YOLOv5训练自己的数据集(超详细完整版)
向AI转型的程序员都关注了这个号????????????机器学习AI算法工程 公众号:datayx一.Requirements本教程所用环境:代码版本V3.0,源码下载地址:https://github...

向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
一.Requirements
本教程所用环境:代码版本V3.0,源码下载地址:https://github.com/ultralytics/yolov5.git
Pytorch:1.6.0
Cuda:10.1
Python:3.7
官方要求Python>=3.8 and PyTorch>=1.6.
通过git clone https://github.com/ultralytics/yolov5.git将YOLOv5源码下载到本地,创建好虚拟环境,并通过pip install -r requirements.txt安装依赖包。
二. 准备自己的数据集(VOC格式)
1.在yolov5目录下创建paper_data文件夹(名字可以自定义),目录结构如下,将之前labelImg标注好的xml文件和图片放到对应目录下
paper_data
…images # 存放图片
…Annotations # 存放图片对应的xml文件
…ImageSets/Main #之后会在Main文件夹内自动生成train.txt,val.txt,test.txt和trainval.txt四个文件,存放训练集、验证集、测试集图片的名字(无后缀.jpg)
示例如下:
paper_data文件夹下内容如下:
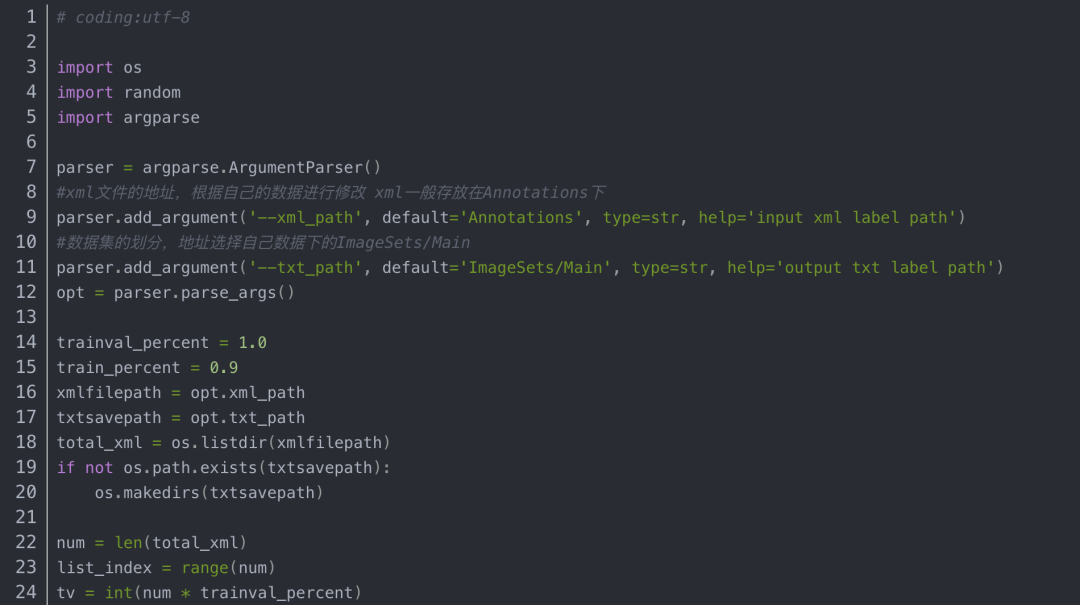
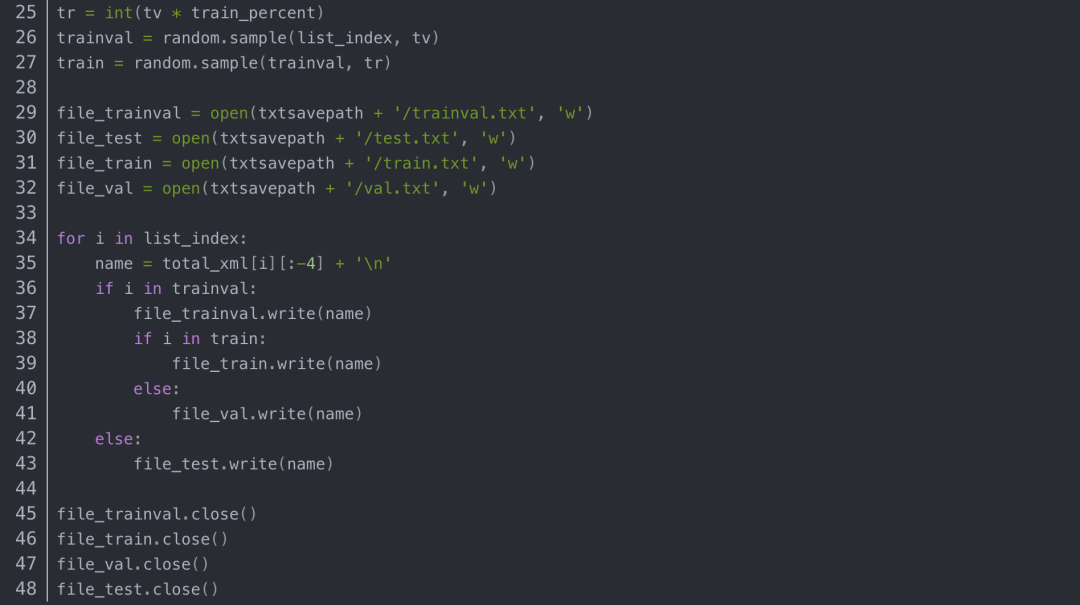
ImageSets文件夹下面有个Main子文件夹,其下面存放训练集、验证集、测试集的划分,通过脚本生成,可以创建一个split_train_val.py文件,代码内容如下:
运行代码后,在Main文件夹下生成下面四个txt文档:
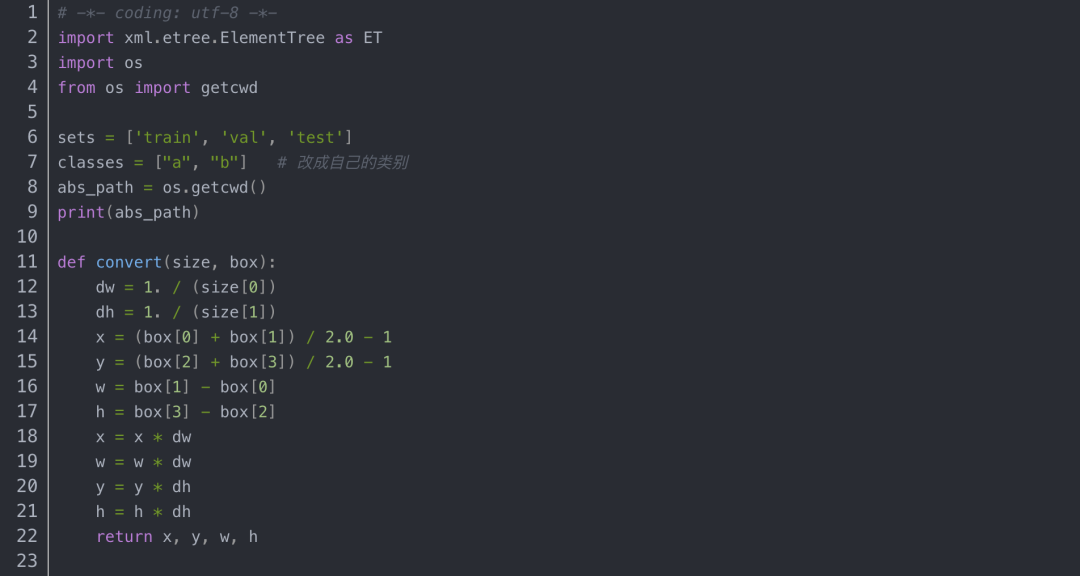
2.接下来准备labels,把数据集格式转换成yolo_txt格式,即将每个xml标注提取bbox信息为txt格式(这种数据集格式成为yolo_txt格式),每个图像对应一个txt文件,文件每一行为一个目标的信息,包括class, x_center, y_center, width, height格式。格式如下:

创建voc_label.py文件,将训练集、验证集、测试集生成label标签(训练中要用到),同时将数据集路径导入txt文件中,代码内容如下:
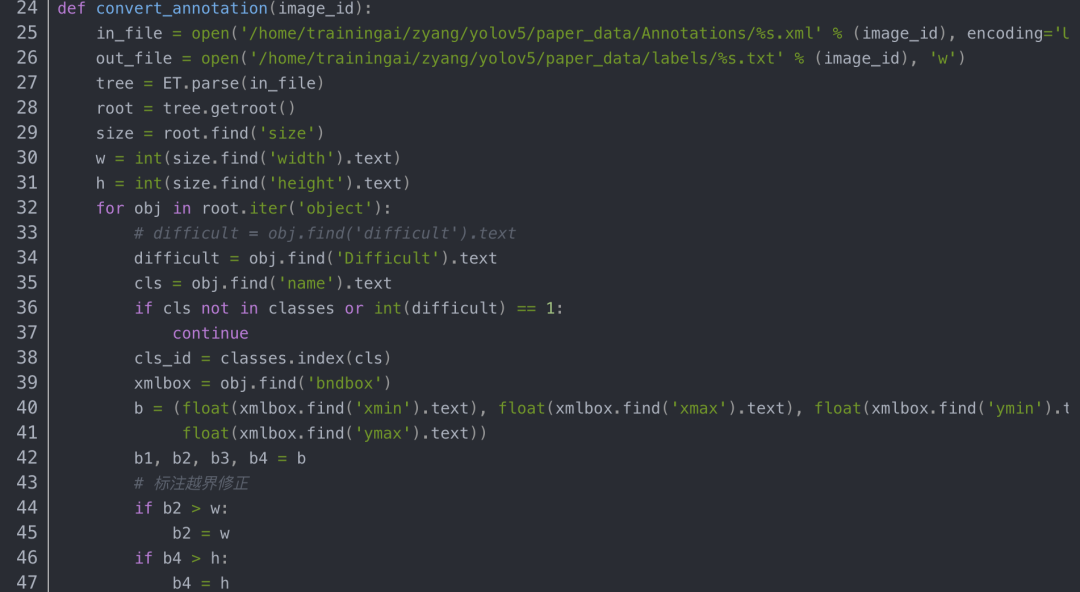
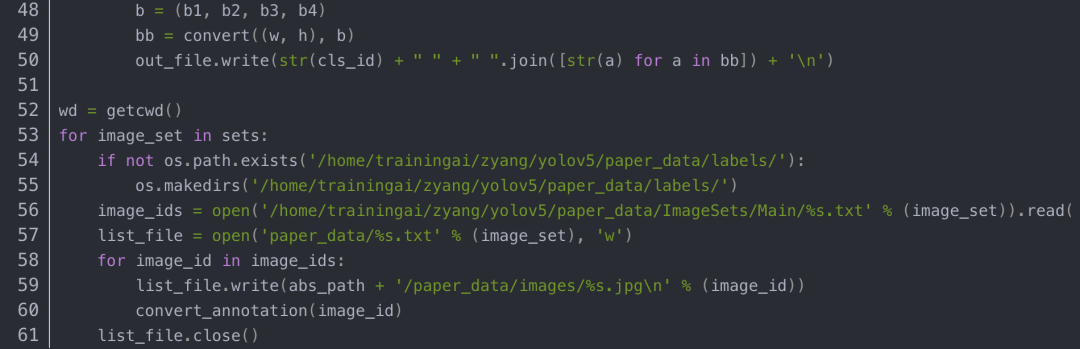
运行后会生成如下labels文件夹和三个包含数据集的txt文件,其中labels中为不同图像的标注文件,train.txt等txt文件为划分后图像所在位置的绝对路径,如train.txt就含有所有训练集图像的绝对路径。
运行voc_label.py时报错“ZeroDivisionError: float division by zero”的原因是:标注文件中存在width为0或者height为0的数据,检查修改后可解决。

.配置文件
1)数据集的配置
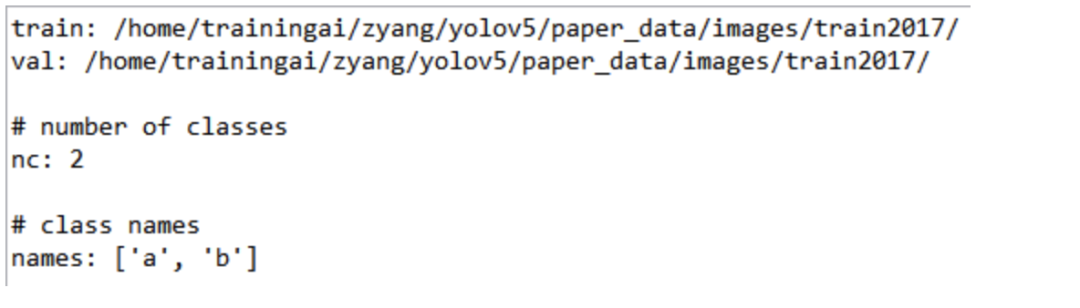
在yolov5目录下的data文件夹下新建一个ab.yaml文件(可以自定义命名),用来存放训练集和验证集的划分文件(train.txt和val.txt),这两个文件是通过运行voc_label.py代码生成的,然后是目标的类别数目和具体类别列表,ab.yaml内容如下:

疑问:ab.yaml文件中train和val通过train.txt和val.txt指定,我在训练时报错(别人没有报错,很费解!评论中有人遇到一样的报错,给出解决方法是:发现冒号后面需要加空格,否则会被认为是字符串而不是字典,可以试一下),于是我参照官网上data/coco128.yaml的形式指定train和val,内容如下:
2)编辑模型的配置文件
2-1) 聚类得出先验框(可选)(聚类重新生成anchors运行时间较长)
最新版的yolov5,它会自动kmeans算出anchors
如下图所示:

kmeans.py代码内容如下:
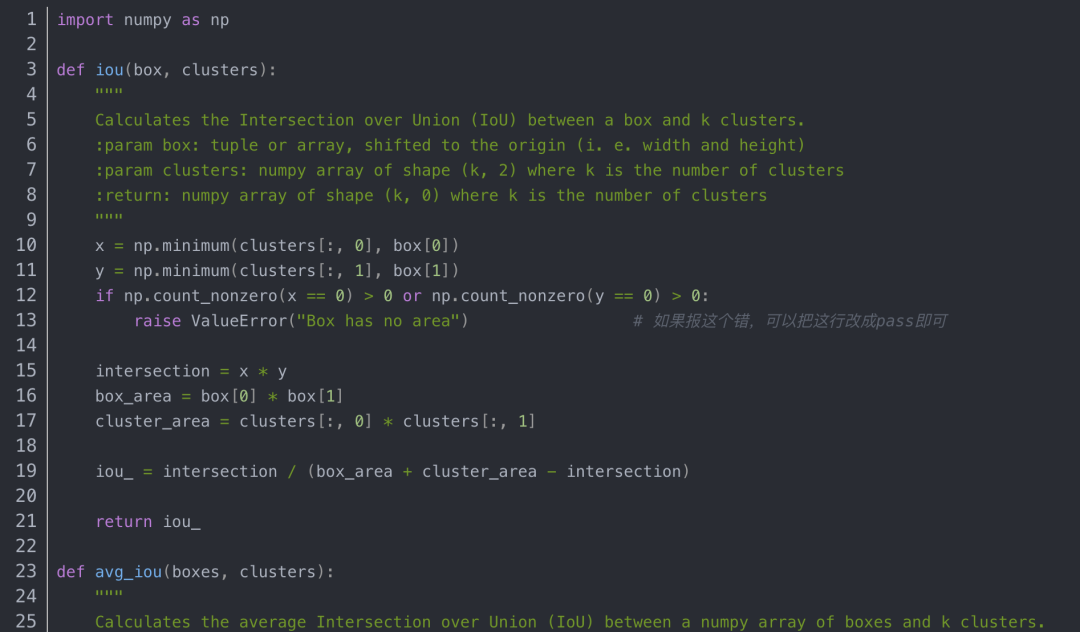
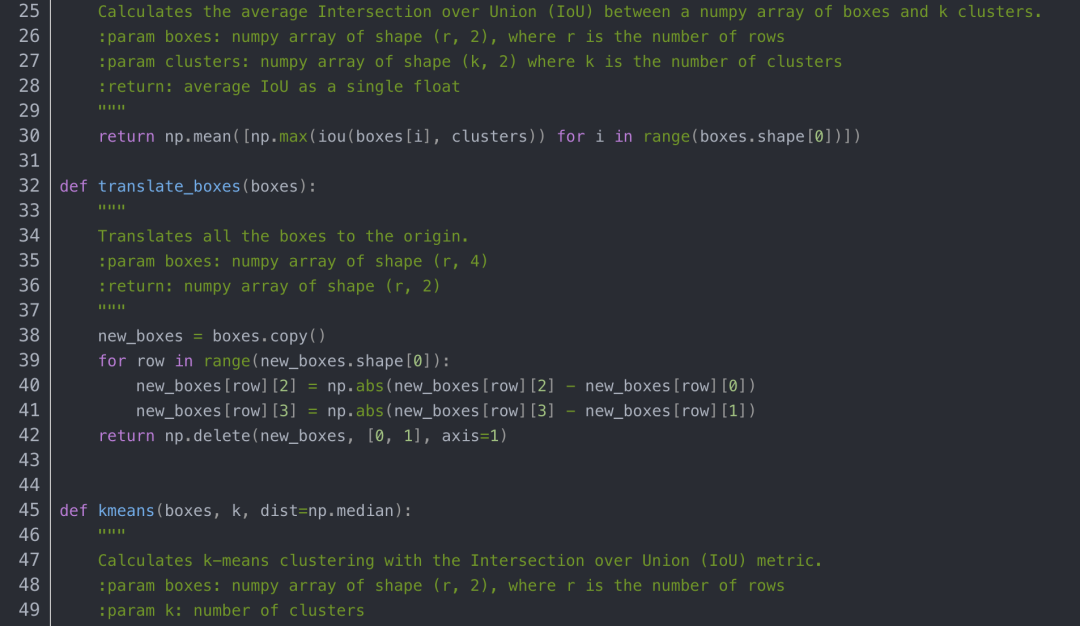
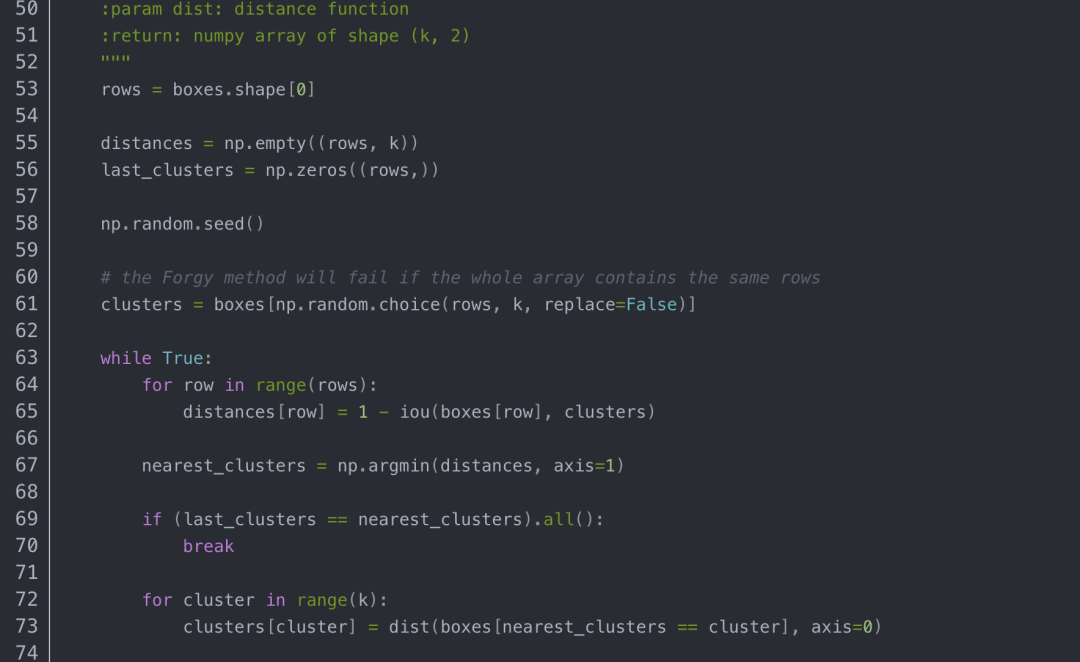

聚类生成新anchors的文件clauculate_anchors.py
clauculate_anchors.py 内要修改为自己数据集的路径,如下:

运行clauculate_anchors.py跑完会生成一个文件 anchors.txt,里面有得出的建议先验框anchors,内容如下:

PS: 如果自己动手生成anchors时候报错“ raise ValueError(“Box has no area”)”,可能是标注数据中有的目标物很小很小,可以把kmeans.py中第13行注释掉,改成pass即可解决这个报错。
2-2) 选择一个你需要的模型
在yolov5目录下的model文件夹下是模型的配置文件,这边提供s、m、l、x版本,逐渐增大(随着架构的增大,训练时间也是逐渐增大),假设采用yolov5s.yaml,只用修改一个参数,把nc改成自己的类别数;如果anchors是重新生成的,也需要修改,根据anchors.txt 中的 Best Anchors 修改,需要取整(可选) 如下:
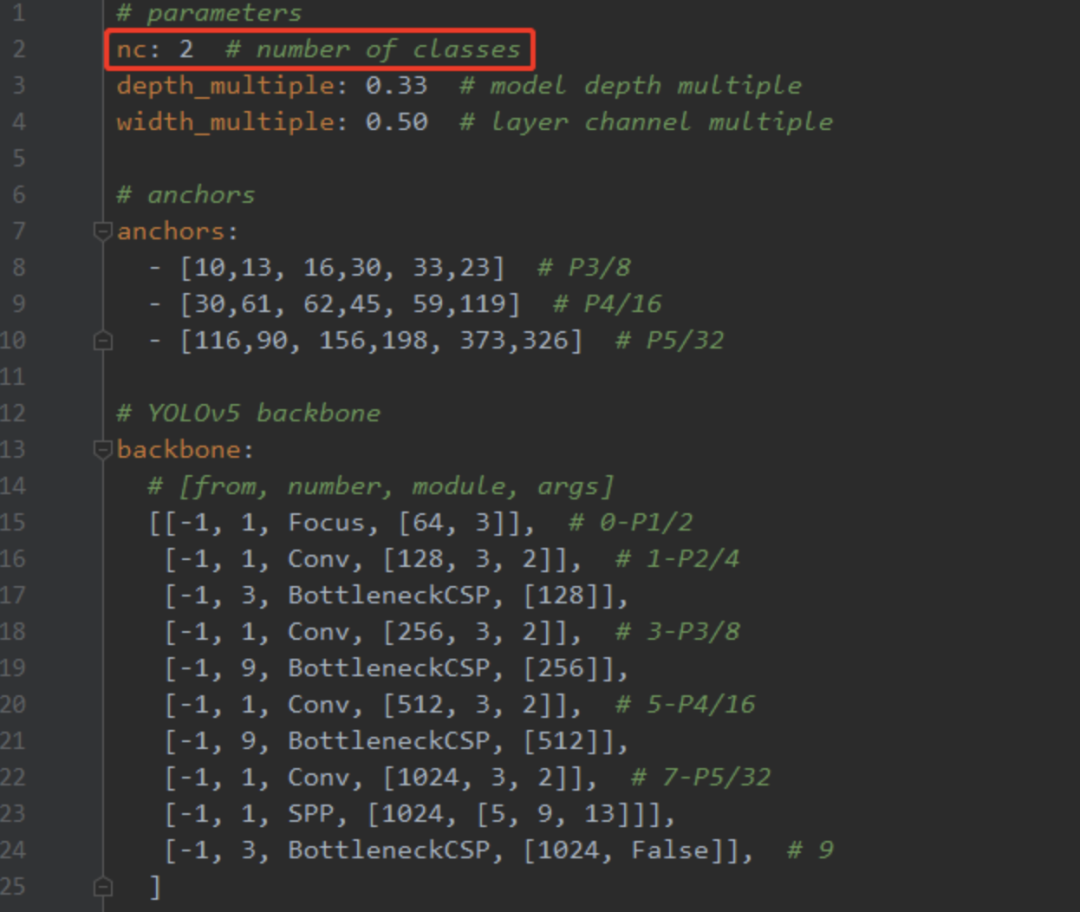
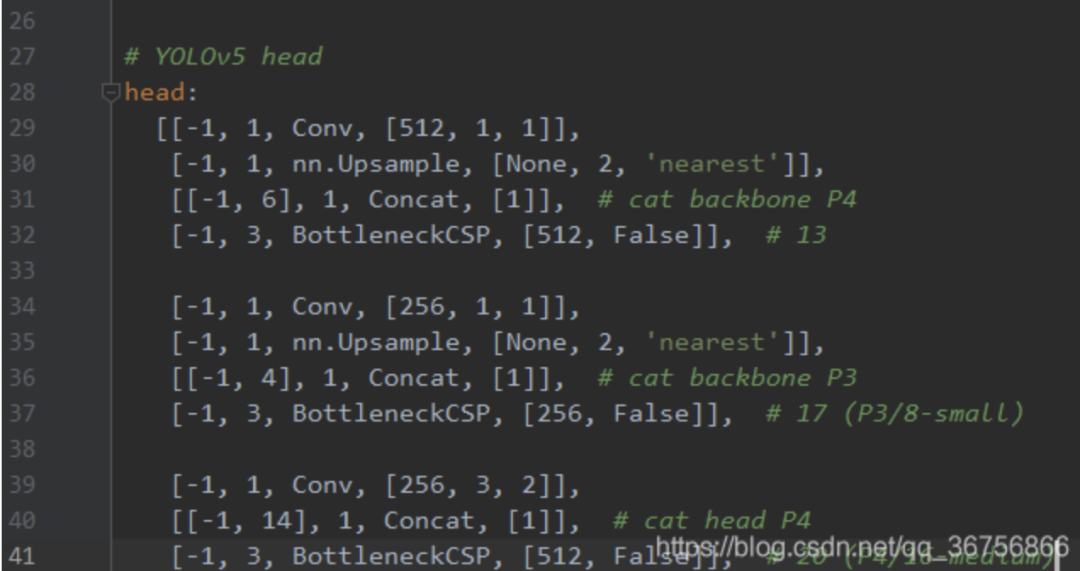
至此,自定义数据集已创建完毕,接下来就是训练模型了。
三.模型训练
1.下载预训练模型
源码中在yolov5目录下的weights文件夹下提供了下载四种预训练模型的脚本----download_weights.sh
执行这个shell脚本就可以下载,这里weights的下载可能因为网络而难以进行,有人分享了百度网盘的下载地址,但是不一定是v3.0版本最新的预训练模型,如果不是v3.0版本最新的预训练模型,在训练时会报错如下:
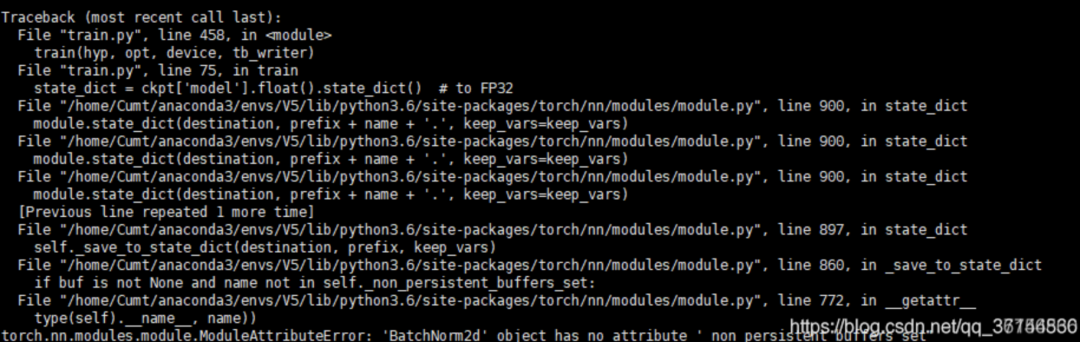
出现这个问题原因是预训练模型下载的不是最新的,例如V3.0的代码,下载的是V2.0或者V1.0的模型权重就会报错,重新下载最新的模型权重即可解决。我是通过官网源码给的链接翻墙在google云盘上下载的。
2.训练
在train.py进行以下几个修改:
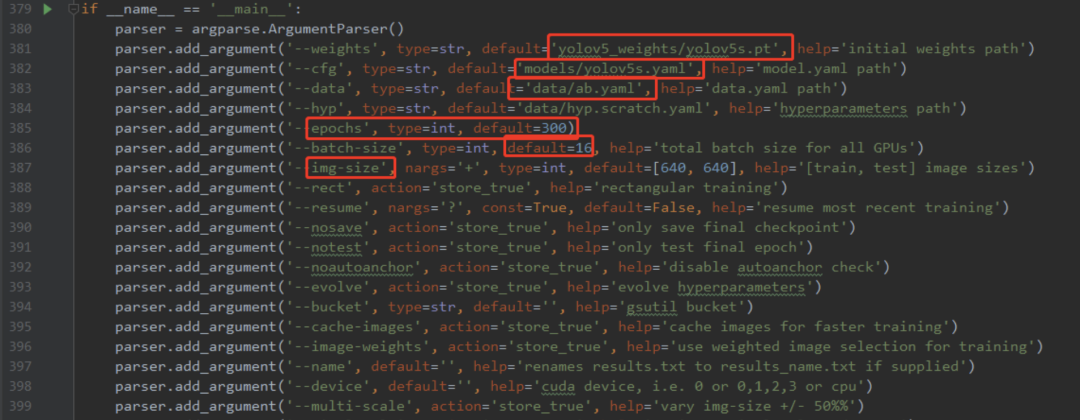
以上参数解释如下:
epochs:指的就是训练过程中整个数据集将被迭代多少次,显卡不行你就调小点。
batch-size:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点。
cfg:存储模型结构的配置文件
data:存储训练、测试数据的文件
img-size:输入图片宽高,显卡不行你就调小点。
rect:进行矩形训练
resume:恢复最近保存的模型开始训练
nosave:仅保存最终checkpoint
notest:仅测试最后的epoch
evolve:进化超参数
bucket:gsutil bucket
cache-images:缓存图像以加快训练速度
weights:权重文件路径
name:重命名results.txt to results_name.txt
device:cuda device, i.e. 0 or 0,1,2,3 or cpu
adam:使用adam优化
multi-scale:多尺度训练,img-size +/- 50%
single-cls:单类别的训练集
之后运行训练命令如下:
python train.py --img 640 --batch 16 --epoch 300 --data data/ab.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --device '0' # 0号GPU
根据自己的硬件配置修改参数,训练好的模型会被保存在yolov5目录下的runs/exp0/weights/last.pt和best.pt,详细训练数据保存在runs/exp0/results.txt文件中。
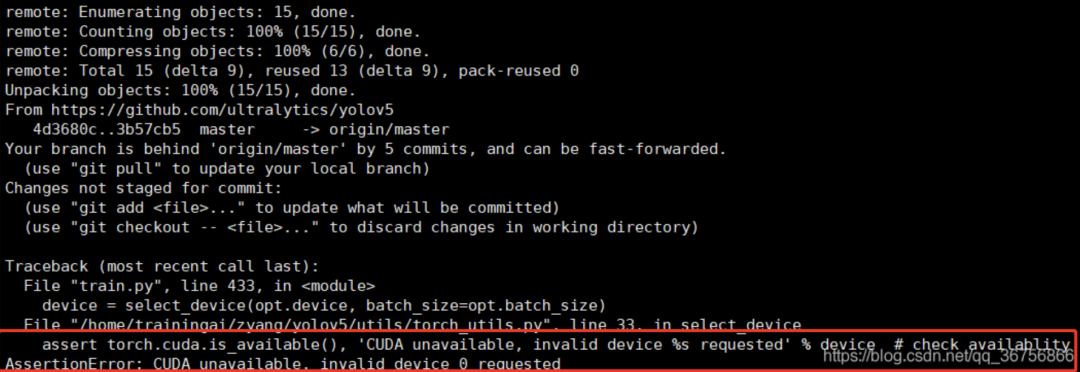
如果Cuda版本不对(不是>=10.1版本),在调用GPU训练时会报错如下:
3.训练过程可视化
利用tensorboard可视化训练过程,训练开始会在yolov5目录生成一个runs文件夹,利用tensorboard打开即可查看训练日志,命令如下:
tensorboard --logdir=runs
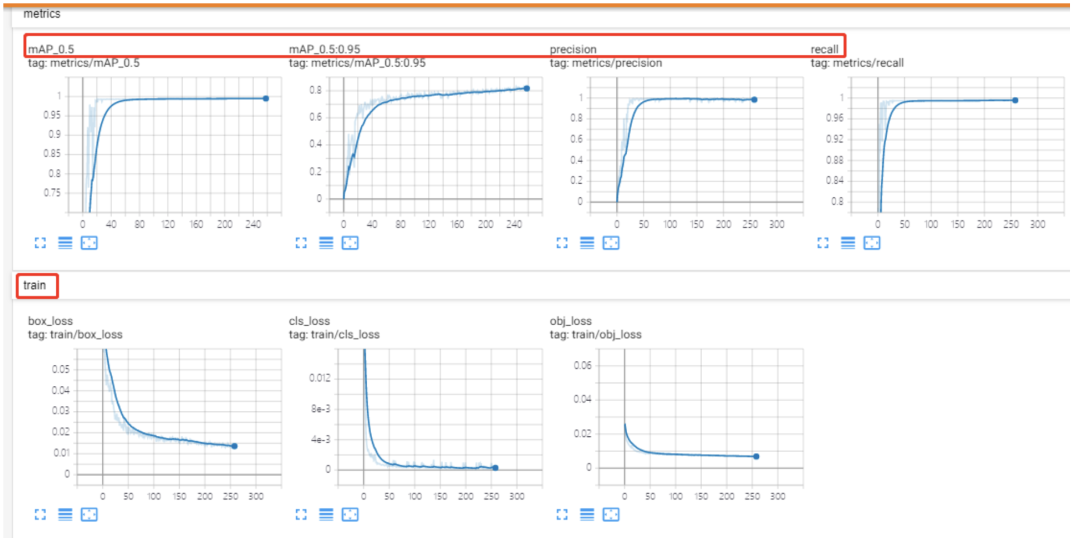
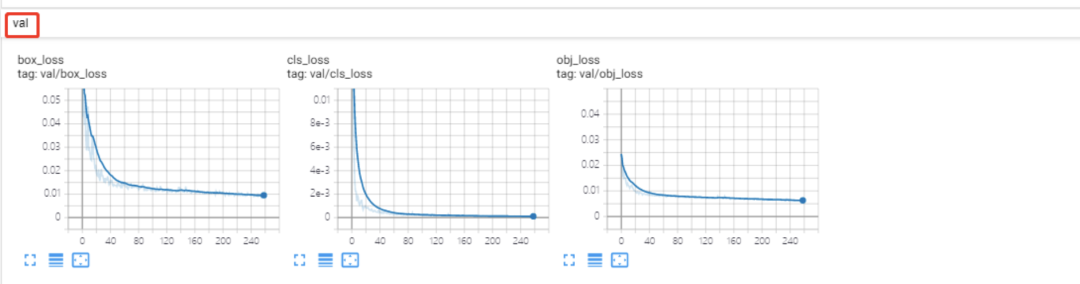
由于TensorFlow2.0及以上版本现在支持CUDA10.0,还不支持CUDA10.1,因此我在使用TensorFlow2.0以上版本利用tensorboard打开训练日志时报错如下:

于是我改用tensorflow-gpu1.13.1版本的环境,利用tensorboard即可成功打开并查看训练日志,可视化结果如上图。
至此YOLOv5训练自己的数据集,训练阶段已完毕。
YOLOv5训练速度更快,准确率更高,个人感觉最大的优势是相比YOLOv3,YOLOv5的模型更加轻量级,同样的数据集训练出来的模型大小是YOLOv3的将近四分之一大小。
四.模型测试
评估模型好坏就是在有标注的测试集或者验证集上进行模型效果的评估,在目标检测中最常使用的评估指标为mAP。在test.py文件中指定数据集配置文件和训练结果模型,如下:
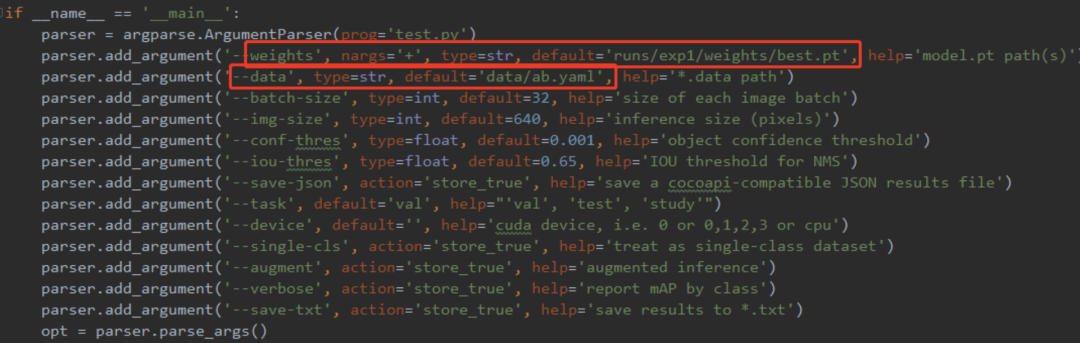
通过下面的命令进行模型测试:
python test.py --data data/ab.yaml --weights runs/exp1/weights/best.pt --augment
模型测试效果如下:

五.模型推理
最后,模型在没有标注的数据集上进行推理,在detect.py文件中指定测试图片和测试模型的路径,其他参数(img_size、置信度object confidence threshold、IOU threshold for NMS)可自行修改,如下:
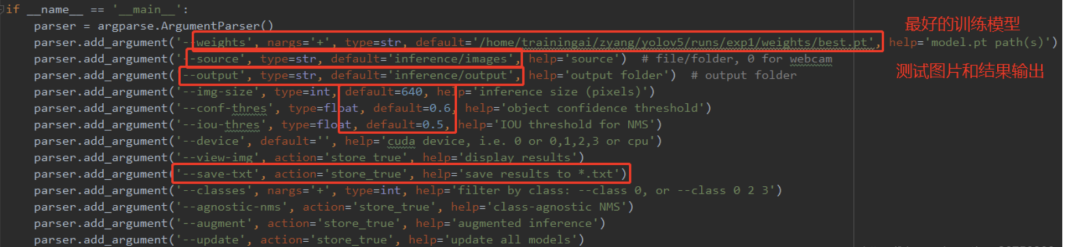
使用下面的命令(该命令中save_txt选项用于生成结果的txt标注文件,不指定则只会生成结果图像),其中,weights使用最满意的训练模型即可,source则提供一个包含所有测试图片的文件夹路径即可。
python detect.py --weights runs/exp1/weights/best.pt --source inference/images/ --device 0 --save-txt
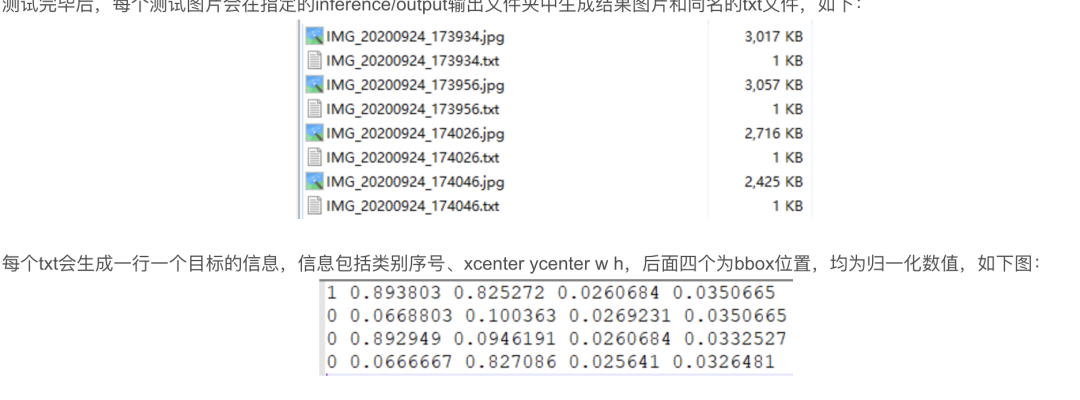
在进行模型推理时,无论是加载模型的速度还是对测试图片的推理速度,都能明显感觉到YOLOv5比YOLOv3速度快,尤其是加载模型的速度,因为同样的数据集训练出来的模型YOLOv5更加轻量级,模型大小减小为YOLOv3的将近四分之一。
至此YOLOv5训练自己的数据集整个过程:制作数据集----模型训练----模型测试----模型推理阶段已全部完成。
原文地址
https://blog.csdn.net/qq_36756866/article/details/109111065
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx


为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 27
27 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)