你需要了解的Java快捷开发 stream的使用(一) stream对List集合进行查询、统计等操作
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如
Stream简介
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。
什么是 Stream?
Stream(流)是一个来自数据源的元素队列并支持聚合操作
- 元素是特定类型的对象,形成一个队列。 Java中的Stream并不会存储元素,而是按需计算。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器generator 等。
- 聚合操作 类似SQL语句一样的操作, 比如filter, map, reduce, find, match, sorted等。
和以前的Collection操作不同, Stream操作还有两个基础的特征:
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行(laziness)和短路( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过Iterator或者For-Each的方式, 显式的在集合外部进行迭代, 这叫做外部迭代。 Stream提供了内部迭代的方式, 通过访问者模式(Visitor)实现。
为什么需要 Stream
Stream 作为 Java 8 的一大亮点,它与 java.io 包里的 InputStream 和 OutputStream 是完全不同的概念。它也不同于 StAX 对 XML 解析的 Stream,也不是 Amazon Kinesis 对大数据实时处理的 Stream。Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言+多核时代综合影响的产物。
什么是聚合操作
在传统的 J2EE 应用中,Java 代码经常不得不依赖于关系型数据库的聚合操作来完成诸如:
- 客户每月平均消费金额
- 最昂贵的在售商品
- 本周完成的有效订单(排除了无效的)
- 取十个数据样本作为首页推荐
这类的操作。
但在当今这个数据大爆炸的时代,在数据来源多样化、数据海量化的今天,很多时候不得不脱离 RDBMS,或者以底层返回的数据为基础进行更上层的数据统计。而 Java 的集合 API 中,仅仅有极少量的辅助型方法,更多的时候是程序员需要用 Iterator 来遍历集合,完成相关的聚合应用逻辑。这是一种远不够高效、笨拙的方法。在 Java 7 中,如果要发现 type 为 grocery 的所有交易,然后返回以交易值降序排序好的交易 ID 集合
生成流
在 Java 8 中, 集合接口有两个方法来生成流:
-
stream() − 为集合创建串行流。
-
parallelStream() − 为集合创建并行流。
List<String> strings = Arrays.asList("abc", "", "bc", "efg", "abcd","", "jkl");
List<String> filtered = strings.stream().filter(string -> !string.isEmpty()).collect(Collectors.toList());Collector 接口中方法:
1 List toList() 把流中元素收集到List
举例: List<Employee> emps= list.stream().collect(Collectors.toList());
2 Set toSet() 把流中元素收集到Set
举例: Set<Employee> emps= list.stream().collect(Collectors.toSet());
3 Collection toCollection() 把流中元素收集到创建的集合
举例: Collection<Employee>emps=list.stream().collect(Collectors.toCollection(ArrayList::new));
4 Long counting() 计算流中元素的个数
举例: long count = list.stream().collect(Collectors.counting());
5 Integer summingInt() 对流中元素的整数属性求和
举例: int total=list.stream().collect(Collectors.summingInt(Employee::getAge));
6 Double averagingInt() 计算流中元素Integer属性的平均值
举例: double avg = list.stream().collect(Collectors.averagingInt(Employee::getAge));
7 IntSummaryStatistics summarizingInt() 收集流中Integer属性的统计值。如:平均值
举例: int SummaryStatisticsiss= list.stream().collect(Collectors.summarizingInt(Employee::getAge));
String joining() String 连接流中每个字符串
举例:String str= list.stream().map(Employee::getName).collect(Collectors.joining());
举例:String str= list.stream().map(Employee::getName).collect(Collectors.joining(",", "{", "}")));
举例:String str= list.stream().map(Employee::getName).collect(Collectors.joining(","));
9: Optional maxBy() 根据比较器选择最大值
举例:Optional<Emp>max= list.stream().collect(Collectors.maxBy(Comparator.comparingDouble(Employee::getSalary)));
10:Optional minBy() 根据比较器选择最小值
举例:Optional<Emp> min = list.stream().collect(Collectors.minBy(Comparator.comparingDouble(Employee::getSalary)));
11:reducing() 从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值
举例: int total=list.stream().collect(Collectors.reducing(0, Employee::getAge, Integer::sum));
12:collectingAndThen() 转换函数返回的类型 包裹另一个收集器,对其结果转换函数
举例:int how= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size));
13:Map<K, List> groupingBy() 根据某属性值对流分组,属性为K,结果为V
举例:Map<String, List<Employee>> map= list.stream().collect(Collectors.groupingBy(Employee::getName));
14:Map<Boolean, List> partitioningBy() 收集后根据true或false进行分区
举例: employees.stream().collect(Collectors.partitioningBy(employee -> employee.getSalary()>8000, Collectors.mapping(Employee::getName,Collectors.counting()))).forEach((Key, value)-> System.out.println(Key+"----"+value));
15:mapping()方法会将结果应用到另一个收集器上。
举例:employees.stream().collect(Collectors.partitioningBy(employee -> employee.getSalary()>8000, Collectors.mapping(Employee::getName,Collectors.toList()))).forEach((Key, value)-> System.out.println(Key+"----"+value));
16:flatMapping()–类似于Collectors.mapping() 方法,但粒度更细。两者都带一个函数和一个收集器参数用于收集元素,但flatMapping函数接收元素流,然后通过收集器进行累积操作,一般用于collect()里对嵌套流的处理
17:filtering()–类似Stream filter()方法,用于过滤输入元素,常和groupingBy/partitioningBy搭配使用
18:toUnmodifiableMap()–将元素聚集到一个不可修改的Map,Map中的对象地址不可修改,里面的对象若支持修改的话,其实也还是可以修改的。
19:toUnmodifiableSet()—将元素聚集到一个不可修改的HashSet
20:toMap()—将元素聚集到一个map中
21:toConcurrentMap()—将元素聚集到一个支持并发的concurrentHashMap中
22:toUnmodifiableList()—将元素聚集到一个不可修改的ArrayList
23:groupingByConcurrent()—类似groupingBy(),但其聚集的集合是concurrentHashMap支持并发,可以提高并行流分组的效率
24:teeing()–返回一个由两个下游收集器组成的收集器。传递给生成的收集器的每个元素都由下游收集器处理,然后使用指定的合并函数将它们的结果合并到最终结果中。
支持使用两个独立的收集器收集流,然后使用提供的双功能合并结果。
综合实例
1.创建实体类和数据
User.java
import java.math.BigDecimal;
/**
* 用户信息实体类 by 青冘
**/
public class User
{
private int id; //用户ID
private String name; //用户名称
private String sex; //性别
private int age; //年龄
private String department; //部门
private BigDecimal salary; //薪资
//构造方法
public User(int id,String name,String sex,int age,String department,BigDecimal salary)
{
this.id = id;
this.name = name;
this.sex = sex;
this.age = age;
this.department = department;
this.salary = salary;
}
public int getId()
{
return id;
}
public void setId(int id)
{
this.id = id;
}
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
public String getSex()
{
return sex;
}
public void setSex(String sex)
{
this.sex = sex;
}
public int getAge()
{
return age;
}
public void setAge(int age)
{
this.age = age;
}
public String getDepartment()
{
return department;
}
public void setDepartment(String department)
{
this.department = department;
}
public BigDecimal getSalary()
{
return salary;
}
public void setSalary(BigDecimal salary)
{
this.salary = salary;
}
@Override
public String toString()
{
return "ID:" + this.id + " 名称:" + this.name + " 性别:" + this.sex
+ " 年龄:" + this.age + " 部门:" + this.department + " 薪资:" + this.salary + "元";
}
}UserService.class
import com.pjb.streamdemo.entity.User;
import java.math.BigDecimal;
import java.util.ArrayList;
import java.util.List;
/**
* 用户信息业务逻辑类 by 青冘
**/
public class UserService
{
/**
* 获取用户列表
*/
public static List<User> getUserList()
{
List<User> userList = new ArrayList<User>();
userList.add(new User(1, "青冘的博客_01", "男", 32, "研发部", BigDecimal.valueOf(1600)));
userList.add(new User(2, "青冘的博客_02", "男", 30, "财务部", BigDecimal.valueOf(1800)));
userList.add(new User(3, "青冘的博客_03", "女", 20, "人事部", BigDecimal.valueOf(1700)));
userList.add(new User(4, "青冘的博客_04", "男", 38, "研发部", BigDecimal.valueOf(1500)));
userList.add(new User(5, "青冘的博客_05", "女", 25, "财务部", BigDecimal.valueOf(1200)));
return userList;
}
}2.查询方法
2.1 forEach()
使用 forEach() 遍历列表数据。
/**
* 使用forEach()遍历列表信息 by 青冘
*/
@Test
public void forEachTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//遍历用户列表
userList.forEach(System.out::println);
}上述遍历语句等同于以下语句:
userList.forEach(user -> {System.out.println(user);});执行结果:
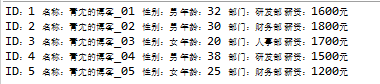
2.2 filter(T -> boolean)
使用 filter() 过滤列表数据
获取部门为“研发部”的用户列表。
/**
* 使用filter()过滤列表信息 by 青冘
*/
@Test
public void filterTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//获取部门为“研发部”的用户列表
userList = userList.stream().filter(user -> user.getDepartment() == "研发部").collect(Collectors.toList());
//遍历用户列表
userList.forEach(System.out::println);
}执行结果:
![]()
2.3findAny() 和 findFirst()
使用 findAny() 和 findFirst() 获取第一条数据。
获取用户名称为“青冘的博客_02”的用户信息,如果未找到则返回null。
/**
* 使用findAny()获取第一条数据 by 青冘
*/
@Test
public void findAnytTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//获取用户名称为“青冘的博客_02”的用户信息,如果没有找到则返回null
User user = userList.stream().filter(u -> u.getName().equals("青冘的博客_02")).findAny().orElse(null);
//打印用户信息
System.out.println(user);
}执行结果:

注意:findFirst() 和 findAny() 都是获取列表中的第一条数据,但是findAny()操作,返回的元素是不确定的,对于同一个列表多次调用findAny()有可能会返回不同的值。使用findAny()是为了更高效的性能。如果是数据较少,串行地情况下,一般会返回第一个结果,如果是并行(parallelStream并行流)的情况,那就不能确保是第一个。
2.4map(T -> R) 和 flatMap(T -> Stream)
使用 map() 将流中的每一个元素 T 映射为 R(类似类型转换)。
使用 flatMap() 将流中的每一个元素 T 映射为一个流,再把每一个流连接成为一个流。
使用 map() 方法获取用户列表中的名称列。
/**
* 使用map()获取列元素 by 青冘
*/
@Test
public void mapTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//获取用户名称列表
List<String> nameList = userList.stream().map(User::getName).collect(Collectors.toList());
//或者:List<String> nameList = userList.stream().map(user -> user.getName()).collect(Collectors.toList());
//遍历名称列表
nameList.forEach(System.out::println);
}返回的结果为数组类型,写法如下:
//数组类型
String[] nameArray = userList.stream().map(User::getName).collect(Collectors.toList()).toArray(new String[userList.size()]);执行结果:
使用 flatMap() 将流中的每一个元素连接成为一个流。
/**
* 使用flatMap()将流中的每一个元素连接成为一个流 by 青冘
*/
@Test
public void flatMapTest()
{
//创建城市
List<String> cityList = new ArrayList<String>();
cityList.add("北京;上海;深圳;");
cityList.add("广州;武汉;杭州;");
//分隔城市列表,使用 flatMap() 将流中的每一个元素连接成为一个流。
cityList = cityList.stream()
.map(city -> city.split(";"))
.flatMap(Arrays::stream)
.collect(Collectors.toList());
//遍历城市列表
cityList.forEach(System.out::println);
}执行结果:

2.5 distinct()
使用 distinct() 方法可以去除重复的数据。
获取部门列表,并去除重复数据。
/**
* 使用distinct()去除重复数据 by 青冘
*/
@Test
public void distinctTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//获取部门列表,并去除重复数据
List<String> departmentList = userList.stream().map(User::getDepartment).distinct().collect(Collectors.toList());
//遍历部门列表
departmentList.forEach(System.out::println);
}执行结果:

2.6 limit(long n) 和 skip(long n)
limit(long n) 方法用于返回前n条数据,skip(long n) 方法用于跳过前n条数据。
/**
* limit(long n)方法用于返回前n条数据
* skip(long n)方法用于跳过前n条数据 by 青冘
*/
@Test
public void limitAndSkipTest()
{
//获取用户列表
List<User> userList = UserService.getUserList();
//获取用户列表,要求跳过第1条数据后的前3条数据
userList = userList.stream()
.skip(1)
.limit(3)
.collect(Collectors.toList());
//遍历用户列表
userList.forEach(System.out::println);
}执行结果:
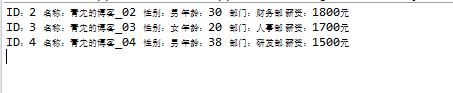
3.统计方法
3.1 reduce((T, T) -> T) 和 reduce(T, (T, T) -> T)
使用 reduce((T, T) -> T) 和 reduce(T, (T, T) -> T) 用于组合流中的元素,如求和,求积,求最大值等。
@Test
public void testReduce() {
Stream<Integer> stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7, 8});
//求集合元素之和
System.out.println("求集合元素之和");
Integer result = stream.reduce(0, Integer::sum);
System.out.println(result);
stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7});
//求和
System.out.println("求和");
stream.reduce((i, j) -> i + j).ifPresent(System.out::println);
stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7});
//求最大值
System.out.println("求最大值");
stream.reduce(Integer::max).ifPresent(System.out::println);
stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7});
//求最小值
System.out.println("求最小值");
stream.reduce(Integer::min).ifPresent(System.out::println);
stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7});
//做逻辑
System.out.println("做逻辑");
stream.reduce((i, j) -> i > j ? j : i).ifPresent(System.out::println);
stream = Arrays.stream(new Integer[]{1, 2, 3, 4, 5, 6, 7});
//求逻辑求乘机
System.out.println("求逻辑求乘机");
int result2 = stream.filter(i -> i % 2 == 0).reduce(1, (i, j) -> i * j);
Optional.of(result2).ifPresent(System.out::println);
}执行结果:

3.2 mapToInt(T -> int) 、mapToDouble(T -> double) 、mapToLong(T -> long)
int sumVal = userList.stream().map(User::getAge).reduce(0,Integer::sum);计算元素总和的方法其中暗含了装箱成本,map(User::getAge) 方法过后流变成了 Stream 类型,而每个 Integer 都要拆箱成一个原始类型再进行 sum 方法求和,这样大大影响了效率。针对这个问题 Java 8 有良心地引入了数值流 IntStream, DoubleStream, LongStream,这种流中的元素都是原始数据类型,分别是 int,double,long。
流转换为数值流:
- mapToInt(T -> int) : return IntStream
- mapToDouble(T -> double) : return DoubleStream
- mapToLong(T -> long) : return LongStream
//用户列表中年龄的最大值、最小值、总和、平均值
int maxVal = userList.stream().mapToInt(User::getAge).max().getAsInt();
int minVal = userList.stream().mapToInt(User::getAge).min().getAsInt();
int sumVal = userList.stream().mapToInt(User::getAge).sum();
double aveVal = userList.stream().mapToInt(User::getAge).average().getAsDouble(); 3.3 counting() 和 count()
使用 counting() 和 count() 可以对列表数据进行统计。
//统计研发部的人数,使用 counting()方法进行统计
Long departCount = userList.stream().filter(user -> user.getDepartment() == "研发部").collect(Collectors.counting());
//统计30岁以上的人数,使用 count()方法进行统计(推荐)
Long ageCount = userList.stream().filter(user -> user.getAge() >= 30).count();3.4 summingInt()、summingLong()、summingDouble()
用于计算总和,需要一个函数参数。
//计算年龄总和
int sumAge = userList.stream().collect(Collectors.summingInt(User::getAge));3.5 averagingInt()、averagingLong()、averagingDouble()
用于计算平均值
//计算平均年龄
double aveAge = userList.stream().collect(Collectors.averagingDouble(User::getAge));
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)