MySQL之orderby详解
MySQL中
MySQL基本执行流程
我会在整个专栏中反复提到,MySQL是一个存储引擎插件化的数据库。存储引擎不会直接识别执行sql语句,只是提供最基本的读写接口。
比如
1、获取一个表的所有索引信息
2、查询一个索引的第一条记录
3、查询一个索引的符合查询条件的第一条记录
4、查询一个索引中的下一条记录
5、向一个索引中插入一条记录
sql的具体执行流程是由Server层控制的,Server层会对sql进行分析,会根据sql的具体信息来选择选择哪个索引,以及各种各样的优化,指定一个执行方案,然后执行器会老老实实的根据执行方案 调用 存储引擎提供的接口执行 执行方案。
orderby
我们假设现在有一个表t,表的具体结构如下:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
`addr` varchar(128) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;
当我们执行 select city,name,age from t where city = '杭州' order by name;,我们来看下执行流程
1、分析器分析
分析器对sql进行分析,分析得到以下信息:
1、这是一个查询语句
2、有where条件,对应的字段为city
3、需要返回*
4、需要排序,排序字段为 name
2、优化器优化
优化器会选择索引来优化查询效率,发现city对应的有索引,就会选择city索引,而不是主键索引来查询,并根据其他信息生成执行方案。
3、执行器执行
当MySQL的一个线程需要排序查询的时候,MySQL会为每个线程分配一块sorted buffer,也就是分配一块内存来用于对查询的结果进行排序。
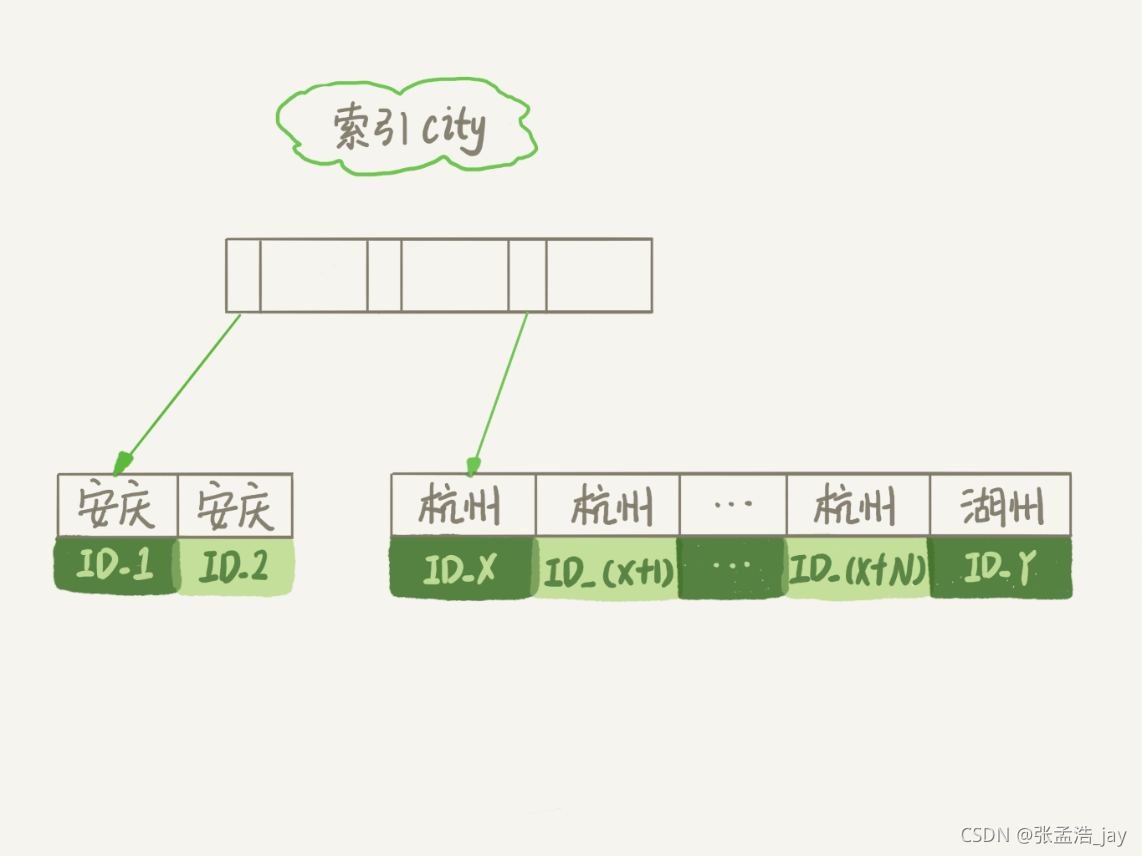
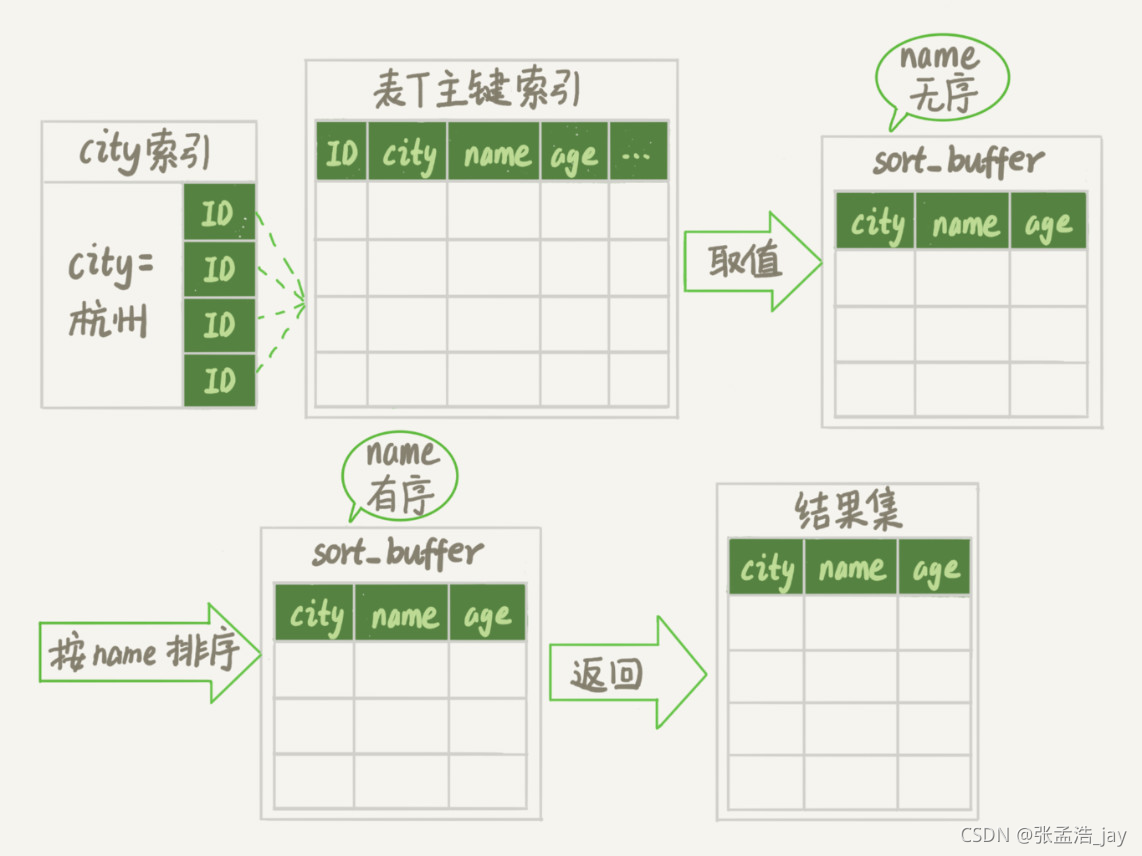
1、执行器会调用存储引擎提供的根据索引和查询条件得到第一条行记录的api,输入参数就是 city索引和 city = ‘杭州’,存储引擎会返回符合条件的第一条记录。因为是city索引,记录包括了city的值和对应的id主键的值。
2、因为是select name、age ,city索引中没有对应的信息,所以需要根据id,回表查询主键索引,得到主键索引中对应的记录,记录中包含了所有字段,然后将记录放到sorted buffer中。
3、执行器会调用存储引擎提供的下一条记录api,得到city索引中对应的下一条记录,判断对应的city 是否等于 ‘杭州’,如果等于杭州,就继续回表将对应的主键索引记录放到sorted buffer中,然后继续调用下一条记录。
如果不等于,就说明所有city = ‘杭州’ 的记录都已经查询完毕,所有的记录都放到sorted buffer中了。
4、开始对sorted buffer中的所有记录按照name进行排序,将排好序的结果返回给客户端。
总体来说,orderby的流程就是 执行器将所有满足条件的记录读取到sorted buffer中,然后进行排序,将排序后的结果返回给客户端。
当然查询的场景有很多很多,有一些特殊的场景,MySQL是做了优化的,我们来具体看一下:
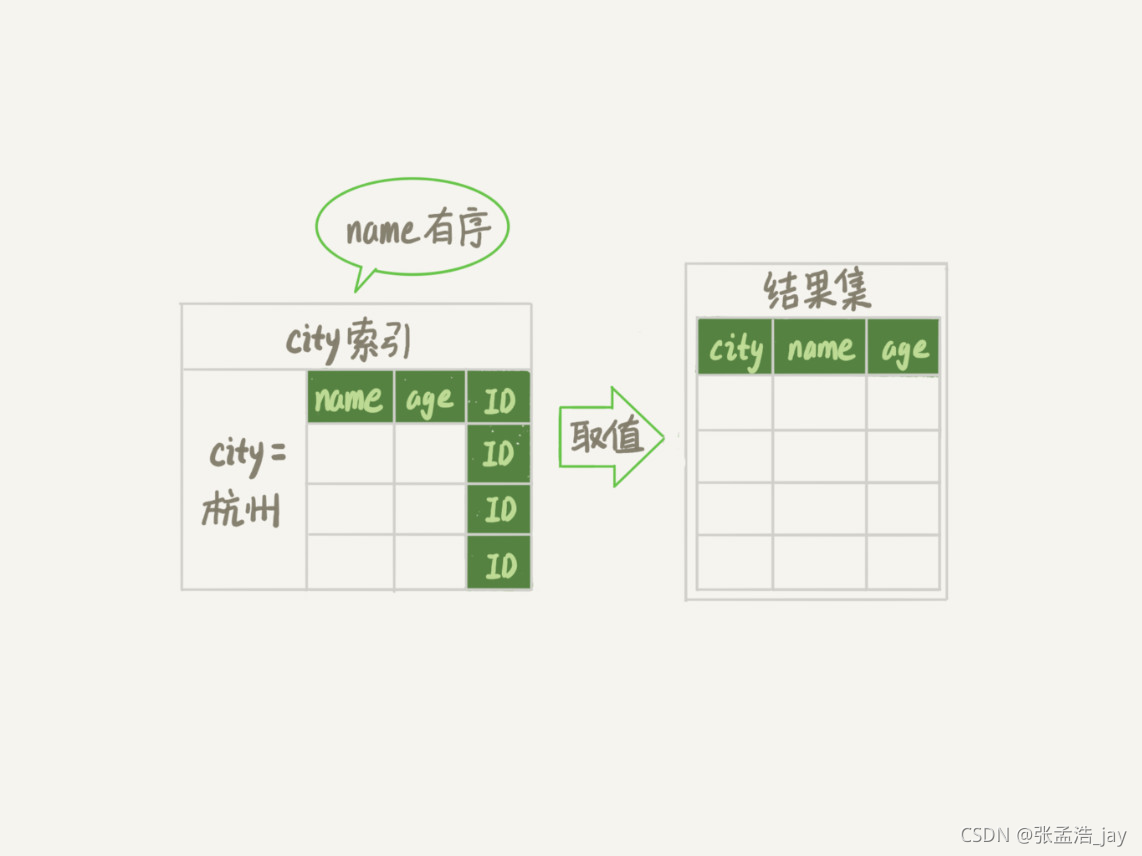
1、覆盖索引
如果t表中不是city索引,而是一个联合索引(city,name,age)的话,在对应的索引叶子节点的链表中,对应的name是有序的,那么就会省去排序的过程
这时,MySQL只需要通过联合索引定位到city=‘杭州’的第一条记录,然后一直遍历到末尾或者不符合city='杭州’的记录就ok了,将对应的记录直接返回给客户端就ok了,不需要回表和排序了。
2、外部排序
sorted buffer的内存是有限的,如果查询的数据特别大的话,sorted buffer是无法直接放下所有数据的,这个时候会用到磁盘。
1、将所有数据分为若干组存放到磁盘文件中,每个磁盘文件中存放的数据是可以通过sorted buffer来排序的。通过sorted buffer将每个磁盘文件进行排序
2、通过归并排序将这若干个磁盘文件合并成一个有序的大文件
3、每次读取大文件中的一小段内容,将内容返回给客户端,通过多次读取就可以将所有的排序结果传回给客户端。
3、rowid排序
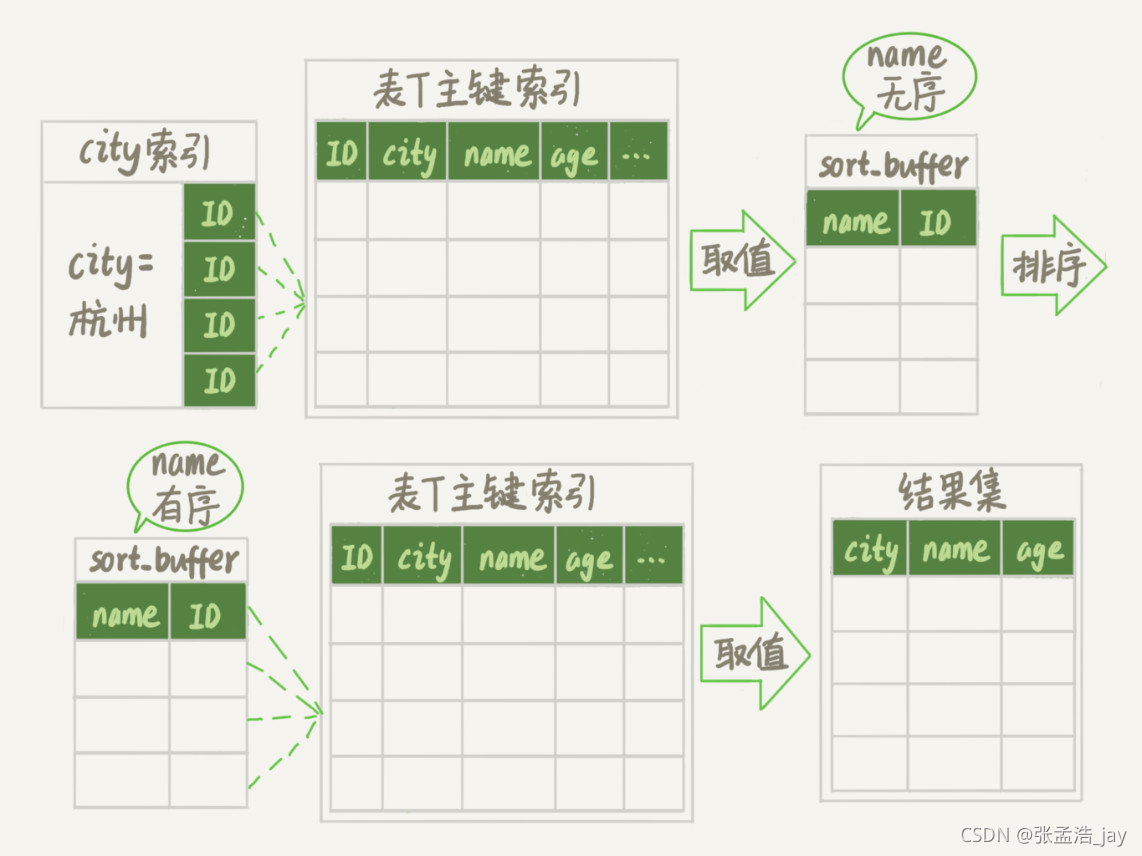
MySQL不仅对数据的整体结果有大小要求,对于排序的单行的大小也有限制,这个限制通过配置文件来更改。
比如 name + age + city的大小超出了限制,当回表查询的时候,只会讲name取出。sorted buffer中只有id 和 name 两个字段,然后进行排序。
然后遍历排序结果集,每次根据id回表,得到age、name、city字段将其返回给客户端。
rowid 和全字段排序区别
rowid排序 和全字段排序 相比的话,会增加多次的IO磁盘访问,速度更慢,典型的用时间换空间的做法。
总结
当排好序的结果集需要回表查询的时候,不会等待所有记录回表查询完毕之后一块返回给客户端,而是回表查询一条,就返回一条。
对于不需要排序的情况也是,也是查询一条就返回一条。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)