MYSQL lag()和lead()函数用法
这两个函数是偏移量函数,可以查出一个字段的前面N个值或者后面N个值,配合over来使用。下面举例说明,新建表格如下:drop table if exists exam_record;CREATE TABLE exam_record (id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',uid int NOT NULL COMMENT '用户ID',ex
·
这两个函数是偏移量函数,可以查出一个字段的前面N个值或者后面N个值,配合over来使用。
下面举例说明,新建表格如下:
drop table if exists exam_record;
CREATE TABLE exam_record (
id int PRIMARY KEY AUTO_INCREMENT COMMENT '自增ID',
uid int NOT NULL COMMENT '用户ID',
exam_id int NOT NULL COMMENT '试卷ID',
start_time datetime NOT NULL COMMENT '开始时间',
submit_time datetime COMMENT '提交时间',
score tinyint COMMENT '得分'
)CHARACTER SET utf8 COLLATE utf8_general_ci;
INSERT INTO exam_record(uid,exam_id,start_time,submit_time,score) VALUES
(1001, 9001, '2020-01-01 09:01:01', '2020-01-01 09:21:59', 90),
(1002, 9001, '2020-01-20 10:01:01', '2020-01-20 10:10:01', 89),
(1002, 9001, '2020-02-01 12:11:01', '2020-02-01 12:31:01', 83),
(1003, 9001, '2020-03-01 19:01:01', '2020-03-01 19:30:01', 75),
(1004, 9001, '2020-03-01 12:01:01', '2020-03-01 12:11:01', 60),
(1003, 9001, '2020-03-01 12:01:01', '2020-03-01 12:41:01', 90),
(1002, 9001, '2020-05-02 19:01:01', '2020-05-02 19:32:00', 90),
(1001, 9002, '2020-01-02 19:01:01', '2020-01-02 19:59:01', 69),
(1004, 9002, '2020-02-02 12:01:01', '2020-02-02 12:20:01', 99),
(1003, 9002, '2020-02-02 12:01:01', '2020-02-02 12:31:01', 68),
(1001, 9002, '2020-02-02 12:01:01', '2020-02-02 12:43:01', 81),
(1001, 9002, '2020-03-02 12:11:01', null, null);
1.lag()
lag(expr,N,default)
- expr:它可以是列或任何内置函数。
- N:它是一个正值,它确定当前行之前的行数。如果在查询中将其省略,则其默认值为1
- default:如果在当前行之前没有行N行的情况下,它是函数返回的默认值。如果缺少,则默认为NULL。
select *,lag(start_time,1) over(order by id)lad_1,
lag(uid,2) over(order by id)lad_2
from exam_record 
可以看到所有的start_time都等于前面一个的start_time,前面没有的填充NULL,设置lag()里面的参数为2,可以看到所有的uid偏移了两个。
select *,lag(start_time,2,0) over(partition by uid order by id)lag_1
from exam_record
根据uid分组对start_time向前移动2个单元,然后设置NULL值默认填充为0. 可以自己体会一下数据的移动方式。
2.lead()
lead(expr,N,default)
- expr:它可以是列或任何内置函数。
- N:它是一个正值,它确定当前行之后的行数。如果在查询中将其省略,则其默认值为1
- default:如果在当前行之后没有行N行的情况下,它是函数返回的默认值。如果缺少,则默认为NULL。
select *,lead(start_time,1) over(order by id)lead_1,
lead(uid,2) over(order by id)lead_2
from exam_record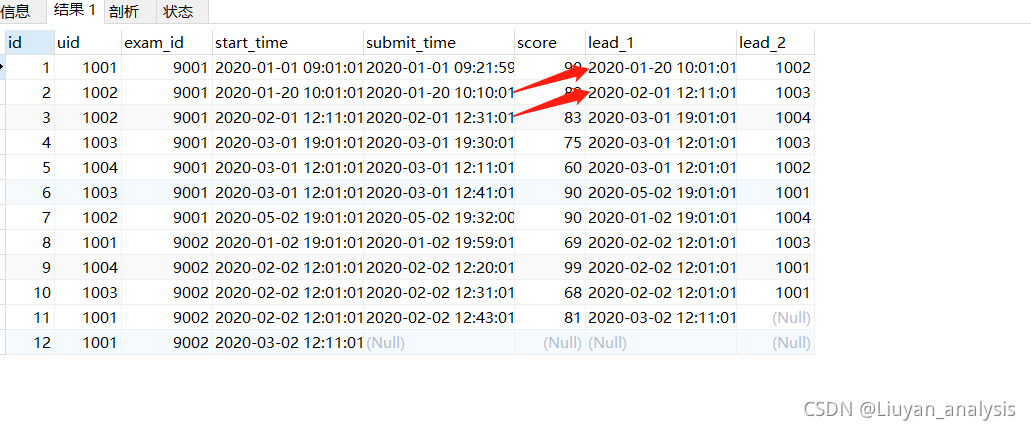
可以看到所有的start_time都等于后面一个的start_time,后面没有的填充NULL,设置lead()里面的参数为2,可以看到所有的uid都等于后面第二个的uid。
select *,lead(start_time,1) over(partition by uid order by id)lead_1
from exam_record
还可以根据uid进行分组,然后再进行偏移。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)