flink基本介绍
一、flink介绍1、flink是什么?1、flink是一个面向流处理和批处理的分布式计算框架,即支持流处理,也支持批处理。2、flink基于流处理引擎实现,正真做到了流处理,将批处理看作一种特殊的有界流3、flink是基于java编程语言实现,支持java,scala,python进行编程开发4、flink支持单机执行,或运行在大数据的yarn集群,或部署到k8s中执行二、flink特点1、fl
·
一、flink介绍
1、flink是什么?
flink是一个面向流处理和批处理的分布式计算框架,即支持流处理,也支持批处理。
flink基于流处理引擎实现,正真做到了流处理,将批处理看作一种特殊的有界流
flink是基于java编程语言实现,支持java,scala,python进行编程开发
flink支持单机执行,或运行在大数据的yarn集群,或部署到k8s中执行
二、flink特点
支持有状态计算的Extactor-once语义及checkpoint
支持带有事件操作的流处理和窗口处理
支持灵活的窗口处理(时间,大小等多种窗口)
轻量级容错处理(使用savepoint进行错误恢复)
高吞吐,低延迟,高性能的流处理
支持savepoints机制(任务恢复)
支持大规模集群模式(yarn,Mesos,k8s)
内部实现了JVM内存管理
支持迭代计算和自动优化
三、flink能做什么?
1、事件驱动型应用:一类具有状态的应用,它从一个或多个事件流提数据,并根据到来的事件触发计算,状态更新或其他外部操作(如:反欺诈,异常检测,规则告警)
2、数据分析应用:从原始数据中提取有价值的信息和指标。(如:数据监控,实验评估,实时数据分析)
3、数据管道应用:提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方式。 数据管道和 ETL 作业的用途相似,都可以转换、丰富数据。ETL会周期的将数据从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发(如:检测文件系统目录,将新文件写到其他库)
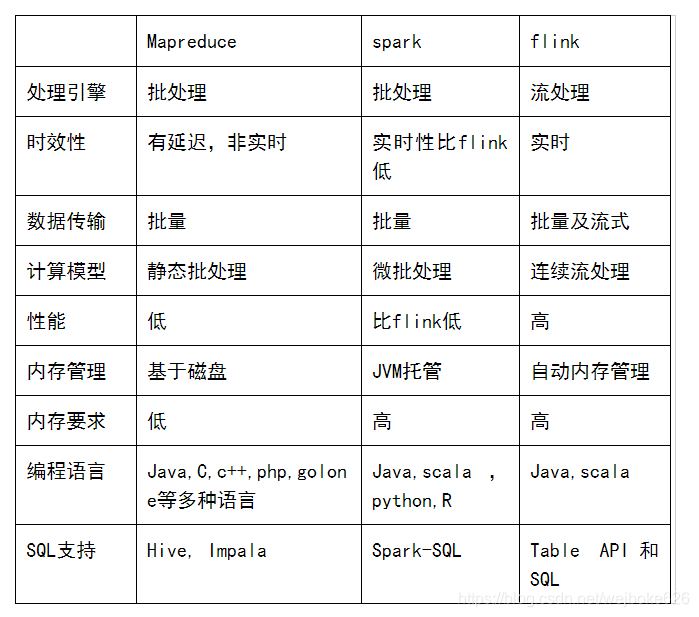
四、flink , mapreduce , Spark 对比

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)