sqlserver中的字符编码、排序规则、nvarchar和varchar、大N‘‘
sqlserver:一般我们在window或window server上安装sqlserver,安装后默认排序规则是:Chinese_PRC_CI_AS(GBK编码,不区分大小写,区分重音)。Chinese_PRC:针对大陆简体字UNICODE(unicode,而非UTF-8)的排序规则。CI:CaseSensitivity,指定不区分大小写。AS:AccentSensitivity,指定区分重音
环境:
- sqlserver 2014
- window 10
建议先阅读《细说ASCII、GB2312/GBK/GB18030、Unicode、UTF-8/UTF-16/UTF-32编码》
先说下结论:
- 如果你想在数据库中存储emoji表情等特殊字符,就需要将varchar改为nvarchar并且在编写sql语句时使用大N
(N'小明...')。- 默认的sqlserver中字符串的排序比较已忽略掉了全角/半角、大/小写的差别,所以不用担心因为大小写和全半角搜索不到数据的问题。
一、说说字符集、字符集编码和排序规则
- 字符集:罗列所有图形字符的一张大表。
比如:
- GBK字符集(中国制造): 罗列了所有的中文简体、繁体字的一张大表。
- Unicode字符集(全世界通用):罗列了世界上所有图形字符的一张大表。
- 字符集编码:将字符集上罗列的图形字符存储到计算机中的一种编码规则。
比如:
- 排序规则:定义各个图形字符之间的大小比较规则,比如:是否区分大小写,区分全角和半角等。
在软件使用中,一般我们只指定字符编码即可,因为确定了字符编码字符集自然就确定了。
但是在数据库类软件中,我们除了要指定编码规则,还需要指定排序规则,因为,数据库是要提供模糊匹配、排序显示功能的。
二、sqlserver中字符集编码和排序规则
上面虽然把字符集、字符集编码、排序规则的概念分的很清,但sqlserver中的配置并没有分的太清。
在sqlserver中没有单独设置字符集编码的地方,仅能设置排序规则。
至于最终使用什么字符集编码,则会受排序规则、数据类型(varchar、nvarchar)的影响。
一般我们在window或window server上安装sqlserver 2014,安装后默认排序规则是:Chinese_PRC_CI_AS。
Chinese_PRC:针对大陆简体字UNICODE的排序规则。
CI:CaseSensitivity,指定不区分大小写。
AS:AccentSensitivity,指定区分重音。
sqlserver设置排序规则有四个级别:
-
服务器(示例级别):
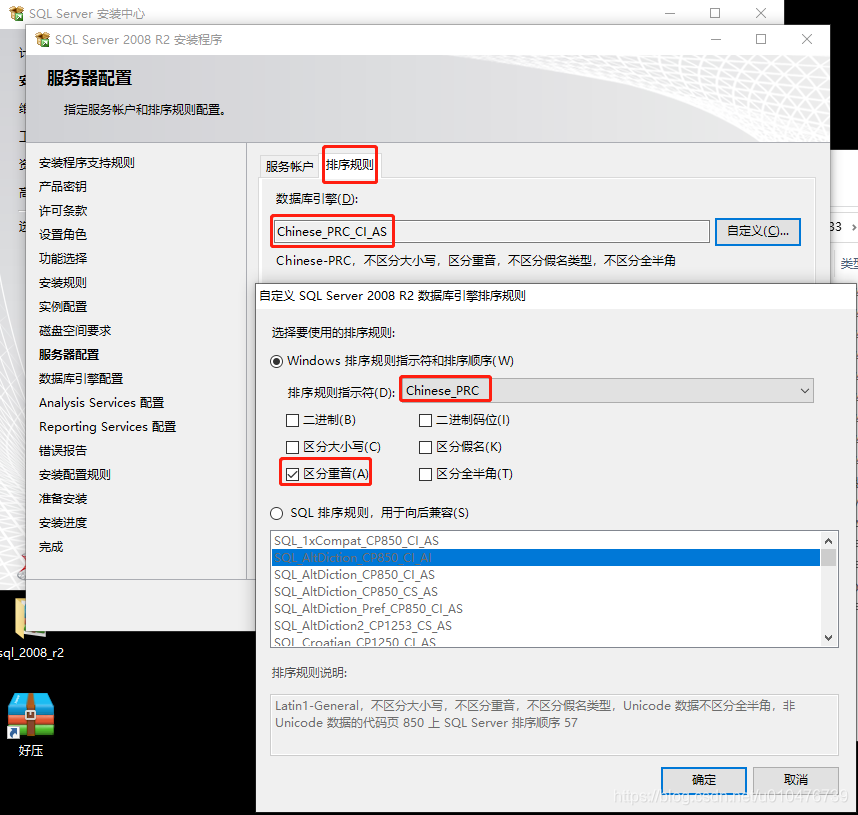
-
数据库:
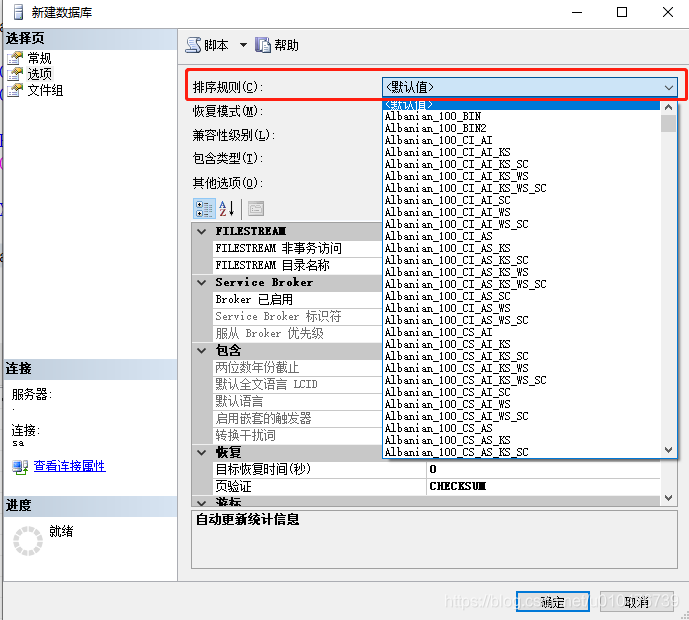
-
列级别:
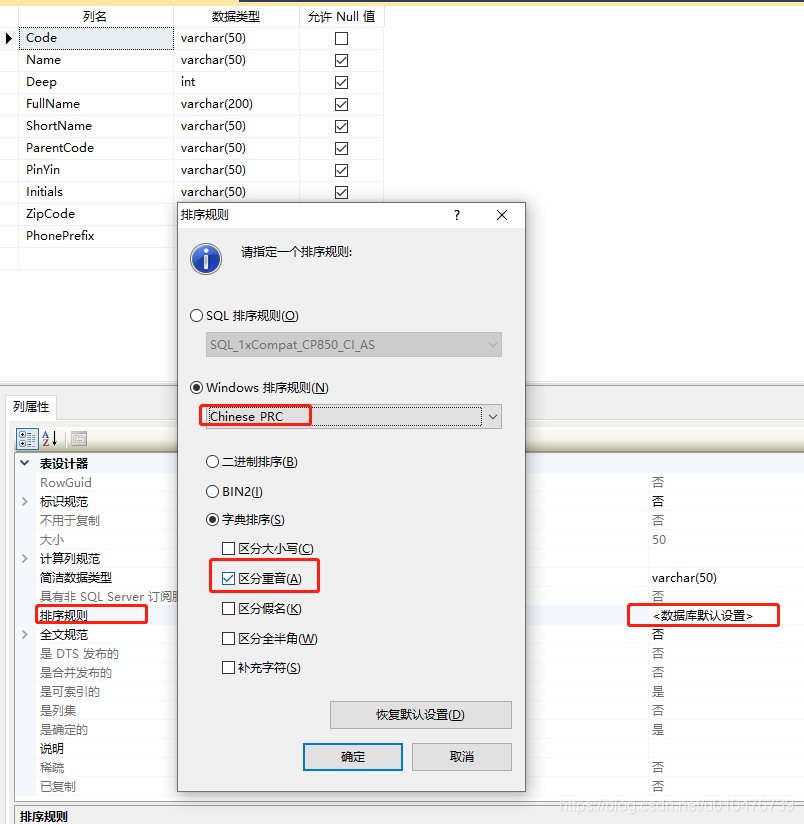
-
表达式级别:
SELECT name FROM customer ORDER BY name COLLATE Latin1_General_CS_AI;
注意:
Chinese_PRC_CI_AS不是存储为UTF8,事实上,直到SqlServer2019才引入UTF-8的支持(Chinese_PRC_CI_AS_UTF8)。
参照:
《Introducing UTF-8 support for SQL Server》
《排序规则和 Unicode 支持》
附:查询排序规则元数据
-- 查询数据库的排序规则
select serverproperty(N'Collation');
--查询所有受支持的排序规则
select * from fn_helpcollations()
-- 查询列的排序规则
select name,collation_name from sys.columns where collation_name is not null
三、排序规则对sql语句的一影响
观察排序规则对sql语句影响的时候,我主要从以下两个方面考虑:
- 全角/半角
- 大写/小写
至于其他的重音、假名则是很难用到,直接用默认的即可。
分析其他数据库的排序规则时,也可以从这两个方面考虑,经过综合对比,sqlserver中的排序规则还是很贴近实际情况的,其他的数据库或多或少都有问题。
全角/半角对查询的影响:
我们期望的效果:当使用
like查询或=比较符时,数据库能忽略掉全角“a”和 半角"a",将它们判定相等。
sqlserver不负众望,默认情况下的比较是忽略全角/半角的,所以,sqlserver能做到判定它们相等。
看如下实验:
create table test(
id int identity(1,1),
name varchar(50)
);
insert into test values
('角a啊'),--全角a
('角a啊');--半角a
--测试like中的全角半角处理
select * from test where name like '%a%';--半角a
select * from test where name like '%a%';--全角a
--测试=中的全角半角处理
select * from test where name = '角a啊';--半角a
select * from test where name = '角a啊';--全角a
上面的查询结果均显示:
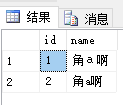
大小写对查询的影响:
我们期望的效果:当使用
like查询或=比较符时,数据库能忽略掉大写和小写的区别,将它们判定相等。
sqlserver不负众望,默认情况下的比较是忽略大小写的,所以,sqlserver能做到判定它们相等。
看如下实验:
create table test(
id int identity(1,1),
name varchar(50)
)
insert into test values
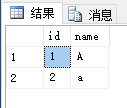
('A'),('a');
select * from test where name like 'A';
select * from test where name like 'a';
select * from test where name = 'A';
select * from test where name = 'a';
上面的查询结果均显示:
四、sqlserver究竟会以何种编码存储字符
上面只说了sqlserver中的默认排序规则:Chinese_PRC_CI_AS,但是sqlserver中究竟是以哪种编码规则存储的呢?
具体用什么编码规则存储不仅受排序规则的影响,还受数据类型的影响(nvarchar、varchar)。
以Chinese_PRC_CI_AS排序规则为例:
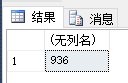
当我们使用varchar类型时,存储到表里面的数据其实就是GBK编码,因为:Chinese_PRC对应的是区域编码(ANSI,活动代码页:936)是GBK。可以通过sql查询得知:
SELECT COLLATIONPROPERTY('Chinese_PRC_CI_AS', 'CodePage')
当我们使用nvarchar类型时,存储到表里面的是UTF-16的编码。
验证不同数据类型对应的编码规则:
首先,我们数据库的排序规则是:Chinese_PRC_CI_AS,已知 汉字“王”的各种格式编码如下:

参考:《细说ASCII、GB2312/GBK/GB18030、Unicode、UTF-8/UTF-16/UTF-32编码》
准备数据:
create table test(
name varchar(50),
nname nvarchar(50)
)
insert into test values('王','王')
select
name,nname,
convert (varbinary (20) , name) as name_binary,
convert (varbinary (20) , nname) as nname_binary
from test
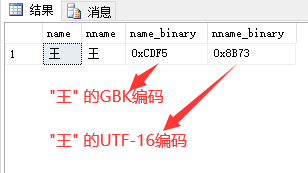
由此,可以看出,数据表中存储使用的字符编码和排序规则和数据类型都有关系。
五、sqlserver中数据类型varchar和nvarchar的区别、N’'的作用
其实从上面的实验中可以看得出来,对于Chinese_PRC_CI_AS排序规则来说:
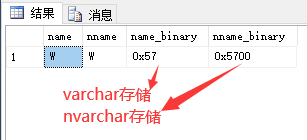
我们知道,UTF-16编码规则最少使用2个字节存储字符,即使对于英文字母“W”也要使用两个字节,而GBK编码则可以使用1个字节存储英文字母“W”,所有当只有英文字母时,varchar显然要节省空间。
下面是存储英文字母“W”的示例:
create table test(
name varchar(50),
nname nvarchar(50)
)
insert into test values('W','W')
select
name,nname,
convert (varbinary (20) , name) as name_binary,
convert (varbinary (20) , nname) as nname_binary
from test
nvarchar(8000)和varchar(8000) 中的8000指的是字节数,而不是字符数,GBK中一个字符可以是1个字节或两个字节,UTF-16中一个字符则是2个或4个字节,所以在计算最多存储多少文字时不要搞错了。
N’小明’ 的作用:
这个大N表示单引号中的字符串使用的是Unicode编码,当我们sqlserver引擎会用Unicode的方式去解析"小明",而不是用GBK编码的方式。
一般来说,我们感觉不到加不加大N的区别,那是因为我们存储的数据都在Unicode的常见字符区域内,如果我们存储一个emoji表情,那么加不加大N的就立马看得出来了,看如下的实验:
create table test(
name varchar(50),
nname nvarchar(50)
)
insert into test values('王','王')
insert into test values(N'王',N'王')
insert into test values('W','W')
insert into test values(N'W',N'W')
insert into test values('😀','😀')
insert into test values(N'😀',N'😀')
select
name,nname,
convert (varbinary (20) , name) as name_binary,
convert (varbinary (20) , nname) as nname_binary
from test
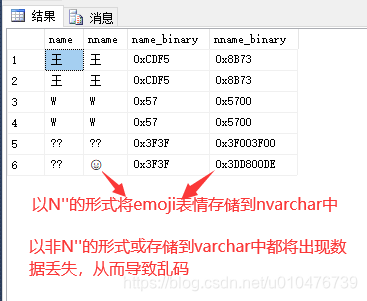
到底该如何选用nvarchar和varchar?用不用以N’'形式编写sql?
如果你的数据中不需要保存中英文以外的字符(如:emoji表情字符),那么你可以忽略nvarchar和N’’,如果你的数据库中需要保存其他特殊字符(如:emoji表情字符),那么你就必须使用nvarchar数据类型,并且以N’'形式编写sql语句。
六、关于nvarchar(10)个varchar(10)的最多能存多少个字符
首先,要明白字符和字节不是一个概念。英文字母“a”、汉字“啊”、emoji表情“😀”都称之为一个字符,但使用不同的字符集编码的时候他们可能占用不同的字节。
- 英文字母“a”在GBK下占1个字节、在UTF-16下占2个字节、在UTF-8下占用1个字节;
- 汉字“啊”在GBK下和UTF-16下都占2个字节、在UTF-8下占三个字节;
- emoji表情“😀”在UTF-16和UTF-8下都占4个字节,在GBK下无对应编码;
在sqlserver2012以上的Chinese_PRC_CI_AS排序规则下,nvarchar使用UTF-16编码,varchar使用ANSI编码(如果电脑的区域设置为中文的话,就是GBK编码,在中国可认为就是GBK编码)。
-
对于nvarchar(10)来说,这一列将最多使用
10*2个字节来存储数据。又因为使用UTF-16来编码数据,所以最多存储10个英文字母或汉字,这看起来capcity就像是字符数量一样(但实际不是)。如果你存储的只有英文字符和汉字的话,这么认为也没有错,但如果你要存储emoji表情的话(UTF-16下占4个字节),那么capcity可就不能这么认为了。一会看下面的实验; -
对于varchar(10)来说。这一列将最多使用
10个字节来存储数据。又因为使用GBK(在中国这么认为)编码,所以最多存储10个英文字母或10/2个汉字。注意:emoji表情存不进去哦(GBK中没有emoji,存进去就是乱码)。 -
另外,应该微软有意限制varchar或nvarchar占用的字节数,所以规定
nvarchar(capcity)的capcity最大值为4000,varchar(capcity)的capcity的最大值为8000。当然,如果你用nvarchar(max)或varchar(max)就基本上可以忽略大小限制了,因为它们最大可占用2G。
关于nvarchar和varchar的容量实验:
-- sqlserver2014
-- 排序规则: Chinese_PRC_CI_AS
--drop table t
create table t(
name nvarchar(10),
name2 varchar(10)
)
-- name: 最多存储10*2=20个字节,对于英文字母和汉字(utf16编码下都是两个字节)来说就是10个字符
-- name2 最多存储10个字节,用GBK编码,英文字母一个字节,汉字两个字节,最多存储10个英文字母和5个汉字
insert into t(name) values('1234567890') --正常
insert into t(name) values('一二三四五六七八九十') --正常
insert into t(name) values('123456789😀') -- 截断
insert into t(name2) values('一二三四五') --正常
insert into t(name2) values('1234567890') --正常
insert into t(name2) values('一二三四五1') --截断

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 19
19 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)