
MySQL十四:单表最大2000W行数据
在互联网技术圈中有一个说法:MySQL 单表数据量大于 2000 W行,性能会明显下降。网传这个说法最早由百度传出,真假不得而知。但是却成为了行业内一个默认的标准。
尺有所短,寸有所长;不忘初心,方得始终。
请关注公众号:星河之码
在互联网技术圈中有一个说法:MySQL 单表数据量大于 2000 W行,性能会明显下降。网传这个说法最早由百度传出,真假不得而知。但是却成为了行业内一个默认的标准。
单表超过2000W行数据一定会导致性能下降吗?我认为是不一定的,虽然说建议单表不超过2000W,但是我不接受它的建议可不可以?那必然也是可以的。
一、单表最大到底能存多少数据
先来看看下面这张图,了解一下mysql各个类型的大小
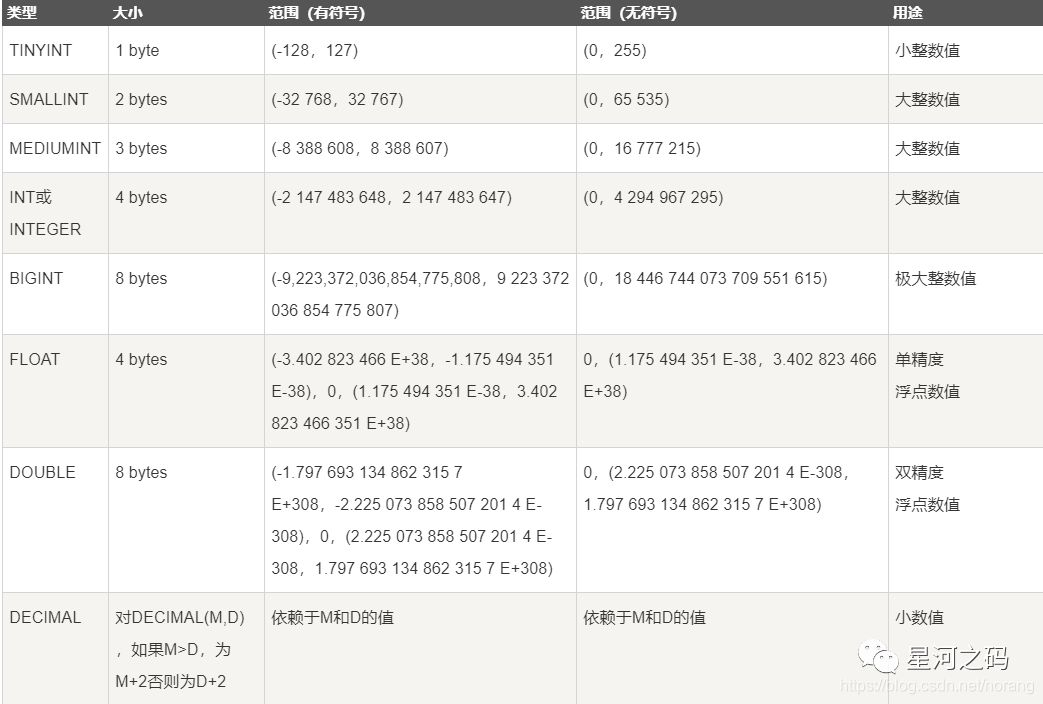
我们知道在MySQL是支持主键自增长的,不考虑其他因素的前提下,理论上只有主键没有用完,表中的数据就可以一直增加。从上图可以中可以分析出:
-
主键类型为Int时
主键32位,数据最大为2^32-1,大约可以存储21亿的数据,远远大约2KW。
-
主键类型为bigint时
主键64位,数据最大为2^64-1,存储的数据远远大于了常用的计量单位了,磁盘都达不到这个数量级。
-
主键类型为tinyint时
主键8位,数据最大为255,Id自增超过255就会报错
由此可見:MySQL能够存储的数据在一定程度上受限与主键的类型。但是数据量的大小却跟2000W没啥影响,既然百度大佬推荐单表最大2000W行数据,那肯定不会是空口白话,一定定会有其他影响行数的因素。
二、数据存储的结构
先不要着急,影响数据行数的因素肯定是有的,在此之前,先来看看数据在InnoDB中是怎么存储在磁盘的,又是怎么读取的。
2.1 数据存储的结构
在MySQL中默认的存储引擎是InnoDB,在之前的《存储引擎》中有说过,InnoDB为每个表都生成了两个文件:
- .frm文件:表结构文件
- .ibd文件:数据文件(聚簇索引包含数据与索引),又叫表空间。
我们表中的的数据其实都是存储在磁盘的.ibd文件中,而每次读取整个.ibd文件无疑是非常慢的,所以在《InnoDB数据文件》中又提到,InnoDB将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为 16KB。如下
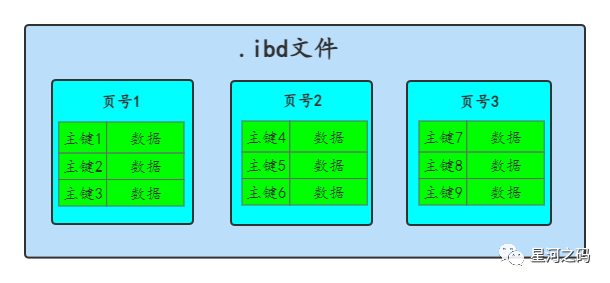
从上图中可以很清晰的看出,一个.ibd文件文件是由多个数据页组成的,也就是说一个表的数据会被分散存储在多个数据页中。当然数据页也不仅仅只是存储表中的数据,先来回顾一下页的组成
- 页的组成
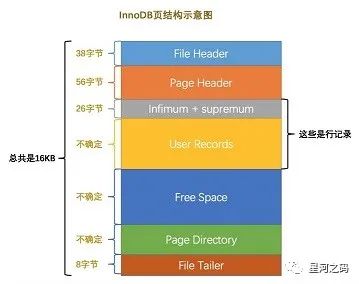
如图所示,InnoDB数据页由以下七个部分组成,
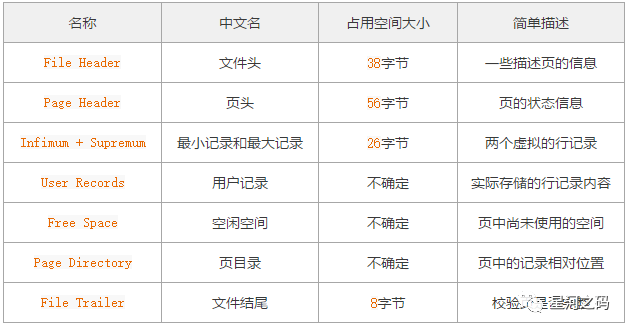
从也得组成中我们知道,数据页中还存储了除数据之外的东西,比如数据页的前后指针,页号,页目录等,因此虽然一个数据页一共16KB,但是能够用来存储数据的其实是不足16KB的 。
通过页的组成,我们可以大致分析在数据页中一下查找数据的整体过程:
- 记录被分散在不同的数据页中,InnoDB通过页号【表空间的地址偏移量】来标识数据具体在哪一页中。
- 不通的数据页之间使用前后指针进行关联,避免检索消耗,
- 当找到数据在那个数据页之后,InnoDB为避免遍历检索而提供了一个页目录,页目录通过二分查找将查找效率从O(n) 变成O(lgn),从而快速定位数据的位置。
2.2 索引的结构
既然在.ibd文件中只要知道了页号,就可以快速定位数据行的位置,从而读取到相应的数据。那么问题来了,我咋知道我要找的数据在那个数据页里,咋知道页号是啥?
万事都有解决的方式,要知道页号其实也简单,无非就两种方式:
- 全表扫描:简单粗暴,没那么多花花肠子,干就完事,但是数据量大了,性能就会下降,非长久之计。
- 通过索引找到数据页:重点了解一下这个
在《索引基本原理》中解释了InnoDB索引是基于B+tree实现的,InnoDB在构建B+tree结构时,一般会找出每个数据页中id最小(或者说索引最小, InnoDB主键即聚簇索引)的记录与其对应的页号,将id与页号组成一个新的记录,存储在一个新生成的数据页中,其大小也为16K,为与存储数据的数据页区分,引入了数据页之间的上下层级关系,也就是页层级(page level)。因此我们知道在B+tree中分为两部分:
- 叶子节点:真正存放表中的数据的数据页,page level = 0
- 非叶子节点:存放索引以及索引对应数据所在的页号的数据页
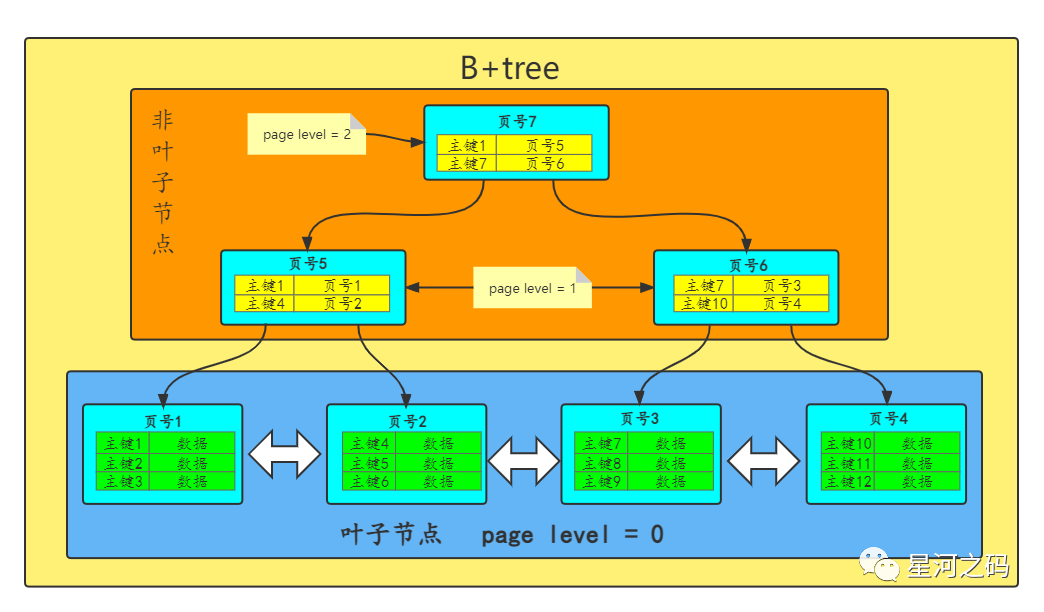
根据这张B+tree的图,我们知道数据页之间是有地址指向的,如果要找一条数据,最多只需要经历三次磁盘IO就可以将数据页都加载到内存中,从而找到数据,完成查询。
三、B+Tree能存储多少数据
要知道一个B+Tree能存储多少数据其实也不难,B+Tree中的叶子节点存放的是数据,而一个数据页只有16K,我们假设:数据页中页目录,页头,页尾加起来总共占用1KB,剩余15KB全部用了存放数据。
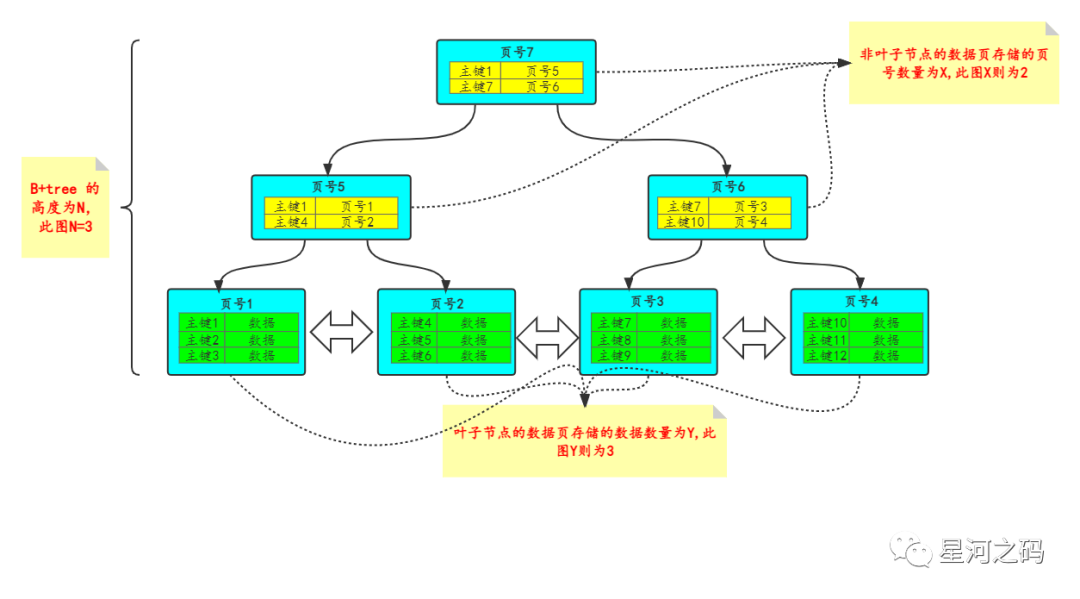
如上图:
根据以上定义,B+tree存储的数据总量:M ={X ^ (N-1)} * Y
前文中我们说到主键类型会影响行数,那么此时我们假设主键类型为bigint类型,占8个字节,而在InnoDB源码中页号(FIL_PAGE_OFFSET)被设置为4字节。则此时非叶子节点能存储的数据量为
X = 15 * 1024 / (8 +4) = 1280
前面已经将目录,页头,页尾作为1KB排除,所以这里是15
基于此:在来做一个假设,假设叶子节点中存储的数据,每条的大小都为1KB,即每个数据页存储15条数据。
Y = 15
现在来看看B+tree的数据量
-
两层B+tree的数据量(N=2)
M = {X ^ (N-1)} * Y = {1280 ^ (2-1)} * 15 = 19200 条
-
三层B+tree的数据量(N=3)
M = {X ^ (N-1)} * Y = {1280 ^ (3-1)} * 15 = 24579000条
-
四层B+tree的数据量(N=4)
M = {X ^ (N-1)} * Y = {1280 ^ (4-1)} * 15 = 计算器都算不清楚了
可能还没有写到这么多数据,磁盘已经罢工了
从这里的24579000条,我们就知道为啥单表不推荐超过2000W了,三层B+tree的时候最多只有三次磁盘IO,四层的时候数据量太大,磁盘可能都造不住了。
四、啥时候能超过2000W的数据
不知道大家有没有注意到一点,在上面计算中,我们都是做了很多假设,其中就有一条:假设叶子节点中每条数据占用1KB,以此得出一个数据页的数据量Y=15。
在实际中,要是我一行的数据非常小,仅仅只占用了100KB(比如一个中间表,记录的仅仅是ID),此时
-
叶子节点数据页的数据量
Y = 15 * 1024 / 100 = 153
-
三层B+tree的数据量
M = {X ^ (N-1)} * Y = {1280 ^ (3-1)} * 153 = 250675200条
同样是三层B+tree,此时却可以存储2.5亿条数据,增长十倍,但是查找同样只需要三次磁盘IO,并不会对性能有太大影响。
这里说的是【叶子节点】数据页的数据行大小影响了最终存储的数据总量,实际上【非叶子节点】的数据页存储数量X的大小变化的时候,也会影响数据总量,但是这种影响一般会在B-tree中体现。
我们知道B-tree跟B+tree最大的区别就是B-tree的非叶子节点中存储的是真实的数据行,而数据页的大小是16KB固定的,因此相同数据下,B-tree需要更多数据页才能存储数据,数据页增多势必会造成非叶子节点的层级变高,造成更多的磁盘IO,导致性能下降。这也是InnoDB使用B+tree作为索引结构,而不用B-tree的原因。
-
总结
这里总结一下前文中提的问题其他影响行数的因素?现在就很清晰了,除了主键大小和磁盘限制,最重要的就是索引的结构,即B+tree。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 14
14 2
2- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)