mysql为什么要用b+树
mysql为什么要用b+树
mysql为什么要用b+树
先看原因:
1.B+树减少了IO次数,效率更高
(这里这么理解:-----就是减少了磁盘的访问次数,毕竟内存速度要比磁盘快的多)
2.B+树查询跟稳定,因为所有数据放在叶子节点
3.B+树范围查询更好,因为叶子节点指向下一个叶子结点
介绍
一般查询一堆数据会使用到的数据结构是:哈希表、B+树。mysql使用的是B+树。
B+树是通过二叉查找树,再由平衡二叉树(B-树)演变而来。
但B+树不是二叉树
科普:什么叫二叉树
- ⾮叶⼦节点最多拥有两个⼦节点
- ⾮叶⼦节值⼤于左边⼦节点、⼩于右边⼦节点
- 没有值相等重复的节点;
二叉树如图:
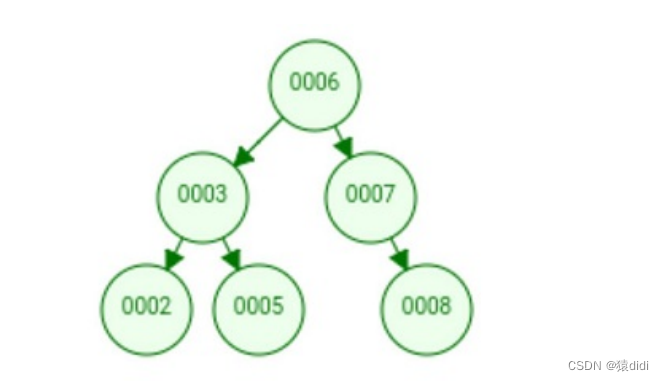
比如:你想找到008,先和006比对,008大于006,则和007比对,一次类推。每一次比对都能排除一半的数据,是不是效率比较高。
既然二叉树查询效率比较高,那为啥还需引进平衡二叉树呢?
那是因为二叉树会有一种极端的情况:
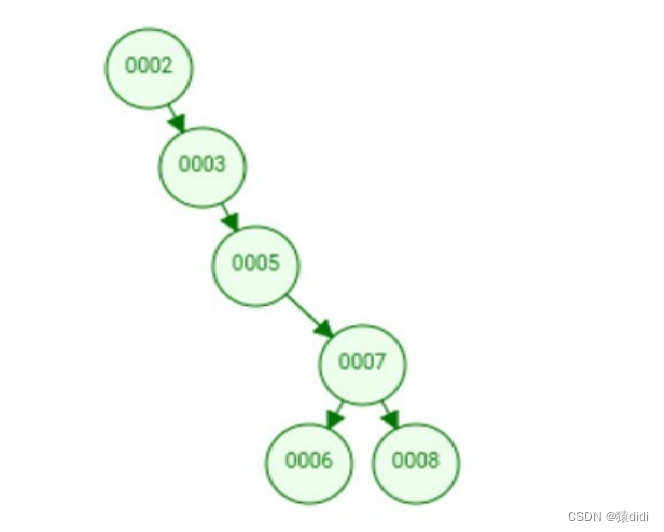
这个也是满足二叉树的极端情况,你想找到0008的,则必须经过4次比对。效率低下!
平衡二叉树则是在二叉树的条件下多了一个限制条件:树的左右两边的层级数相差不会⼤于1
这样就不会让二叉树处于一条线的极端情况了。
平衡⼆叉树的查找效率确实很快,但维护⼀颗平衡⼆叉树的代价是⾮常⼤的,需要1次或多次左旋和右旋来得到插
⼊或更新后树的平衡性。
那么又问题来了,既然平衡二叉树查询效率这么高了,为什么还需要引入B树和B+树呢???
B树和B+树
B树和B-树是同⼀种树,假如⽤平衡⼆叉树实现索引效率已经很⾼了,查找⼀个节点所做的IO次数是这个节点所处
的树的⾼度,因为我们⽆法把整个索引都加载到内存,并且节点数据在磁盘中不是顺序排放的。所以最快情况下,
磁盘的IO次数为数的高度。虽然平衡⼆叉树查找效率确实很⾼,但是频繁的IO才是阻碍提⾼性能的瓶颈,怎样减少IO次数呢?前辈们很聪明的提出了局部性原理,分为时间局部性原理,即加⼊你查询id为1的⽤户数据,过⼀段时间你还会查询id为1的数据,所以会将这部分数据缓存下来。空间局部性原理,当你查询id为1的⽤户数据的时候,你有很⼤的概率会去查询id为2,3,4的⽤户的数据,所以会⼀次性的把id为1,2,3,4的数据都读到内存中去,这个最小的单位就是页。
简单来说CPU进行运算是电⼦运动,计算速度很快。而将数据从硬盘读取到内存中是机械运动,很慢。我们在买硬盘的时候经常问这个硬盘是多少转(每分钟转动的圈数),7200转,5400转。所以说转动的越快加载数据越快,但是和CPU比起来差的还很远,所以说要减低IO次数。
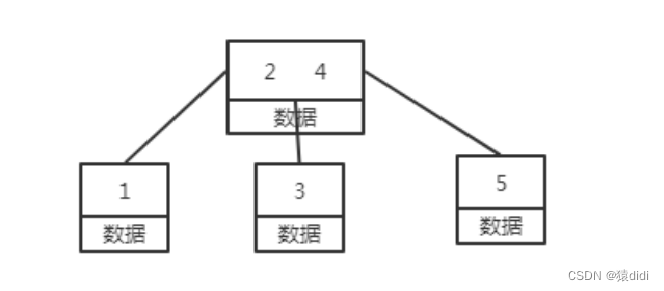
B树:
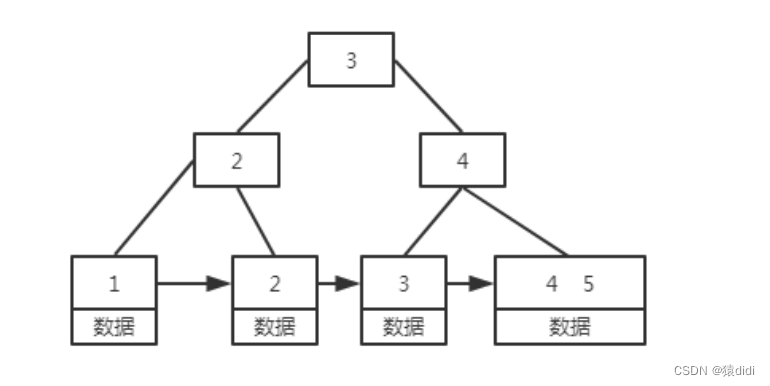
b+树:
B+树和B树由什么区别?
1.B+树的的非叶子节点只存储索引,叶子节点存储数据(所以B+树能存储更多的索引,并且查询次数也是一样的)
2.B+树每个叶子节点都包含了根节点的键值数据,每个叶子节点的关键字从小到大链
在B树的基础上每个节点存储的关键字数更多,树的层级更少所以查询数据更快,所有关键字指针都存在叶⼦节 点,所以每次查找的次数都相同所以查询速度更稳定。 除此之外,B+树的叶⼦节点是跟后序节点相连接的,这对范围查找是⾮常有⽤的。 看到没B+树的⾮叶⼦节点是主键,主键占⽤的空间越⼩,每个节点能放的主键就能更多,这就是为什么我们的主键 ⼀般不设置太⼤的原因。主键占⽤的空间⼩,能降低树⾼,减少IO次数
未完待续~~~

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)