
Cassandra使用简介 - Cassandra Knowledge Base
通过技术特性、安装部署、应用编程及与HBase、MongoDB的区别等多个角度,对Cassandra相关要点进行简介,便于整体快速把握Cassandra
1. Cassandra简介
Cassandra是一种非关系型(NoSQL)开源大规模分布式数据库,具有水平可扩展性、分布式架构及表结构灵活定义等突出特性。
具体而言,其特性表现在以下几方面:
-
弹性可扩展性与写入效率:Cassandra设计本身是线性可扩展性的,通过增加集群中的节点数量增加你的吞吐量,从而保持快速响应,这也意味着通过添加更多的硬件就可以适应更多的客户和更多的数据存储要求;Cassandra被设计为在相对廉价的硬件体系上运行,支持快速写入与存储数百TB的数据而不牺牲读取效率。
-
数据存储灵活性:可以适应各种可能的数据格式,包括存储结构化、半结构化及非结构化等多种类型海量数据。
-
便捷的数据分发:其分布式架构支持多个数据中心之间的数据复制,灵活地在需要时进行数据分发。
-
基于架构的高可靠性:Cassandra具有自成体系(不依赖外部组件)的相对轻量级的架构设计,集群设计上各节点之间采用对等分布式系统,而且数据分布在集群中的所有节点之间(对Cassandra 的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取),整体上无中心节点,无单点故障,从而有效支持业务连续性要求极高的关键业务应用系统,可以进行不停服升级及多地域容灾。
Cassandra发端于Facebook, 并于2008年7月开源,2009年3月被纳入Apache组织孵化器(Incubator),2010年2月便提升为Apache的一个顶级项目,并逐渐演化和丰富,目前的主要发布的在支持版本如下:
| 版本号 | 发布日期 |
| 4.0.1 | 2021-09-07 |
| 3.11.11 | 2021-07-28 |
Cassandra一直位列全球数据库排行榜列存储(Wide Column stores)数据库榜首的位置(HBase紧随其后),在数据库综合排名中也名列前茅((如下图2022年1月排名)。
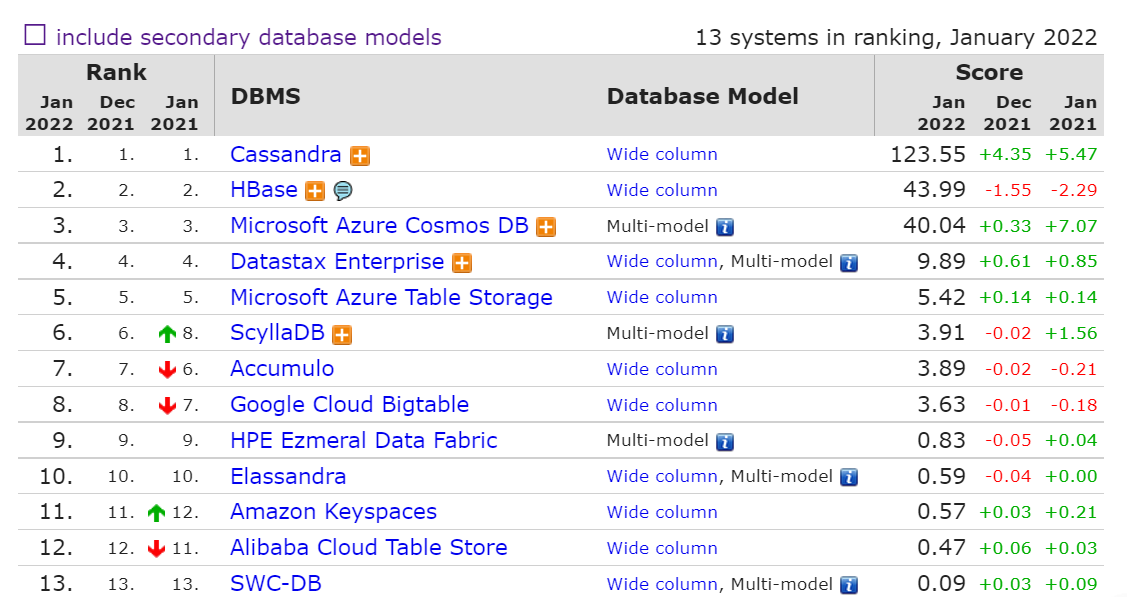
Cassandra已广泛应用于各行业领先公司的业务系统中,如国外的Netflix,Hulu,Instagram,eBay,Apple和Spotify,国内阿里淘宝、京东、华为、奇虎360等,也都在大规模使用Cassandra,中国气象局MICAPS4军民融合项目中的后端数据存储服务器也就是使用Cassandra存储数据的。
2. Cassandra技术特性
2.1 架构要素
如前所述,Apache Cassandra是一种开源的分布式NoSQL数据库,它呈现的是一种分区宽列及最终一致性(Eventual Consistency )的存储模式。
从底层上,Facebook设计时采用了SEDA(staged event-driven architecture)架构,结合了Amazon Dynamo的分布式存储与复制分发(replica)技术及Google Bigtable的数据存储引擎模式,具有一定的后发优势。
Cassandra设计目标主要概括如下:
-
完全的多主数据库复制 Full multi-master database replication
-
低延迟全局可用性 Global availability at low latency
-
基于常用硬件的可扩展性 Scaling out on commidity hardware
-
吞吐量随着节点数量增加线性增长 Linear throughput increase with each additional processor
-
在线负载均衡与集群扩展 Online load balancing and cluster growth
-
分区的面向键值的查询 Partitioned key-oriented queries
-
灵活的库表结构 Flexible schema
作为一种NoSQL类型的数据库,Cassandra提供了类似SQL的语言CQL(Cassandra Query Languag), 进行数据库表的相关操作。Cassnadra核心概念有以下几个:
-
键空间 Keyspace
键空间类似传统数据库的概念,它包含多个表Table。它会定义大数据集在每个数据中心是如何复制replicated的(即每个集群复制多少份)。
-
表 Table
Cassandra的表定义了分区集合的结构类型,表包含一系列分区,分区又包含了行与列。 Cassandra允许不停机状态下灵活地向表中添加新的列。
-
分区 Partition
Cassandra分区由分区键所标识,分区键是所有行主键的必备部分,以标识该行在集群中所存储的节点,同一分区键的数据都会被Cassandra存储在同一节点上。 所有高性能查询都可通过分区键来进行。
-
行 Row
与关系数据库类似,每行有多列组成,行由唯一主键Primary Key所标识定义,该主键包含分区键Partition Key及可选的聚簇键Clustering Key(Cassandra中Clustering Key决定了分区内数据的排序)。
-
列 Column
与传统数据库相类,是归属于各行的不同类型的数据单元。
Cassandra提供与SQL类似的查询语言CQL(Cassandra Query Language), 支持一系列对分区数据集的高级特性 ,主要包括:
-
轻量级事务支持
-
用户定义的数据类型、函数和聚合(aggregates)
-
集合类型支持(集合、映射和列表 sets, maps, lists)
-
本地2级索引
-
物化视图Materialized View (实验完善中)
Cassandra 明确选择不实现需要跨分区协调的操作,以提升效率及全局高可用性。例如,Cassandra不支持以下操作:
-
跨分区事务
-
分布式join
-
外键或者引用完整性(一译参照完整性,referential integrity)
2.2 管理运维工具
2.2.1 数据库系统运行管理
Cassandra的默认配置文件是cassandra.yaml, 其中有近400个各类参数(4.0.1版本合计378个),用于对Cassandra进行调节管理,其中一些参数及时生效,一些参数需要重启方能生效。
Cassandra可通过nodetool进行集群管理并在运行时调节cassandra.yaml中的很多参数设置。nodetool的命令格式为:
nodetool [(-h <host> | --host <host>)] [(-pwf <passwordFilePath> | --password-file <passwordFilePath>)] [(-pw <password> | --password <password>)] [(-pp | --print-port)] [(-p <port> | --port <port>)] [(-u <username> | --username <username>)] <command> [<args>]
nodetool详细命令可以参见:
Untitled | Apache Cassandra Documentation
共计约140个左右,相当丰富。
常见的如:
nodetool help 列出所有支持的命令选项及简要说明
nodetool help <command> 列出特定命令的详细说明
nodetool status 列示cassandra集群节点、负载状态等信息
nodetool info 列出节点的uptime、load等信息
nodetool clientstats 列出客户端链接情况
Cassandra 4.0提供了另外两个命令行工具。 auditlogviewer 用于查看审计日志,fqltool 用于查看、回放和比较完整的查询日志。
此外,Cassandra 支持开箱即用的原子快照功能atomic snapshot,该功能提供 Cassandra 数据的即时快照,以便与许多备份工具轻松集成,它 还支持增量备份,其中数据可以在写入时进行备份。 这些配置均可以在cassandra.yaml中进行调整设定。
2.2.2 数据库表管理交互
如前所述,cqlsh作为cassandra数据库表管理的命令行工具,可以进行各种数据库表的操作。 cqlsh实际上是一个python程序,需要python 2.7或python 3.6版本以上环境的支持。
Cassandra商业化公司DataStax对cqlsh进行了较为详尽的介绍,可以进一步参考:
下面将对cqlsh的常见用法进行简要介绍。
cqlsh启动的命令行如下:
cqlsh [options] [host [port]]
options的选项如下:
| 选项 | 说明 |
| -C 或 --color | 彩色方式输出 |
| --nocolor | 禁止彩色方式输出 |
| --browser | 采用哪种浏览器展示cqlsh帮助文件,支持多种类型的浏览器,常见的浏览器名称包括: firefox, chrome, opera, Windows-Default, safari等, 具体可参见:(20.1. webbrowser — Convenient Web-browser controller — Python 2.7.18 documentation 或 webbrowser — Convenient web-browser controller — Python 3.10.4 documentation) 或者浏览器执行文件路径名+‘ s%' ,例如:/usr/bin/google-chrome-stable %s |
| --ssl | 通过SSL连接cassandra |
| -u 或 --user -p 或 --password | 连接采用的用户名和密码鉴权 |
| -k 或 --keyspace | 授权访问的keyspace, 如与用户授权相关,需与-u一起使用 |
| -f 或 --file | 执行文件中的cql命令并退出 |
| --debug | 输出更多的调试信息 |
| --encoding | 输出信息的编码格式(默认是utf-8格式) |
| --cqlshrc | cqlsh资源文件cqlshrc的位置 (默认是 ~.cassandra/cqlshrc) |
| -e 或 --execute | 执行相应的cql语句并退出 |
| --connect-timeout | 连接超时秒数(默认2秒) |
| --request-timeout | 执行语句请求超时秒数(默认10秒) |
| --python | 指定所采用的python全路径名(当系统中安装多个python版本时尤其有用,可以替代系统默认版本号) |
cqlsh通过CQL语句可以进行数据库表的各种DDL、DML操作,CQL相关事项,可以参见官方文档,暂不作进一步展开:
The Cassandra Query Language (CQL) | Apache Cassandra Documentation
cqlsh除了支持CQL语句外,同时支持其它一些数据库运行相关的一些特性,主要包括:
| 操作命令 | 说明 |
| CONSISTENCY <consistency level> | 用于设置后续数据库运行的一致性级别,用于平衡Cassandra分布式运行的可用性及准确性,可以对读写分别设置,具体包括: ANY、ONE、TWO、THREE、QUORUM、EACH_QUORUM、ALL、LOCAL_QUORUM、LOCAL_ONE、SERIAL、LOCAL_SERIAL、SERIAL CONSISTEN等。 具体是指确认一个读写操作所成功完成所需要的最少节点数。 具体细节及控制粒度可参见: How is the consistency level configured? 其中对读写控制级别有非常详细的介绍,控制相当灵活及细粒度。 |
| SERIAL CONSISTENCY <consistency level> | 该类级别包括: SERIAL、LOCAL_SERIAL。 主要用于读操作时,如果有更新操作在进行,可以作为预commit的记录来读取。 LOCAL_SERIAL则限于单个数据中心。 |
| SHOW VERSION | 显示cqsh、Cassandra、CSQL规范及native protocol本地协议的版本号 |
| SHOW HOST | 显示csqlsh链接的节点IP地址和端口号 |
| SHOW SESSION <session id> | 显示特定session会话信息 |
| SOURCE <string filename> | 从文件中读取并执行每行的cql语句及csqlsh支持的语句,如: cqlsh> SOURCE '/home/calvinhobbs/commands.cql' |
| CAPTURE | 将执行的操作结果输出到指定文件中(不回显),如: CAPTURE '<file>'; CAPTURE OFF; CAPTURE; 其中CAPTURE表示目前CAPTURE的设置状态。 |
| HELP HELP <topic> | 显示cqlsh相关的命令信息帮助 |
| PAGING | 便于设置分页查询。对于查询大量记录时尤为有用。 PAGING ON; PAGING OFF; PAGING <page size in rows> |
| EXPAND | 将查询输出的行以垂直列元素形式显示(即横向显示转为纵向显示),对于列数较多或者单列内容较长时,都非常有用。 EXPAND ON EXPAND OFF |
| LOGIN <username> [<password>] | 当前会话切换到另外一个用户 |
| DESCRIBE 或 DESC | 获取Cassandra集群、数据库表等相关的概要信息。主要包括: DESCRIBE CLUSTER DESCRIBE SCHEMA DESCRIBE KEYSPACES DESCRIBE KEYSPACE <keyspace name> DESCRIBE TABLES DESCRIBE TABLE <table name> DESCRIBE INDEX <index name> DESCRIBE MATERIALIZED VIEW <view name> DESCRIBE TYPES DESCRIBE TYPE <type name> DESCRIBE FUNCTIONS DESCRIBE FUNCTION <function name> DESCRIBE AGGREGATES DESCRIBE AGGREGATE <aggregate function name> |
| COPY TO | 将表中的数据拷贝到CSV格式的文件中。 具体用法: COPY <table name> [(<column>, ...)] TO <file name> WITH <copy option> [AND <copy option> ...] 文件名设为STDOUT时,输出到终端上。 copy option可以对copy时的行为进行细化控制调节,包括: MAXREQUESTS、PAGESIZE、 PAGETIMEOUT、BEGINTOKEN,ENDTOKEN、MAXOUTPUTSIZE、ENCODING |
| COPY FROM | 将CSV文件导入到表中 COPY <table name> [(<column>, ...)] FROM <file name> WITH <copy option> [AND <copy option> ...] copy from option可以对copy时的行为进行细化控制调节,包括: INGESTRATE、MAXROWS、SKIPROWS、SKIPCOLS、MAXPARSEERRORS、MAXINSERTERRORS、ERRFILE= (默认是import_<keyspace>_<table>.err)、MAXBATCHSIZE、MINBATCHSIZE、CHUNKSIZE COPY TO和COPY FROM公用的选项option有以下各项,对数据格式处理、处理方式等都提供了更大的灵活性: NULLVAL、HEADER、DECIMALSEP、THOUSANDSSEP、BOOLSTYLE、NUMPROCESSES、MAXATTEMPTS、REPORTFREQUENCY、RATEFILE 这些选项本身名字也基本上展示了功用,如 HEADER=True表示文件存在首行头,导入时会被跳过。 各选项每个都有默认值,可以根据需要自行调节,具体条目解释也可以参考官方文档: cqlsh: the CQL shell | Apache Cassandra Documentation 也可以参看DataStax公司的专业文档: COPY FROM通常用于小型数据集的导入。 需要特别注意的是:如果在命令行中不指定列名,那么默认列的读取顺序是和Cassandra的内部列排序机制一致的,这点和传统数据库上是有差异的。传统上表中各列顺序是根据表创建时的顺序确定的,如ID,Name,BirthDate, Address等,而Cassandra则有其自身的列排序机制,即:Partion Key中的列、Clusterting Key中的列、其余按照字母升序排列的各列,上面的例子(假定ID为Primary Key)在Cassandra库表元数据中,列的排序为:ID, Address, BirthDate、Name。 |
上表这些选项有助于通过交互方式,进行数据检视操作。 这些选项可以从 cqlshrc文件设置,Linux系统中cqlshrc文件的默认位置为 ~/.cassandra/cqlsrc。 如果该文件不存在,可以从下列网址中获取:
cassandra/cqlshrc.sample at trunk · apache/cassandra · GitHub
cassandra商业化产品DataStax Enterprise中也提供了类似的示例文件,可供必要时参考:
2.2.3 SSTable离线工具
SSTable是cassandra持久化存储数据文件,是Cassandra的核心概念之一。 SSTable的相关工具需要在Cassandra实例停止后才能使用,所以本质上是用于数据库离线情况下的操作。
需要注意的是,这些工具本身并不会判断 Cassandra是否已经停止,Cassandra官方提醒,数据库在线时使用这些工具,可能会带来不可预期的结果。
下表仅将简要介绍各自用途,详细用法及命令行选项可点击内置链接或者访问下列网址:
SSTable Tools | Apache Cassandra Documentation
这些对于数据库维护人员比较重要, 其中和应用直接相关的几个简介如下:
| 命令 | 用途 |
| 将指定SSTable的内容以JSON格式导出(dump)到标准输出上 用法: sstabledump <options> <sstable file path> | |
| 将指定目录中的sstable批量加载到所配置的集群中。 用法: sstabledump <options> <sstable file path> | |
| 显示指定表相关数据文件Data.db的所有元数据信息。 用法:sstableloader <options> <dir_path> | |
| 显示指定表的相关sttable系列 用法: sstableutil <options> <keyspace> <table> |
其它命令还包括:sstableexpirdblockers、sstablelevelreset、sstableofflinerelevel、sstablerepairdset、sstablesrub、sstablesplit、sstablrupgrade和sstableverify等,这一系列工具对于DBA角色提供了不同层面的工具。
2.2.3 cassandra-stress压力测试工具
cassandra-stress用于cassandra的基准测试和负载测试 (benchmark、load-test), 它支持测试任意的表及CQL操作,便于用户对自己的数据模型进行基准测试。
命令行为:
cassandra-stress <command> [options]
该工具提供了同时读、写或者混合读写等功能支持以及包括启动的线程数等多种选型,用于多种测试场景。
通过用户模式(user mode)及不同描述文件(profile, yaml文件格式)来进行测试场景的设计实施。
可以通过选项-graph将测试结果进行输出。 如下列命令:
cassandra-stress user profile=./stress-example.yaml "ops(insert=1,latest_event=1,events=1)" -graph file=graph.html title="Awesome graph"
具体可以参考:
Cassandra Stress | Apache Cassandra Documentation
3. Cassandra安装
Cassandra可以采取多种安装方式,可以采用Docker安装、Linux系统自动安装包及手动下载安装包。
官方参考页面如下: Installing Cassandra | Apache Cassandra Documentation
Cassandra安装需要Java 8或Java 11版本支持, 可以采用Oracle或OpenJDK发布的版本,相关信息参见如下:
Orace: Java Downloads | Oracle
Open JDK: OpenJDK
另外,cqlsh运用需要python 3.6+ 或 python 2.7版本环境支持。
3.1 Docker快速安装
3.1.1 快速安装
参见 Apache Cassandra | Apache Cassandra Documentation (2022年1月地址)
可以按以下步骤:
-
获取Docker Cassandra镜像
docker pull cassandra:latest
-
启动Cassandra容器
docker run --name cassandra cassandra
或
docker run --rm -d --name cassandra --hostname cassandra --network cassandra cassandra
需要注意的是:Docker早期版本不支持 -rm -d 共用。
以下为对安装后的验证。
-
进行Cassandra基本库表操作
采用类似SQL的Cassandra Query Lanague(CQL)可以进行库表的操作,可以将如下操作存入data.cql脚本文件中。该脚本首先创建一个Cassandra的keyspace(类似SQL中的库,在该层Cassandra进行数据Replica复制分发等操作),一个存储具体数据的表及一些对标的操作。
-- Create a keyspace
CREATE KEYSPACE IF NOT EXISTS store WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : '1' };
-- Create a table
CREATE TABLE IF NOT EXISTS store.shopping_cart (
userid text PRIMARY KEY,
item_count int,
last_update_timestamp timestamp
);
-- Insert some data
INSERT INTO store.shopping_cart
(userid, item_count, last_update_timestamp)
VALUES ('9876', 2, toTimeStamp(now()));
INSERT INTO store.shopping_cart
(userid, item_count, last_update_timestamp)
VALUES ('1234', 5, toTimeStamp(now()));
-
通过CQL Shell工具cqlsh命令直接进行数据操作
docker run --rm --network cassandra -v "$(pwd)/data.cql:/scripts/data.cql" -e CQLSH_HOST=cassandra -e CQLSH_PORT=9042 nuvo/docker-cqlsh
注意该命令是linux下运行docker相关的命令。
-
通过CQL Shell工具cqlsh进行交互式操作
docker run --rm -it --network cassandra nuvo/docker-cqlsh cqlsh cassandra 9042 --cqlversion='3.4.4'
或者
docker exec -it cassandra cqlsh
-
进入cqlsh后,进行其它操作
SELECT * FROM store.shopping_cart;
INSERT INTO store.shopping_cart (userid, item_count) VALUES ('4567', 20);
-
清理退出
docker kill cassandra
docker network rm cassandra
3.1.2 Docker环境下Cassandra简要集群搭建
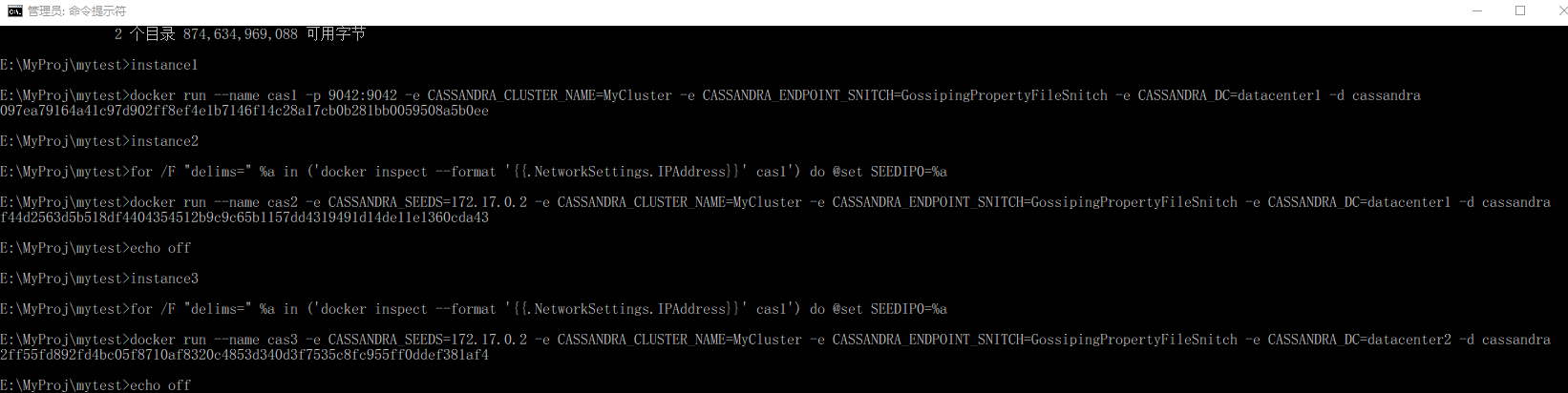
Docker环境也为Cassandra的集群环境搭建、测试提供了便利,通过以下的简要Windows命令行环境批处理命令, 即可以搭建一个多数据中心的3节点Cassandra集群(Windows 10环境下Docker), 其中casx为节点名。
需要注意的是,这种仿真集群搭建,需要较大的内存支撑(16G以上), 作者在8G内存的笔记本上,无法在Docker环境下启动所有的节点。
instance1.bat
docker run --name cas1 -p 9042:9042 -e CASSANDRA_CLUSTER_NAME=MyCluster -e CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch -e CASSANDRA_DC=datacenter1 -d cassandra
instance2.bat
for /f "delims=" %%a in ('docker inspect --format=^'{{.NetworkSettings.IPAddress}}^' cas1') do @set SEEDIP0=%%a
docker run --name cas2 -e CASSANDRA_SEEDS=%SEEDIP0:~1,-2% -e CASSANDRA_CLUSTER_NAME=MyCluster -e CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch -e CASSANDRA_DC=datacenter1 -d cassandra
echo off
instance3.bat
for /f "delims=" %%a in ('docker inspect --format=^'{{.NetworkSettings.IPAddress}}^' cas1') do @set SEEDIP0=%%a
docker run --name cas3 -e CASSANDRA_SEEDS=%SEEDIP0:~1,-2% -e CASSANDRA_CLUSTER_NAME=MyCluster -e CASSANDRA_ENDPOINT_SNITCH=GossipingPropertyFileSnitch -e CASSANDRA_DC=datacenter2 -d cassandra
echo off
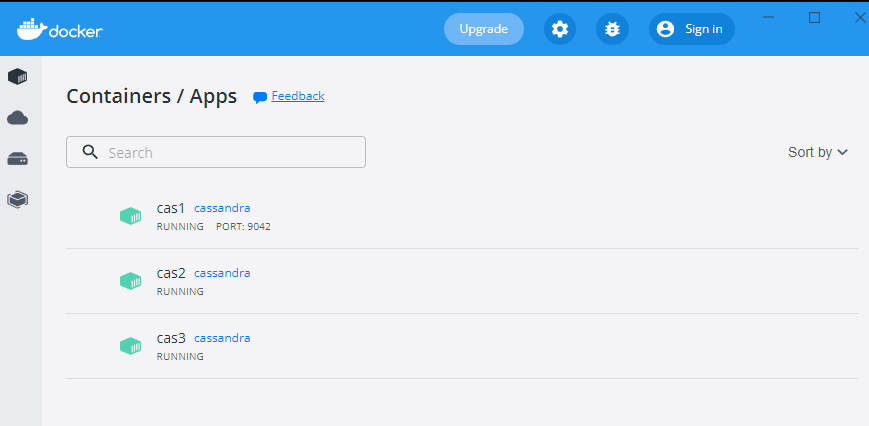
Windows 10 Docker环境下,运行效果如下图:
3.2 二进制Tar包安装
-
从Cassandra官方网站下载:
Apache Cassandra | Apache Cassandra Documentation
可用curl命令行下载:
$ curl -OL http://apache.mirror.digitalpacific.com.au/cassandra/4.0.0/apache-cassandra-4.0.0-bin.tar.gz
注意检验下下载包的完整性。
-
安装包解压
-
了解掌握软件目录结构
其中
bin/: cassandra数据库相关的系统应用及程序工具
conf/: cassandra相关的配置文件,如cassandra.yaml
data/: cassandra相关的系统运行存储数据,如commit logs、SSTables等
logs/: cassandra系统运行与调试日志等
tools/: 主要是cassandra-stress工具
-
运行cassandra
cassandra不建议用root用户与组去运行,如果用root用户运行,需要采用如下的参数:
cassandra -R
- 查看系统启动过程
$ tail -f logs/system.log
- 检查系统状态
-
$ bin/nodetool status
3.3 系统安装包(Package) (RPM,YUM, APT)
Cassandra提供了已预先编译好的常用流行Linux操作系统的系统安装包, 如Redhat、Debian/CentOS等。
Debian和Redhat系列安装的详细步骤可以参见如下地址:
Apache Cassandra | Apache Cassandra Documentation
作者在windows WSL2 ubuntu 20版本中采用的安装命令是:
$ sudo apt-get cassandra
安装运行都非常顺利。
3.4 源码编译安装
可以从以下网址获取源码,根据其官方文档进行编译与安装。
git clone https://gitbox.apache.org/repos/asf/cassandra.git cassandra
或
git clone https://github.com/apache/cassandra.git cassandra
从源码编译安装的详细步骤可以参阅:
Apache Cassandra | Apache Cassandra Documentation
编译环境需要JDK8或JDK11的支持。
其中有对常用IDE工具的集成设置等描述,包括IntelliJ IDEA, Apache NetBeans, Eclipse等。
源码包中提供了build.xml文件, 联网情况下, 可以直接采用ant命令,进行编译构建。
3. Cassandra编程应用
Apache Cassandra官方虽然提供了开放源代码,但它并没有直接提供其它的API接口,而这方面也有相关的Cassandra商业化生态公司所弥补,并提供了Java、Python、Ruby、C#/.NET、PHP、Node.JS、C++、GO、Scala、Perl等多种客户端编程驱动.
相关信息可以从以下网址获取:
Client drivers | Apache Cassandra Documentation
其中DataStax公司是脱胎于Apache Cassandra开发团队发展成熟起来的一个代表,它免费提供了Cassandra的Java、Python、C#等多种语言的客户端编程接口,推荐使用。从DataStax的github库上可以找到语言驱动程序。
数据处理中Python比较常用,下面简要介绍Python与Cassandra的编程交互支持。
4.1 安装Cassandra Python驱动
pip install cassandra-driver
将会安装DataStax的最新cassadra python驱动。
可以通过以下命令来查看版本号(Python3):
python -c 'import cassandra; print(cassandra.__version__)'
4.2 进行数据库相关操作
4.2.1 连接数据库
from cassandra.cluster import Cluster
cluster = Cluster()
这种情况默认连接本地Cassandra数据库实例(127.0.0.1),可以根据情况可以连接Cassandra集群中的任一或者全部节点。
from cassandra.cluster import Cluster
cluster = Cluster(['192.168.0.1', '192.168.0.2'], port=..., ssl_context=...)
只要与其中一个节点建立初始连接,驱动程序就会自动集群中的其它节点并同样建立初步连接。
4.2.2 建立会话
上述操作仅建立起与数据库-数据库集群的初始连接,如果需要进一步操作,需要进一步建立和各节点的会话连接,便于各类数据库表的操作。
cluster = Cluster()
session = cluster.connect()
可以进一步创建键空间:
session.execute('CREATE KEYSPACE users WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};')
可以直接指定keyspace,并基于此进行后续的各类操作, 如下所示:
cluster = Cluster()
session = cluster.connect('mykeyspace')
中间可以进行keyspace的切换:
session.set_keyspace('users')
或
session.execute('USE users')
4.2.2 执行操作
建立会话之后,即可以进行各类数据库表相关的操作,包括Profile环境变量设置、增删查改等cql语句等。
简单示例如下:
根据系统表,查询Cassandra版本号:
print(session.execute("SELECT release_version FROM system.local").one())
根据系统表,查询系统库表各类信息(假定examples键空间下已经建立了users表):
#查询所有的keyspaces
print(cluster.metadata.keyspaces)
#查询特定keyspace下的表结构信息
print(cluster.metadata.keyspaces['examples'].tables)
print(cluster.metadata.keyspaces['examples'].tables['users'])
print(cluster.metadata.keyspaces['examples'].tables['users'].columns)
print(cluster.metadata.keyspaces['examples'].tables['users'].columns['age'])
从创建的users表中,查询所有记录
rows = session.execute('SELECT name, age, email FROM users')
for user_row in rows:
print(user_row.name, user_row.age, user_row.email)
对于常用的操作,采用Prepared语句
user_lookup_stmt = session.prepare("SELECT * FROM users WHERE user_id=?")
users = []
for user_id in user_ids_to_query:
user = session.execute(user_lookup_stmt, [user_id])
users.append(user)
对于常用的操作,采用Prepared语句
user_lookup_stmt = session.prepare("SELECT * FROM users WHERE user_id=?")
users = []
for user_id in user_ids_to_query:
user = session.execute(user_lookup_stmt, [user_id])
users.append(user)
对于输入变量的操作, 也可以直接采用如下的方式(注意:即便是数值型的列类型,VALUES中站位标识符也需用 s%, 而非 d%)
session.execute("INSERT INTO USERS (name, age) VALUES (%s, %s)", ("bob", 42))
对于常用的操作,采用Prepared语句
user_lookup_stmt = session.prepare("SELECT * FROM users WHERE user_id=?")
users = []
for user_id in user_ids_to_query:
user = session.execute(user_lookup_stmt, [user_id])
users.append(user)
类似的操作还有很多,包括异步执行查询等,进一步深入挖掘可以参看如下连接:
Best practices for DataStax drivers
详细可以参见:
DataStax Python Driver - DataStax Python Driver for Apache Cassandra®
4.3 Cassandra可视化分析 (TBD)
后续将陆续补充。
5. Cassandra、HBase、MongoDB比较
与Cassandra相类的NoSQL数据库还有HBase、MongoDB等,设计上各有特色,在海量大数据处理领域都得到了广泛的应用。
MongoDB因对JSON等数据类型的内在支持,通常被称为文档型数据库, 而HBase、Cassandra则因为数据记录存储方式,被称为列式数据库库。 基于系统架构及功能特性,三种数据库也都有自己的优势场景。
下面是基于数据库排行专业网站db-engines进行三种数据库的简要对比。
Cassandra和其它两种NoSQL数据库相比,最突出的一个区别,就是它的集群设计是去中心话的,集群中各节点是对等的,从本质上一个类似P2P的分布式网络存储服务。 对Cassandra 的一个写操作,会被复制到其它节点上,而对Cassandra的读操作,也会被路由到某个节点上面去读取,因此,扩展一个Cassandra集群来说,可以简单地通过增加集群节点即可,不同于HBase的Master/Slave架构,Cassandra集群不存在单点故障,在高可用性及易扩展性方面,优势明显。
另外,从部署组件上看,HBase部署需要Zookeeper及HDFS支持,相对复杂,而Cassandra的部署相对自洽,无须引入其它过多组件,从一定程度上降低了运维部署的复杂度。
但需要指出的是,由于Cassandra这种去中心化架构,默认都是利用HASH算法实现数据分布的共识机制,不似HBase/HDFS这种中心化架构,底层机制通过元数据对集群数据文件进行逻辑操作与管理,从而在数据库迁移时,必须进行物理层面的数据移动,需要相对谨慎规划与实施; 同时Cassandra这种去中心化架构各节点承担的任务复杂度较高,不似HBase,复杂的协调指挥问题由主节点服务来完成,节点功能越简单,一定程度上降低了多节点的风险,对于大规模节点的管理有一定的优势。
表: Cassandra、HBase、MongoDB简要对比
| 对比项 | Cassandra | HBase | MongoDB |
| DB-Engines排名 | 11 | 25 | 5 |
| 开发商 | Apache基金会 | Apache基金会 | MongoDB Inc. 有社区版 |
| 系统主要开发语言 | Java | Java | C/C++ |
| 所支持的主要操作系统 | BSD Linux OS X Windows | Linux Unix Windows | Linux OS X Solaris Windows |
| 集群支持 | 支持 | 支持 | 社区版也支持集群 |
| SQL内生语言支持 | 类SQL的CQL语言,支持数据库的SELECT、DML和DDL操作 | 不支持 | 通过MongoDB Connector for BI支持只读类型SQL查询操作 |
| API及其它访问方式 | 专有协议(CQL) Thrift | Java API RESTful HTTP API Thrift | 基于JSON的专有协议 |
| 编程语言支持 | 支持主流开发语言 C# C++ Clojure Erlang Go Haskell Java JavaScript Perl PHP Python Ruby Scala | 支持主流开发语言 C C# C++ Groovy Java PHP Python Scala | 最全的开发语言支持 Actionscript C/C++ C# Clojure ColdFusion D Dart Delphi Erlang Go Groovy Haskell Java JavaScript Lisp Lua MatLab Perl PHP PowerShell Prolog Python R Ruby Rust Scala Smalltalk Swift |
| MapReduce支持 | 支持 | 支持 | 支持 |
| 分布式存储方式 | 分片Sharding | 分片 | 分片 |
| 数据一致性支持 | 最终一致性(eventual consistency) 即时一致性 (immediate consistency) | 最终一致性(eventual consistency) 即时一致性(immediate consistency) | 最终一致性(eventual consistency) 即时一致性(immediate consistency) |
| 安全机制 | 可基于每个数据库对象进行权限设置 | 基于角色的权限的控制列表(RBAC),可与Apache Ranger集成 | 基于用户和角色授权 |
| 授权类型 | Apache授权协议 DataStax等公司提供商业版本 | Apache授权协议 Cloudera等公司提供商业版本 | MongoDB数据库SSPL(Server Side Public License)授权 MongoDB提供多种版本形式的商业授权 MongoDB链接驱动等采用Apache授权 |
| 市场影响力 | Fortune 100公司中的40%都有使用 | 商业营收最大的NoSQL数据库 | Fortune 100公司中的50%都有使用,在DB-Engines位列非关系型数据库榜首 |
| 主要用户 | Apple, Netflix, Uber, ING,, Intuit,Fidelity, NY Times, Outbrain, Best Buy, Comcast, eBay, Hulu, Sky, Pearson Education, Walmart, Microsoft, Macy's, McDonalds, Macquarie Bank | Apple, Salesforce, Cerner, Allegis Group, Bloomberg, Airtel, Thomson Reuters, Dish, Opower, Experian, Deutsche Telekom, T-Mobile, Santander, RingCentral, Ceasars Entertainment, Komats | ADP, Adobe, Amadeus, AstraZeneca, Auto Trader, Barclays, BBVA, Bosch, Cisco, CERN, City of Chicago, Coinbase, Department of Veteran Affairs, Department of Works and Pensions, eBay, eHarmony, Electronic Arts, Elsevier, Epic Games, Expedia, Forbes, Foursquare, Gap, Genentech, HSBC, Jaguar Land Rover, KPMG, MetLife, Morgan Stanley, Nationwide, OTTO, Pearson, Porsche, RBS, Sage, Salesforce, SAP, Sega, Sprinklr, Telefonica, The Weather Channel, Ticketmaster, Under Armour, Verizon Wireless |
下面有几处对比分析,相对明确,可供借鉴参考:
Cassandra vs. HBase vs. MongoDB Comparison
https://logz.io/blog/nosql-database-comparison/
https://www.zhihu.com/question/309984206
主要参考资料
Cassandra官方网站
Welcome to Apache Cassandra’s documentation! | Apache Cassandra Documentation

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)