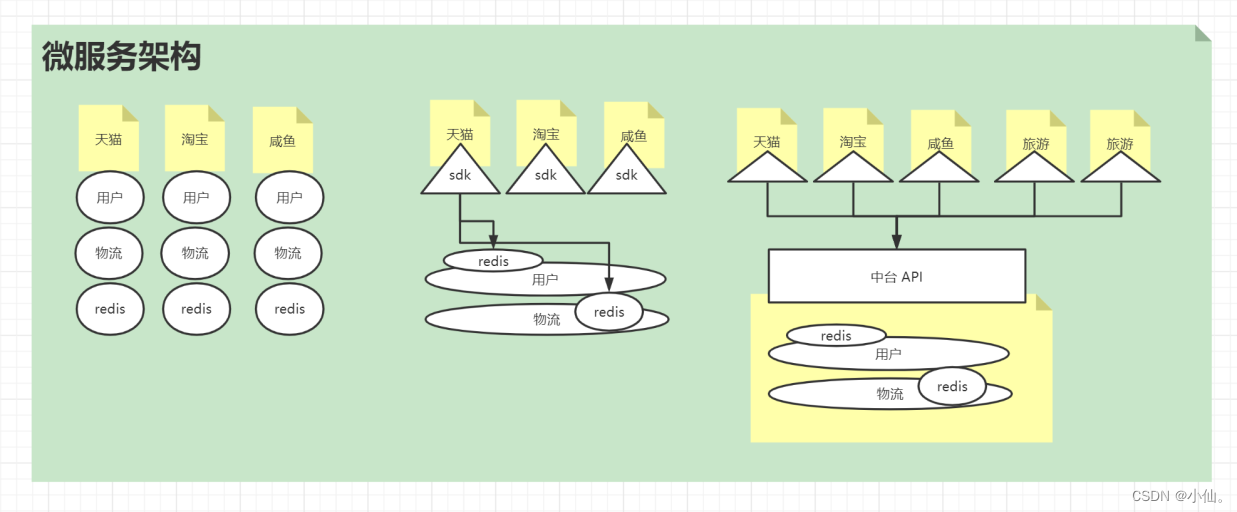
三、分布式微服务中,应该由哪个服务引入redis
sdk:jar
中台:封装统一的api
CQRS( Command and Query Responsibility Segregation)
四、CAP中的CP还是AP
CP肯定是有问题的,性能,可用性都会收到影响,这和引入redis是违背的
常见的AP不是没有一致性,分布式中基本都是最终一致性,以及数据库事务(锁、各种机制)兜底
五、有什么其他解决方案吗
1、NoSQL
2、NewSQL
3、es:顺序写入磁盘
数据库性能问题体现在:
1、IO随机读写
2、缓存与计算争抢内存资源
3、不是天生分布式的,或者没有云基因的
六、回到现实
其实很难,是否有机会/有团队/有场景/有业务/有需求/有资金,去实现以上的架构思想。
但是,多去思考,脑子才会灵光
没有最完美的方案,只有最适合的方案

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)