SQL Server 多行合并成一行与一行拆分成多行
多行合并成一行(逗号隔开):原表结构:合并后的结果:建表及插入数据:-- 创建测试用表rows_to_rowcreate table rows_to_row(name char(5) not null default '',hobby varchar(20) not null default '')-- 向测试表添加数据insert into rows_to_rowvalues('张三','aaa
多行合并成一行(逗号隔开):
原表结构:
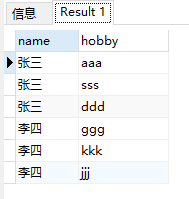
合并后的结果:
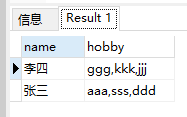
建表及插入数据:
-- 创建测试用表rows_to_row
create table rows_to_row(
name char(5) not null default '',
hobby varchar(20) not null default ''
)
-- 向测试表添加数据
insert into rows_to_row
values
('张三','aaa'),
('张三','sss'),
('张三','ddd'),
('李四','ggg'),
('李四','kkk'),
('李四','jjj');实现合并效果的代码:
select name ,
hobby = ( stuff((select ',' + hobby from rows_to_row where name = Test.name for xml path('')), 1, 1, '') )
from rows_to_row as Test
group by name在解析前,我们要知道SQL Server中语句的逻辑执行顺序(与MySQL中的执行顺序类似),stuff函数和for xml path的用法:
执行顺序可以参考:SqlServer中Sql语句的逻辑执行顺序
stuff函数用法可以参考:SqlServer中 stuff 函数
for xml path的用法可以参考:sql for xml path用法
解析:
首先来看主查询,主查询按照name进行分组,随后select从分组结果中依次查询出name值李四和张三,接着将李四和张三依次传入子查询中,我们用‘张三’来替换子查询中的Test.name,然后单独执行替换后的子查询,并查看其执行结果:
select ','+hobby from rows_to_row where name='张三' for xml path('')
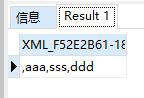
使用stuff函数替换掉上述查询结果中字段值最开始处的逗号:
select STUFF((select ',' + hobby from rows_to_row where name = '张三' for xml path('')), 1, 1, '')
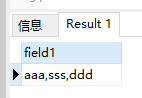
完整查询代码:
select name ,
hobby = ( stuff((select ',' + hobby from rows_to_row where name = Test.name for xml path('')), 1, 1, '') )
from rows_to_row as Test
group by name一行拆分成多行:
原表结构:
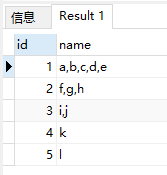
拆分后的结果:
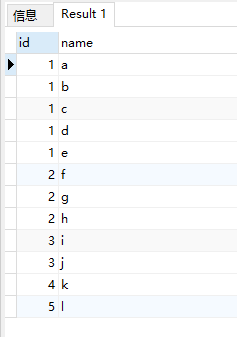
建表及插入数据:
--创建测试表:
create table apply_test(
id int not null default 0,
name varchar(20)
)
-- --向测试表中添加数据
insert into apply_test
values
(1,'a,b,c,d,e'),
(2,'f,g,h'),
(3,'i,j'),
(4,'k'),
(5,'l');实现拆分效果的代码:
select a.id,b.name from
(select id,name=cast('<v>'+replace(name,',','</v><v>')+'</v>' as xml)
from apply_test ) as a
outer apply (select name=T.C.value('.','varchar(20)') from a.name.nodes('v')
as T(C)) as b --其中T是表别名,C指表T中的列在解析前,我们要知道cast函数的用法,outer apply的用法,XQuery中value函数和nodes函数的用法:
cast函数用法可以参考:SQL Server常用函数总结
outer apply用法可以参考:CROSS APPLY和 OUTER APPLY 区别详解
XQuery中value函数和nodes函数的用法可以参考:sqlserver中的CAST()函数
解析:
其中,
--将apply_test中的name列由varchar型转化成xml型
select id,name=cast('<v>'+replace(name,',','</v><v>')+'</v>' as xml) from apply_test查询结果为:
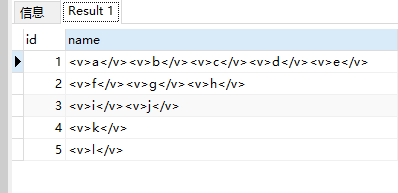
select name=T.C.value('.','varchar(20)') from a.name.nodes('v') as T(C)
的作用是将已经转化成xml类型的name列中的值拆分成多个varchar类型的字母。其中,nodes函数负责将name中的每一个xml值都拆分成多个稍短的xml值,nodes('v')中的'v'是路径表达式;value('.','varchar(20)')中的'.'指定拆分点是当前节点'v','varchar(20)'表示把拆分后的多个xml值转化成最大长度为20的varchar型的字符串。
为便于理解,举一个例子:
declare @x xml
set @x='<v>a</v><v>b</v><v>c</v><v>d</v><v>e</v>'
--查询一:
select T.c.query('.') as result1
FROM @x.nodes('v') T(c)
--查询二:
select name=T.c.value('.','varchar(20)')
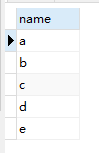
from @x.nodes('v') T(c)查询一结果:
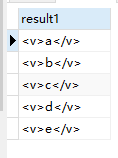
查询二结果:
此外,当outer apply后不跟筛选条件时,a outer apply b的结果就是a和b的笛卡尔积。
所以完整的查询代码为:
select a.id,b.name from
(select id,name=cast('<v>'+replace(name,',','</v><v>')+'</v>' as xml) from apply_test ) as a
outer apply (select name=T.C.value('.','varchar(20)') from a.name.nodes('v') as T(C)) as b 其他参考:
SQL Server 行转列,列转行。多行转成一列_兰博zey的博客-CSDN博客_sql 列转行
SQLServer连接查询之Cross Apply和Outer Apply的区别及用法_Wikey_Zhang的博客-CSDN博客_outapply

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)