9.MongoDB之explain(执行计划分析)
对executionStats返回逐层分析第一层,executionTimeMillis最为直观explain返回值是executionTimeMillis值,指的是我们这条语句的执行时间,这个值当然是希望越少越好。其中有3个executionTimeMillis,分别是:executionStats.executionTimeMillis该query的整体查询时间。executionStats.
一、前言
mongodb提供db.collection.explain()、cursort.explain()获取查询计划及查询计划统计信息。利用explain命令,我们可以很好的观察系统如何使用索引来加快检索,同时可以做针对性的性能优化。可以作用的命名有:aggregate, count, distinct, find, findAndModify, delete, mapReduce, update等。
1、两种语法格式与可选参数verbosity
到MongoDB4.4版本,db.collection.explain()支持的方法已经和explain相同,推荐这种。
官网的说明如下:
db.collection.explain() #推荐
db.collection.explain() — MongoDB Manual
cursor.explain()
cursor.explain() — MongoDB Manual
(1)db.collection.explain()语法格式—— 推荐
#语法格式
db.collection.explain()
#使用举例
db.coll_0.explain().remove({key:"2852354899_3000000000100596",chan:54,time:{"$lte":1696941720269347,"$gte":1696933326656511}})
db.coll_1.explain().count({key:"2852354899_3000000000100596",chan:54,time:{"$lte":1696941720269347,"$gte":1696933326656511}})
db.coll_0.explain("executionStats").find({key:"2852354899_3000000000100596",chan:54,time:{"$lte":1696941720269347,"$gte":1696933326656511}})
(2)cursor.explain()格式
#格式如下
db.collection.find().explain()
#使用举例
#命令行语句.explain("pattern") //
db.test.find({index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",systime:1600000001000000}).explain("executionStats")db.mkt_track_detail_560.aggregate([ { $match: { kfuin: 2885772560, sa_list: { $in: [ "2_+8613266776354", "4_8643975168", "3_wxe232d626118f1acd_oDzMB5R1jrfOc3RXxVlXWcKXJNss", "7_12345@qq.com" ] }, sensor_event: "小程序启动", time: { $gte: 1620252229000000.0 } } }, { $group: { _id: null, count: { $sum: 1 } } } ],{explain:true})
(3)db.collection.explain()方法有一个可选参数:verbosity。
该参数会影响explain()方法的行为和返回信息,可以设置为如下几个值:①queryPlanner(Default)、②executionStats、③allPlansExecution 。
2、三种模式介绍
(0)这里先列出几个非常重要的关键字
重点关注的是COLLSCAN、IXSCAN、keysExamined、docsExamined 等关键字。keysExamined 和 docsExamined 越大代表没有建索引或者索引的区分度不高。请确认索引的创建字段。
1、COLLSCAN:代表该查询进行了全表扫描;
2、IXSCAN:代表进行了索引扫描;
3、keysExamined:代表索引扫描条目;
4、docsExamined:代表文档扫描条目。
(1)queryPlanner
queryPlanner是现版本explain的默认模式。这种模式并不会真正进行query语句查询,而是针对query语句进行执行计划分析并选出winning plan。
"queryPlanner" : {
"mongosPlannerVersion" : <int>,
"winningPlan" : {
"stage" : <STAGE1>,
"shards" : [
{
"shardName" : <string>,
"connectionString" : <string>,
"serverInfo" : {
"host" : <string>,
"port" : <int>,
"version" : <string>,
"gitVersion" : <string>
},
"plannerVersion" : <int>,
"namespace" : <string>,
"parsedQuery" : <document>,
"queryHash" : <hexadecimal string>,
"planCacheKey" : <hexadecimal string>,
"optimizedPipeline" : <boolean>, // Starting in MongoDB 4.2, only appears if true
"winningPlan" : {
"stage" : <STAGE2>,
"inputStage" : {
"stage" : <STAGE3>
...,
}
},
"rejectedPlans" : [
<candidate plan 1>,
...
]
},
...
]
}
}explain.queryPlanner
包含由查询优化器选择的查询计划信息。
explain.queryPlanner.namespace
指明当前查询语句操作的命令空间(i.e.,<database>.<colleciton>)
explain.queryPlanner.indexFilterSet
一个布尔值表名mongodb是否使用 index filter
注:Index filter决定了优化器为query shape所评估的索引(们)。
explain.queryPlanner.queryHash
一个十六进制字符串用于表名query shape的hash,它仅仅取决于query shapes。
explain.queryPlanner.winningPlan
查询优化器针对该query所返回的最优执行计划的详细内容。mongodb将计划呈现为一个阶段树;即,一个阶段可以有一个inputStage,如果一个阶段有多个子阶段就是inputStages。
explain.queryPlanner.winningPlan.stage
阶段名。每个阶段都包含特定于该阶段的信息。例如IXSCAN阶段将包括索引边界以及特定于索引扫描的其他数据。如果一个阶段有一个子阶段或者多个子阶段,则该阶段将有一个或多个inputStage。
explain.queryPlanner.winningPlan.inputStage
描述子阶段的文档,它向其父阶段提供文档或索引键(???)。如果父阶段只有一个子阶段则此字段存在。
explain.queryPlanner.winningPlan.inputStages
描述诸多子阶段的文档数组。子阶段们为父阶段提供文档或索引键。如果父阶段有多个子阶段,则该字段存在。例如, $or expressions 或 index intersection 阶段就会消费来自多个来源的输入。
注:关于索引键这个东西最好还是深入的了解下mongodb的索引实现这块东西。
(2)executionStats
executionStats返回的是获胜计划的执行细节。必须在executionStats或allPlansExcution详细模式下运行的explain才显示相关信息。
"executionStats" : {
"nReturned" : <int>,
"executionTimeMillis" : <int>,
"totalKeysExamined" : <int>,
"totalDocsExamined" : <int>,
"executionStages" : {
"stage" : <STAGE1>
"nReturned" : <int>,
"executionTimeMillis" : <int>,
"totalKeysExamined" : <int>,
"totalDocsExamined" : <int>,
"totalChildMillis" : <NumberLong>,
"shards" : [
{
"shardName" : <string>,
"executionSuccess" : <boolean>,
"executionStages" : {
"stage" : <STAGE2>,
"nReturned" : <int>,
"executionTimeMillisEstimate" : <int>,
...
"chunkSkips" : <int>,
"inputStage" : {
"stage" : <STAGE3>,
...
"inputStage" : {
...
}
}
}
},
...
]
}
"allPlansExecution" : [
{
"shardName" : <string>,
"allPlans" : [
{
"nReturned" : <int>,
"executionTimeMillisEstimate" : <int>,
"totalKeysExamined" : <int>,
"totalDocsExamined" :<int>,
"executionStages" : {
"stage" : <STAGEA>,
"nReturned" : <int>,
"executionTimeMillisEstimate" : <int>,
...
"inputStage" : {
"stage" : <STAGEB>,
...
"inputStage" : {
...
}
}
}
},
...
]
},
{
"shardName" : <string>,
"allPlans" : [
...
]
},
...
]
}explain.executionStats
描述获胜计划(winning plan)完整的查询执行数据。对于写操作,是指讲些执行修改的信息,但是并不会真的修改数据库。
explain.executionStats.nReturned
查询条件匹配到的文档数量。
explain.executionStats.executionTimeMillis
被选择的查询计划所需的总时间(毫秒为单位)。对应于早期版本mongodb中cursor.explain()返回的millis字段。
explain.executionStats.totalKeysExamined
扫描的索引项数(索引扫描条目)。totalKeysExamined 对应于早期版本的cursor.explaom()返回的nscanned字段。
explain.executionStats.totalDocsExamined
扫描的文档数。检查文档常用的查询执行阶段是COLLSCAN和FETCH。
注意:①totalDocsExamined是指检查的文档总数,而不是返回的文档数。②如果在查询执行期间多次检查文档,则totalDocsExamined会对每次检查进行计数。也就是说,totalDocsExamined不是检查的唯一文档总数的计数。
explain.executionStats.executionStages
以阶段树的形式详细说明已完成的获胜计划(winning plan);即一个阶段可以有一个inputStage或者多个inputStages。每个stage都包含特定于该stage的执行信息。
explain.executionStats.executionStages.executionTimeMillisEstimate
查询执行的预估时间(单位毫秒)
explain.executionStats.executionStages.works
表明查询执行stage执行的“work units”数。查询执行将其工作划分为几个小单元。“work units”可能包括检查单个索引键、从集合中获取单个文档、对单个文档应用projection或执行一段内部簿记等。
explain.executionStats.executionStages.advanced
中间结果返回的次数。或者这个stage对其父stage的“advanced”。
explain.executionStats.executionStages.needTime
未将中间结果“advance”到期父stage的工作循环数。例如,索引扫描阶段可能花费一个工作周期来寻找索引中的一个新位置,而不是返回索引键;这个工作周期将会计入needTime而不是advanced。
explain.executionStats.executionStages.needYield
存储层请求查询阶段暂停处理并产生锁的次数。
explain.executionStats.executionStages.saveState
查询阶段挂起处理并保存其当前执行状态的次数,例如为产生锁做准备的次数。
explain.executionStats.executionStages.isEOF
用于表名执行阶段是否已达到流的结尾。true或者1,则执行阶段已达到流的结尾。false或者0,则阶段可能仍有结果要返回。举个例子。考虑一个具有limit的查询,其执行阶段由limit阶段组成,该查询的输入阶段为IXSCAN。如果查询返回的值超过指定的限制,则limit阶段将报告isEOF:1,但其基础IXSCAN阶段将报告isEOF:0。
explain.executionStats.executionStages.inputStage.keysExamined
对于扫描索引的查询执行阶段(例如IXSCAN),keysExamined是索引扫描过程中检查的in-bounds键和out-of-bounds键的总数。如果索引扫描包含单个连续的键范围,则只需要检查边界内的键。如果索引边界由多个键范围组成,则索引扫描执行过程可以检查超出边界的键,以便从一个范围的末尾跳到下一个范围的开头。
考虑以下示例,其中有一个字段x的索引,集合包含100个x值为1到100的文档:
db.keys.find( { x : { $in : [ 3, 4, 50, 74, 75, 90 ] } } ).explain( "executionStats" )查询将扫描键3和4。随后它将扫描键5,检测到它out-of-bounds,然后跳到下一个键50。
继续此过程,查询将扫描键3、4、5、50、51、74、75、76、90和91。键5、51、76和91是仍在检查的out-of-bounds。keysExamined值为10。
explain.executionStats.executionStages.inputStage.docsExamined
指定在查询执行阶段扫描的文档数。用于COLLSCAN阶段,以及从集合中retrieve文档的阶段(例如FETCH)。
explain.executionStats.executionStages.inputStage.seeks
为了完成索引扫描我们不得不为了新位置去寻找索引光标的次数。 版本3.4中的新功能:仅用于索引扫描(IXSCAN)阶段。
explain.executionStats.executionStages.inputStage.allPlansExecution
包含在计划选择阶段为成功计划和拒绝计划捕获的部分执行信息。
(3)allPlansExecution
(4)stage状态分析
那么又是什么影响到了totalKeysExamined和totalDocsExamined?是stage的类型。类型列举如下:
COLLSCAN:全表扫描
IXSCAN:索引扫描
FETCH:根据索引去检索指定document
SHARD_MERGE:将各个分片返回数据进行merge
SORT:表明在内存中进行了排序
LIMIT:使用limit限制返回数
SKIP:使用skip进行跳过
IDHACK:针对_id进行查询
SHARDING_FILTER:通过mongos对分片数据进行查询
COUNT:利用db.coll.explain().count()之类进行count运算
COUNTSCAN:count不使用Index进行count时的stage返回
COUNT_SCAN:count使用了Index进行count时的stage返回
SUBPLA:未使用到索引的$or查询的stage返回
TEXT:使用全文索引进行查询时候的stage返回
PROJECTION:限定返回字段时候stage的返回
对于普通查询,我希望看到stage的组合(查询的时候尽可能用上索引):
Fetch+IDHACK
Fetch+ixscan
Limit+(Fetch+ixscan)
PROJECTION+ixscan
SHARDING_FITER+ixscan
COUNT_SCAN
不希望看到包含如下的stage:
COLLSCAN(全表扫描),SORT(使用sort但是无index),不合理的SKIP,SUBPLA(未用到index的$or),COUNTSCAN(不使用index进行count)
如下这几个链接:
https://blog.csdn.net/devcloud/article/details/99412074
https://docs.mongodb.com/manual/reference/explain-results/
https://mongoing.com/eshu_explain1
https://cloud.tencent.com/developer/article/1509697
二、explain分析的案例
0、分析 这篇文章 中复合索引的顺序对于排序查询生效情况
前言:数据组成也非常重要。如下,time_num越大性能差异越明显,time_num很小的时候性能差异几乎可以忽略。
var coll_name = "coll"
var time_num = 100000
var name_num = 10
var docs =[]
for (var i = 1; i <= time_num ; i++){
for (var j = 1; j <= name_num ; j++){
var str_name = "name_" + (j).toString()
docs.push({name:str_name,time:(i)})
}
}
db.getCollection(coll_name).save(docs)创建如下索引:
db.coll.createIndex({name:1,time:-1})执行如下如何数据组织形式的查询语句,如下:
db.coll.find({name:"name_5"}).sort({name:1,age:-1}).limit(3).explain("executionStats")
db.coll.find({name:"name_5"}).sort({name:-1,age:1}).limit(3).explain("executionStats")
执行不符合属于组织形式的查询,如下:
db.coll.find({name:"name_5"}).sort({name:1,age:1}).limit(3).explain("executionStats")

1、设置与不设置分片的explain分析
在shell命令行贴上如下语句;然后分别往test集合和testunshard集合分别插入如下数据。
对于前者我们按照 mongodb之分片集群_mijichui2153的博客-CSDN博客 中设置分片举例中的案例一对test集合设置分片;但是却不对testunshard开启分片。
注意:对于test集合以kfuin为分片键。
var msg_num = 500000;
var index_num = 1000;
var coll_name = "collection1"
var docs = [];
for (var i = 1; i < msg_num; i++){
var index_name_val = "event_detail_2852199351_wx58b4690f0ab8193f_" + (i%index_num).toString()
docs.push({kfuin:2852119999,index_name:index_name_val,systime:(1600000000000000 + 1000000 * i)})
}
//向test集合插入50万条数据
db.test.save(docs)
db.test.count()
//向testunshard集合插入同样的50万条数据
db.testunshard.save(docs)
db.testunshard.count()验证一:对于分片集群的查询操作带与不带分片键的效果。
结论:对于分片集群执行查询操作的时候带上分片键字段mongos会将请求直接路由到对应分片;如果不带分片字段则请求会扩散到每个分片。完全符合预期
注:分片键字段只要带上就好,测试发现对出现顺序是没要求的。
(1)查询时不带分片键:
db.test.find({index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",systime:1600000001000000}).explain("executionStats")
(2)查询时带分片键字段
db.test.find({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",systime:1600000001000000}).explain("executionStats")
对一个分片集群执行查询操作时带上分片键字段(kfuin)
效果:请求只打到目标分片上去

验证二:带不带分片键对查询效率的影响(注:此处是对kfuin进行的hash分片)
同样上面的两张截图。可以看到对于不带分片键的查询只需要292ms,带上分片键后却需要830毫秒。细查发现对于前者仅仅执行50万次totalDocsExamined,执行0次totalKeysExamined;但是后者则全部都执行了50万次。其中”IXSCAN“阶段耗费了不少时间的,而且可以看到优化选择器是选择了为了创建hash分片而设的那个hash索引。如下。

如果本分片有更多主号的数据是不是就能体现出效果了呢?试一下。为此将kfuin字段换成28521998 继续插入50万条。注:注意这里我是通过db.stats()验证过kfuin为此数值时数据正好位于分片0上了的。
此时前者耗时476ms,其中totalDocsExamined为100万,totalKeysExamined为0;后者耗时为788ms,其中totalDocsExamined和totalKeysExamined依然是50万。
结论:现在在实际场景下一个分片中应该是有N多个主号的数据每个主号下有M条数据;对于不带分片键的查询来说其需要遍历所有N*M条数据,而带了分片键(即使只是hash分片)的请求来说则可以将扫描的数据量将至2*M(综合totalDocsExamined和totalKeysExamined)。所以这里结论就很显然了。对于hash分片,带分片键能显著提高性能。
注意:如果再考虑实际情况另外两个分片依然也有很多数据的情况就知道不带分片键的效果会更差。两点:①另外两个分片的数据量如果大于当前分片则进度会被数据量最大的那个分片拖后腿 ②梁歪两个分片去做这种无用功会影响集群整体的吞吐量。
问题:有没有更好的方式来提升整体性能呢?
分析:对于带有分片键的查询我们发现命中的"kfuin_hashed"这个索引;前面分析过了,这是合理的。不过针对我们的业务场景我们可以尝试建立针对性的索引,例如再建一个{kfuin:1,index_name:1}的复合索引。
db.test.createIndex({kfuin:1,index_name:1})然后我们再执行查询。发现:
①不带分片键的查询耗时472ms,其中totalDocsExamined为100万,totalKeysExamined为0;仔细观察没有命中任何索引。
②带分片键的查询:"executionTimeMillis" : 5, "totalKeysExamined" : 500, "totalDocsExamined" : 500,显然有了质的飞跃;再仔细观察发现其命中了新建的复合索引,堪称完美。
验证三:继续上面。查询字段顺序是否与(复合)索引字段顺序一致会影响索引的命中吗?
验证方法很简单。执行下面两条指令对比效果。
结论:测试下来是没有影响的。经过观察explain在IXSCAN阶段的输出可以看到其依然能匹配到我们上面创建的复合索引。 其实也可以理解,mongos完全可以针对你的这种情况匹配到对应索引。
db.test.find({index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",kfuin:2852119999,systime:1600000001000000}).explain("executionStats")
db.test.find({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",systime:1600000001000000}).explain("executionStats")
验证四:继续上面。如果仅有复合索引的后缀字段(无前缀字段)还能命中目标复合索引吗?
结论:仅有index_name字段的情况下就不会命中{kfuin:1,index_name:1}这个复合索引,其查询测试又退化到单纯的集合扫描了。"executionTimeMillis" : 475,"totalKeysExamined" : 0, "totalDocsExamined" : 1000001。
db.test.find({index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",systime:1600000001000000}).explain("executionStats")验证五:继续上面。仅有kfuin前缀字段会命中{kfuin:1,index_name:1}复合索引吗?
答:经过验证可以命中这个复合索引,而且请求也只是打到分片0。 "executionTimeMillis" : 1603, "totalKeysExamined" : 499999, "totalDocsExamined" : 499999。但是因为测试数据的原因,耗时显得有些太长了。
db.test.find({kfuin:2852119999,systime:1600000001000000}).explain("executionStats")验证六:有必要验证下是否对被用于范围查询的字段建索引对性能的影响——结论:肯定是有用的啦!
1、首先验证下对单个范围字段systime在$gt/$lt操作下的性能情况。建立索引会如何?
注意:这里实际上又分为两种情况,一种是不指定排序、一种是指定排序(sort)。两者完全不一样。
注:上述测试数据systime字段的取值为1600000000000000~1600500000000000
1.1、不指定排序
db.test.find({kfuin:2852119999,systime:{$gt:1600000013000000}}).limit(2).explain("executionStats")
分析:如下左图可以看到速度非常的快,文档遍历数和索引遍历数都非常的少。请注意 在没有执行排序的情况下其语义是:“找到任意两条systime大于 1600000013000000 的即可;注意是任意两条是否最紧挨着比较数值都不关心。”显然这不是我们想要的!!!
因此这情况并不是我们实际应用的场景。留在这里是给大家提个醒,即“指定排序和不指定排序完全是两个不同的概念”。


1.2、指定排序
查询指令如下。这个时候的语义是:“查询大于1600000013000000的数据按照升序排列然后取前两条(即我们期望的是返回systime为1600000014000000/1600000015000000的两条数据,而不是随便大于比较数值的两条)。” 果然查询速度感官可见的慢了好多个数量级。见上右图。
db.test.find({kfuin:2852119999,systime:{$gt:1600000013000000}}).limit(2).sort({systime:1}).explain("executionStats")
1.3、对systime建立一个单字段的索引看看是否有效果
//对systime字段建立单字段索引
db.test.createIndex({systime:1})
//check下确实建立ok
db.test.getIndexes()然后再执行上面一样的带有排序的查询语句。肉眼可见的快。如下图 :
db.test.find({kfuin:2852119999,systime:{$gt:1600000013000000}}).limit(2).sort({systime:1}).explain("executionStats")

结论:对于经常被用于比较操作(gt/lt)的字段(一般字段值及其分散)建立索引也是有用的,能极大的提升查找效率。
1.4、用一个能命中{kfuin,index_name}这个复合索引的查询语句,同时也带上对systime的比较操作。看看能不能同时命中复合索引和systime字段的单字段索引。
查询语句如下。见下图,从结果上看只是命中了{kfuin,index_name}这个复合索引,并没有说同时命中两个索引。(这里猜测:一次请求最多只能命中一个索引)。文档扫描数为500恰好是满足{kfuin,index_name}后的所有记录条数(500000/1000=500),也就是说{kfuin,index_name}复合索引生效后将范围缩小至500条数据,然后mongo遍历了所有的这500条数据。
db.test.find({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",systime:{$gt:1600000000000000}}).limit(2).sort({systime:1}).explain("executionStats")

结论:就测试来看不会说完美命中复合索引后,对缩小范围后数据再命中systime单字段索引的说法。也就是说如果想进一步提升性能的话可能需要建立{kfuin,index_name,systime}三字段的复合索引,而不是{kfuin,index_name}两字段复合索引+systime单字段索引。
2、验证下{kfuin:1,index_name:1,systime:1}三字段索引是不是能进一步提升性能。
//首先将systime的单字段索引删了
db.test.dropIndex("systime_1")
//然后把{kfuin:1,index_name:1}的双字段复合索引也删了
db.test.dropIndex("kfuin_1_index_name_1")
//然后建立{kfuin:1,index_name:1,systime:1}的三字段复合索引
db.test.createIndex({kfuin:1,index_name:1,systime:1})
//确认无误
db.test.getIndexes()重复执行1.4的操作,效果如下:
db.test.find({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",systime:{$gt:1600000000000000}}).limit(2).sort({systime:1}).explain("executionStats")
结论:对于经常被用于比较操作(gt/lt)的字段(一般字段值及其分散)建立索引同样能极大的提升效率;
结论:不要想着mongo会智能到帮你命中一个复合索引后再命中一个单字段索引,这只是你的一厢情愿。建立与查询语句全字段匹配的索引能更进一步的提升查询效率。
验证七:在上述查询语句的基础上新增一个session_id字段的匹配会怎样?
1、首先看下我们选中用来测试的数据
db.test.find({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1"}).count()
500
db.test.find({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1"})
//数据如下:
{ "_id" : ObjectId("6075858edc709741eac38ce7"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600000001000000 }
{ "_id" : ObjectId("60758592dc709741eac390cf"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600001001000000 }
{ "_id" : ObjectId("60758597dc709741eac394b7"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600002001000000 }
{ "_id" : ObjectId("6075859cdc709741eac3989f"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600003001000000 }
{ "_id" : ObjectId("607585a1dc709741eac39c87"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600004001000000 }
{ "_id" : ObjectId("607585a5dc709741eac3a06f"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600005001000000 }
{ "_id" : ObjectId("607585aadc709741eac3a457"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600006001000000 }
{ "_id" : ObjectId("607585afdc709741eac3a83f"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600007001000000 }
{ "_id" : ObjectId("607585b3dc709741eac3ac27"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600008001000000 }
2、保持不设置session_id字段看看执行效果
#注意session_id字段的前后顺序对查询没有任何影响
db.test.find({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",session_id:"session_id",systime:{$gt:1600000000000000}}).limit(2).sort({systime:1}).explain("executionStats")
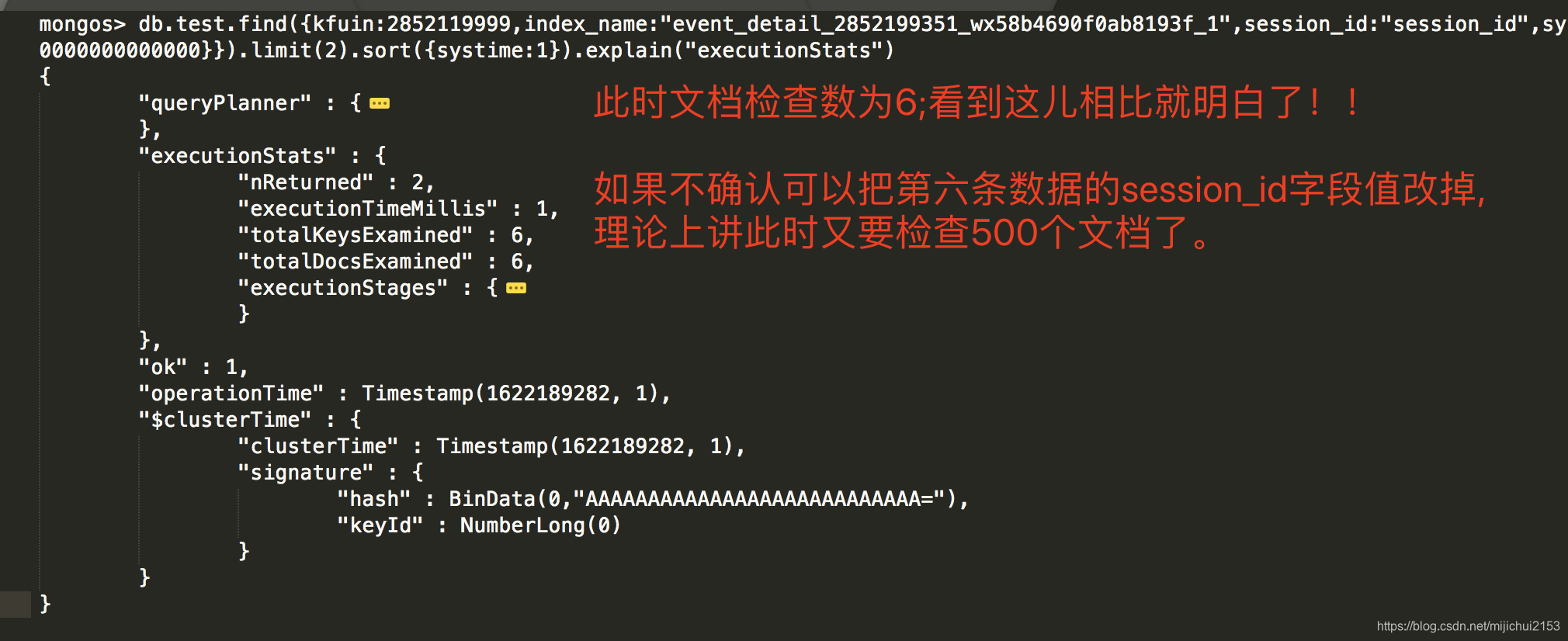
2、我们给其中的第5、6条数据设置session_id字段使之满足session_id的匹配条件
#给第五条数据设置session_id字段
db.test.update({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1","systime":1600004001000000},{$set:{session_id:"session_id"}})
#给第六条数据设置session_id字段
db.test.update({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1","systime":1600005001000000},{$set:{session_id:"session_id"}})
#此时数据如下:
mongos> db.test.find({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1"})
{ "_id" : ObjectId("6075858edc709741eac38ce7"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600000001000000 }
{ "_id" : ObjectId("60758592dc709741eac390cf"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600001001000000 }
{ "_id" : ObjectId("60758597dc709741eac394b7"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600002001000000 }
{ "_id" : ObjectId("6075859cdc709741eac3989f"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600003001000000 }
{ "_id" : ObjectId("607585a1dc709741eac39c87"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600004001000000, "session_id" : "session_id" }
{ "_id" : ObjectId("607585a5dc709741eac3a06f"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600005001000000, "session_id" : "session_id" }
{ "_id" : ObjectId("607585aadc709741eac3a457"), "kfuin" : 2852119999, "index_name" : "event_detail_2852199351_wx58b4690f0ab8193f_1", "systime" : 1600006001000000 }此时执行上述查询语句。explain结果见上右图:
db.test.find({kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",session_id:"session_id",systime:{$gt:1600000000000000}}).limit(2).sort({systime:1}).explain("executionStats")总结:这里想捞取的数据条件是{kfuin:2852119999,index_name:"event_detail_2852199351_wx58b4690f0ab8193f_1",session_id:"session_id",systime:{$gt:1600000000000000}}.limit(2).sort(systime:1);翻译过来就是满足kfuin、index_name固定值、systime大于某值、session_id也固定值的两条数据,且是systime从小打到排序的前两条。①根据explain可知该请求命中了{kfuin:1,index_name:1,systime:1}这个复合索引;②即查询条件中新增session_id字段并不会影响命中该复合索引 ③不考虑session_id字段,满足上述条件的数据有500条 ④考虑到又要匹配session_id的值,mongo就会对于{kfuin:1,index_name:1,systime:1}索引得到的500条数据(注意:这500条数据是从小到大严格有序的)依次匹配session_id值;如果提前匹配到了就提前返回,直至遍历完这个500条数据。至此,就一目了然了。
继续分析:对于包含session_id的查询场景复合索引{kfuin:1,index_name:1,systime:1}满足高效搜索的要求吗?如果不满足的话要怎么办??
先说一下这个问题的背景。目前对于所存的数据可能会有两种查询方式。查询一:指定(kfuin,index_name,systime)来查询;查询二:指定(kfuin,index_name,session_id,systime)来查询。
注意:对于索引字段,出现的前后顺序非常重要;对于查询语句则不关心。
保持现状会怎样?经过前面的分析我们知道仅依赖{kfuin:1,index_name:1,systime:1}三字段索引的话实际上会对满足这个三个条件的所有数据(n)进行遍历,虽然说有可能提前找到满足条件的数据,但其期望复杂度依然是O(n)。至此。结论一:三字段索引不能满足需求。
优化索引的话要如何优化?根据目前情况来看可以建立一个四字段复合索引,如下为systime和session_id字段个不相同时的测试结果。显然我么想要2、3的效果,但这需要建立两个索引。
| 序号 | 索引 | 查询 | 效果 |
| 1 | 仅{kfuin:1,index_name:1,systime:1,session_id:1} | 带session_id | 文档检查数为1,索引检查数为501,耗时3ms。 |
| 2 | 仅{kfuin:1,index_name:1,systime:1,session_id:1} | 不带session_id | 索引检查数为2,文档检查数为2,耗时0ms。 |
| 3 | 仅{kfuin:1,index_name:1,session_id:1,systime:1} | 带session_id | 文档检查数为1,索引检查数为1,耗时1ms。 |
| 4 | 仅{kfuin:1,index_name:1,session_id:1,systime:1} | 不带session_id | 索引检查数为501,文档检查数为500,耗时1ms。 |
验证八、消息记录存储索引验证
关于消息记录存储其模型如下,我们这里是ToB的业务,这里主要记录测试历程,背景就不做过多介绍了:
| sacc | 字典序较小的社交号 |
| bacc | 字典序较大的社交号 |
| time | |
| chan | ??? |
| msg | |
| day |
该模型无非支持三类查询 ①某账号对的消息记录拉取 ②某账号对的日历卡拉取 ③某账号对特定类型消息的查询。分别对应如下三个索引:
{sacc:1,bacc:1,time:1} #应对所有账号对的拉取
{sacc:1,bacc:1,day:1} #日历卡拉取(可有可无)
{sacc:1,bacc:1,sort:1,time:1} #应对账号对的图片筛选
现在面临的挑战是qd业务场景中有主号通路和工号通路的消息,这两个通路的消息最终都落在两个qq号上;但是企点的业务却要对这两个通路做区分。即有时候是只拉取主号通路的消息,有时候又只拉取工号通路的消息。与此同时,也还要求能支持账号对对主、工号通路消息的完整拉取。这意味着要引入chan字段了。
1.验证点 {sacc:1,bacc:1,chan:1,time:1}索引对find{sacc:"",bacc:"",time:{"$gt":123456}}.sort({time:1})是否完美生效。
分析:对于上述查询语句 {sacc:1,bacc:1,time:1} 索引肯定是能完美生效的;我们就验证有chan的这个索引是否也能完美起作用。
2.造数据
/*
数据集如下:
account1有account1_num个取值,范围为(2852000000 ~ 2852000000+account1_num);
account2有account2_num个取值,范围为(726045513175435_{0~account2_num});
每个账号对有 couple_acc_msg_num 条消息;消息时间为 1600000000 开始没10秒发送一条;
对于每个账号对的 couple_acc_msg_num 条消息间隔性的氛围三份;一份chan为1、一份chan为2、一份无chan;
每个账号对的时间范围为1600000000没10秒一条,持续发couple_acc_msg_num条
注:对于下述场景消息时间范围为 1600000000~1600300000(1600000000+30000*10)
*/
account1_beg = 2852000000
account1_num = 10
account2_prefix = "726045513175435"
account2_num = 10
couple_acc_msg_num = 30000
for (var acc1 = account1_beg; acc1 < account1_beg+account1_num; acc1++){
var docs = [];
for (var acc2_index = 0; acc2_index < account2_num; acc2_index++){
account1 = acc1.toString();
account2 = account2_prefix + "_" + acc2_index.toString()
for (var msg_num = 0; msg_num < couple_acc_msg_num; msg_num ++){
var time_sec = 1600000000 + msg_num*10
if (msg_num % 3 == 0){
docs.push({sacc:account1,bacc:account2,chan:1,time:time_sec})
}else if(msg_num %3 == 1){
docs.push({sacc:account1,bacc:account2,chan:2,time:time_sec})
}else{
docs.push({sacc:account1,bacc:account2,time:time_sec})
}
}
}
db.coll2.save(docs)
print("finish ",account1)
}case1:没有索引 —— 遍历全部300万条数据
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")case2:建立{sacc:1,bacc:1,chan:1,time:1}索引
db.coll2.createIndex({sacc:1,bacc:1,chan:1,time:1})
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")
case3:建立{sacc:1,bacc:1,time:1}索引
注:在上述两个索引都存在的情况下果断命中 {sacc:1,bacc:1,time:1};达到最理想效果。
db.coll2.createIndex({sacc:1,bacc:1,time:1})
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")case4:移除前面索引,建立{sacc:1,bacc:1,time:1,chan:1}索引
db.coll2.dropIndex("sacc_1_bacc_1_time_1")
db.coll2.dropIndex("sacc_1_bacc_1_chan_1_time_1")
db.coll2.createIndex({sacc:1,bacc:1,time:1,chan:1})
#显然对于如下查询效率非常高 2ms 6 6
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")

case5: 和case4索引保持一致,验证过滤条件包括chan的效果
#再看看指定chan字段的查询如何 1ms 18 6
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",chan:1,time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")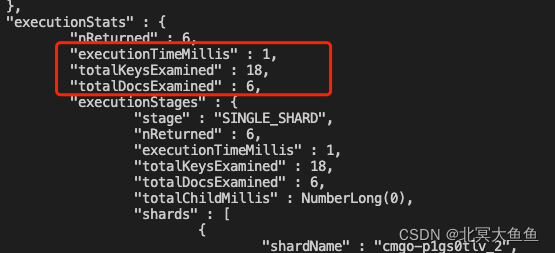
case6:case5的索引和仅有{sacc:1,bacc:1,time:1}效果应该差不多吧—— 多一个chan还是有作用的。
db.coll2.dropIndex("sacc_1_bacc_1_time_1_chan_1")
db.coll2.createIndex({sacc:1,bacc:1,time:1})
db.coll2.find({sacc:"2852000005",bacc:"726045513175435_5",chan:1,time:{"$gte":1600100000}}).sort({time:1}).limit(6).explain("executionStats")效果如下。就测试结果来看还是有点区别的。多一个chan字段至少能在降低DocsExamined上有作用。

3.结论
经测试由于主、工号通路情况的存在,不得不对三种场景都再额外建立一个包含chan字段的索引。索引数由三个变成了六个。注:这个是最完善的索引。
{sacc:1,bacc:1,time:1} #应对所有账号对的拉取
{sacc:1,bacc:1,day:1} #日历卡拉取(可有可无)
{sacc:1,bacc:1,sort:1,time:1} #应对账号对的图片筛选
{sacc:1,bacc:1,chan:1,time:1} #用于区分通路,主要是为了区分主、工号通路
{sacc:1,bacc:1,chan:1,day:1} #用于区分主工号通路的日历卡拉取(可有可无)
{sacc:1,bacc:1,chan:1,sort:1,time:1} #用于区分主、工号通路的图片筛选
再额外加一个查找单条数据和保证幂等性的索引,如下:
{sacc:1,bacc:1,subkey:1} ,{unique:true} #单条数据查找和幂等性保证
另外还要有一个片键索引,如下:
{sacc:1, bacc: "hashed"} #片键索引
分析:关于日历的索引是可以不要的。因为这种场景可以通过time字段限定时间范围(例如就一个月),即使性能没有达到最优,但整体遍历的数据是可控的。最终经过权衡取舍,保留如下6个索引:
{sacc:1, bacc: "hashed"} #片键索引
{sacc:1,bacc:1,time:1} #应对所有账号对的拉取
{sacc:1,bacc:1,sort:1,time:1} #应对账号对的图片筛选
{sacc:1,bacc:1,chan:1,time:1} #用于区分通路,主要是为了区分主、工号通路
{sacc:1,bacc:1,chan:1,sort:1,time:1} #用于区分主、工号通路的图片筛选
{sacc:1,bacc:1,subkey:1} ,{unique:true} #单条数据查找和幂等性保证
继续造数据:这里造了单表过亿的数据。详细分布为:100个主号,每个主号100万条数据;100万条数据里面有1万个cid,每个cid有10通会话,每通会话里面有9条消息。
脚本如下,插入一个主号的100万数据后立马把docs清空,然后再插下一个主号就可以避免kill了。
kfuin_beg = 0
kfuin_end = 100
for(var num = kfuin_beg; num < kfuin_end; num++){
var kfuin_num = num+1;//主号数
var cid_num = 10000 //1万个cid
var session_num = 10//每个cid有10通会话
var detail_num = 9//每个session有9条消息
var docs = [];
for(var i = num; i < kfuin_num; i++){
for(var j = 0; j < cid_num; j++){
for(var k = 0; k < session_num; k++){
var kfuin_val = i + 2852000000
var session_index_name_val = "event_session_" + kfuin_val.toString() + "_wx58b4690f0ab8193f-" + j.toString()
var session_id_val = "session_id" + "_wx58b4690f0ab8193f-" + j.toString() + "_" +(k).toString()
var systime_val = 1600000000000000 + k*1000
docs.push({kfuin:kfuin_val,index_name:session_index_name_val,session_id:session_id_val,systime:systime_val})
for(var h = 0; h < detail_num; h++){
var detail_index_val = "event_detail_" + kfuin_val.toString() + "_wx58b4690f0ab8193f-" + j.toString()
systime_val = 1600000000000000 + k*1000 + h
docs.push({kfuin:kfuin_val,index_name:detail_index_val,session_id:session_id_val,systime:systime_val})
}
}
}
}
db.coll1.save(docs)
}
目前插入1kw条数据,[0,9)。好像得设完分片再插数据,否则不太行。查询语句主要有一下几个:
//1.拉取一级节点
db.coll1.find({kfuin:2852000000,index_name:"event_session_2852000000_wx58b4690f0ab8193f-0",systime:{$gt:1600000000004000}}).sort({systime:1}).limit(3).explain("executionStats")
//2.根据time拉取二级节点
db.coll1.find({kfuin:2852000000,index_name:"event_detail_2852000000_wx58b4690f0ab8193f-0",systime:{$gt:1600000000004000}}).sort({systime:1}).limit(3).explain("executionStats")
//3.根据session_id和time拉取二级节点
db.coll1.find({kfuin:2852000000,index_name:"event_detail_2852000000_wx58b4690f0ab8193f-0",session_id:"session_id_wx58b4690f0ab8193f-0_7",systime:{$gt:1600000000007004}}).sort({systime:1}).limit(3).explain("executionStats")可以比较下建立如下索引前后的执行效率,非常有效:
db.coll1.createIndex({kfuin:1,index_name:1,session_id:1,systime:1})
db.coll1.createIndex({kfuin:1,index_name:1,systime:1})
为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 7
7 1
1- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)