mysql字符集编码和排序规则
环境:mysql 5.7 26DBeaver 21.1.2.202107041908参考:《MySQL字符集与排序规则总结》一、说说字符集、字符集编码和排序规则字符集:罗列所有图形字符的一张大表。比如:GBK字符集(中国制造): 罗列了所有的中文简体、繁体字的一张大表。Unicode字符集(全世界通用):罗列了世界上所有图形字符的一张大小表。字符集编码:将字符集上罗列的图形字符存储到计算机中的一种
环境:
- mysql 5.7 26
- DBeaver 21.1.2.202107041908
参考:《MySQL字符集与排序规则总结》
建议先阅读:《细说ASCII、GB2312/GBK/GB18030、Unicode、UTF-8/UTF-16/UTF-32编码》
先说下结论:
- 如果你想在数据库中存储emoji表情等特殊字符,就需要设置数据库的字符集编码为
utf8mb4,排序规则为utf8mb4_general_ci,并且连接字符串中也需要指定utf8mb4(对于nuget: MySqlConnector来说,默认就是utf8mb4,无须显示指定);- utf8mb4_general_ci是忽略大/小写的差别,所以不用担心因为大小写搜索不到数据的问题;
- utf8mb4_general_ci是不能忽略全半角差别的,所以可能因为全半角的原因导致搜索不到数据。
一、说说字符集、字符集编码和排序规则
- 字符集:罗列所有图形字符的一张大表。
比如:
- GBK字符集(中国制造): 罗列了所有的中文简体、繁体字的一张大表。
- Unicode字符集(全世界通用):罗列了世界上所有图形字符的一张大表。
- 字符集编码:将字符集上罗列的图形字符存储到计算机中的一种编码规则。
比如:
- 排序规则:定义各个图形字符之间的大小比较规则,比如:是否区分大小写,区分全角和半角等。
在软件使用中,一般我们只指定字符编码即可,因为确定了字符编码字符集自然就确定了。
但是在数据库类软件中,我们除了要指定编码规则,还需要指定排序规则,因为,数据库是要提供模糊匹配、排序显示功能的。
二、mysql中的字符集编码和排序规则
mysql共支持40多种字符集编码和200多个排序规则。
sqlserver中将字符集编码和排序规则合在一起了,指定了排序规则也就基本上确定了字符集编码(为什么说是基本上,因为sqlserver中还有nvarchar和varchar的区别,详见:《sqlserver中的字符编码、排序规则、nvarchar和varchar、大N‘‘》)
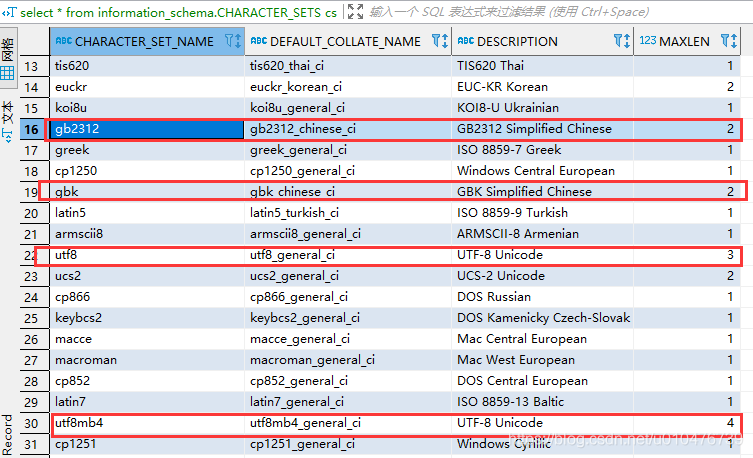
如下sql可以查看mysql支持的字符集编码和排序规则,其中每个字符集编码都有一个默认的排序规则:
-- 查看所有的字符集编码和对应的默认排序规则
select * from information_schema.CHARACTER_SETS cs ;
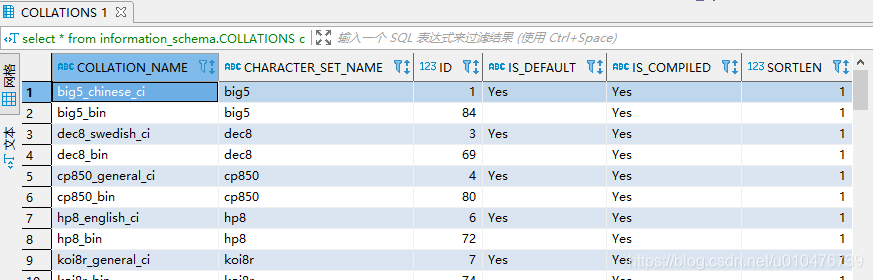
-- 查看所有的排序规则
select * from information_schema.COLLATIONS c
注意:
mysql中的utf8并不是真正的UTF-8编码,utf8mb4才是真正的UTF-8编码,我们在建数据库的时候记得使用utf8mb4而不是utf8。
三、mysql中字符集编码设置的级别
mysql中共有4种级别的字符集编码的设置:Mysql Server级别、 数据库级别、表级别、列级别。
- 如果新建数据库时未指定字符集编码则使用Mysql Server级别的设置。
-- 创建数据库时指定字符集编码和排序规则 CREATE DATABASE test2 CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; - 如果新建表时未指定字符集编码则使用数据库级别的设置;
-- 创建表时指定字符集编码和排序规则 create table tt2( addr varchar(50) ) character set utf8mb4 collate utf8mb4_general_ci; - 如果新建列时未指定字符集编码则使用表级别的设置;
-- 创建表时指定某个列的字符集编码和排序规则 create table tt4( name varchar(50) character set utf16 collate utf16_general_ci, addr varchar(50) )character set utf8mb4 collate utf8mb4_general_ci;
查看当前数据库的字符集编码和排序规则:
select SCHEMA_NAME,DEFAULT_CHARACTER_SET_NAME,DEFAULT_COLLATION_NAME
from information_schema.SCHEMATA s
where SCHEMA_NAME ='test2';

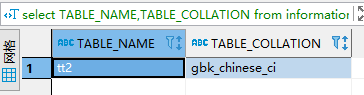
查看指定表的字符集编码和排序规则:
select TABLE_NAME,TABLE_COLLATION
from information_schema.TABLES t
where TABLE_SCHEMA ='test2' and TABLE_NAME ='tt2';
查看指定列的字符集编码和排序规则:
select c.TABLE_NAME,c.COLUMN_NAME,c.CHARACTER_SET_NAME,c.COLLATION_NAME
from information_schema.`COLUMNS` c
where c.TABLE_SCHEMA ='test2' and c.TABLE_NAME ='tt2'

四、mysql中会话环境的字符集编码设置
上面虽然讲了可以给mysql的数据库级别、表级别、甚至列级别设置字符集编码,但如果平时不注意,仍然会出现乱码的情况!
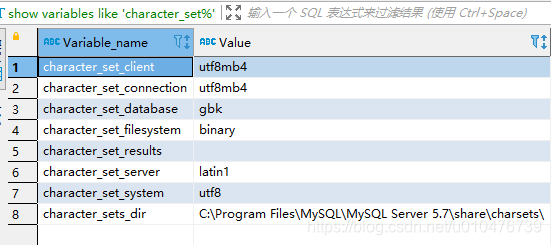
首先看一个mysql连接回话中出现的编码设置:
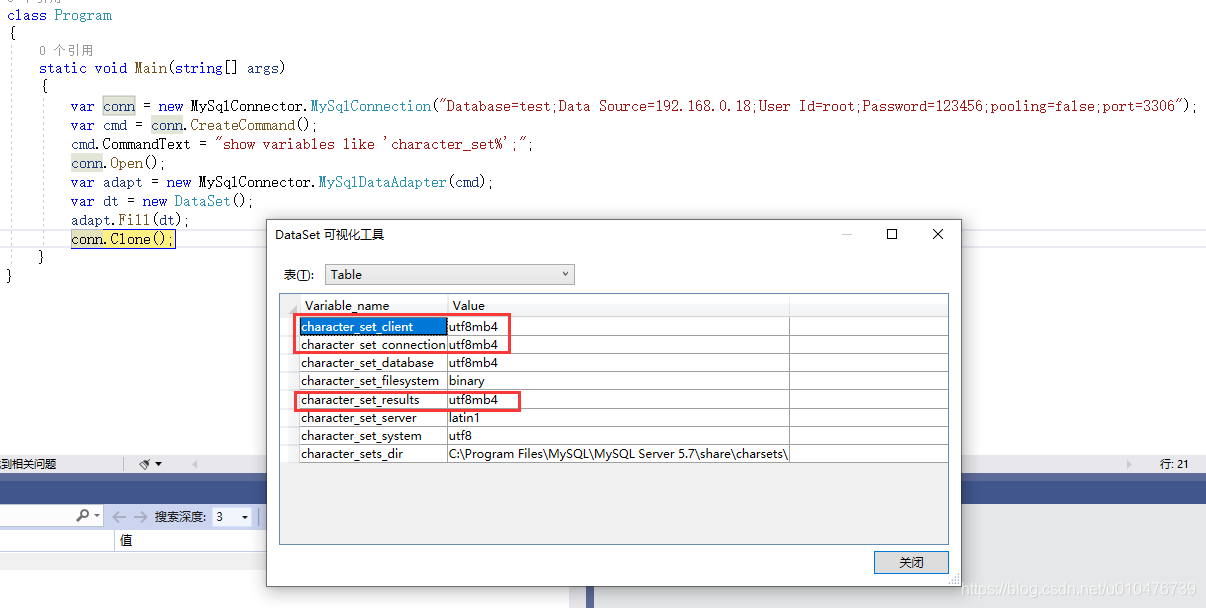
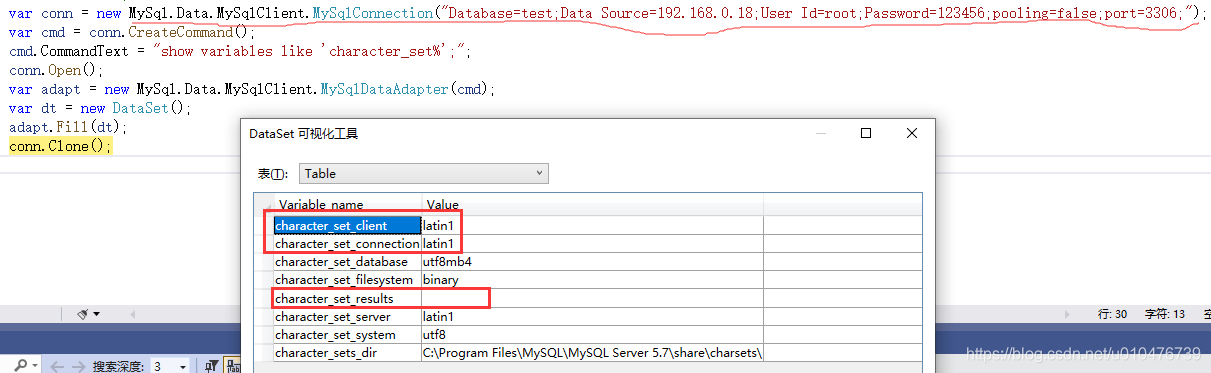
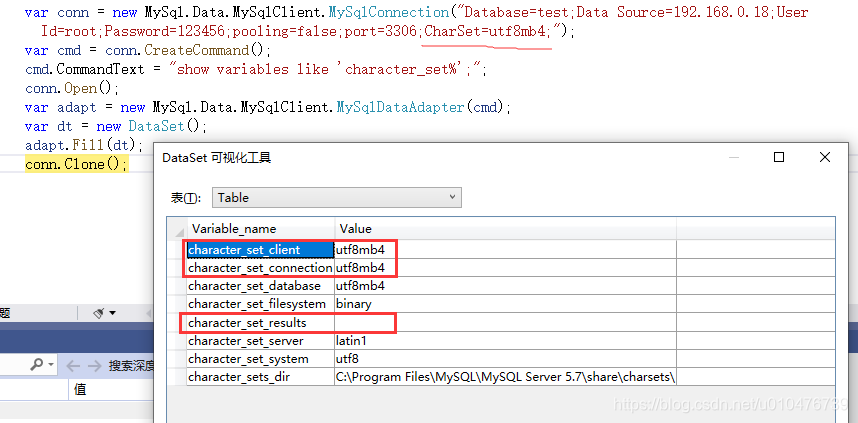
show variables like 'character_set%';
解释一下上面变量的意思:
character_set_client、character_set_connection、character_set_results是一个mysql连接后mysql客户端和mysql服务器协商的编码规则。character_set_client表名客户端使用何种字符集编码序列化文本字符,character_set_connection一般和character_set_client保持一致即可(受SELECT _utf8'abc'形式语句的影响,参见:《10.3.8 Character Set Introducers》),character_set_results表示服务端应该以何种编码返回文本。
character_set_database表示当前连接操作的数据库的字符集编码。
character_set_server表示mysql服务端的默认字符集编码。
character_set_system表示mysql存储元数据时使用的编码,固定为:utf8。
character_set_filesystem表示涉及到文件操作的时的编码,如:LOAD DATA INFILE和SELECT ... INTO OUTFILE语句和LOAD_FILE()函数中
对于我们程序员来说,新建数据库时选择字符集编码为utf8mb4,排序规则为utf8mb4_general_ci即可。
另外,如果你发现乱码的话,可以查看自己客户端声明的编码是多少,在c#中默认为utf8mb4(
nuget: MySqlConnector),如:
注意:在MySqlConnector驱动包中,默认就是utf8mb4并且不能修改,如果你用的是Mysql.Data,那么你需要注意了,因为它默认的是latin1,如下:
此时,为了避免乱码,你就需要手动指定编码为utf8mb4,如下:
五、 可以存储emoji表情吗?
emoji表情属于Unicode后面的字符集,使用标准utf8编码是可以存储的(在mysql中是utf8mb4)。
只要我们保证,数据库(表、列)使用utf8mb4字符集编码,且客户端可Mysql服务端的连接使用的也是utf8mb4字符集编码,那么就可以愉快的存储emoji表情了。
六、mysql中的排序规则
mysql中的排序规则支持忽略大小写(如:utf8mb4_general_ci),但不支持忽略全角和半角。
顺便说下:
sqlserver在排序规则上的功能就要强大的多,它不仅支持忽略大小写,还支持忽略全半角、假名(日语相关)、重音等。如下:
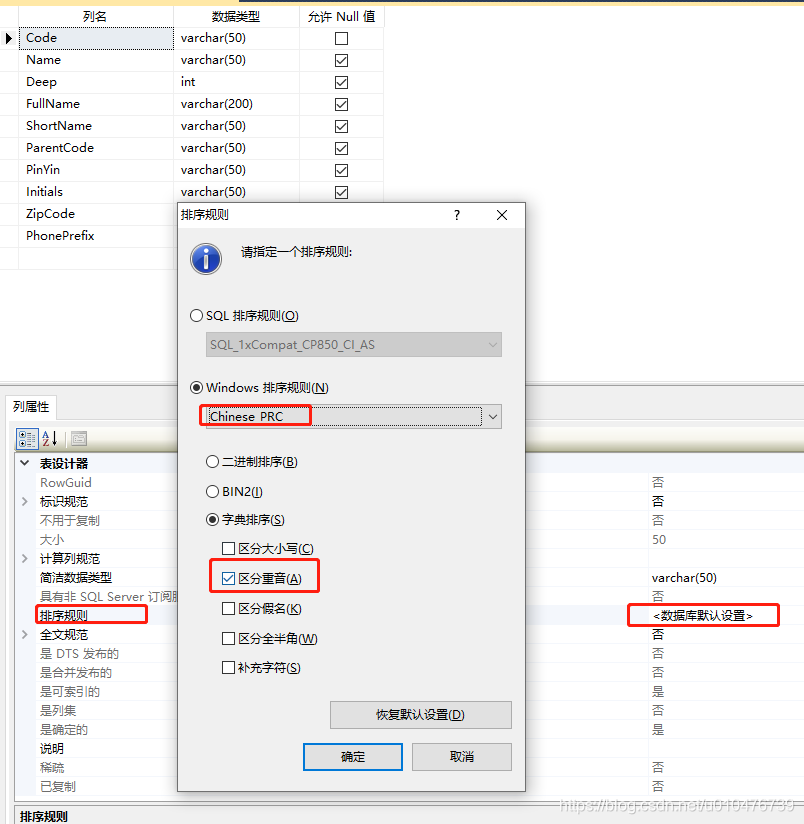
以排序规则utf8mb4_general_ci为例说明:
-
mysql中的排序规则
支持忽略大小写,即可以将大写“A”和小写“a”判定为相等没区别。这在模糊匹配的精确查询时非常重要,如果mysql不支持忽略大小写的话,那么程序就可能会出现莫名的bug(数据库存的是A,用户属于a怎么也搜索不出来)。在postgresql和sqlite中就有这种问题。
看下面的示例代码:
create table tt( name varchar(50) ); insert into tt values('ali'),('Ali'); -- like查询中忽略了A和a的区别 select * from tt where name like '%a%'; -- 精确匹配中也忽略了A和a的区别 select * from tt where name ='ali'; -
mysql中的排序规则
不支持忽略全半角,即“a”和“a”是不同的,前者是英文字母a,后者是中文的a,这就造成:如果数据中输入的是全角a,而用户使用半角a去搜索的话是搜索不到数据的,看如下代码:create table tt( name varchar(50) ); insert into tt values('aother'),('aother'); -- 下面like匹配和“=”均只能检索到一条数据,即:不能忽略掉全半角的区别 select * from tt where name like '%a%'; select * from tt where name like '%a%'; select * from tt where name ='aother'; select * from tt where name ='aother';
七、mysql更改编码和排序规则
参照:
更改数据库级别的编码规则:
-- 数据库级别
ALTER DATABASE testdb CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci
-- 更改表的编码级别
ALTER TABLE testtable CONVERT TO CHARACTER SET utf8mb4 collate utf8mb4_general_ci;
-- 列级别
ALTER TABLE testtable MODIFY `colname` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
意外情况:
我在 mysql5.7.32测试的时候,报错:“Specified key was too long; max key length is 767 bytes”。
出现这个是因为,索引列最大长度不允许大于767B,之前列是utf8,定义为 varchar(255) 255*3<767,所以可以有:CREATE INDEX idx_testtable_name ON testtable (name);
但是,当列改成utf8mb4的时候,列的定义还是varchar(255)191*4<767,此时索引列的长度最大是191,所以索引应改为:CREATE INDEX idx_testtable_name ON testtable (name(191));
注意:在高版本mysql中(如: mysql8)不存在此问题。
八、推荐的数据库配置
推荐配置默认字符集和排序规则为:utf8mb4 utf8mb4_general_ci
具体到配置文件:
[mysqld]
basedir = "D:\\mysql-8.0.28-winx64"
datadir = "D:\\mysql-8.0.28-winx64\\data"
port = 3306
# 默认字符集
character-set-server = utf8mb4
# 默认排序规则, 排序规则不一致可能导致问题: Illegal mix of collations (utf8mb4_general_ci,IMPLICIT) and (utf8mb4_0900_ai_ci,IMPLICIT) for operation '='
collation_server =utf8mb4_general_ci
lower_case_table_names=1
sql_mode=TRADITIONAL
local_infile = 1

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 8
8 1
1- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)