RocksDB的一些基本概念及简单应用(扫盲)
本文介绍RocksDB的一些基本概念和术语,及Java程序如何使用RocksDB。
一、简介
RocksDB是使用C++编写的嵌入式kv存储引擎,其键值均允许使用二进制流。由Facebook基于levelDB开发, 提供向后兼容的levelDB API。
二、写入机制
1、原理
首先,任何的写入都会先写到 WAL,然后在写入 Memory Table(Memtable)。当然为了性能,也可以不写入 WAL,但这样就可能面临崩溃丢失数据的风险。Memory Table 通常是一个能支持并发写入的 skiplist,但 RocksDB 同样也支持多种不同的 skiplist,用户可以根据实际的业务场景进行选择。
当一个 Memtable 写满了之后,就会变成 immutable 的 Memtable,RocksDB 在后台会通过一个 flush 线程将这个 Memtable flush 到磁盘,生成一个 Sorted String Table(SST) 文件,放在 Level 0 层。当 Level 0 层的 SST 文件个数超过阈值之后,就会通过 Compaction 策略将其放到 Level 1 层,以此类推。如图。
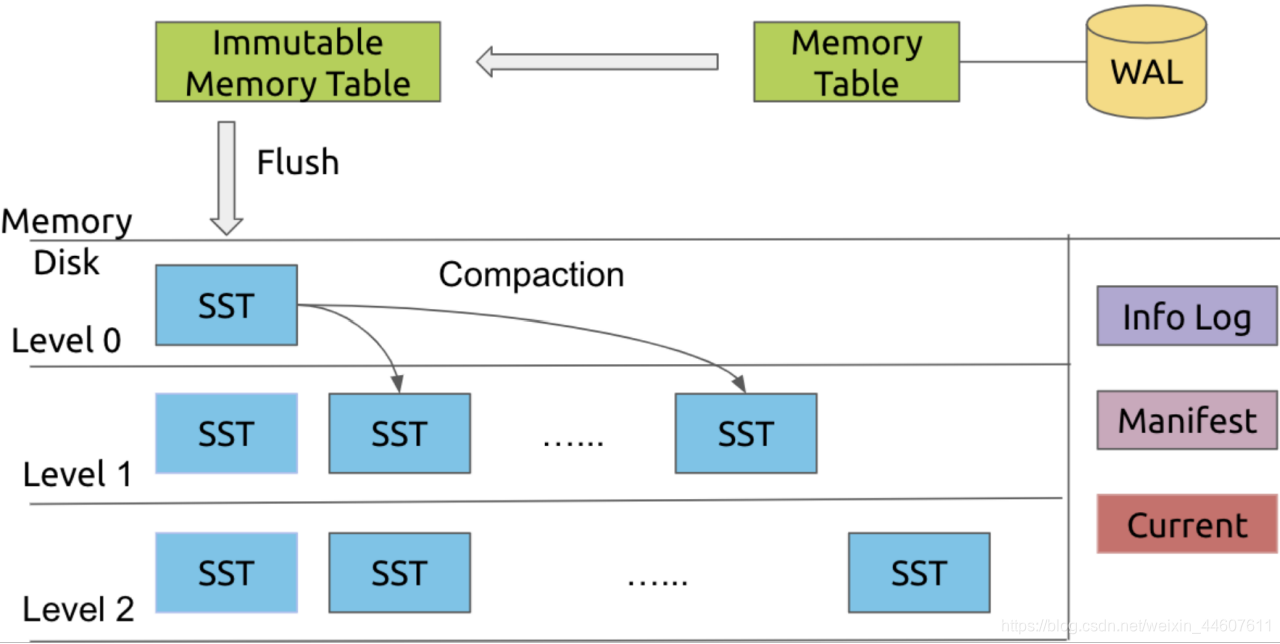
2、相关术语
2.1、LSM(log-structed-merge-tree)
上述原理是使用LSM tree这种结构来实现的,上图也是LSM tree的一种直观体现,那为什么要选用LSM tree呢?
B+树(MySQL InnoDB索引)和log型(append)文件操作(数据库WAL日志)是数据读写效率的两个极端。
磁盘读写分为随机读写和顺序读写,一般来说随机读写的效率要低于顺序读写。
B+树解决的是磁盘随机读慢的问题,但随机写无法保证效率,因为写入数据时涉及到树的重构。
log型(append)文件操作解决的是磁盘随机写慢的问题,但读时需要遍历整个文件。
B+树读效率高而写效率差;log型文件操作写效率高而读效率差;因此要在排序和log型文件操作之间做个折中,于是就引入了log-structed merge tree模型,通过名称可以看出LSM既有日志型的文件操作,提升写效率,又在每个sstable中排序,保证了查询效率。
2.2、WAL(Write Ahead Log)
顾名思义,就是在实际操作数据前先写日志,便于恢复。WAL在很多数据库中都存在。
RocksDB中的每个更新操作都会写到两个地方:
- 一个内存数据结构,名为memtable(后面会被刷盘到SST文件)
- 写到磁盘上的WAL日志。在出现崩溃的时候,WAL日志可以用于完整的恢复memtable中的数据,以保证数据库能恢复到原来的状态。在默认配置的情况下,RocksDB通过在每次写操作后对WAL调用flush来保证一致性。
2.3、Memtable
MemTable是一个内存数据结构,他保存了落盘到SST文件前的数据。他同时服务于读和写——新的写入总是将数据插入到memtable,读取在查询SST文件前总是要查询memtable,因为memtable里面的数据总是更新的。一旦一个memtable被写满,他会变成不可修改的,并被一个新的memtable替换。一个后台线程会把这个memtable的内容落盘到一个SST文件,然后这个memtable就可以被销毁了。
默认的memtable实现是基于skiplist的。除了默认的memtable实现,用户可以使用其他memtable实现,例如HashLinkList,HashSkipList或者Vector,以加快查询速度。
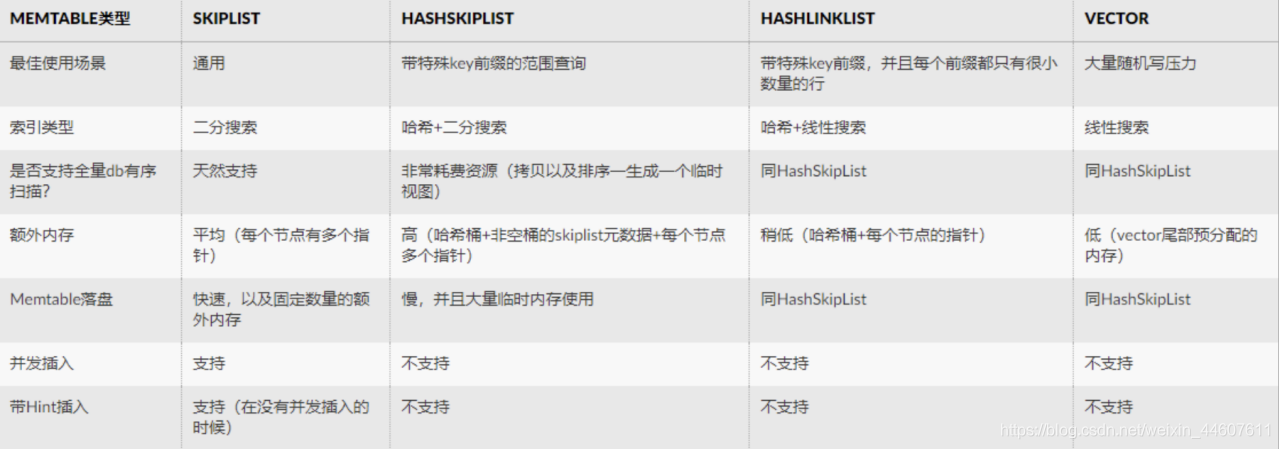
影响memtable的最重要的几个选项是:
- memtable_factory: memtable对象的工厂。通过声明一个工厂对象,用户可以改变底层memtable的实现,并提供事先声明的选项。
- write_buffer_size:一个memtable的大小。
- db_write_buffer_size:多个列族的memtable的大小总和。这可以用来管理memtable使用的总内存数。
- write_buffer_manager:除了声明memtable的总大小,用户还可以提供他们自己的写缓冲区管理器,用来控制总体的memtable使用量。这个选项会覆盖db_write_buffer_size。
- max_write_buffer_number:内存中可以拥有刷盘到SST文件前的最大memtable数。
这些都可以在RocksDB的Option对象中配置。
2.4、Flush
有三种场景会导致memtable落盘被触发:
- Memtable的大小在一次写入后超过write_buffer_size。
- 所有列族中的memtable大小超过db_write_buffer_size了,或者write_buffer_manager要求落盘。在这种场景,最大的memtable会被落盘。
- WAL文件的总大小超过max_total_wal_size。在这个场景,有着最老数据的memtable会被落盘,这样才允许携带有跟这个memtable相关数据的WAL文件被删除。
就结果来说,memtable可能还没写满就落盘了。这是为什么生成的SST文件小于对应的memtable大小。压缩是另一个导致SST文件变小的原因,因为memtable里的数据是没有压缩的。
2.5、Compaction
LSM-Tree 能将离散的随机写请求都转换成批量的顺序写请求(WAL + Compaction),以此提高写性能。但也带来了一些问题:
- 读放大(Read Amplification)。LSM-Tree 的读操作需要从新到旧(从上到下)一层一层查找,直到找到想要的数据。这个过程可能需要不止一次 I/O。特别是 range query 的情况,影响很明显。
- 空间放大(Space Amplification)。因为所有的写入都是顺序写(append-only)的,不是 in-place update ,所以过期数据不会马上被清理掉。
- 写放大。实际写入 HDD/SSD 的数据大小和程序要求写入数据大小之比。正常情况下,HDD/SSD 观察到的写入数据多于上层程序写入的数据。
RocksDB 和 LevelDB 通过后台的 compaction 来减少读放大(减少 SST 文件数量)和空间放大(清理过期数据),但也因此带来了写放大(Write Amplification)的问题。
写放大、读放大、空间放大,三者就像 CAP 定理一样,需要做好权衡和取舍。
压缩算法有很多种,RocksDB也支持很多种,这里我们看两个经典的压缩算法及区别
Tiered Compaction vs Leveled Compaction
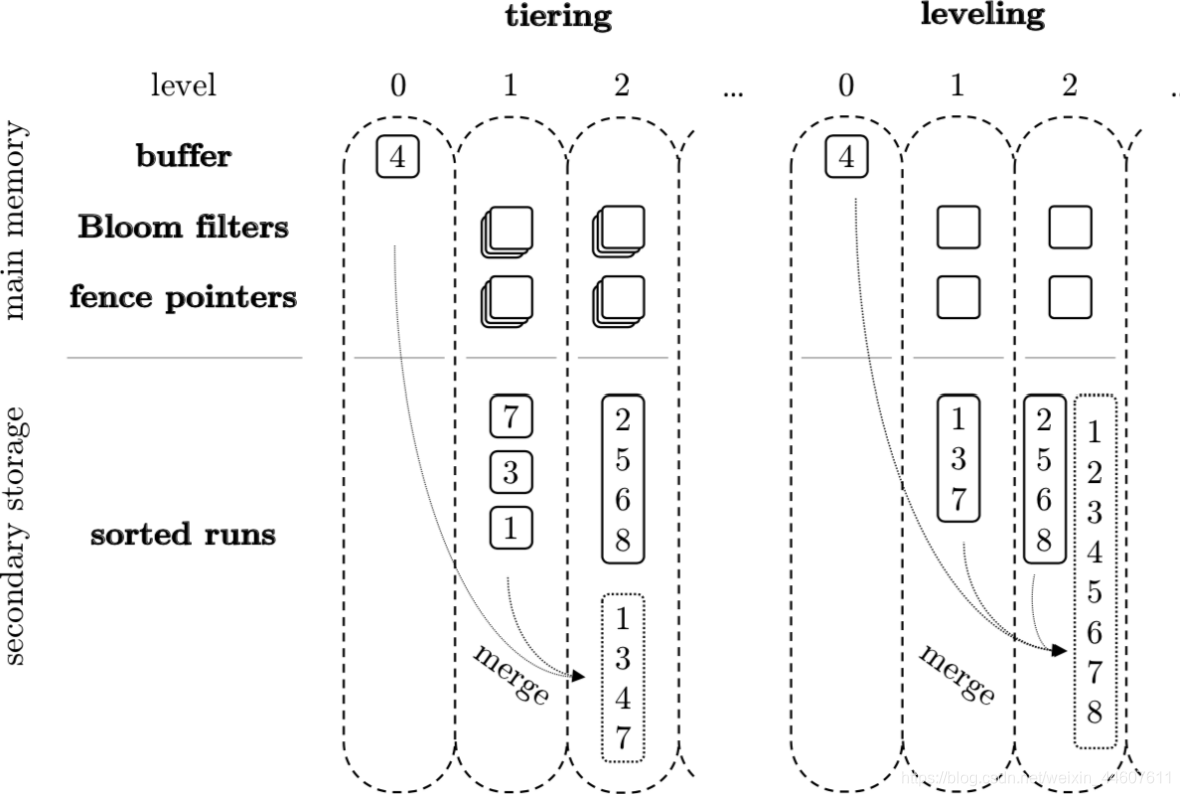
上图是两种 compaction 的区别,当 Level 0 刷到 Level 1,让 Level 1 的 SST 文件达到设定的阈值,就需要进行 compaction。
对于 Tiered 来说,我们会将所有的 Level 1 的文件 merge 成一个 Level 2 SST 放在 Level 2。也就是说,compaction 其实就是将上层的所有小的 SST merge 成下层一个更大的 SST 的过程。
而对于 Leveled 来说,不同 Level 里面的 SST 大小都是一致的,Level 1 里面的 SST 会跟 Level 2 一起进行 merge 操作,最终在 Level 2 形成一个有序的 SST,而各个 SST 不会重叠。
三、RocksDB在磁盘中生成的文件
1、生成的文件
图中为Windows环境生成的文件截图,在Linux中是一样的。
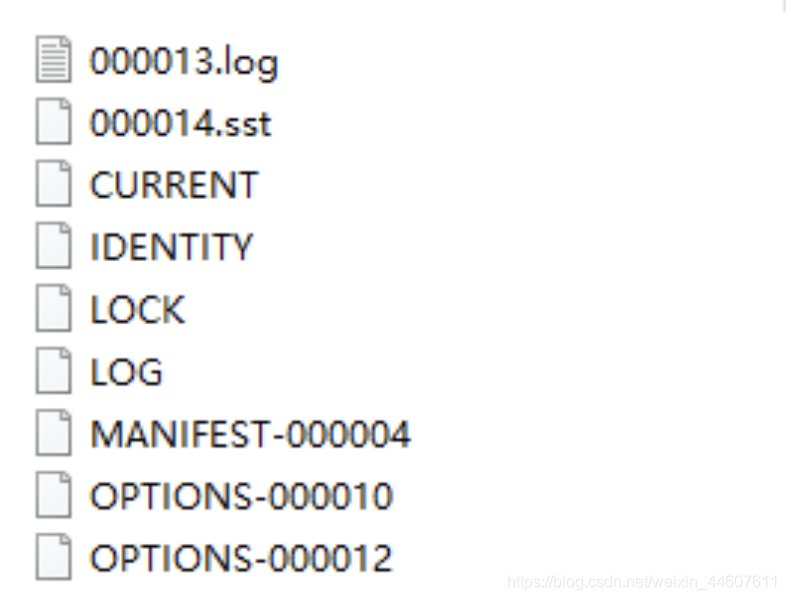
2、文件作用解释
xxx.log:wal日志文件
xxx.sst:数据文件
CURRENT:是一个特殊的文件,用于声明最新的manifest日志文件
IDENTITY:id
LOCK:无内容,open时创建,表示一个db在一个进程中只能被open一次,多线程共用此实例
LOG:统计日志
MANIFEST:指一个独立的日志文件,它包含RocksDB的状态快照/版本
OPTIONS:配置信息
2.1、MANIFEST
Rocksdb对文件系统以及存储介质保持不可预知的态度。文件系统操作不是原子的,并且在系统错误的时候容易出现不一致。即使打开了日志系统,文件系统还是不能在一个不合法的重启中保持一致。POSIX文件系统不支持原子化的批量操作。因此,无法依赖RocksDB的数据存储文件中的元数据文件来构建RocksDB重启前的最后的状态。
RocksDB有一个内建的机制来处理这些POSIX文件系统的限制,这个机制就是保存一个名为MANIFEST的RocksDB状态变化的事务日志文件。MANIFEST文件用于在重启的时候,恢复RocksDB到最后一个一致的一致性状态。
- MANIFEST 指通过一个事务日志,来追踪RocksDB状态迁移的系统
- Manifest日志 指一个独立的日志文件,它包含RocksDB的状态快照/版本
- CURRENT 指最后的Manifest日志
RocksDB 称 Manifest 文件记录了 DB 状态变化的事务性日志,也就是说它记录了所有改变 DB 状态的操作。
RocksDB 的函数 VersionSet::LogAndApply 是对 Manifest 文件的更新操作,所以可以通过定位这个函数出现的位置来跟踪 Manifest 的记录内容。
Manifest 文件作为事务性日志文件,只要数据库有变化,Manifest都会记录。其内容 size 超过设定值后会被 VersionSet::WriteSnapShot 重写。
RocksDB 进程 Crash 后 Reboot 的过程中,会首先读取 Manifest 文件在内存中重建 LSM 树,然后根据 WAL 日志文件恢复 memtable 内容。
四、其他术语
1、Column Family
在RocksDB3.0,增加了Column Families的支持。
RocksDB的每个键值对都与唯一一个列族(column family)结合。如果没有指定Column Family,键值对将会结合到“default” 列族。
列族提供了一种从逻辑上给数据库分片的方法。他的一些有趣的特性包括:
支持跨列族原子写。意味着你可以原子执行Write({cf1, key1, value1}, {cf2, key2, value2})。
跨列族的一致性视图。
允许对不同的列族进行不同的配置
即时添加/删除列族。两个操作都是非常快的。
列族的主要实现思想是他们共享一个WAL日志,但是不共享memtable和table文件。通过共享WAL文件,我们实现了酷酷的原子写。通过隔离memtable和table文件,我们可以独立配置每个列族并且快速删除它们。
每当一个单独的列族刷盘,我们创建一个新的WAL文件。所有列族的所有新的写入都会去到新的WAL文件。但是,我们还不能删除旧的WAL,因为他还有一些对其他列族有用的数据。我们只能在所有的列族都把这个WAL里的数据刷盘了,才能删除这个WAL文件。这带来了一些有趣的实现细节以及一些有趣的调优需求。确保你的所有列族都会有规律地刷盘。另外,看一下Options::max_total_wal_size,通过配置他,过期的列族能自动被刷盘。
如果类比到关系型数据库中,列族可以看做是表的概念。
2、Statistics
用法:
创建一个statistics对象传给options,rocksdb.open时将options传进去。
open后可通过options拿出statistics对象,可直接在代码中获取统计信息;也可配置时间,周期性将统计信息输出到日志中。
官方文档中指出,打开statistics会损失5%-10%的性能。
这里做个小测试
创建4个列族,向其中一个列族批量插入100W条数据,通过代码获取全部统计信息,打印到控制台。
数据统计类型分成两种:
- ticker:计数,类型是64位无符号整型。用于度量counters (e.g. “rocksdb.block.cache.hit”), cumulative bytes (e.g. “rocksdb.bytes.written”) 或者 time (e.g. “rocksdb.l0.slowdown.micros”)。
- histogram:统计数据的统计分布,大多数用于DB操作的耗时分布。
ticker输出截图如下:
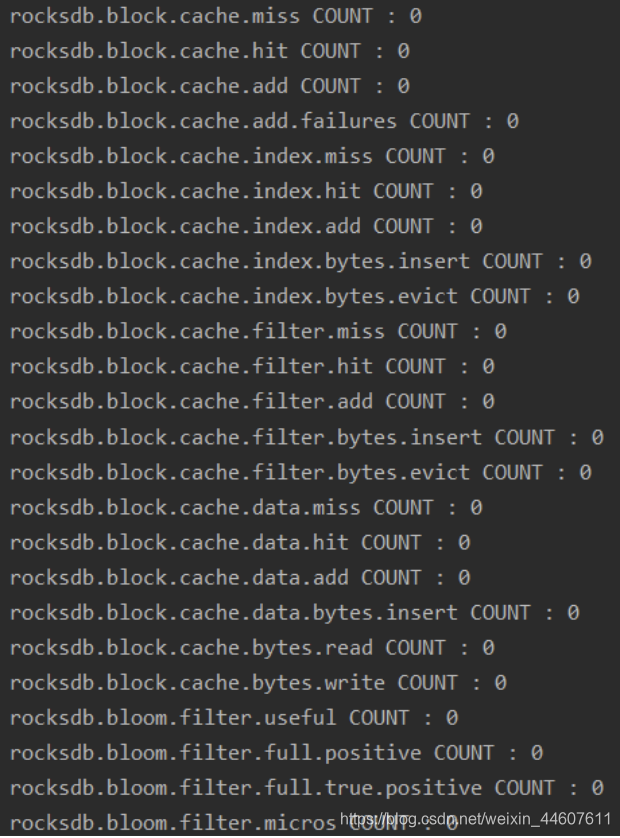
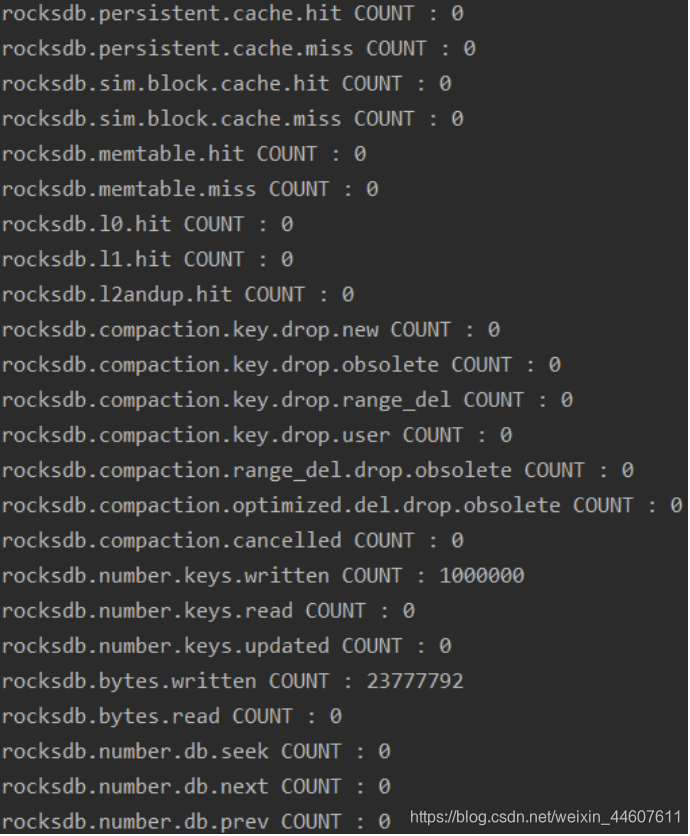
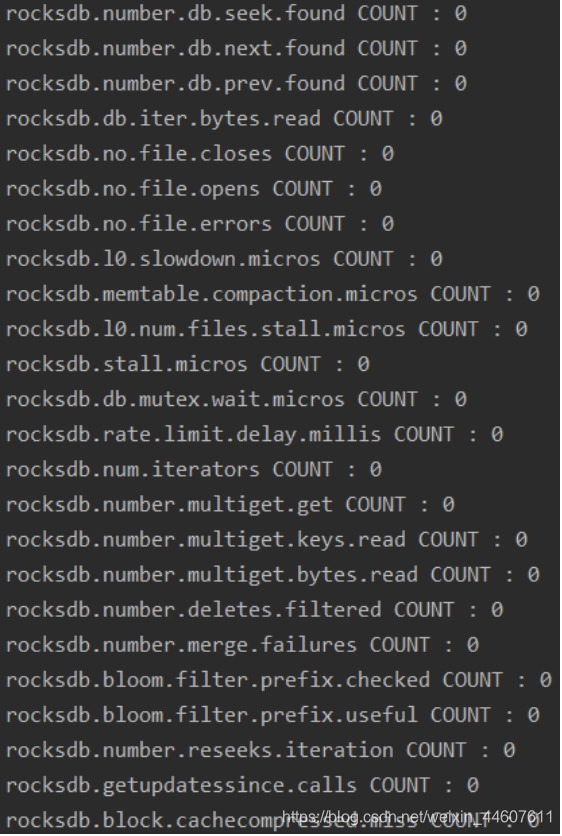
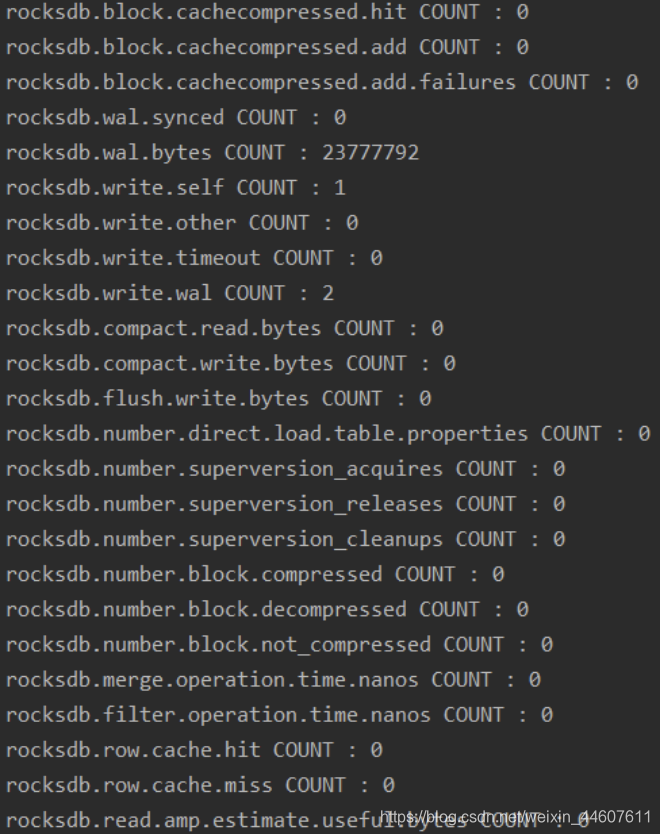
histogram输出截图如下:
3、Snapshot
一个快照会捕获在创建的时间点的DB的一致性视图。快照在DB重启之后将消失。
4、Iterator
RocksDB迭代器允许用户以一个排序好的顺序向后或者向前遍历db。它还拥有查找DB中的一个特定key的功能,为此,迭代器需要以一个排序好的流来访问DB。
迭代器可以结合快照使用。比如Jraft源码中的这一段,就是使用迭代器遍历RocksDB中的数据,来找到一个中间值。
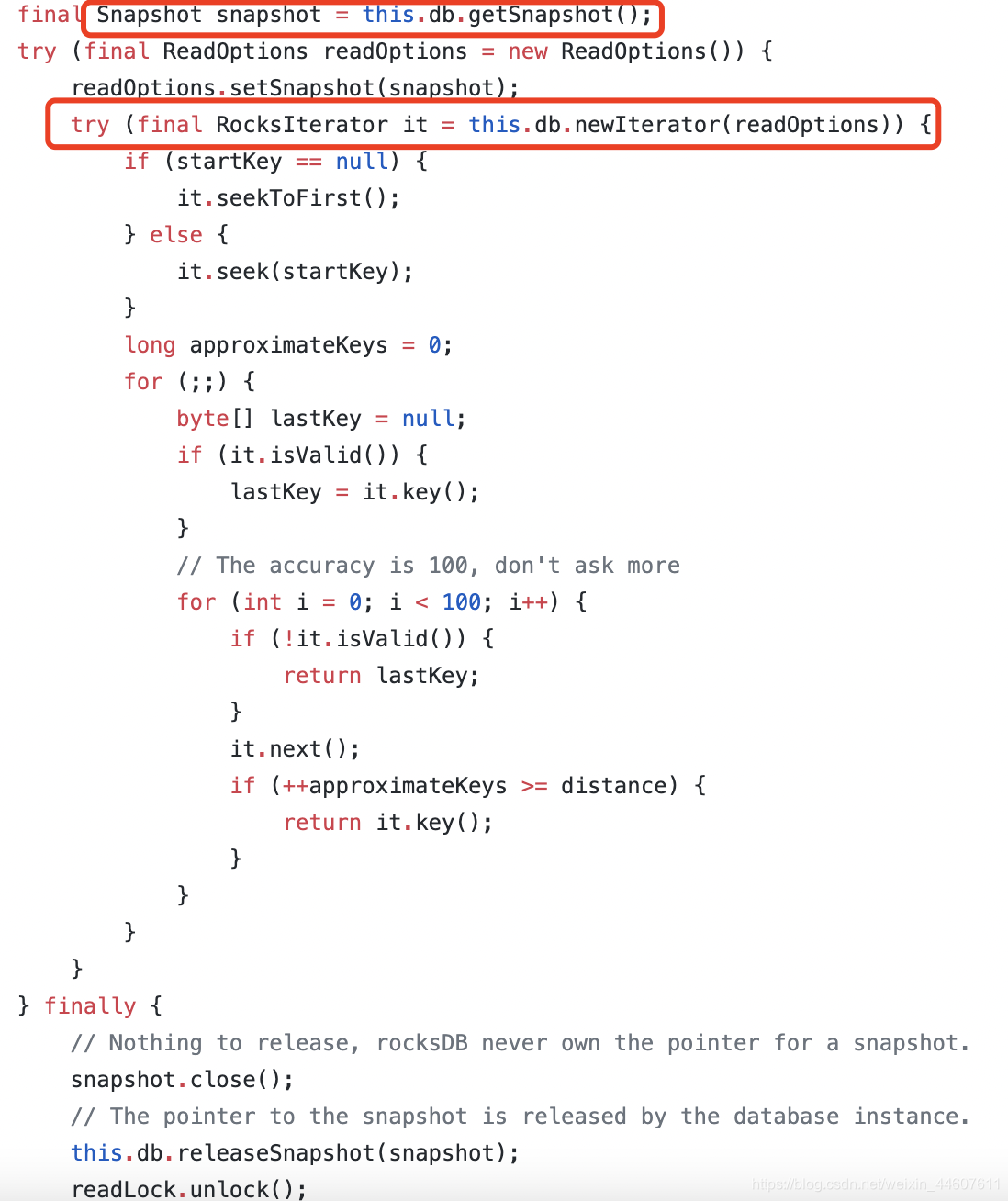
5、Ingest
RocksDB向用户提供了一系列API用于创建及导入SST文件。在你需要快速读取数据但是数据的生成是离线的时候,这非常有用。
可以通过SstFileWriter这个对象来直接写sst,然后再将sst通过Ingest导入到RocksDB中。
注意:
- 传给SstFileWriter的Options会被用于指定表类型,压缩选项等,用于创建sst文件。
- 传入SstFileWriter的Comparator必须与之后导入这个SST文件的DB的Comparator绝对一致。
- 行必须严格按照增序插入
五、Java程序中的应用
1、业界应用
蚂蚁金服开源的SOFA-Jraft,采用RocksDB存储raft日志。
百度开源图数据库HugeGraph,默认采用RocksDB作为存储引擎。
国产开源分布式数据库TiDB,底层采用RocksDB作为存储引擎。
2、本地简单应用
使用maven构建项目,在pom.xml中加入依赖
<dependency>
<groupId>org.rocksdb</groupId>
<artifactId>rocksdbjni</artifactId>
</dependency>
简单的kv插入和查询,就是先open出一个rocksdb实例,构造方法中传入配置和路径,然后通过这个实例来进行操作
/**
* @author ctl
* @date 2021/2/7
*/
public class RocksTest {
RocksDB rocksDB;
String path = "/Users/ctl/rocksTest";
@Test
public void testOpen() throws RocksDBException {
RocksDB.loadLibrary();
Options options = new Options();
options.setCreateIfMissing(true);
rocksDB = RocksDB.open(options, path);
rocksDB.put("key".getBytes(), "val".getBytes());
byte[] bytes = rocksDB.get("key".getBytes());
System.out.println(new String(bytes));
}
}
使用Java操作RocksDB是基于jni机制,目前Java的API没有C++的全,但上面介绍的一些术语,比如快照、迭代器、导入等等,都是可以使用Java的API来操作的,操作方式跟上述demo很像,都是open出rocosdb实例后,通过实例来进行对应的操作,这并不难。
难点在于,open时要传入的option对象可配置的太多了,就连rocksdb开发者都没有给出一个完美的调优方案,只是给出了一系列调优参考值,建议的是在不同的应用场景中通过压测来进行参数调优。github上的调优参考链接如下。
https://github.com/facebook/rocksdb/wiki/RocksDB-Tuning-Guide
此图为上面链接的文档中最后一段,可见rocksdb调优是多么复杂的一件事。

六、总结
RocksDB可以作为内嵌式数据库来使用,也可以作为自研数据库的底层存储引擎来使用,其数据结构是LSM tree,保证了读写效率。
使用简单但调优困难,可以借鉴业界中一些开源产品对其使用时设置的参数,来参考调优。但切忌盲目“抄袭”参数,毕竟业务场景不同,对应的调优参数也是不同的。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)