Hive自定义UDF函数详解
Hive自定义UDF函数详解一、UDF概述二、UDF种类三、如何自定义UDF四、自定义实现UDF和UDTF4.1 需求4.2 项目pom文件4.3 Hive建表测试及数据4.4 UDF函数编写4.5 UDTF函数编写一、UDF概述UDF全称:User-Defined Functions,即用户自定义函数,在Hive SQL编译成MapReduce任务时,执行java方法,类似于像MapReduce
Hive自定义UDF函数详解
一、UDF概述
UDF全称:User-Defined Functions,即用户自定义函数,在Hive SQL编译成MapReduce任务时,执行java方法,类似于像MapReduce执行过程中加入一个插件,方便扩展。
二、UDF种类
UDF:操作单个数据行,产生单个数据行;
UDAF:操作多个数据行,产生一个数据行;
UDTF:操作一个数据行,产生多个数据行一个表作为输出;
三、如何自定义UDF
1.编写UDF函数,UDF需要继承org.apache.hadoop.hive.ql.exec.UDF,UDTF继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,UDAF使用比较少,这里先不讲解
2.将写好的类打包为jar,如HiveUDF-1.0.jar,并且上传到Hive机器或者HDFS目录
3.入到Hive shell环境中,输入命令add jar /home/hadoop/HiveUDF-1.0.jar注册该jar文件;或者把HiveUDF-1.0.jar上传到hdfs,hadoop fs -put HiveUDF-1.0.jar /home/hadoop/HiveUDF-1.0.jar,再输入命令add jar hdfs://hadoop60:8020/home/hadoop/HiveUDF-1.0.jar;
4.为UDF类起一个别名,create temporary function myudf as ‘com.master.HiveUDF.MyUDF’;注意,这里UDF只是为这个Hive会话临时定义的;
5.在select中使用myudf();
四、自定义实现UDF和UDTF
4.1 需求
1)UDF,自定义一个函数,并且实现把列中的数据由小写转换成大写
2)UDTF,拆分一个表中的name字段,以|为分割,分成不同的列,如下所示:
表中的数据为:
id name
1 Ba|qz
2 xa
要拆分成如下格式:
id name
1 Ba
1 qz
2 xa
4.2 项目pom文件
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.1.1</version>
</dependency>
4.3 Hive建表测试及数据
create table if not exists t_user (
id int,
name string
)
clustered by (id) into 2 buckets
row format delimited fields terminated by '|'
stored as orc TBLPROPERTIES('transactional'='true');
向Hive表中插入数据:
insert into t_user values(1,'Ba|qz');
insert into t_user values(1,'xa');
4.4 UDF函数编写
UDF函数需要继承org.apache.hadoop.hive.ql.exec.UDF类,并且添加evaluate方法,原因是:UDF类默认的UDFMethodResolver是org.apache.hadoop.hive.ql.exec.DefaultUDFMethodResolver,evaluate方法是在DefaultUDFMethodResolver中进行配置,默认绑定的是evaluate方法。
添加evaluate有两个注意事项:
1)evaluate方法遵循重载的原则,参数是用户自定义的,调用那个方法调用是在使用函数时候的参数决定。
2)evaluate方法必须有返回值,返回类型以及方法参数可以是Java数据或相应的Writable类。
具体实现:
public class MyUDF extends UDF {
public String evaluate(String s) {
if (s == null) {
return "";
}
return s.toUpperCase();
}
}
4.5 UDTF函数编写
1)UDTF限制(----后面为原文解析),官网地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-Built-inTable-GeneratingFunctions(UDTF)
在UDTF中Select里面不能有其他语句----No other expressions are allowed in SELECT/SELECT pageid, explode(adid_list) AS myCol… is not supported
UDTF不能被嵌套----UDTF’s can’t be nested/SELECT explode(explode(adid_list)) AS myCol… is not supported
UDTF不支持GROUP BY / CLUSTER BY / DISTRIBUTE BY / SORT BY----GROUP BY/ CLUSTER BY/ DISTRIBUTE BY/ SORT BY is not supported/SELECT explode(adid_list) AS myCol … GROUP BY myCol is not supported
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize,process,close三个方法。
2)注意事项
initialize方法制定了返回的列名及数据类型(forward写入数据的类型是一个数组,对应着initialize定义的列名),可以返回多个,在List里面对应即可。函数列名调用的时侯通过:myudtf(col,col1) t1 as co1,col2来使用列名。
3)实现
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyUDTF extends GenericUDTF {
@Override
public StructObjectInspector initialize(ObjectInspector[] argOIs) throws UDFArgumentException {
List<String> fieldNames = new ArrayList<>();
List<ObjectInspector> fieldTypes = new ArrayList<>();
fieldNames.add("col");
fieldTypes.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldTypes);
}
@Override
public void process(Object[] args) throws HiveException {
String col = args[0].toString();
String[] cols = col.split("\\|");
for (String c : cols) {
String[] results = new String[1];
results[0] = c;
forward(results);
}
}
@Override
public void close() throws HiveException {
}
}
4)在Hive Shell中添加临时函数
上传到Linux目录,然后用add jar来添加路径
hive>add jar /home/hadoop/hivetest/HiveUDF-1.0.jar
创建临时函数:
hive>create temporary function myudf as "com.master.HiveUDF.MyUDF";
hive>create temporary function myudtf as "com.master.HiveUDF.MyUDTF"
5)UDF使用
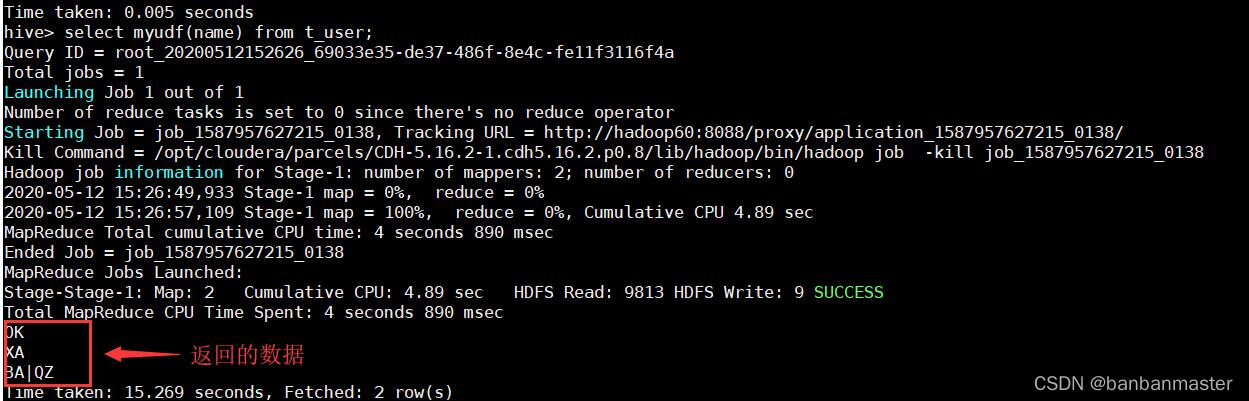
select myudf(name) from t_user;
效果如下
4.6 UDTF使用
select myudtf(name) from t_user
效果如下:
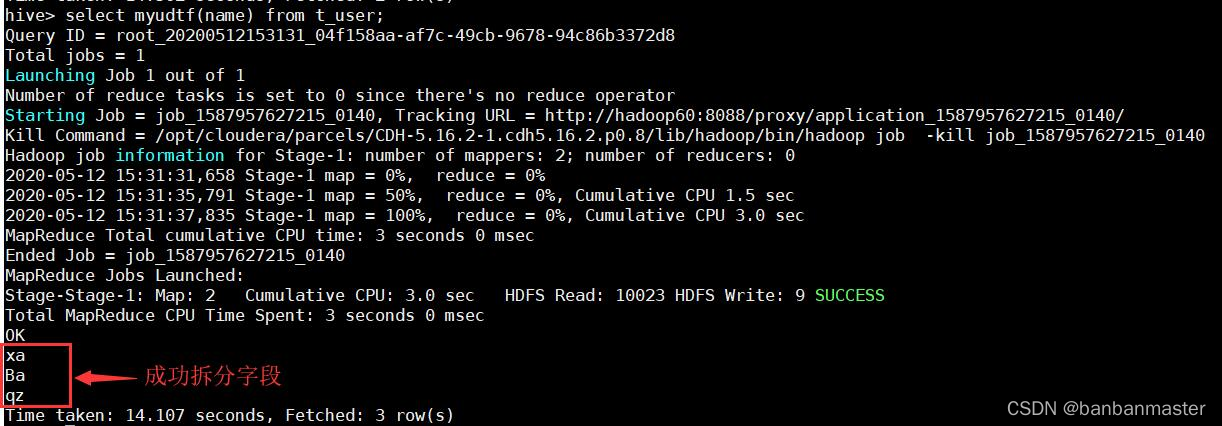
但是貌似没有和前面的数据结合,这时候,需要用lateral view来操作,语句如下
select t1.id,t2.col from t_user t1 lateral view myudtf(name) t2 as col
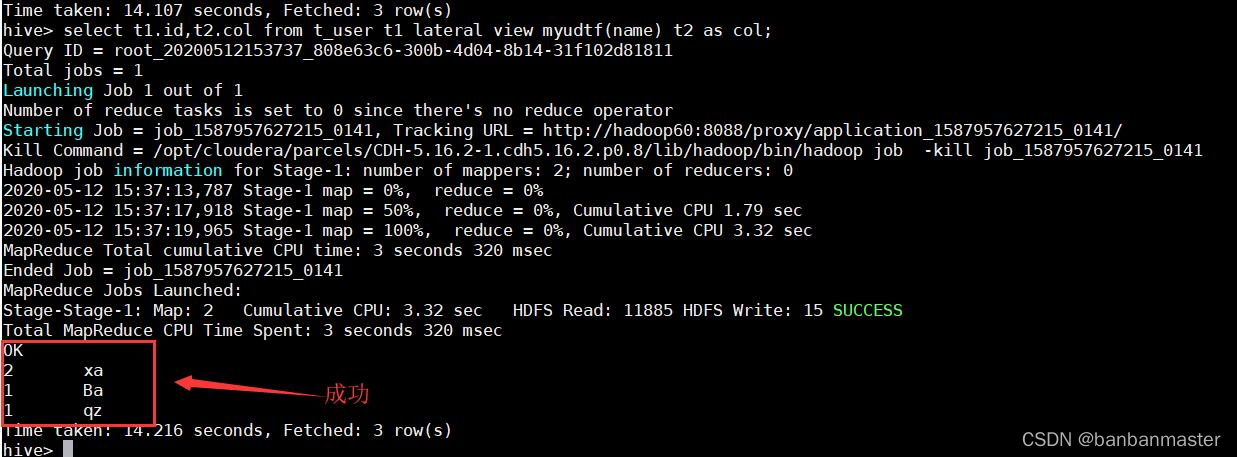
lateral view用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 10
10 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)