Flink程序中Tuple类型使用+ 算子程序Lambda方式正确使用姿势
Tuple元组类型使用以及Lambda编写flink程序正确姿势(方法与避坑)
文章目录
(一)Tuple
(1)说明
Tupe: 元组;在前文中,我们使用Tuple2、Tuple3 来作为OUT(输出)使用

Tuple 是flink 一个很特殊的类型 (元组类型),是一个抽象类,共26个Tuple子类继承Tuple 他们是 Tuple0一直到Tuple25

Tuple后的数字,代表每一个元组中可用空间(理解为插槽也行,每个字段对应一个插槽)
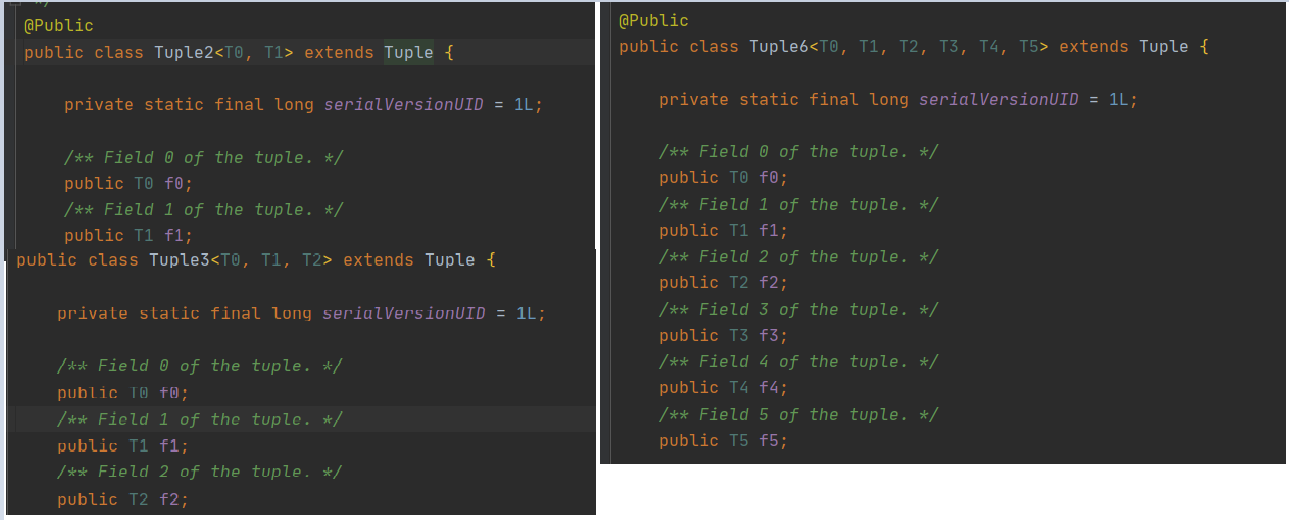
我们可将其理解为Flink 为我们构造好了0-25个字段的模板类,每个字段类型可以自己指定,字段名由Flink控制,例如 f0 f1 f2等等
(2)Tuple的使用
元组使用姿势1
构造元组
可使用静态方法 newInstance进行元组构造 指定元组空间大小;
ex: 1 则元组只有一个空间,则实际使用的Tuple1 字段只有f0
ex: 12 则元组只有两个空间,则实际使用的Tuple2 字段只有f0,f1
// 指定 Tuple元组空间大小 (可理解为字段个数)
Tuple tuple = Tuple.newInstance(1);
元组存取值
//设置字段值 以及字段索引位置 (从0开始)
tuple.setField("zs",0);
//取值
Object field = tuple.getField(0);
//zs
System.out.println(field.toString());
上方取值,是通过元组字段索引获取的,那么,我前边指定了tuple的空间大小为1 ,我如果tuple.getField(1); 会发生什么呢?
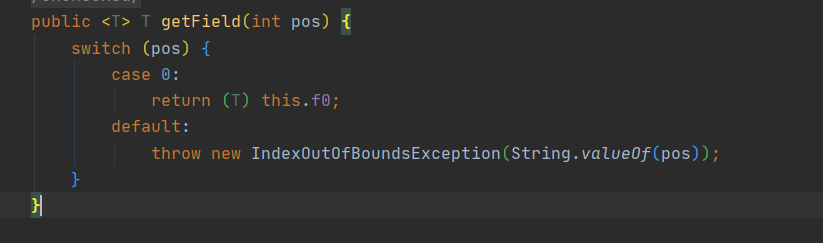
答案是:索引越界异常
元组使用姿势2
我们发现啊,如果使用Tuple.newInstance(xx),指定元组空间大小的话,这样存取虽然能够实现,但会存在存储索引位置使用不正确的情况,可能由于失误操作编写出索引越界异常,而且使用不太方便…那么有没有更好的操作方式呢?当然是有的!;
我们在确定了元组空间大小以及每个空间存值后,我们可直接定义固定长度元组空间 例如直接使用Tuple2、Tuple3、Tuple18…
使用Tuplex.of(数据)方法构造Tuple元组
Tuple3<String, String, String> tuple3 = Tuple3.of("第一个格子 F0:zs", "第二个格子 F1:ls", "第三个格子 F2:ww");
System.out.println(tuple3.f0); // 第一个格子 F0:zs
System.out.println(tuple3.f1); // 第二个格子 F1:ls
System.out.println(tuple3.f2); // 第三个格子 F2:ww
Tuple也支持数据覆盖
例如,原本F0设置的是第一个格子 F0:zs,我们可以再次将其余值set进F0格子,覆盖以前的数据
// 覆盖某个格子值
tuple3.setField("a",0);
//覆改所有格子的值
tuple3.setFields("DDD", "b", "c");
System.out.println(tuple3.f0);
Flink计算程序中Tuple使用姿势
public static void main(String[] args) throws Exception {
List<Tuple3<String, String, Integer>> list = Arrays.asList(Tuple3.of("zs", "532101xxx", 13),
Tuple3.of("ls", "532102xxx", 19),
Tuple3.of("ww", "532103xxx", 19));
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(1);
DataStreamSource<Tuple3<String, String, Integer>> streamSource = env.fromCollection(list);
SingleOutputStreamOperator<String> result = streamSource.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() {
@Override
public String getKey(Tuple3<String, String, Integer> value) throws Exception {
return value.f0;
}
}).countWindow(1).apply(new RichWindowFunction<Tuple3<String, String, Integer>, String, String, GlobalWindow>() {
@Override
public void apply(String s, GlobalWindow window, Iterable<Tuple3<String, String, Integer>> input, Collector<String> out) throws Exception {
for (Tuple3<String, String, Integer> tuple3 : input) {
out.collect(tuple3.f0.toUpperCase());
}
}
});
result.print();
env.execute();
}
(二)算子程序Lambda表达式的使用
我们前边讲了很多很多的算子 例如 map、FlatMap、KeyBy等等
(1)之前算子使用姿势


从三遍三个图中可以看出,我们都是使用的匿名内部类的形式,且IDEA还提示我们可以优化(显示灰黑色)
那么,如何优化呢?
我们先以Map算子为例
点进MapFunction类中,我们发现了一个注解@FunctionalInterface

@FunctionalInterface 作为一个JAVA开发者来说,应该是必须掌握或者非常熟悉的一个东西,这到底是啥呢?
这便是JAVA8特性之一的函数式接口
(2)函数式接口
函数式接口使用规则
1.必须注解在接口上
2.被注解的接口有且只有一个抽象方法
3.被注解的接口可以有默认方法/静态方法,或者重写Object的方法
函数式接口使用方法
函数式接口除了可以和普通接口一样写Impl实现之外,还可通过Lambda表达式进行构造,而不用写Impl class(实现类)
我们前边所有算子的写法都是基于匿名内部类来编写的,压根没用到JAVA8函数式接口语法糖
(3)使用函数式接口改造算子
既然我们知道MapFunction被注解@FunctionalInterface修饰,则代码我们可以使用Lambda语法来优化我们之前编写的Map算子案例
Map算子优化前
SingleOutputStreamOperator<String> source = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toUpperCase();
}
});
Map算子Lambda写法
SingleOutputStreamOperator<String> source = stream.map(String::toUpperCase);
FlatMap算子优化前
// 使用flatMap算子
SingleOutputStreamOperator<String> source = stream.flatMap(new FlatMapFunction<List<String>, String>() {
@Override
public void flatMap(List<String> value, Collector<String> out) throws Exception {
for (String s : value) {
out.collect(s);
}
}
});
FlatMap算子优化后
// 使用flatMap算子
SingleOutputStreamOperator<String> source = stream
.flatMap((List<String> value, Collector<String> out) -> value.forEach(out::collect));
执行结果

Exception in thread "main" org.apache.flink.api.common.functions.InvalidTypesException: The return type of function 'main(FlatMapOperator.java:41)' could not be determined automatically, due to type erasure. You can give type information hints by using the returns(...) method on the result of the transformation call, or by letting your function implement the 'ResultTypeQueryable' interface.
at org.apache.flink.api.dag.Transformation.getOutputType(Transformation.java:479)
at org.apache.flink.streaming.api.datastream.DataStream.addSink(DataStream.java:1236)
at org.apache.flink.streaming.api.datastream.DataStream.print(DataStream.java:937)
at com.leilei.FlatMapOperator.main(FlatMapOperator.java:43)
咦?报错了?这是为啥呢?
(4)Lambda表达式优化算子的坑(重要.重要.重要)
翻阅官方,发现居然有Flink lambda 说明专栏,哼,我想事情一定不简单啊!
附上官网Lambda说明链接:https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/java_lambdas.html

感到吃力,咱们直接右键…

Flink居然告诉我们我们使用 lambda表达式申明Java泛型时,需要显式声明类型信息
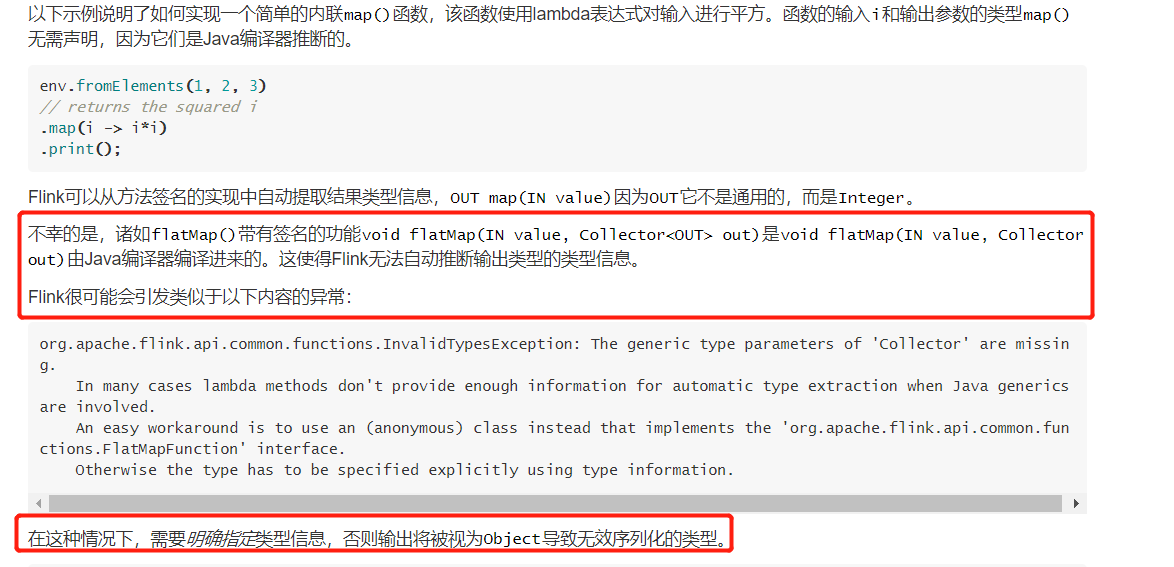
看完后,已然明了,我们在使用Lambda表达式时,FLink可能无法自动推断出输出类型,导致异常,因此,我们在使用Lambda表达式时,需要手动指定返回值类型
上方FlatMap算子优化正确姿势
SingleOutputStreamOperator<String> source = stream
.flatMap((List<String> value, Collector<String> out) -> value.forEach(out::collect))
.returns(Types.STRING);
上方Map算子优化正确姿势
SingleOutputStreamOperator<String> source = stream.map(String::toUpperCase).returns(Types.STRING);
之前算子综合案例改造前
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
env.setParallelism(1);
DataStreamSource<String> streamSource = env.socketTextStream("xx", 8080);
SingleOutputStreamOperator<String> flatMapStream = streamSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String s, Collector<String> collector) throws Exception {
for (String s1 : s.split(",")) {
collector.collect(s1);
}
}
});
SingleOutputStreamOperator<String> filterStream = flatMapStream.filter(s -> !s.equals("zsls"));
SingleOutputStreamOperator<String> mapStream = filterStream.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
return s.toUpperCase();
}
});
DataStream<Tuple2<String, Integer>> map = mapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s, 1);
}
});
KeyedStream<Tuple2<String, Integer>, String> groupStream = map.keyBy(tp -> tp.f0);
SingleOutputStreamOperator<Tuple2<String, Integer>> reduce = groupStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t2, Tuple2<String, Integer> t1) throws Exception {
return Tuple2.of(t1.f0, t1.f1 + t2.f1);
}
});
reduce.print();
env.execute();
}
之前算子综合案例改造后
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
env.setParallelism(1);
DataStreamSource<String> streamSource = env.socketTextStream("xxx", 8080);
SingleOutputStreamOperator<Tuple2<String, Integer>> result = streamSource.
flatMap((FlatMapFunction<String, String>) (s, collector) -> Arrays.stream(s.split(",")).forEach(collector::collect))
.returns(Types.STRING)
.filter(s -> !s.equals("sb"))
.map(String::toUpperCase).returns(Types.STRING)
.map(s -> Tuple2.of(s, 1)).returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(tp -> tp.f0)
.reduce((t2, t1) -> Tuple2.of(t1.f0, t1.f1 + t2.f1))
.returns(Types.TUPLE(Types.STRING,Types.INT));
result.print();
env.execute();
}
(5)说明
可以看到Lambda 方式优化算子程序可以减少很多代码量以及使程序变得更加美观,但需要注意的是切莫忘记手动指定返回值类型

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 13
13 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)