数据库架构设计——表结构设计
摘要如何打造出一个能支撑海量的并发访问的分布式 MySQL 架构,本系列博文将从一下多个方面来分析有关MYSQL系统的架构设计相关原理。实际的业务为案例分析,分析实际业务中表使用的字段类型是如何选型,在介绍MySQL 中表的设计,比如表结构设计、访问设计、物理存储设计。通过模块一解决你表结构设计的痛点问题,让你打好架构设计最为基础的工作。一、MySQL架构设计原理1.1 表结构设计实际的业务为案例
摘要
如何打造出一个能支撑海量的并发访问的分布式 MySQL 架构,本系列博文将从一下多个方面来分析有关MYSQL系统的架构设计相关原理。实际的业务为案例分析,分析实际业务中表使用的字段类型是如何选型,在介绍MySQL 中表的设计,比如表结构设计、访问设计、物理存储设计。通过模块一解决你表结构设计的痛点问题,让你打好架构设计最为基础的工作。
一、MySQL架构设计原理
1.1 表结构设计
实际的业务为案例分析,分析实际业务中表使用的字段类型是如何选型,在介绍MySQL 中表的设计,比如表结构设计、访问设计、物理存储设计。通过模块一解决你表结构设计的痛点问题,让你打好架构设计最为基础的工作。
1.2 索引设计
当单表的设计不足以支撑业务上线,接下来需要考虑的是索引设计优化。通过分析索引的基本原理,层层推进到索引的创建和优化,最后触达复杂 SQL 索引的设计与调优,比如多表 JOIN、子查询、分区表的问题。希望学完这部分内容之后,你能解决线上所有的 SQL 问题,不论是 OLTP 业务,还是复杂的 OLAP 业务。
1.3 高可用的架构设计
业务上线必不可少的就是高可用的环节,而 MySQL 作为一个开源的数据库,虽然提供了大量的高可用解决方案,但或多或少存在不少问题。将介绍搭建一个完整的、可靠的、符合各种业务类型的高可用解决方案。
1.4 分布式架构设计
海量的业务还会涉及分布式架构的设计,这其实对当前业务与 DBA 同学来说,是非常具有挑战性的技术难点。从介绍分布式架构概述、分布式表结构设计、分布式索引设计、分布式事务相关原理。
1.5 偏向的拓展设计
将介绍mysql中是对一些数据库设计中热门话题的分析,学习这些问题,能从更宏观、更上层的角度去设计出一个更好的架构,解决对应的问题,比如热点更新问题、数据迁移等问题。
二、表结构设计
2.1 数字类型选择:自增ID
在进行表结构设计时,数字类型是最为常见的类型之一,但要用好数字类型并不如想象得那么简单,比如:
- 怎么设计一个互联网海量并发业务的自增主键?用 INT 就够了?
- 怎么设计账户的余额?用 DECIMAL 类型就万无一失了吗?
以上全错!数字类型看似简单,但在表结构架构设计中很容易出现上述“设计上思考不全面”的问题(特别是在海量并发的互联网场景下)。所以我将从业务架构设计的角度带你深入了解数字类型的使用,希望能真正用好 MySQL 的数字类型(整型类型、浮点类型和高精度型)。
2.1.1 整型类型
MySQL 数据库支持 SQL 标准支持的整型类型:INT、SMALLINT。此外,MySQL 数据库也支持诸如 TINYINT、MEDIUMINT 和 BIGINT 整型类型(表 1 显示了各种整型所占用的存储空间及取值范围):
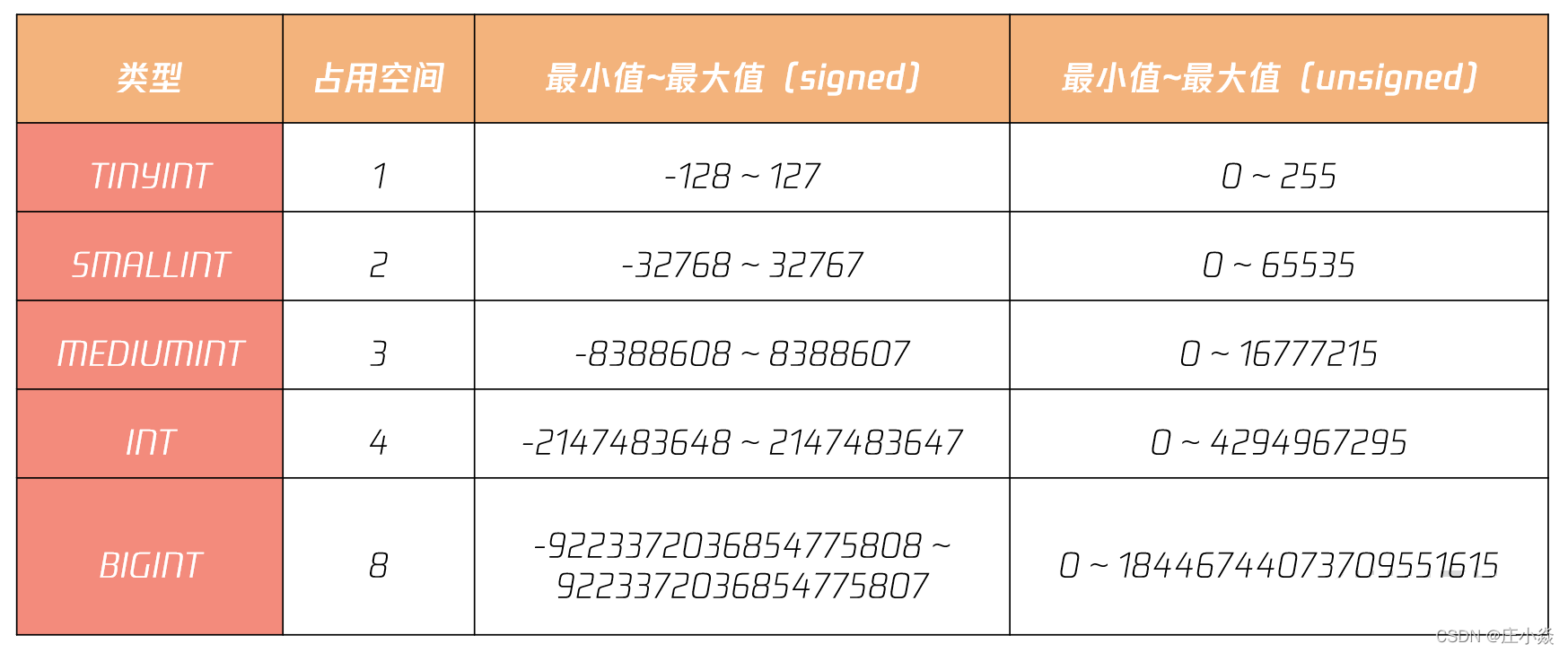
各 INT 类型的取值范围:在整型类型中,有 signed 和 unsigned 属性,其表示的是整型的取值范围,默认为 signed。在设计时,我不建议你刻意去用 unsigned 属性,因为在做一些数据分析时,SQL 可能返回的结果并不是想要得到的结果。
“销售表 sale”的例子,其表结构和数据如下。这里要特别注意,列 sale_count 用到的是 unsigned 属性(即设计时希望列存储的数值大于等于 0):
mysql> SHOW CREATE TABLE sale\G;
*************************************************************************************
Table: sale
Create Table: CREATE TABLE `sale` (
`sale_date` date NOT NULL,
`sale_count` int unsigned DEFAULT NULL,
PRIMARY KEY (`sale_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
1 row in set (0.00 sec)
*************************************************************************************
mysql> SELECT * FROM sale;
+------------+------------+
| sale_date | sale_count |
+------------+------------+
| 2020-01-01 | 10000 |
| 2020-02-01 | 8000 |
| 2020-03-01 | 12000 |
| 2020-04-01 | 9000 |
| 2020-05-01 | 10000 |
| 2020-06-01 | 18000 |
+------------+------------+
6 rows in set (0.00 sec)
*************************************************************************************mysql> SELECT
s1.sale_date, s2.sale_count - s1.sale_count AS diff
FROM
sale s1
LEFT JOIN
sale s2 ON DATE_ADD(s2.sale_date, INTERVAL 1 MONTH) = s1.sale_date
ORDER BY sale_date;然而,在执行的过程中,由于列 sale_count 用到了 unsigned 属性,会抛出这样的结果:
ERROR 1690 (22003): BIGINT UNSIGNED value is out of range in '(`test`.`s2`.`sale_count` - `test`.`s1`.`sale_count`)'可以看到,MySQL 提示用户计算的结果超出了范围。其实,这里 MySQL 要求 unsigned 数值相减之后依然为 unsigned,否则就会报错。为了避免这个错误,需要对数据库参数 sql_mode 设置为 NO_UNSIGNED_SUBTRACTION,允许相减的结果为 signed,这样才能得到最终想要的结果:
mysql> SET sql_mode='NO_UNSIGNED_SUBTRACTION';
***************************************************************************************
mysql> SELECT
s1.sale_date,
IFNULL(s2.sale_count - s1.sale_count,'') AS diff
FROM
sale s1
LEFT JOIN sale s2
ON DATE_ADD(s2.sale_date, INTERVAL 1 MONTH) = s1.sale_date
ORDER BY sale_date;
+------------+-------+
| sale_date | diff |
+------------+-------+
| 2020-01-01 | |
| 2020-02-01 | 2000 |
| 2020-03-01 | -4000 |
| 2020-04-01 | 3000 |
| 2020-05-01 | -1000 |
| 2020-06-01 | -8000 |
+------------+-------+2.1.2 浮点类型和高精度型
除了整型类型,数字类型常用的还有浮点和高精度类型。MySQL 之前的版本中存在浮点类型 Float 和 Double,但这些类型因为不是高精度,也不是 SQL 标准的类型,所以在真实的生产环境中不推荐使用,否则在计算时,由于精度类型问题,会导致最终的计算结果出错。更重要的是,从 MySQL 8.0.17 版本开始,当创建表用到类型 Float 或 Double 时,会抛出下面的警告:MySQL 提醒用户不该用上述浮点类型,甚至提醒将在之后版本中废弃浮点类型。
Specifying number of digits for floating point data types is deprecated and will be removed in a future release而数字类型中的高精度 DECIMAL 类型可以使用,当声明该类型列时,可以(并且通常必须要)指定精度和标度,例如:
salary DECIMAL(8,2)其中,8 是精度(精度表示保存值的主要位数),2 是标度(标度表示小数点后面保存的位数)。通常在表结构设计中,类型 DECIMAL 可以用来表示用户的工资、账户的余额等精确到小数点后 2 位的业务。然而,在海量并发的互联网业务中使用,金额字段的设计并不推荐使用 DECIMAL 类型,而更推荐使用 INT 整型类型。
2.1.3 业务表主键设计
整型类型与自增设计:在真实业务场景中,整型类型最常见的就是在业务中用来表示某件物品的数量。例如上述表的销售数量,或电商中的库存数量、购买次数等。在业务中,整型类型的另一个常见且重要的使用用法是作为表的主键,即用来唯一标识一行数据。整型结合属性 auto_increment,可以实现自增功能,但在表结构设计时用自增做主键,希望你特别要注意以下两点,若不注意,可能会对业务造成灾难性的打击:
- 用 BIGINT 做主键,而不是 INT;
- 自增值并不持久化,可能会有回溯现象(MySQL 8.0 版本前)。
从表 1 可以发现,INT 的范围最大在 42 亿的级别,在真实的互联网业务场景的应用中,很容易达到最大值。例如一些流水表、日志表,每天 1000W 数据量,420 天后,INT 类型的上限即可达到。因此,(敲黑板 1)用自增整型做主键,一律使用 BIGINT,而不是 INT。不要为了节省 4 个字节使用 INT,当达到上限时,再进行表结构的变更,将是巨大的负担与痛苦。
如果达到了 INT 类型的上限,数据库的表现又将如何呢?是会重新变为 1?我们可以通过下面的 SQL 语句验证一下:
# 创建一张表
mysql> CREATE TABLE t (a INT AUTO_INCREMENT PRIMARY KEY);
# 插入数据
mysql> INSERT INTO t VALUES (2147483647);
# 插入数据
mysql> INSERT INTO t VALUES (NULL);
# 报错
ERROR 1062 (23000): Duplicate entry '2147483647' for key 't.PRIMARY'可以看到,当达到 INT 上限后,再次进行自增插入时,会报重复错误,MySQL 数据库并不会自动将其重置为 1。
第二个特别要注意的问题是,MySQL 8.0 版本前,自增不持久化,自增值可能会存在回溯问题!
mysql> SELECT * FROM t;
**********************************************************************************
+---+
| a |
+---+
| 1 |
| 2 |
| 3 |
+---+
**********************************************************************************
mysql> DELETE FROM t WHERE a = 3;
Query OK, 1 row affected (0.02 sec)
**********************************************************************************
mysql> SHOW CREATE TABLE t\G
Table: t
Create Table: CREATE TABLE `t` (
`a` int NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`a`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
1 row in set (0.00 sec
**********************************************************************************可以看到,在删除自增为 3 的这条记录后,下一个自增值依然为 4(AUTO_INCREMENT=4),这里并没有错误,自增并不会进行回溯。但若这时数据库发生重启,那数据库启动后,表 t 的自增起始值将再次变为 3,即自增值发生回溯。具体如下所示:
mysql> SHOW CREATE TABLE t \G;
*************************** 1. row ***************************
Table: t
Create Table: CREATE TABLE `t` (
`a` int NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`a`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
1 row in set (0.00 s)
******************************************************************若要彻底解决这个问题,有以下 2 种方法:
- 升级 MySQL 版本到 8.0 版本,每张表的自增值会持久化;
- 若无法升级数据库版本,则强烈不推荐在核心业务表中使用自增数据类型做主键。
其实,在海量互联网架构设计过程中,为了之后更好的分布式架构扩展性,不建议使用整型类型做主键,更为推荐的是字符串类型。
2.1.4 资金字段设计
在用户余额、基金账户余额、数字钱包、零钱等的业务设计中,由于字段都是资金字段,通常程序员习惯使用DECIMAL 类型作为字段的选型,因为这样可以精确到分,如:DECIMAL(8,2)。
mysql> CREATE TABLE User (
userId BIGINT AUTO_INCREMENT,
money DECIMAL(8,2) NOT NULL,
......
)在海量互联网业务的设计标准中,并不推荐用 DECIMAL 类型,而是更推荐将 DECIMAL 转化为 整型类型。也就是说,资金类型更推荐使用用分单位存储,而不是用元单位存储。如1元在数据库中用整型类型 100 存储。
金额字段的取值范围如果用 DECIMAL 表示的,如何定义长度呢?
因为类型 DECIMAL 是个变长字段,若要定义金额字段,则定义为 DECIMAL(8,2) 是远远不够的。这样只能表示存储最大值为 999999.99,百万级的资金存储。用户的金额至少要存储百亿的字段,而统计局的 GDP 金额字段则可能达到数十万亿级别。用类型 DECIMAL 定义,不好统一。
另外重要的是,类型 DECIMAL 是通过二进制实现的一种编码方式,计算效率远不如整型来的高效。因此,推荐使用 BIG INT 来存储金额相关的字段。字段存储时采用分存储,即便这样 BIG INT 也能存储千兆级别的金额。这里,1兆 = 1万亿。
这样的好处是,所有金额相关字段都是定长字段,占用 8 个字节,存储高效。另一点,直接通过整型计算,效率更高。注意,在数据库设计中,我们非常强调定长存储,因为定长存储的性能更好。
我们来看在数据库中记录的存储方式,大致如下:
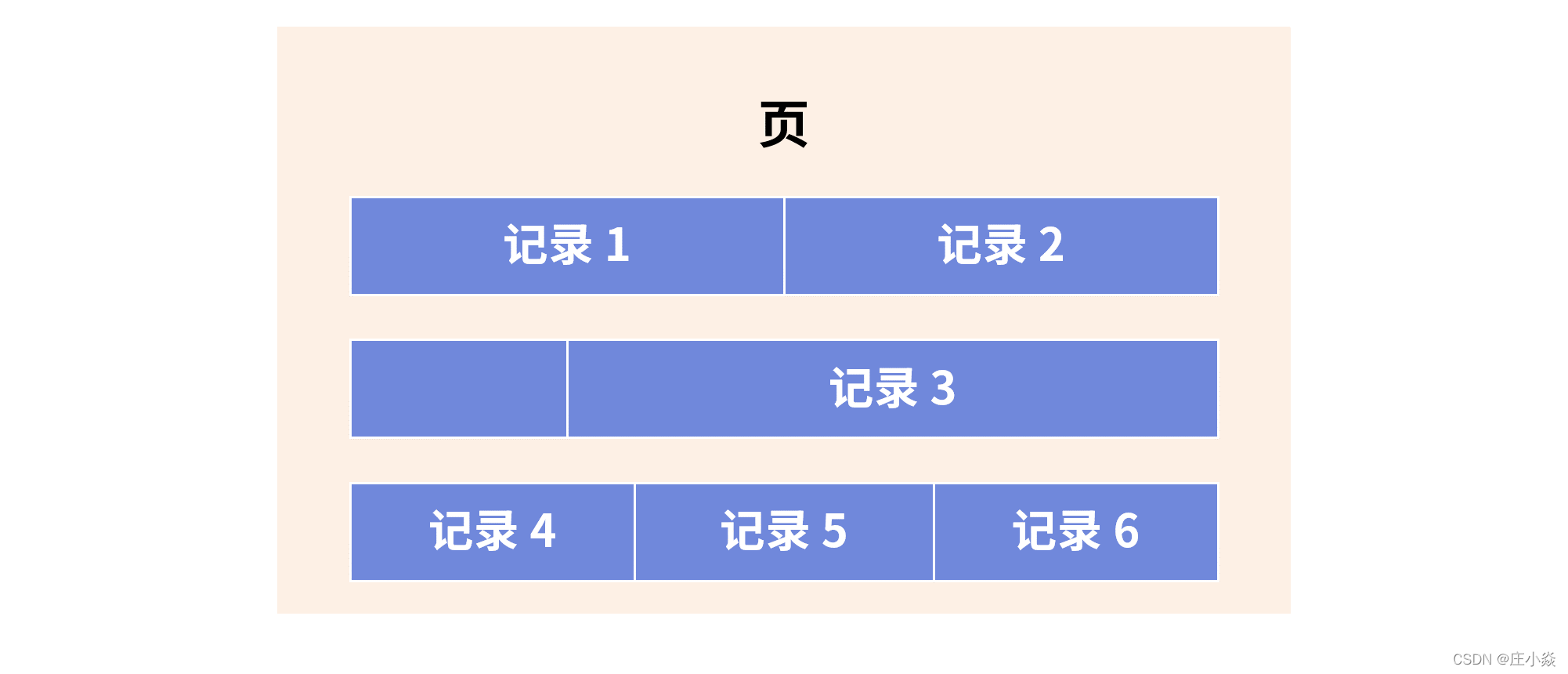
若发生更新,记录 1 原先的空间无法容纳更新后记录 1 的存储空间,因此,这时数据库会将记录 1 标记为删除,寻找新的空间给记录1使用,如:

上图中*记录 1 表示的就是原先记录 1 占用的空间,而这个空间后续将变成碎片空间,无法继续使用,除非人为地进行表空间的碎片整理。
那么,当使用 BIG INT 存储金额字段的时候,如何表示小数点中的数据呢?其实,这部分完全可以交由前端进行处理并展示。作为数据库本身,只要按分进行存储即可。
2.1.5 表数字类型设计总结
- 不推荐使用整型类型的属性 Unsigned,若非要使用,参数 sql_mode 务必额外添加上选项 NO_UNSIGNED_SUBTRACTION;
- 自增整型类型做主键,务必使用类型 BIGINT,而非 INT,后期表结构调整代价巨大;
- MySQL 8.0 版本前,自增整型会有回溯问题,做业务开发的你一定要了解这个问题;
- 当达到自增整型类型的上限值时,再次自增插入,MySQL 数据库会报重复错误;
- 不要再使用浮点类型 Float、Double,MySQL 后续版本将不再支持上述两种类型;
- 账户余额字段,设计是用整型类型,而不是 DECIMAL 类型,这样性能更好,存储更紧凑。
2.2 字符串类型:COLLATION原理
MySQL 数据库的字符串类型有 CHAR、VARCHAR、BINARY、BLOB、TEXT、ENUM、SET。不同的类型在业务设计、数据库性能方面的表现完全不同,其中最常使用的是 CHAR、VARCHAR。
2.2.1 CHAR 和 VARCHAR 的定义
CHAR(N) 用来保存固定长度的字符,N 的范围是 0 ~ 255,请牢记,N 表示的是字符,而不是字节。VARCHAR(N) 用来保存变长字符,N 的范围为 0 ~ 65536, N 表示字符。
在超出 65536 个字符的情况下,可以考虑使用更大的字符类型 TEXT 或 BLOB,两者最大存储长度为 4G,其区别是 BLOB 没有字符集属性,纯属二进制存储。和 Oracle、Microsoft SQL Server 等传统关系型数据库不同的是,MySQL 数据库的 VARCHAR 字符类型,最大能够存储 65536 个字符,所以在 MySQL 数据库下,绝大部分场景使用类型 VARCHAR 就足够了。
2.2.2 字符集
在表结构设计中,除了将列定义为 CHAR 和 VARCHAR 用以存储字符以外,还需要额外定义字符对应的字符集,因为每种字符在不同字符集编码下,对应着不同的二进制值。常见的字符集有 GBK、UTF8,通常推荐把默认字符集设置为 UTF8。而且随着移动互联网的飞速发展,推荐把 MySQL 的默认字符集设置为 UTF8MB4,否则,某些 emoji 表情字符无法在 UTF8 字符集下存储,比如 emoji 笑脸表情,对应的字符编码为 0xF09F988E:
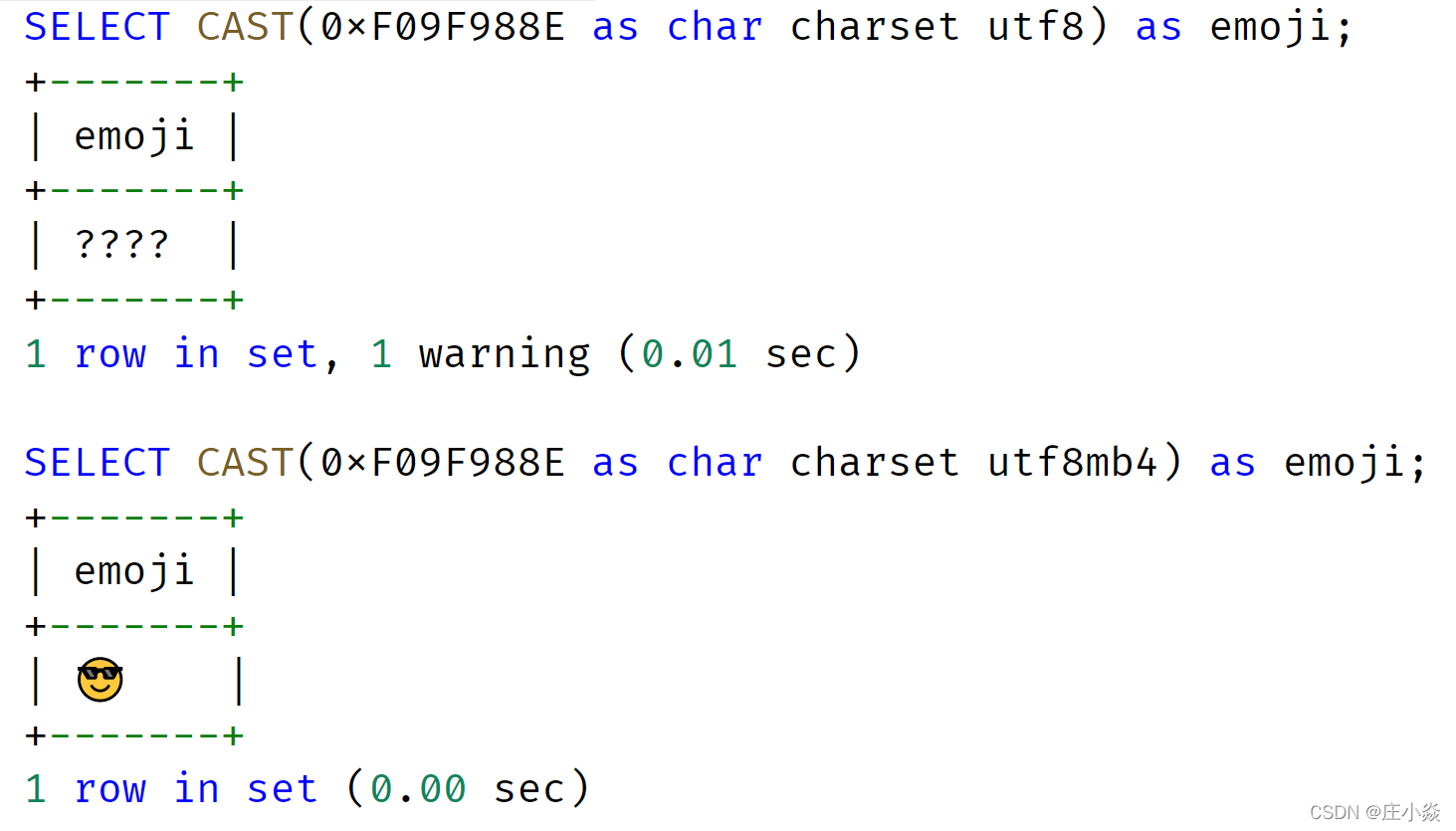
若强行在字符集为 UTF8 的列上插入 emoji 表情字符, MySQL 会抛出如下错误信息:
mysql> SHOW CREATE TABLE emoji_test \G;
*************************** 1. row ***************************
Table: emoji_test
Create Table: CREATE TABLE `emoji_test` (
`a` varchar(100) CHARACTER SET utf8,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
# 插入表情
INSERT INTO emoji_test VALUES (0xF09F988E);
# 报错
ERROR 1366 (HY000): Incorrect string value: '\xF0\x9F\x98\x8E' for column 'a' at row 1包括 MySQL 8.0 版本在内,字符集默认设置成 UTF8MB4,8.0 版本之前默认的字符集为 Latin1。因为不同版本默认字符集的不同,你要显式地在配置文件中进行相关参数的配置:
[mysqld]
# 字符集默认设置成 UTF8MB4
character-set-server = utf8mb4另外,不同的字符集,CHAR(N)、VARCHAR(N) 对应最长的字节也不相同。比如 GBK 字符集,1 个字符最大存储 2 个字节,UTF8MB4 字符集 1 个字符最大存储 4 个字节。所以从底层存储内核看,在多字节字符集下,CHAR 和 VARCHAR 底层的实现完全相同,都是变长存储!
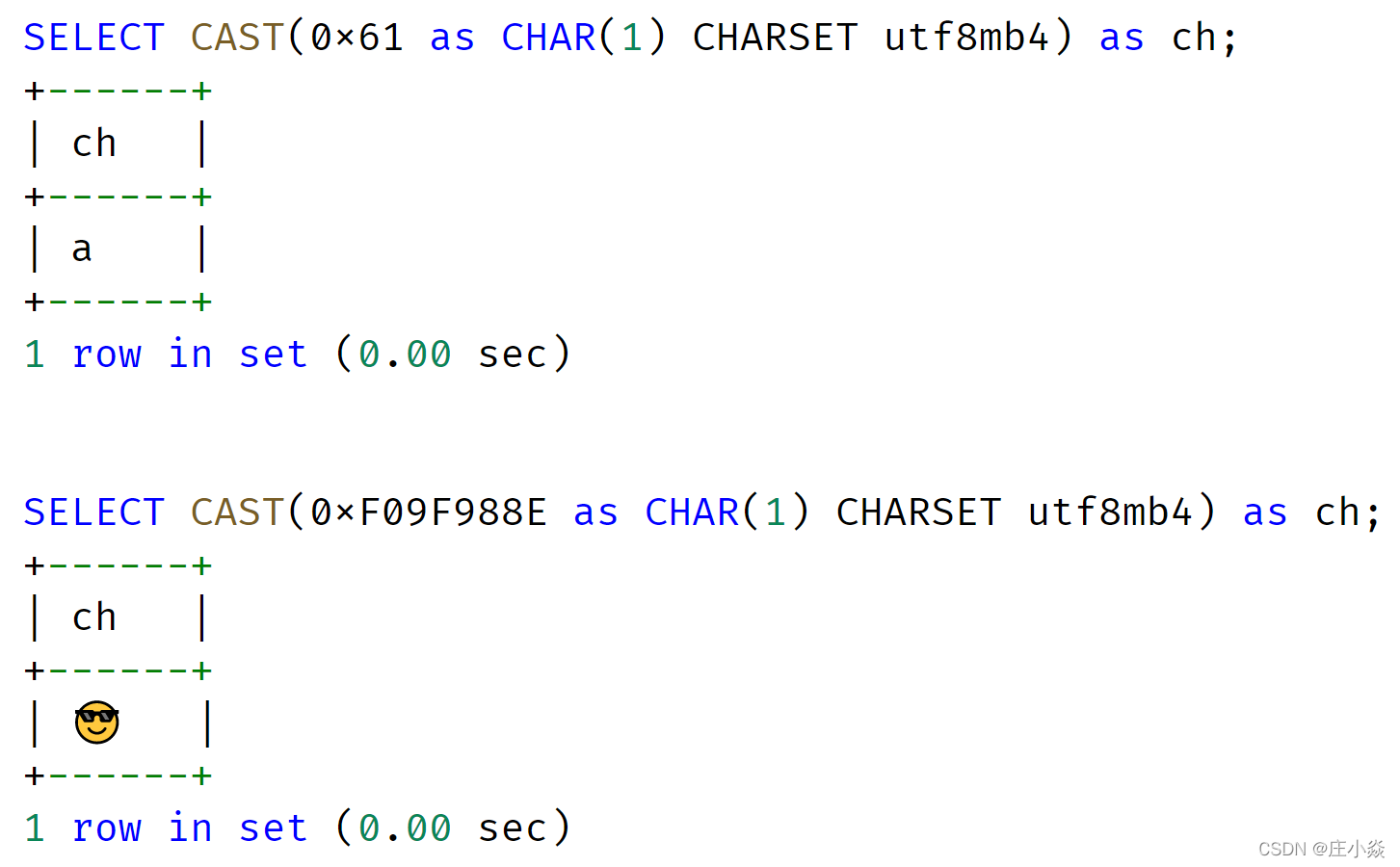
从上面的例子可以看到,CHAR(1) 既可以存储 1 个 'a' 字节,也可以存储 4 个字节的 emoji 笑脸表情,因此 CHAR 本质也是变长的。鉴于目前默认字符集推荐设置为 UTF8MB4,所以在表结构设计时,可以把 CHAR 全部用 VARCHAR 替换,底层存储的本质实现一模一样。
2.2.3 排序规则
排序规则(Collation)是比较和排序字符串的一种规则,每个字符集都会有默认的排序规则,你可以用命令 SHOW CHARSET 来查看:
mysql> SHOW CHARSET LIKE 'utf8%';
+---------+---------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------+--------------------+--------+
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
+---------+---------------+--------------------+--------+
mysql> SHOW COLLATION LIKE 'utf8mb4%';
+----------------------------+---------+-----+---------+----------+---------+---------------+
| Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute |
+----------------------------+---------+-----+---------+----------+---------+---------------+
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD |
| utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD |
| utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD |
| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE |排序规则以 _ci 结尾,表示不区分大小写(Case Insentive),_cs 表示大小写敏感,_bin 表示通过存储字符的二进制进行比较。需要注意的是,比较 MySQL 字符串,默认采用不区分大小的排序规则:
mysql> SELECT 'a' = 'A';
+-----------+
| 'a' = 'A' |
+-----------+
| 1 |
+-----------+
1 row in set (0.00 sec)
mysql> SELECT CAST('a' as char) COLLATE utf8mb4_0900_as_cs = CAST('A' as CHAR) COLLATE utf8mb4_0900_as_cs as result;
+--------+
| result |
+--------+
| 0 |
+--------+牢记,绝大部分业务的表结构设计无须设置排序规则为大小写敏感!除非你能明白你的业务真正需要。
2.2.4 正确修改字符集
当然,相信不少业务在设计时没有考虑到字符集对于业务数据存储的影响,所以后期需要进行字符集转换,但很多同学会发现执行如下操作后,依然无法插入 emoji 这类 UTF8MB4 字符:
mysql> ALTER TABLE emoji_test CHARSET utf8mb4;其实,上述修改只是将表的字符集修改为 UTF8MB4,下次新增列时,若不显式地指定字符集,新列的字符集会变更为 UTF8MB4,但对于已经存在的列,其默认字符集并不做修改,你可以通过命令 SHOW CREATE TABLE 确认:
2.2.5 用户性别设计
设计表结构时,你会遇到一些固定选项值的字段。例如,性别字段(Sex),只有男或女;又或者状态字段(State),有效的值为运行、停止、重启等有限状态。大多数开发人员喜欢用 INT 的数字类型去存储性别字段,比如:
mysql> CREATE TABLE `User` (
`id` bigint NOT NULL AUTO_INCREMENT,
`sex` tinyint DEFAULT NULL,
......
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
其中,tinyint 列 sex 表示用户性别,但这样设计问题比较明显。
- 表达不清:在具体存储时,0 表示女,还是 1 表示女呢?每个业务可能有不同的潜规则;
- 脏数据:因为是 tinyint,因此除了 0 和 1,用户完全可以插入 2、3、4 这样的数值,最终表中存在无效数据的可能,后期再进行清理,代价就非常大了。
在 MySQL 8.0 版本之前,可以使用 ENUM 字符串枚举类型,只允许有限的定义值插入。如果将参数 SQL_MODE 设置为严格模式,插入非定义数据就会报错:
SHOW CREATE TABLE User\G;
*************************** 1. row ***************************
Table: User
Create Table: CREATE TABLE `User` (
`id` bigint NOT NULL AUTO_INCREMENT,
`sex` enum('M','F') COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
1 row in set (0.00 sec)
mysql> SET sql_mode = 'STRICT_TRANS_TABLES';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> INSERT INTO User VALUES (NULL,'F');
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO User VALUES (NULL,'A');
ERROR 1265 (01000): Data truncated for column 'sex' at row 1
由于类型 ENUM 并非 SQL 标准的数据类型,而是 MySQL 所独有的一种字符串类型。抛出的错误提示也并不直观,这样的实现总有一些遗憾,主要是因为MySQL 8.0 之前的版本并没有提供约束功能。自 MySQL 8.0.16 版本开始,数据库原生提供 CHECK 约束功能,可以方便地进行有限状态列类型的设计:
mysql> SHOW CREATE TABLE User \G;
*************************** 1. row ***************************
Table: User
Create Table: CREATE TABLE `User` (
`id` bigint NOT NULL AUTO_INCREMENT,
`sex` char(1) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`),
CONSTRAINT `user_chk_1` CHECK (((`sex` = _utf8mb4'M') or (`sex` = _utf8mb4'F')))
) ENGINE=InnoDB
1 row in set (0.00 sec)
mysql> INSERT INTO User VALUES (NULL,'M');
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO User VALUES (NULL,'Z');
ERROR 3819 (HY000): Check constraint 'user_chk_1' is violated.从这段代码中看到,第 8 行的约束定义 user_chk_1 表示列 sex 的取值范围,只能是 M 或者 F。同时,当 15 行插入非法数据 Z 时,你可以看到 MySQL 显式地抛出了违法约束的提示。
2.2.6 账户密码存储设计
切记,在数据库表结构设计时,千万不要直接在数据库表中直接存储密码,一旦有恶意用户进入到系统,则面临用户数据泄露的极大风险。比如金融行业,从合规性角度看,所有用户隐私字段都需要加密,甚至业务自己都无法知道用户存储的信息(隐私数据如登录密码、手机、信用卡信息等)。相信不少开发开发同学会通过函数 MD5 加密存储隐私数据,这没有错,因为 MD5 算法并不可逆。然而,MD5 加密后的值是固定的,如密码 12345678,它对应的 MD5 固定值即为 25d55ad283aa400af464c76d713c07ad。因此,可以对 MD5 进行暴力破解,计算出所有可能的字符串对应的 MD5 值。若无法枚举所有的字符串组合,那可以计算一些常见的密码,如111111、12345678 等。
所以,在设计密码存储使用,还需要加盐(salt),每个公司的盐值都是不同的,因此计算出的值也是不同的。若盐值为 psalt,则密码 12345678 在数据库中的值为:
password = MD5(‘psalt12345678’)这样的密码存储设计是一种固定盐值的加密算法,其中存在三个主要问题:
- 若 salt 值被(离职)员工泄漏,则外部黑客依然存在暴利破解的可能性;
- 对于相同密码,其密码存储值相同,一旦一个用户密码泄漏,其他相同密码的用户的密码也将被泄漏;
- 固定使用 MD5 加密算法,一旦 MD5 算法被破解,则影响很大。
所以一个真正好的密码存储设计,应该是:动态盐 + 非固定加密算法。我比较推荐这么设计密码,列 password 存储的格式如下:
$salt$cryption_algorithm$value- $salt:表示动态盐,每次用户注册时业务产生不同的盐值,并存储在数据库中。若做得再精细一点,可以动态盐值 + 用户注册日期合并为一个更为动态的盐值。
- $cryption_algorithm:表示加密的算法,如 v1 表示 MD5 加密算法,v2 表示 AES256 加密算法,v3 表示 AES512 加密算法等。
- $value:表示加密后的字符串。
这时表 User 的结构设计如下所示:
CREATE TABLE User (
id BIGINT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
sex CHAR(1) NOT NULL,
password VARCHAR(1024) NOT NULL,
regDate DATETIME NOT NULL,
CHECK (sex = 'M' OR sex = 'F'),
PRIMARY KEY(id)
);
SELECT * FROM User\G
*************************** 1. row ***************************
id: 1
name: David
sex: M
password: $fgfaef$v1$2198687f6db06c9d1b31a030ba1ef074
regDate: 2020-09-07 15:30:00
*************************** 2. row ***************************
id: 2
name: Amy
sex: F
password: $zpelf$v2$0x860E4E3B2AA4005D8EE9B7653409C4B133AF77AEF53B815D31426EC6EF78D882
regDate: 2020-09-07 17:28:00在上面的例子中,用户 David 和 Amy 密码都是 12345678,然而由于使用了动态盐和动态加密算法,两者存储的内容完全不同。即便别有用心的用户拿到当前密码加密算法,则通过加密算法 $cryption_algorithm 版本,可以对用户存储的密码进行升级,进一步做好对于恶意数据攻击的防范。
2.2.7 字符串设计总结
字符串是使用最为广泛的数据类型之一,但也是设计最初容易犯错的部分,后期业务跑起来再进行修改,代价将会非常巨大。
- CHAR 和 VARCHAR 虽然分别用于存储定长和变长字符,但对于变长字符集(如 GBK、UTF8MB4),其本质是一样的,都是变长,设计时完全可以用 VARCHAR 替代 CHAR;
- 推荐 MySQL 字符集默认设置为 UTF8MB4,可以用于存储 emoji 等扩展字符;
- 排序规则很重要,用于字符的比较和排序,但大部分场景不需要用区分大小写的排序规则;
- 修改表中已有列的字符集,使用命令 ALTER TABLE ... CONVERT TO ....;
- 用户性别,运行状态等有限值的列,MySQL 8.0.16 版本直接使用 CHECK 约束机制,之前的版本可使用 ENUM 枚举字符串类型,外加 SQL_MODE 的严格模式;
- 业务隐私信息,如密码、手机、信用卡等信息,需要加密。切记简单的MD5算法是可以进行暴力破解,并不安全,推荐使用动态盐+动态加密算法进行隐私数据的存储。
2.3 日期类型:TIMESTAMP原则
几乎每张业务表都带有一个日期列,用于记录每条记录产生和变更的时间。比如用户表会有一个日期列记录用户注册的时间、用户最后登录的时间。又比如,电商行业中的订单表(核心业务表)会有一个订单产生的时间列,当支付时间超过订单产生的时间,这个订单可能会被系统自动取消。
日期类型虽然常见,但在表结构设计中也容易犯错,比如很多开发同学都倾向使用整型存储日期类型,同时也会忽略不同日期类型对于性能可能存在的潜在影响。
日期类型:MySQL 数据库中常见的日期类型有 YEAR、DATE、TIME、DATETIME、TIMESTAMEP。因为业务绝大部分场景都需要将日期精确到秒,所以在表结构设计中,常见使用的日期类型为DATETIME 和 TIMESTAMP。
2.3.1 DATETIME类型
类型 DATETIME 最终展现的形式为:YYYY-MM-DD HH:MM:SS,固定占用 8 个字节。从 MySQL 5.6 版本开始,DATETIME 类型支持毫秒,DATETIME(N) 中的 N 表示毫秒的精度。例如,DATETIME(6) 表示可以存储 6 位的毫秒值。同时,一些日期函数也支持精确到毫秒,例如常见的函数 NOW、SYSDATE:
mysql> SELECT NOW(6);
+----------------------------+
| NOW(6) |
+----------------------------+
| 2020-09-14 17:50:28.707971 |
+----------------------------+
1 row in set (0.00 sec)用户可以将 DATETIME 初始化值设置为当前时间,并设置自动更新当前时间的属性。例如之前已设计的用户表 User,我在其基础上,修改了register_date、last_modify_date的定义:
CREATE TABLE User (
id BIGINT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
sex CHAR(1) NOT NULL,
password VARCHAR(1024) NOT NULL,
money INT NOT NULL DEFAULT 0,
register_date DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
last_modify_date DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6),
CHECK (sex = 'M' OR sex = 'F'),
PRIMARY KEY(id)
);在上面的表 User 中,列 register_date 表示注册时间,DEFAULT CURRENT_TIMESTAMP 表示记录插入时,若没有指定时间,默认就是当前时间。列 last_modify_date 表示当前记录最后的修改时间,DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6) 表示每次修改都会修改为当前时间。
这样的设计保证当用户的金钱(money 字段)发生了变更,则 last_modify_date 能记录最后一次用户金钱发生变更时的时间。来看下面的例子:
mysql> SELECT name,money,last_modify_date FROM User WHERE name = 'David';
+-------+-------+----------------------------+
| name | money | last_modify_date |
+-------+-------+----------------------------+
| David | 100 | 2020-09-13 08:08:33.898593 |
+-------+-------+----------------------------+
1 row in set (0.00 sec)
mysql> UPDATE User SET money = money - 1 WHERE name = 'David';
Query OK, 1 row affected (0.06 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> SELECT name,money,last_modify_date FROM User WHERE name = 'David';
+-------+-------+----------------------------+
| name | money | last_modify_date |
+-------+-------+----------------------------+
| David | 99 | 2020-09-14 18:29:17.056327 |
+-------+-------+----------------------------+
1 row in set (0.00 sec)2.3.2 TIMESTAMP类型
除了 DATETIME,日期类型中还有一种 TIMESTAMP 的时间戳类型,其实际存储的内容为‘1970-01-01 00:00:00’到现在的毫秒数。在 MySQL 中,由于类型 TIMESTAMP 占用 4 个字节,因此其存储的时间上限只能到‘2038-01-19 03:14:07’。同类型 DATETIME 一样,从 MySQL 5.6 版本开始,类型 TIMESTAMP 也能支持毫秒。与 DATETIME 不同的是,若带有毫秒时,类型 TIMESTAMP 占用 7 个字节,而 DATETIME 无论是否存储毫秒信息,都占用 8 个字节。
类型 TIMESTAMP 最大的优点是可以带有时区属性,因为它本质上是从毫秒转化而来。如果你的业务需要对应不同的国家时区,那么类型 TIMESTAMP 是一种不错的选择。比如新闻类的业务,通常用户想知道这篇新闻发布时对应的自己国家时间,那么 TIMESTAMP 是一种选择。
另外,有些国家会执行夏令时。根据不同的季节,人为地调快或调慢 1 个小时,带有时区属性的 TIMESTAMP 类型本身就能解决这个问题。参数 time_zone 指定了当前使用的时区,默认为 SYSTEM 使用操作系统时区,用户可以通过该参数指定所需要的时区。
如果想使用 TIMESTAMP 的时区功能,你可以通过下面的语句将之前的用户表 User 的注册时间字段类型从 DATETIME(6) 修改为 TIMESTAMP(6):
ALTER TABLE User CHANGE register_date register_date TIMESTAMP(6) NOT NULL DEFAULT CURRENT_TIMESTAMP (6);这时通过设定不同的 time_zone,可以观察到不同时区下的注册时间:
mysql> SELECT name,regist er_date FROM User WHERE name = 'David';
+-------+----------------------------+
| name | register_date |
+-------+----------------------------+
| David | 2018-09-14 18:28:33.898593 |
+-------+----------------------------+
1 row in set (0.00 sec)
mysql> SET time_zone = '-08:00';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT name,register_date FROM User WHERE name = 'David';
+-------+----------------------------+
| name | register_date |
+-------+----------------------------+
| David | 2018-09-14 02:28:33.898593 |
+-------+----------------------------+
1 row in set (0.00 sec)从上述例子中,你可以看到,中国的时区是 +08:00,美国的时区是 -08:00,因此改为美国时区后,可以看到用户注册时间比之前延迟了 16 个小时。当然了,直接加减时区并不直观,需要非常熟悉各国的时区表。在 MySQL 中可以直接设置时区的名字,如:
mysql> SET time_zone = 'America/Los_Angeles';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT NOW();
+---------------------+
| NOW() |
+---------------------+
| 2020-09-14 20:12:49 |
+---------------------+
1 row in set (0.00 sec)
mysql> SET time_zone = 'Asia/Shanghai';
Query OK, 0 rows affected (0.00 sec)
mysql> SELECT NOW();
+---------------------+
| NOW() |
+---------------------+
| 2020-09-15 11:12:55 |
+---------------------+
1 row in set (0.00 sec)2.3.3 业务表结构设计实战
DATETIME vs TIMESTAMP vs INT,怎么选?
在做表结构设计时,对日期字段的存储,开发人员通常会有 3 种选择:DATETIME、TIMESTAMP、INT。
INT 类型就是直接存储 '1970-01-01 00:00:00' 到现在的毫秒数,本质和 TIMESTAMP 一样,因此用 INT 不如直接使用 TIMESTAMP。
当然,有些同学会认为 INT 比 TIMESTAMP 性能更好。但是,由于当前每个 CPU 每秒可执行上亿次的计算,所以无须为这种转换的性能担心。更重要的是,在后期运维和数据分析时,使用 INT 存储日期,是会让 DBA 和数据分析人员发疯的,INT的可运维性太差。也有的同学会热衷用类型 TIMESTEMP 存储日期,因为类型 TIMESTAMP 占用 4 个字节,比 DATETIME 小一半的存储空间。
但若要将时间精确到毫秒,TIMESTAMP 要 7 个字节,和 DATETIME 8 字节差不太多。另一方面,现在距离 TIMESTAMP 的最大值‘2038-01-19 03:14:07’已经很近,这是需要开发同学好好思考的问题。
总的来说,我建议你使用类型 DATETIME。 对于时区问题,可以由前端或者服务这里做一次转化,不一定非要在数据库中解决。
不要忽视 TIMESTAMP 的性能问题
前面已经提及,TIMESTAMP 的上限值 2038 年很快就会到来,那时业务又将面临一次类似千年虫的问题。另外,TIMESTAMP 还存在潜在的性能问题。
虽然从毫秒数转换到类型 TIMESTAMP 本身需要的 CPU 指令并不多,这并不会带来直接的性能问题。但是如果使用默认的操作系统时区,则每次通过时区计算时间时,要调用操作系统底层系统函数 __tz_convert(),而这个函数需要额外的加锁操作,以确保这时操作系统时区没有修改。所以,当大规模并发访问时,由于热点资源竞争,会产生两个问题。
- 性能不如 DATETIME: DATETIME 不存在时区转化问题。
- 性能抖动: 海量并发时,存在性能抖动问题。
为了优化 TIMESTAMP 的使用,强烈建议你使用显式的时区,而不是操作系统时区。比如在配置文件中显示地设置时区,而不要使用系统时区:
[mysqld]
time_zone = "+08:00"最后,通过命令 mysqlslap 来测试 TIMESTAMP、DATETIME 的性能,命令如下:
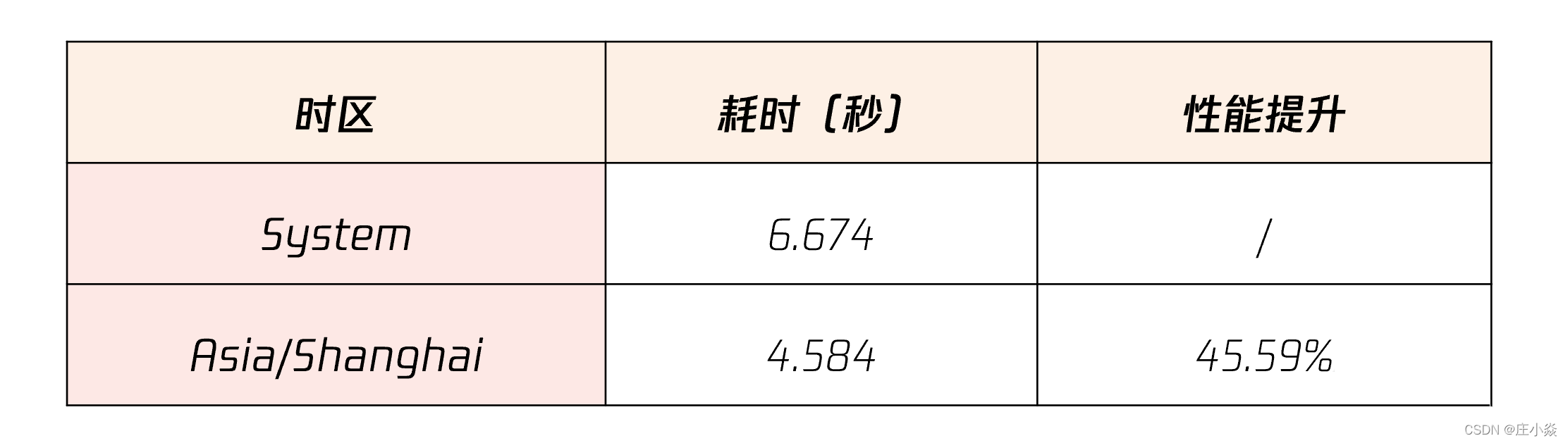
# 比较time_zone为System和Asia/Shanghai的性能对比
mysqlslap -uroot --number-of-queries=1000000 --concurrency=100 --query='SELECT NOW()'最后的性能对比如下:从表中可以发现,显式指定时区的性能要远远好于直接使用操作系统时区。所以,日期字段推荐使用 DATETIME,没有时区转化。即便使用 TIMESTAMP,也需要在数据库中显式地配置时区,而不是用系统时区。
表结构设计规范:每条记录都要有一个时间字段。在做表结构设计规范时,强烈建议你每张业务核心表都增加一个 DATETIME 类型的 last_modify_date 字段,并设置修改自动更新机制, 即便标识每条记录最后修改的时间。
例如,在前面的表 User 中的字段 last_modify_date,就是用于表示最后一次的修改时间:
CREATE TABLE User (
id BIGINT NOT NULL AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
sex CHAR(1) NOT NULL,
password VARCHAR(1024) NOT NULL,
money INT NOT NULL DEFAULT 0,
register_date DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
last_modify_date DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6) ON UPDATE CURRENT_TIMESTAMP(6),
CHECK (sex = 'M' OR sex = 'F'),
PRIMARY KEY(id)
);通过字段 last_modify_date 定义的 ON UPDATE CURRENT_TIMESTAMP(6),那么每次这条记录,则都会自动更新 last_modify_date 为当前时间。这样设计的好处是: 用户可以知道每个用户最近一次记录更新的时间,以便做后续的处理。比如在电商的订单表中,可以方便对支付超时的订单做处理;在金融业务中,可以根据用户资金最后的修改时间做相应的资金核对等。
2.3.4 日期类型总结
- MySQL 5.6 版本开始 DATETIME 和 TIMESTAMP 精度支持到毫秒;
- DATETIME 占用 8 个字节,TIMESTAMP 占用 4 个字节,DATETIME(6) 依然占用 8 个字节,TIMESTAMP(6) 占用 7 个字节;
- TIMESTAMP 日期存储的上限为 2038-01-19 03:14:07,业务用 TIMESTAMP 存在风险;
- 使用 TIMESTAMP 必须显式地设置时区,不要使用默认系统时区,否则存在性能问题,推荐在配置文件中设置参数 time_zone = '+08:00';
- 推荐日期类型使用 DATETIME,而不是 TIMESTAMP 和 INT 类型;
- 表结构设计时,每个核心业务表,推荐设计一个 last_modify_date 的字段,用以记录每条记录的最后修改时间。
2.4 非结构存储:JSON使用
MySQL 数据库中常见的 3 种类型:数字类型、字符串类型和日期类型,这些属于的关系型设计类型。关系型的结构化存储存在一定的弊端,因为它需要预先定义好所有的列以及列对应的类型。但是业务在发展过程中,或许需要扩展单个列的描述功能,这时,如果能用好 JSON 数据类型,那就能打通关系型和非关系型数据的存储之间的界限,为业务提供更好的架构选择。
当然,很多同学在用 JSON 数据类型时会遇到各种各样的问题,其中最容易犯的误区就是将类型 JSON 简单理解成字符串类型。
2.4.1 JSON 数据类型
JSON(JavaScript Object Notation)主要用于互联网应用服务之间的数据交换。MySQL 支持RFC 7159定义的 JSON 规范,主要有JSON 对象和JSON 数组两种类型。下面就是 JSON 对象,主要用来存储图片的相关信息:
{
"Image": {
"Width": 800,
"Height": 600,
"Title": "View from 15th Floor",
"Thumbnail": {
"Url": "http://www.example.com/image/481989943",
"Height": 125,
"Width": 100
},
"IDs": [116, 943, 234, 38793]
}
}从中你可以看到, JSON 类型可以很好地描述数据的相关内容,比如这张图片的宽度、高度、标题等(这里使用到的类型有整型、字符串类型)。JSON对象除了支持字符串、整型、日期类型,JSON 内嵌的字段也支持数组类型,如上代码中的 IDs 字段。另一种 JSON 数据类型是数组类型,如:
[
{
"precision": "zip",
"Latitude": 37.7668,
"Longitude": -122.3959,
"Address": "",
"City": "SAN FRANCISCO",
"State": "CA",
"Zip": "94107",
"Country": "US"
},
{
"precision": "zip",
"Latitude": 37.371991,
"Longitude": -122.026020,
"Address": "",
"City": "SUNNYVALE",
"State": "CA",
"Zip": "94085",
"Country": "US"
}
]上面的示例演示的是一个 JSON 数组,其中有 2 个 JSON 对象。到目前为止,可能很多同学会把 JSON 当作一个很大的字段串类型,从表面上来看,没有错。但本质上,JSON 是一种新的类型,有自己的存储格式,还能在每个对应的字段上创建索引,做特定的优化,这是传统字段串无法实现的。JSON 类型的另一个好处是无须预定义字段,字段可以无限扩展。而传统关系型数据库的列都需预先定义,想要扩展需要执行 ALTER TABLE ... ADD COLUMN ... 这样比较重的操作。需要注意是,JSON 类型是从 MySQL 5.7 版本开始支持的功能,而 8.0 版本解决了更新 JSON 的日志性能瓶颈。如果要在生产环境中使用 JSON 数据类型,强烈推荐使用 MySQL 8.0 版本。
2.4.2 用户登录设计
在数据库中,JSON 类型比较适合存储一些修改较少、相对静态的数据,比如用户登录信息的存储如下:
DROP TABLE IF EXISTS UserLogin;
CREATE TABLE UserLogin (
userId BIGINT NOT NULL,
loginInfo JSON,
PRIMARY KEY(userId)
);由于当前业务的登录方式越来越多样化,如同一账户支持手机、微信、QQ 账号登录,所以这里可以用 JSON 类型存储登录的信息。接着,插入下面的数据:
SET @a = '
{
"cellphone" : "13918888888",
"wxchat" : "破产码农",
"QQ" : "82946772"
}';
INSERT INTO UserLogin VALUES (1,@a);
SET @b = '
{
"cellphone" : "15026888888"
}';
INSERT INTO UserLogin VALUES (2,@b);从上面的例子中可以看到,用户 1 登录有三种方式:手机验证码登录、微信登录、QQ 登录,而用户 2 只有手机验证码登录。而如果不采用 JSON 数据类型,就要用下面的方式建表:
CREATE TABLE UserLogin (
userId BIGINT NOT NULL,
cellphone VARCHAR(255),
wechat VARCHAR(255)
QQ VARCHAR(255),
PRIMARY KEY(userId)
);可以看到,虽然用传统关系型的方式也可以完成相关数据的存储,但是存在两个问题。
- 有些列可能是比较稀疏的,一些列可能大部分都是 NULL 值;
- 如果要新增一种登录类型,如微博登录,则需要添加新列,而 JSON 类型无此烦恼。
因为支持了新的JSON类型,MySQL 配套提供了丰富的 JSON 字段处理函数,用于方便地操作 JSON 数据,具体可以见 MySQL 官方文档。其中,最常见的就是函数 JSON_EXTRACT,它用来从 JSON 数据中提取所需要的字段内容,如下面的这条 SQL 语句就查询用户的手机和微信信息。
SELECT
userId,
JSON_UNQUOTE(JSON_EXTRACT(loginInfo,"$.cellphone")) cellphone,
JSON_UNQUOTE(JSON_EXTRACT(loginInfo,"$.wxchat")) wxchat
FROM UserLogin;
+--------+-------------+--------------+
| userId | cellphone | wxchat |
+--------+-------------+--------------+
| 1 | 13918888888 | 破产码农 |
| 2 | 15026888888 | NULL |
+--------+-------------+--------------+
2 rows in set (0.01 sec)当然了,每次写 JSON_EXTRACT、JSON_UNQUOTE 非常麻烦,MySQL 还提供了 ->> 表达式,和上述 SQL 效果完全一样:
SELECT
userId,
loginInfo->>"$.cellphone" cellphone,
loginInfo->>"$.wxchat" wxchat
FROM UserLogin;当 JSON 数据量非常大,用户希望对 JSON 数据进行有效检索时,可以利用 MySQL 的函数索引功能对 JSON 中的某个字段进行索引。比如在上面的用户登录示例中,假设用户必须绑定唯一手机号,且希望未来能用手机号码进行用户检索时,可以创建下面的索引:
ALTER TABLE UserLogin ADD COLUMN cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone");
ALTER TABLE UserLogin ADD UNIQUE INDEX idx_cellphone(cellphone);上述 SQL 首先创建了一个虚拟列 cellphone,这个列是由函数 loginInfo->>"$.cellphone" 计算得到的。然后在这个虚拟列上创建一个唯一索引 idx_cellphone。这时再通过虚拟列 cellphone 进行查询,就可以看到优化器会使用到新创建的 idx_cellphone 索引:
EXPLAIN SELECT * FROM UserLogin
WHERE cellphone = '13918888888'\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: UserLogin
partitions: NULL
type: const
possible_keys: idx_cellphone
key: idx_cellphone
key_len: 1023
ref: const
rows: 1
filtered: 100.00
Extra: NULL
1 row in set, 1 warning (0.00 sec)当然,我们可以在一开始创建表的时候,就完成虚拟列及函数索引的创建。如下表创建的列 cellphone 对应的就是 JSON 中的内容,是个虚拟列;uk_idx_cellphone 就是在虚拟列 cellphone 上所创建的索引。
CREATE TABLE UserLogin (
userId BIGINT,
loginInfo JSON,
cellphone VARCHAR(255) AS (loginInfo->>"$.cellphone"),
PRIMARY KEY(userId),
UNIQUE KEY uk_idx_cellphone(cellphone)
);2.4.3 用户画像设计
某些业务需要做用户画像(也就是对用户打标签),然后根据用户的标签,通过数据挖掘技术,进行相应的产品推荐。比如:
- 在电商行业中,根据用户的穿搭喜好,推荐相应的商品;
- 在音乐行业中,根据用户喜欢的音乐风格和常听的歌手,推荐相应的歌曲;
- 在金融行业,根据用户的风险喜好和投资经验,推荐相应的理财产品。
在这,我强烈推荐你用 JSON 类型在数据库中存储用户画像信息,并结合 JSON 数组类型和多值索引的特点进行高效查询。假设有张画像定义表:
CREATE TABLE Tags (
tagId bigint auto_increment,
tagName varchar(255) NOT NULL,
primary key(tagId)
);
SELECT * FROM Tags;
+-------+--------------+
| tagId | tagName |
+-------+--------------+
| 1 | 70后 |
| 2 | 80后 |
| 3 | 90后 |
| 4 | 00后 |
| 5 | 爱运动 |
| 6 | 高学历 |
| 7 | 小资 |
| 8 | 有房 |
| 9 | 有车 |
| 10 | 常看电影 |
| 11 | 爱网购 |
| 12 | 爱外卖 |
+-------+--------------+可以看到,表 Tags 是一张画像定义表,用于描述当前定义有多少个标签,接着给每个用户打标签,比如用户 David,他的标签是 80 后、高学历、小资、有房、常看电影;用户 Tom,90 后、常看电影、爱外卖。若不用 JSON 数据类型进行标签存储,通常会将用户标签通过字符串,加上分割符的方式,在一个字段中存取用户所有的标签:
+-------+---------------------------------------+
|用户 |标签 |
+-------+---------------------------------------+
|David |80后 ; 高学历 ; 小资 ; 有房 ;常看电影 |
|Tom |90后 ;常看电影 ; 爱外卖 |
+-------+---------------------------------------+这样做的缺点是: 不好搜索特定画像的用户,另外分隔符也是一种自我约定,在数据库中其实可以任意存储其他数据,最终产生脏数据。用 JSON 数据类型就能很好解决这个问题:
DROP TABLE IF EXISTS UserTag;
CREATE TABLE UserTag (
userId bigint NOT NULL,
userTags JSON,
PRIMARY KEY (userId)
);
INSERT INTO UserTag VALUES (1,'[2,6,8,10]');
INSERT INTO UserTag VALUES (2,'[3,10,12]');其中,userTags 存储的标签就是表 Tags 已定义的那些标签值,只是使用 JSON 数组类型进行存储。MySQL 8.0.17 版本开始支持 Multi-Valued Indexes,用于在 JSON 数组上创建索引,并通过函数 member of、json_contains、json_overlaps 来快速检索索引数据。所以你可以在表 UserTag 上创建 Multi-Valued Indexes:
ALTER TABLE UserTag
ADD INDEX idx_user_tags ((cast((userTags->"$") as unsigned array)));如果想要查询用户画像为常看电影的用户,可以使用函数 MEMBER OF:
EXPLAIN SELECT * FROM UserTag WHERE 10 MEMBER OF(userTags->"$") \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: UserTag
partitions: NULL
type: ref
possible_keys: idx_user_tags
key: idx_user_tags
key_len: 9
ref: const
rows: 1
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
SELECT * FROM UserTag
WHERE 10 MEMBER OF(userTags->"$");
+--------+---------------+
| userId | userTags |
+--------+---------------+
| 1 | [2, 6, 8, 10] |
| 2 | [3, 10, 12] |
+--------+---------------+
2 rows in set (0.00 sec)如果想要查询画像为 80 后,且常看电影的用户,可以使用函数 JSON_CONTAINS:
EXPLAIN SELECT * FROM UserTag
WHERE JSON_CONTAINS(userTags->"$", '[2,10]')\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: UserTag
partitions: NULL
type: range
possible_keys: idx_user_tags
key: idx_user_tags
key_len: 9
ref: NULL
rows: 3
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
SELECT * FROM UserTag
WHERE JSON_CONTAINS(userTags->"$", '[2,10]');
+--------+---------------+
| userId | userTags |
+--------+---------------+
| 1 | [2, 6, 8, 10] |
+--------+---------------+
1 row in set (0.00 sec)如果想要查询画像为 80 后、90 后,且常看电影的用户,则可以使用函数 JSON_OVERLAP:
EXPLAIN SELECT * FROM UserTag
WHERE JSON_OVERLAPS(userTags->"$", '[2,3,10]')\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: UserTag
partitions: NULL
type: range
possible_keys: idx_user_tags
key: idx_user_tags
key_len: 9
ref: NULL
rows: 4
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
SELECT * FROM UserTag
WHERE JSON_OVERLAPS(userTags->"$", '[2,3,10]');
+--------+---------------+
| userId | userTags |
+--------+---------------+
| 1 | [2, 6, 8, 10] |
| 2 | [3, 10, 12] |
+--------+---------------+
2 rows in set (0.01 sec)2.4.4 JSON使用总结
- 使用 JSON 数据类型,推荐用 MySQL 8.0.17 以上的版本,性能更好,同时也支持 Multi-Valued Indexes;
- JSON 数据类型的好处是无须预先定义列,数据本身就具有很好的描述性;
- 不要将有明显关系型的数据用 JSON 存储,如用户余额、用户姓名、用户身份证等,这些都是每个用户必须包含的数据;
- JSON 数据类型推荐使用在不经常更新的静态数据存储。
2.5 范式准则使用
范式设计是非常重要的理论,是通过数学集合概念来推导范式的过程,在理论上,要求表结构设计必须至少满足三范式的要求。
由于完全是数据推导过程,范式理论非常枯燥,但你只要记住几个要点就能抓住其中的精髓:
- 一范式要求所有属性都是不可分的基本数据项;
- 二范式解决部分依赖;
- 三范式解决传递依赖。
2.5.1 范式设计设计原则
真实的业务场景是工程实现,表结构设计做好以下几点就已经足够:
- 每张表一定要有一个主键(方法有自增主键设计、UUID 主键设计、业务自定义生成主键);
- 消除冗余数据存在的可能。
我想再次强调一下,你不用过于追求所谓的数据库范式准则,甚至有些时候,我们还会进行反范式的设计。
2.5.2 自增主键设计
主键用于唯一标识一行数据,所以一张表有主键,就已经直接满足一范式的要求了。在 01 讲的整型类型中,我提及可以使用 BIGINT 的自增类型作为主键,同时由于整型的自增性,数据库插入也是顺序的,性能较好。但你要注意,使用 BIGINT 的自增类型作为主键的设计仅仅适合非核心业务表,比如告警表、日志表等。真正的核心业务表,一定不要用自增键做主键,主要有 6 个原因:
- 自增存在回溯问题;
- 自增值在服务器端产生,存在并发性能问题;
- 自增值做主键,只能在当前实例中保证唯一,不能保证全局唯一;
- 公开数据值,容易引发安全问题,例如知道地址http://www.example.com/User/10/,很容猜出 User 有 11、12 依次类推的值,容易引发数据泄露;
- MGR(MySQL Group Replication) 可能引起的性能问题;
- 分布式架构设计问题。
自增存在回溯问题,我在 01 讲中已经讲到,如果你想让核心业务表用自增作为主键,MySQL 数据库版本应该尽可能升级到 8.0 版本。又因为自增值是在 MySQL 服务端产生的值,需要有一把自增的 AI 锁保护,若这时有大量的插入请求,就可能存在自增引起的性能瓶颈。比如在 MySQL 数据库中,参数 innodb_autoinc_lock_mode 用于控制自增锁持有的时间。假设有一 SQL 语句,同时插入 3 条带有自增值的记录:
INSERT INTO ... VALUES (NULL,...),(NULL,...),(NULL,...);则参数 innodb_autoinc_lock_mode 的影响如下所示:

从表格中你可以看到,一条 SQL 语句插入 3 条记录,参数 innodb_autoinc_lock_mode 设置为 1,自增锁在这一条 SQL 执行完成后才释放。如果参数 innodb_autoinc_lock_mode 设置为2,自增锁需要持有 3 次,每插入一条记录获取一次自增锁。
- 这样设计好处是: 当前插入不影响其他自增主键的插入,可以获得最大的自增并发插入性能。
- 缺点是: 一条 SQL 插入的多条记录并不是连续的,如结果可能是 1、3、5 这样单调递增但非连续的情况。
所以,如果你想获得自增值的最大并发性能,把参数 innodb_autoinc_lock_mode 设置为2。虽然,我们可以调整参数 innodb_autoinc_lock_mode获得自增的最大性能,但是由于其还存在上述 5 个问题。因此,在互联网海量并发架构实战中,我更推荐 UUID 做主键或业务自定义生成主键。
UUID主键设计:UUID(Universally Unique Identifier)代表全局唯一标识 ID。显然,由于全局唯一性,你可以把它用来作为数据库的主键。MySQL 数据库遵循 DRFC 4122 命名空间版本定义的 Version 1规范,可以通过函数 UUID自动生成36字节字符。
业务自定义生成主键:UUID 虽好,但是在分布式数据库场景下,主键还需要加入一些额外的信息,这样才能保证后续二级索引的查询效率(具体这部分内容将在后面的分布式章节中进行介绍)。现在你只需要牢记:分布式数据库架构,仅用 UUID 做主键依然是不够的。 所以,对于分布式架构的核心业务表,我推荐类似如下的设计,比如:
PK = 时间字段 + 随机码(可选) + 业务信息1 + 业务信息2 ......电商业务中,订单表是其最为核心的表之一,你可以先打开淘宝 App,查询下自己的订单号,可以查到类似如下的订单信息:
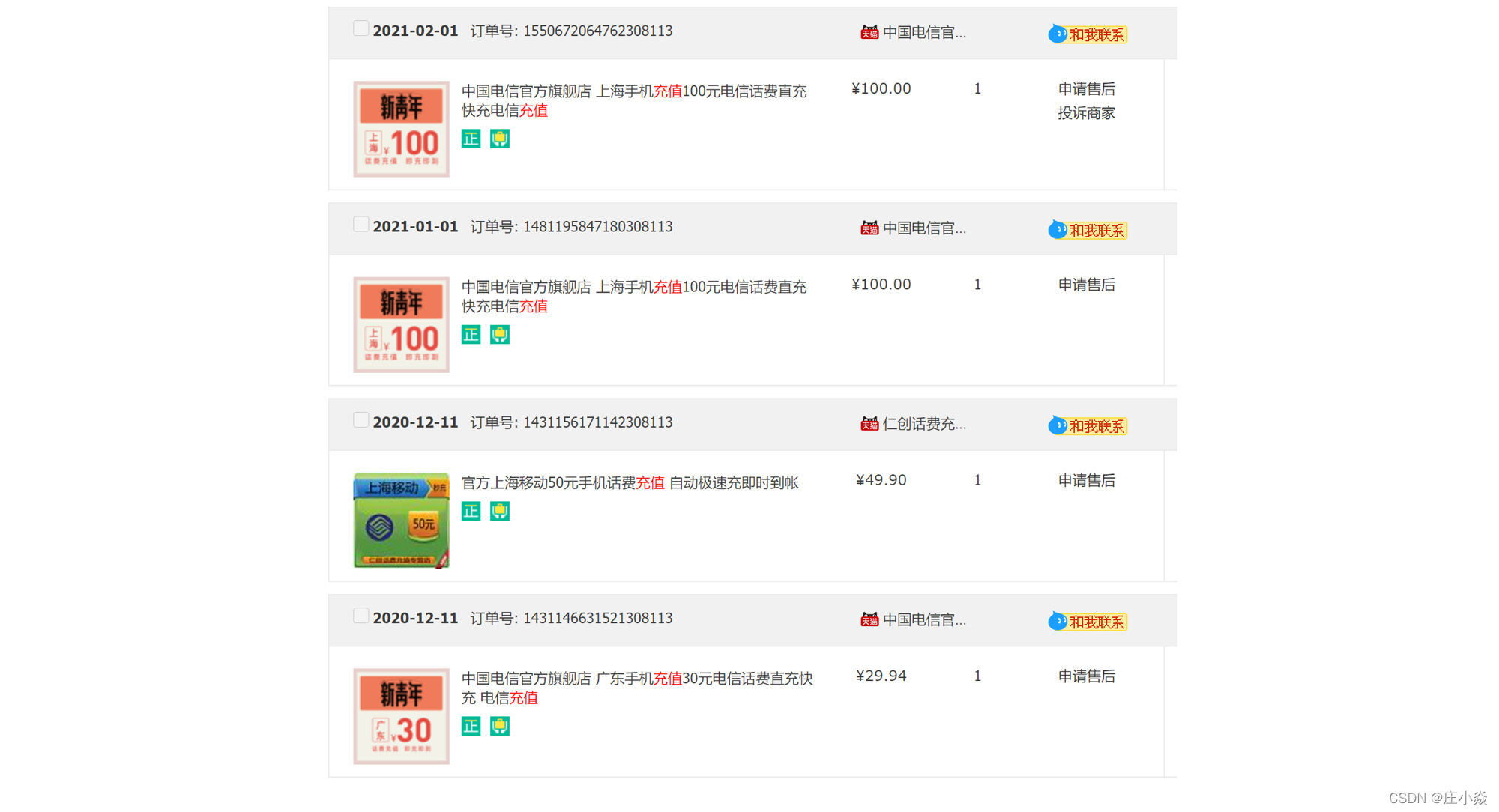
订单号显然是订单表的主键,但如果你以为订单号是自增整型,那就大错特错了。因为如果你仔细观察的话,可以发现图中所有订单号的后 6 位都是相同的,都为308113:所以,我认为淘宝订单号的最后 6 位是用户 ID 相关信息,前 14 位是时间相关字段,这样能保证插入的自增性,又能同时保留业务的相关信息作为后期的分布式查询。
消除冗余:消除冗余也是范式的要求,解决部分依赖和传递依赖,本质就是尽可能减少冗余数据。所以,在进行表结构设计时,数据只需存放在一个地方,其他表要使用,通过主键关联存储即可。比如订单表中需要存放订单对应的用户信息,则保存用户 ID 即可:
CREATE TABLE Orders (
order_id VARCHRA(20),
user_id BINARY(16),
order_date datetime,
last_modify_date datetime
...
PRIMARY KEY(order_id),
KEY(user_id,order_date)
KEY(order_date),
KEY(last_modify_date)
)当然了,无论是自增主键设计、UUID主键设计、业务自定义生成主键、还是消除冗余,本质上都是遵循了范式准则。但是在一些其他业务场景下,也存在反范式设计的情况。
反范式设计:通常我们会在 OLAP 数据分析场景中使用反范式设计,但随着 JSON 数据类型的普及,MySQL 在线业务也可以进行反范式的设计。就是通过 JSON 数据类型进行了反范式的设计,如果通过范式设计,则表 UserTag 应该设计为:
CREATE TABLE UserTag (
userId BIGINT NOT NULL,
userTag INT NOT NULL,
PRIMARY KEY(userId,userTag)
);2.5.3 范式设计设计总结
总的来说,范式是偏数据库理论范畴的表结构设计准则,在实际的工程实践上没有必要严格遵循三范式要求,在 MySQL 海量并发的工程实践上,表结构设计应遵循这样几个规范:
- 每张表一定要有一个主键;
- 自增主键只推荐用在非核心业务表,甚至应避免使用;
- 核心业务表推荐使用 UUID 或业务自定义主键;
- 一份数据应尽可能保留一份,通过主键关联进行查询,避免冗余数据;
- 在一些场景下,可以通过 JSON 数据类型进行反范式设计,提升存储效率;
2.6 表压缩原理
很多同学不会在表结构设计之初就考虑存储的设计,只有当业务发展到一定规模才会意识到问题的严重性。而物理存储主要是考虑是否要启用表的压缩功能,默认情况下,所有表都是非压缩的。但一些同学一听到压缩,总会下意识地认为压缩会导致 MySQL 数据库的性能下降。这个观点说对也不对,需要根据不同场景进行区分。
2.6.1 表压缩
数据库中的表是由一行行记录(rows)所组成,每行记录被存储在一个页中,在 MySQL 中,一个页的大小默认为 16K,一个个页又组成了每张表的表空间。
通常我们认为,如果一个页中存放的记录数越多,数据库的性能越高。这是因为数据库表空间中的页是存放在磁盘上,MySQL 数据库先要将磁盘中的页读取到内存缓冲池,然后以页为单位来读取和管理记录。一个页中存放的记录越多,内存中能存放的记录数也就越多,那么存取效率也就越高。若想将一个页中存放的记录数变多,可以启用压缩功能。此外,启用压缩后,存储空间占用也变小了,同样单位的存储能存放的数据也变多了。
若要启用压缩技术,数据库可以根据记录、页、表空间进行压缩,不过在实际工程中,我们普遍使用页压缩技术,
- 压缩每条记录: 因为每次读写都要压缩和解压,过于依赖 CPU 的计算能力,性能会明显下降;另外,因为单条记录大小不会特别大,一般小于 1K,压缩效率也并不会特别好。
- 压缩表空间: 压缩效率非常不错,但要求表空间文件静态不增长,这对基于磁盘的关系型数据库来说,很难实现。
而基于页的压缩,既能提升压缩效率,又能在性能之间取得一种平衡。
可能很多同学认为,启用表的页压缩功能后,性能有明显损失,因为压缩需要有额外的开销。的确,压缩需要消耗额外的 CPU 指令,但是压缩并不意味着性能下降,或许能额外提升性能,因为大部分的数据库业务系统,CPU 的处理能力是剩余的,而 I/O 负载才是数据库主要瓶颈。借助页压缩技术,MySQL 可以把一个 16K 的页压缩为 8K,甚至 4K,这样在从磁盘写入或读取时,就能将 I/O 请求大小减半,甚至更小,从而提升数据库的整体性能。当然,压缩是一种平衡,并非一定能提升数据库的性能。这种性能“平衡”取决于解压缩开销带来的收益和解压缩带来的开销之间的一种权衡。但无论如何,压缩都可以有效整理数据原本的容量,对存储空间来说,压缩的收益是巨大的。
2.6.2 MySQL 压缩表设计
COMPRESS 页压缩:COMPRESS 页压缩是 MySQL 5.7 版本之前提供的页压缩功能。只要在创建表时指定ROW_FORMAT=COMPRESS,并设置通过选项 KEY_BLOCK_SIZE 设置压缩的比例。需要牢记的是, 虽然是通过选项 ROW_FORMAT 启用压缩功能,但这并不是记录级压缩,依然是根据页的维度进行压缩。
下面这是一张日志表,ROW_FROMAT 设置为 COMPRESS,表示启用 COMPRESS 页压缩功能,KEY_BLOCK_SIZE 设置为 8,表示将一个 16K 的页压缩为 8K。
CREATE TABLE Log (
logId BINARY(16) PRIMARY KEY,
......
)
ROW_FORMAT=COMPRESSED
KEY_BLOCK_SIZE=8COMPRESS 页压缩就是将一个页压缩到指定大小。如 16K 的页压缩到 8K,若一个 16K 的页无法压缩到 8K,则会产生 2 个压缩后的 8K 页,具体如下图所示:

总的来说,COMPRESS 页压缩,适合用于一些对性能不敏感的业务表,例如日志表、监控表、告警表等,压缩比例通常能达到 50% 左右。虽然 COMPRESS 压缩可以有效减小存储空间,但 COMPRESS 页压缩的实现对性能的开销是巨大的,性能会有明显退化。主要原因是一个压缩页在内存缓冲池中,存在压缩和解压两个页。
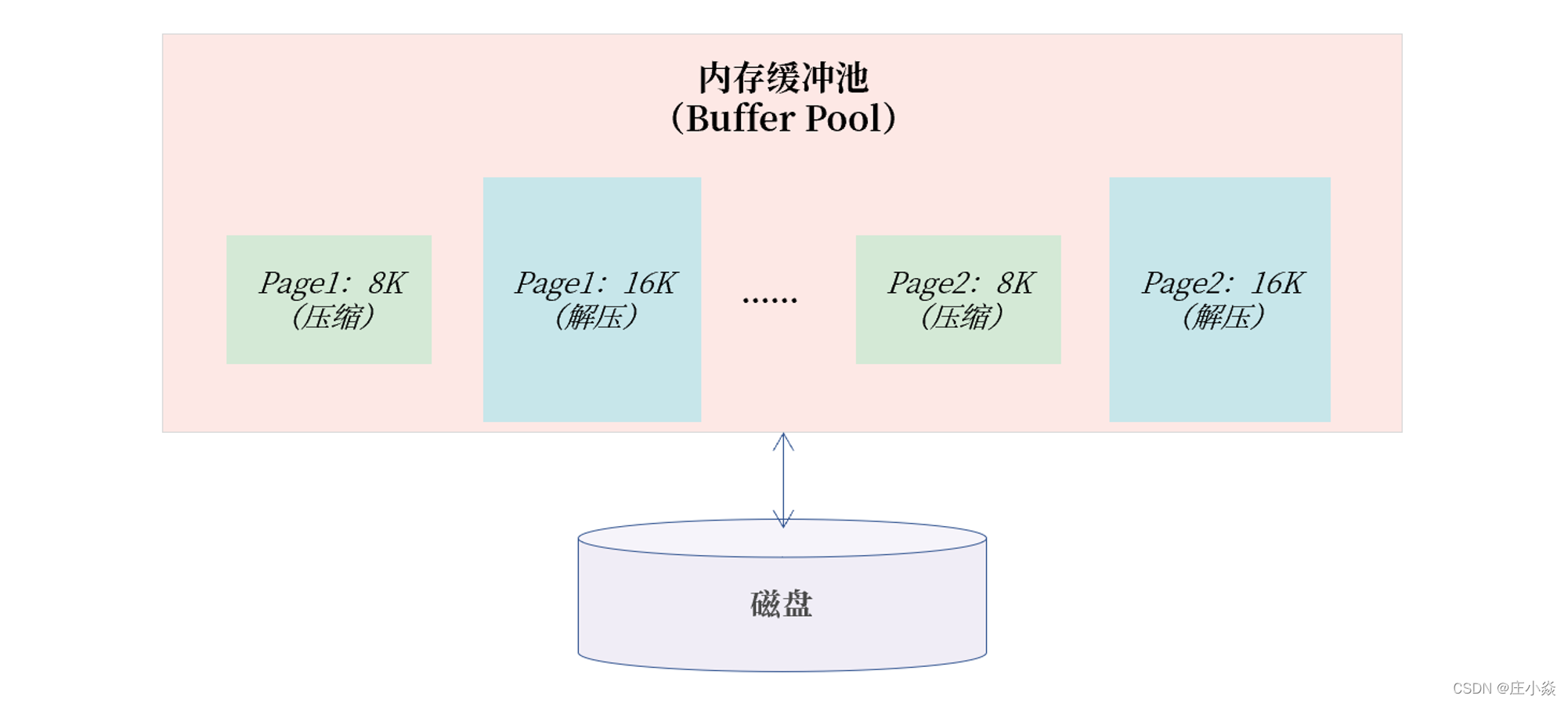
如图所示,Page1 和 Page2 都是压缩页 8K,但是在内存中还有其解压后的 16K 页。这样设计的原因是 8K 的页用于后续页的更新,16K 的页用于读取,这样读取就不用每次做解压操作了。很明显,这样的实现会增加对内存的开销,会导致缓存池能存放的有效数据变少,MySQL 数据库的性能自然出现明显退化。为了 解决压缩性能下降的问题,从MySQL 5.7 版本开始推出了 TPC 压缩功能。
2.6.3 TPC 压缩
TPC(Transparent Page Compression)是 5.7 版本推出的一种新的页压缩功能,其利用文件系统的空洞(Punch Hole)特性进行压缩。可以使用下面的命令创建 TPC 压缩表:
CREATE TABLE Transaction (
transactionId BINARY(16) PRIMARY KEY,
.....
)
COMPRESSION=ZLIB | LZ4 | NONE;要使用 TPC 压缩,首先要确认当前的操作系统是否支持空洞特性。通常来说,当前常见的 Linux 操作系统都已支持空洞特性。由于空洞是文件系统的一个特性,利用空洞压缩只能压缩到文件系统的最小单位 4K,且其页压缩是 4K 对齐的。比如一个 16K 的页,压缩后为 7K,则实际占用空间 8K;压缩后为 3K,则实际占用空间是 4K;若压缩后是 13K,则占用空间依然为 16K。
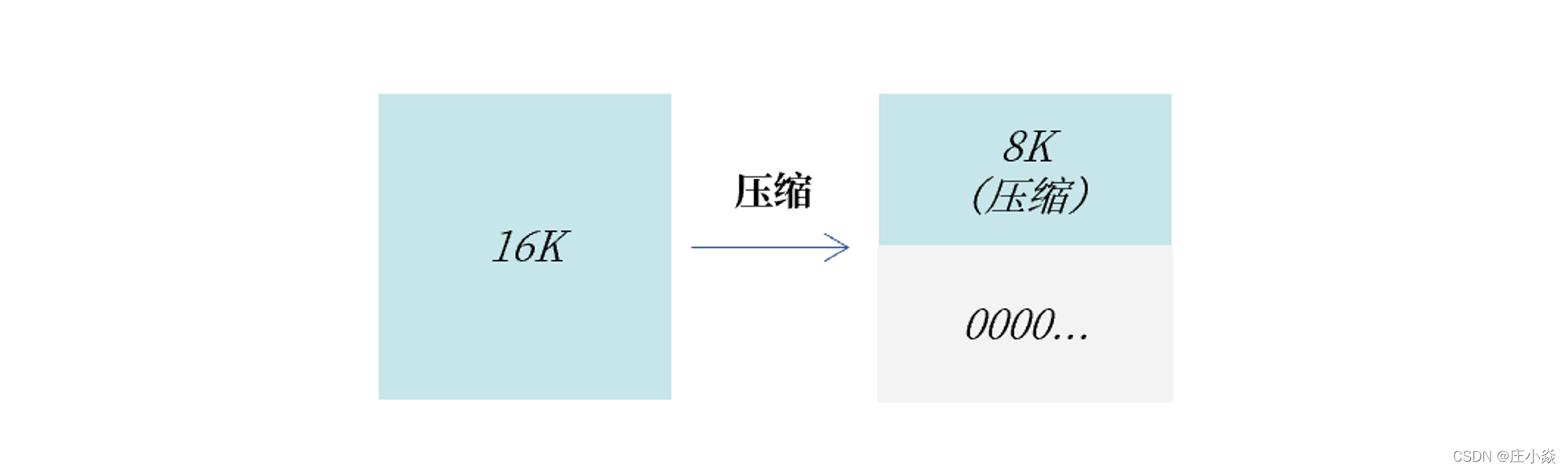
上图可以看到,一个 16K 的页压缩后是 8K,接着数据库会对这 16K 的页剩余的 8K 填充0x00,这样当这个 16K 的页写入到磁盘时,利用文件系统空洞特性,则实际将仅占用 8K 的物理存储空间。空洞压缩的另一个好处是,它对数据库性能的侵入几乎是无影响的(小于 20%),甚至可能还能有性能的提升。这是因为不同于 COMPRESS 页压缩,TPC 压缩在内存中只有一个 16K 的解压缩后的页,对于缓冲池没有额外的存储开销。另一方面,所有页的读写操作都和非压缩页一样,没有开销,只有当这个页需要刷新到磁盘时,才会触发页压缩功能一次。但由于一个 16K 的页被压缩为了 8K 或 4K,其实写入性能会得到一定的提升。

上图是 MySQL 官方的 LinkBench 测试结果,可以看到,无压缩的测试结果为 13,432 QPS,传统的 COMPRESS 页压缩性能下降为 10,480 QPS,差不多30%的性能下降。基于TPC压缩的测试结果为 18,882,在未压缩的基础上还能有额外 40% 的性能提升。
2.6.3 表压缩在业务上的使用
总的来说,对一些对性能不敏感的业务表,例如日志表、监控表、告警表等,它们只对存储空间有要求,因此可以使用 COMPRESS 页压缩功能。在一些较为核心的流水业务表上,我更推荐使用 TPC压缩。因为流水信息是一种非常核心的数据存储业务,通常伴随核心业务。如一笔电商交易,用户扣钱、下单、记流水,这就是一个核心业务的微模型。所以,用户对流水表有性能需求。此外,流水又非常大,启用压缩功能可更为有效地存储数据。
若对压缩产生的性能抖动有所担心,我的建议:由于流水表通常是按月或天进行存储,对当前正在使用的流水表不要启用 TPC 功能,对已经成为历史的流水表启用 TPC 压缩功能,如下所示:
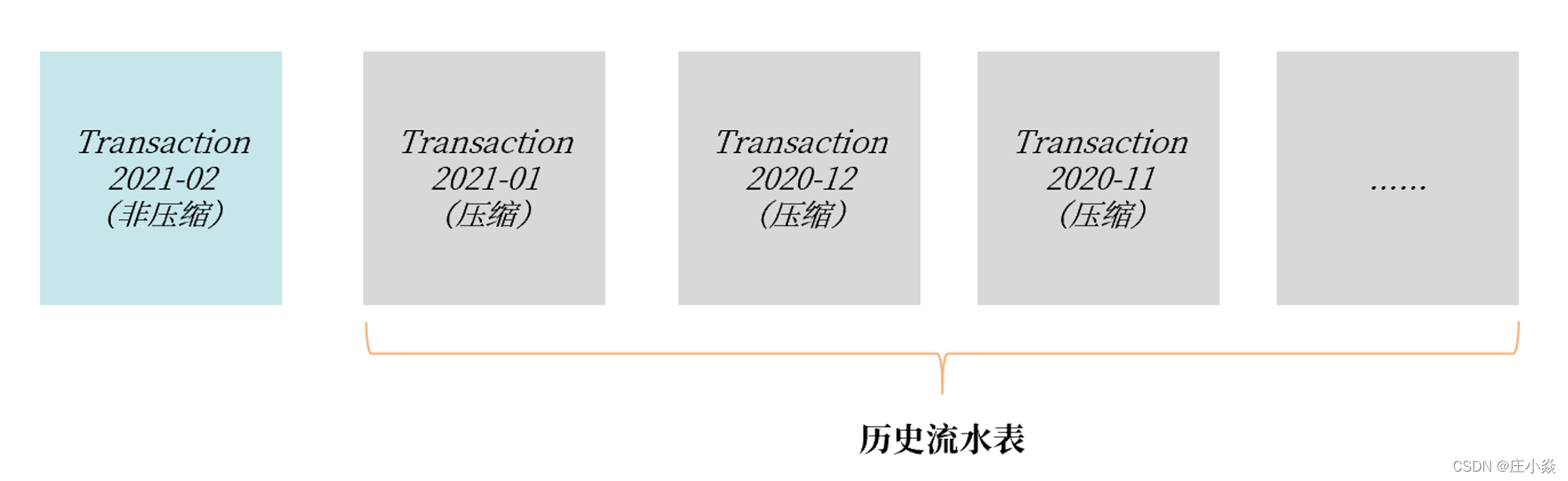
需要特别注意的是: 通过命令 ALTER TABLE xxx COMPRESSION = ZLIB 可以启用 TPC 页压缩功能,但是这只对后续新增的数据会进行压缩,对于原有的数据则不进行压缩。所以上述ALTER TABLE 操作只是修改元数据,瞬间就能完成。若想要对整个表进行压缩,需要执行 OPTIMIZE TABLE 命令:
ALTER TABLE Transaction202102 COMPRESSION=ZLIB;
OPTIMIZE TABLE Transaction202102;2.6.4 表压缩总结
在进行表结构设计时,除了进行列的选择外,还需要考虑存储的设计,特别是对于表的压缩功能的设计,总结来说:
- MySQL 中的压缩都是基于页的压缩;
- COMPRESS 页压缩适合用于性能要求不高的业务表,如日志、监控、告警表等;
- COMPRESS 页压缩内存缓冲池存在压缩和解压的两个页,会严重影响性能;
- 对存储有压缩需求,又希望性能不要有明显退化,推荐使用 TPC 压缩;
- 通过 ALTER TABLE 启用 TPC 压缩后,还需要执行命令 OPTIMIZE TABLE 才能立即完成空间的压缩
2.7 表的访问设计原则
但从 MySQL 5.6 版本开始,就支持除 SQL 外的其他访问方式,比如 NoSQL,甚至可以把 MySQL 打造成一个百万级并发访问的 KV 数据库或文档数据库。
2.7.1 MySQL 中表的访问方式
SQL 是访问数据库的一个通用接口,虽然数据库有很多种,但数据库中的 SQL 却是类似的,因为 SQL 有标准存在,如 SQL92、SQL2003 等。虽然有些数据库会扩展支持 SQL 标准外的语法,但 90% 的语法是兼容的,所以,不同数据库在 SQL 层面的学习成本是比较低的。也因为上述原因,从一种关系型数据库迁移到另一种关系型数据库,开发的迁移成本并不高。比如去 IOE,将 Oracle 数据库迁移到 MySQL 数据库,通常 SQL 语法并不是难题。MySQL 8.0 版本前,有不少同学会吐槽 MySQL 对于 SQL 标准的支持的程度。但是在当前 8.0 版本下,MySQL 对于 SQL 语法的支持度已经越来越好,甚至在某些方面超过了商业数据库 Oracle。

上图是专家评估的不同数据库对 SQL 的支持程度,可以看到,MySQL 8.0 在这一块非常完善,特别是对 JSON_TABLE 的支持功能。通常来说,MySQL 数据库用于 OLTP 的在线系统中,不用特别复杂的 SQL 语法支持。但 MySQL 8.0 完备的 SQL 支持意味着 MySQL 未来将逐渐补齐在 OLAP 业务方面的短板,让我们一起拭目以待。
当前 MySQL 版本中支持的不同表的访问方式:
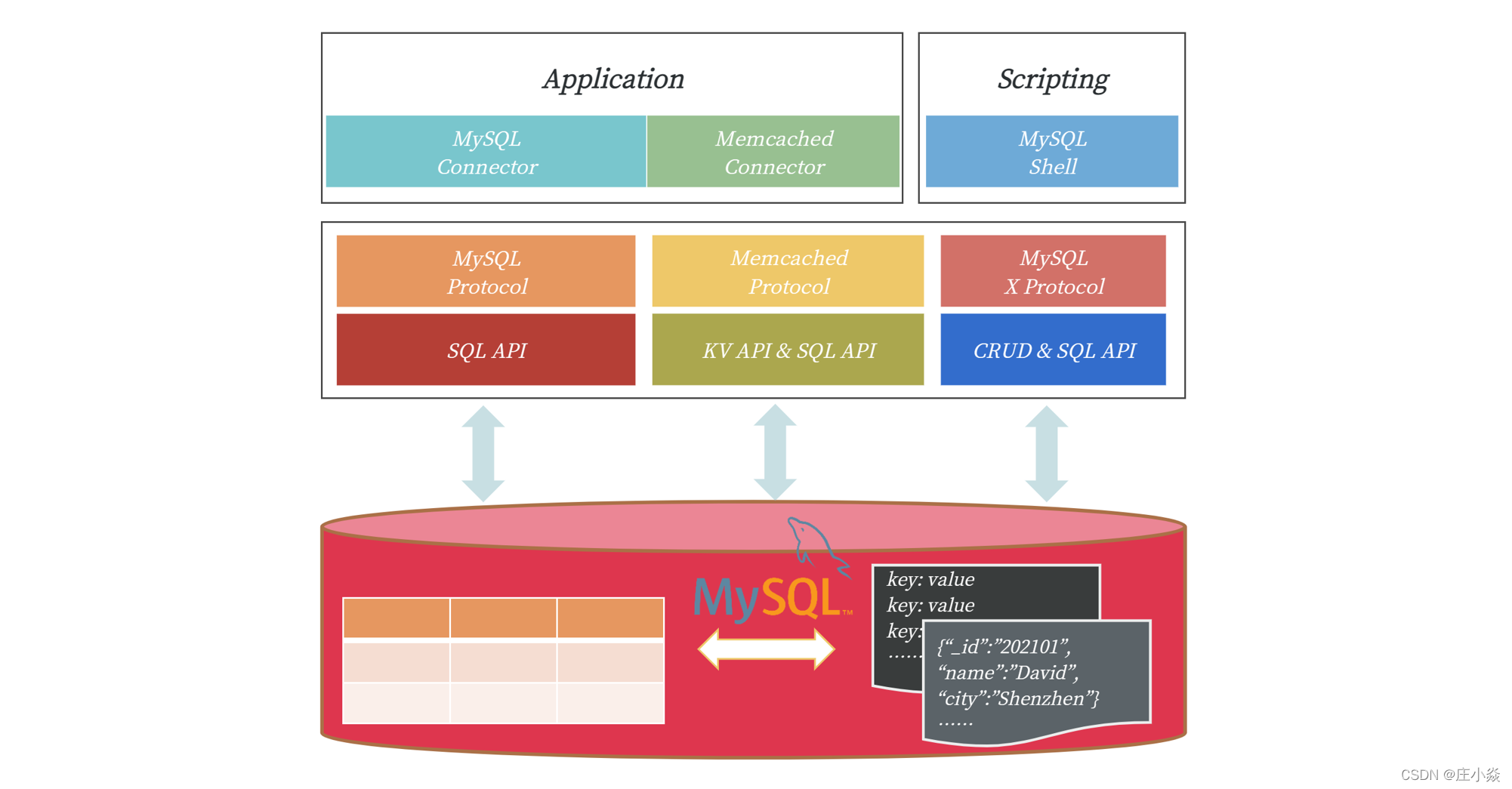
可以看到,除了标准的 SQL 访问,MySQL 5.6 版本开始还支持通过 Memcached 通信协议访问表中的数据,这时 MySQL 可以作为一个 KV 数据库使用。此外,MySQL 5.7 版本开始还支持通过新的 MySQL X 通信协议访问表中的数据,这时 MySQL 可以作为一个文档数据库使用。但无论哪种 NoSQL 的访问方式,其访问的数据都是以表的方式进行存储。SQL 和 NoSQL 之间通过某种映射关系进行绑定。对比传统的 NoSQL 数据库(比如 Memcached、MongoDB),MySQL 这样的访问更具有灵活性,在通过简单的 NoSQL 接口保障性能的前提下,又可以通过 SQL 的方式丰富对于数据的查询。另外,MySQL 提供的成熟事务特性、高可用解决方案,又能弥补 NoSQL 数据库在这方面的不足。
2.7.2 通过 Memcached 协议访问表
MySQL 5.6 版本开始支持通过插件 Memcached Plugin,以 KV 方式访问表,这时可以将 MySQL视作一个 Memcached KV 数据库。对于数据的访问不再是通过 SQL 接口,而是通过 KV 数据库中常见的 get、set、incr 等请求。
但为什么要通过 KV 的方式访问数据呢?因为有些业务对于数据库的访问本质上都是一个 KV 操作。比如用户登录系统,大多是用于信息确认,这时其 SQL 大多都是通过主键或唯一索引进行数据的查询,如:
SELECT * FROM User WHERE PK = ?若在海量并发访问的系统中,通过 SQL 访问这些表,由于通过主键索引进行访问,速度很快。但 SQL 解析(哪怕是软解析)却要耗费不少时间,这时单数据库实例性能会受到一定的限制。基于 Memcached 的 KV 访问,可以绕过 SQL 解析,通过映射关系,直接访问存储在 InnoDB 引擎中的数据,这样数据库的整体性能会在不花费额外成本的前提下得到极大的提升。
那么要启用 Memcached 协议访问 MySQL 需要做两件事情:
- 开启 Memcached 插件;
- 配置表与 KV 的映射关系。
-- 安装映射表
mysql> source MYSQL_HOME/share/innodb_memcached_config.sql
-- 安装插件,默认会启动11211端口
mysql> INSTALL PLUGIN daemon_memcached soname "libmemcached.so";执行完上述操作后,会新增一个库 innodb_memcache,里面的表 containers 就是需要配置的KV映射表。如果业务常见的主键查询 SQL 如下,其中列 user_id 是主键:
SELECT user_id,cellphone,last_login
FROM test.User
WHERE user_id = ?那么我们可以在表 Containers 中插入一条记录:
INSERT INTO containers
VALUES ('User','test','user_id','user_id|cellphone|last_login','0','0','0','PRIAMRY')上面的映射关系表示通过 Memcached 的 KV 方式访问,其本质是通过 PRIAMRY 索引访问 key 值,key 就是 user_id,value 值返回的是由列 user_id、cellphone、last_login 组合而成,分隔符为"|"的字符串。
最后,通过 SQL 和 KV 的对比性能测试,可以发现通过 KV 的方式访问,性能要好非常多,在我的测试服务器上结果如下所示:
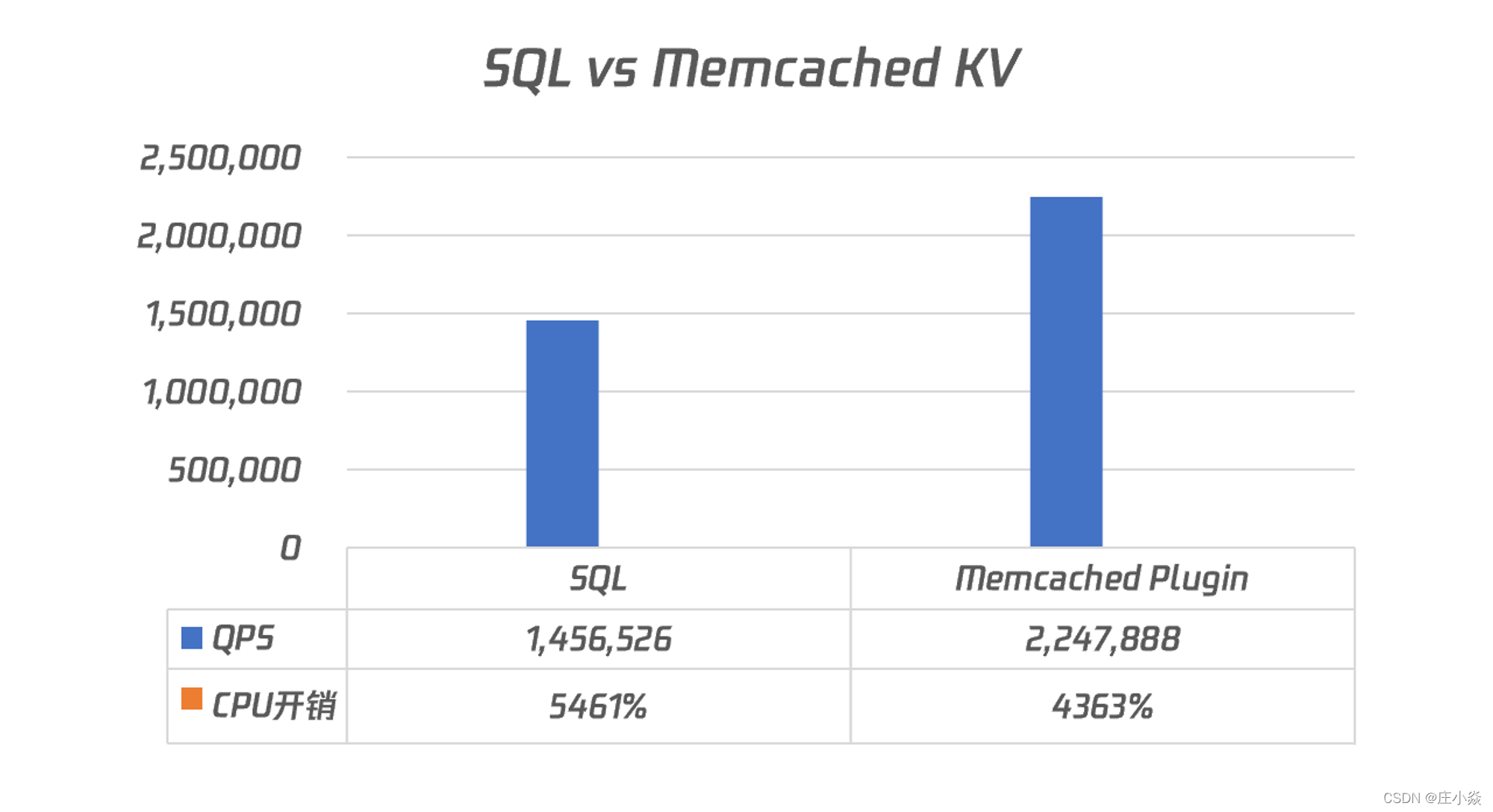
从测试结果可以看到,基于 Memcached 的 KV 访问方式比传统的 SQL 方式要快54.33%,而且CPU 的开销反而还要低20%。
当然了,上述操作只是将表 User 作为 KV 访问,如果想将其他表通过 KV 的方式访问,可以继续在表 Containers 中进行配置。但是在使用时,务必先通过 GET 命令指定要访问的表:
另一种使用 Memcached Plugin 的场景是原先使用原生 Memcached KV 数据库的用户。这些用户可以考虑将 Memcached 数据库迁移到 MySQL 。这样的好处是:
- 通过 MySQL 进行访问的性能比原生 Memcached 好,数据库并发优化做得更好;
- 存储可以持久化,支持事务,数据一致性和安全性更好;
- 利用 MySQL 复制技术,可以弥补原生 Memcached 不支持数据复制的短板;
2.7.3 通过 X Protocol 访问表
MySQL 5.7 版本开始原生支持 JSON 二进制数据类型,同时也提供将表格映射为一个 JSON 文档。同时,MySQL 也提供了 X Protocol 这样的 NoSQL 访问方式,所以,现在我们 MySQL 打造成一个SQL & NoSQL的文档数据库。对比 MongoDB 文档数据库,将 MySQL 打造为文档数据库与 MongoDB 的对比在于:

可以看到,除了 MySQL 目前还无法支持数据分片功能外,其他方面 MySQL 的优势会更大一些,特别是 MySQL 是通过二维表格存储 JSON 数据,从而实现文档数据库功能。这样可以通过 SQL 进行很多复杂维度的查询,特别是结合 MySQL 8.0 的 CTE(Common Table Expression)、窗口函数(Window Function)等功能,而这在 MongoDB 中是无法原生实现的。
另外,和 Memcached Plugin 不同的是,MySQL 默认会自动启用 X Plugin 插件,接着就可以通过新的 X Protocol 协议访问 MySQL 中的数据,默认端口 33060,你可以通过下面命令查看有关 X Plugin 的配置:
mysql> SHOW VARIABLES LIEK '%mysqlx%';
+-----------------------------------+--------------------+
| Variable_name | Value |
+-----------------------------------+--------------------+
| mysqlx_bind_address | * |
| mysqlx_compression_algorithms |
DEFLATE_STREAM,LZ4_MESSAGE,ZSTD_STREAM |
| mysqlx_connect_timeout | 30 |
| mysqlx_document_id_unique_prefix | 0 |
| mysqlx_enable_hello_notice | ON |
| mysqlx_idle_worker_thread_timeout | 60 |
| mysqlx_interactive_timeout | 28800 |
| mysqlx_max_allowed_packet | 67108864 |
| mysqlx_max_connections | 100 |
| mysqlx_min_worker_threads | 2 |
| mysqlx_port | 33060 |
| mysqlx_port_open_timeout | 0 |
| mysqlx_read_timeout | 30 |
| mysqlx_socket | /tmp/mysqlx.sock |
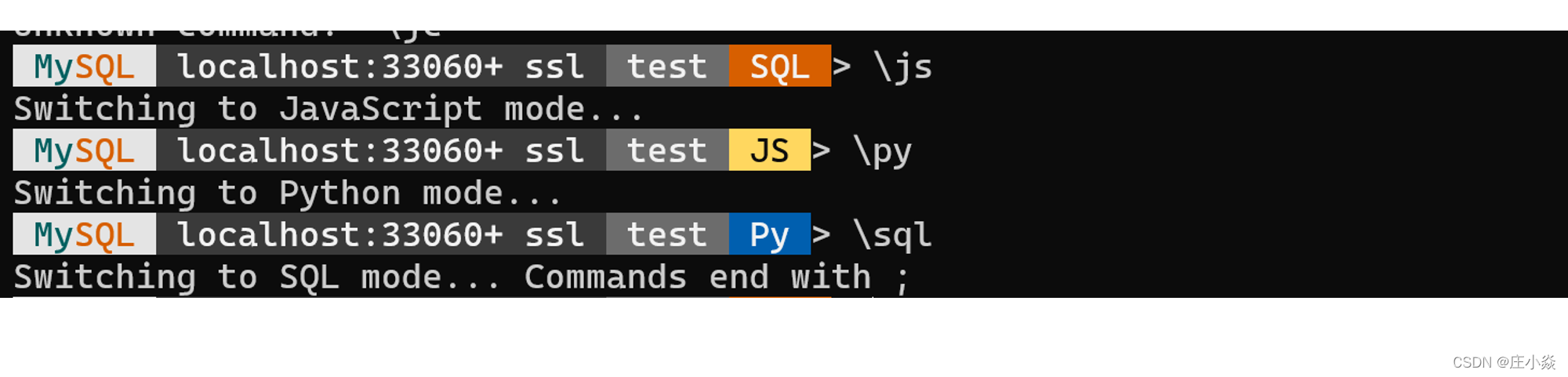
......要通过 X Protocol 管理 MySQL 需要通过新的 MySQL Shell 命令,默认并不安装,需要单独安装。下载地址:https://dev.mysql.com/downloads/shell/。安装后就可以通过命令 mysqlsh 通过新的 X Protocol 访问 MySQL 数据库:
root@MBP-Windows:# mysqlsh root@localhost/testX Protocol 协议支持通过 JS、Python、SQL 的方式管理和访问 MySQL,具体操作你可以参见官方文档。
博文参考

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 16
16 1
1- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)