mysql索引原理
mysql索引原理首先介绍一款可以帮助理解数据结构的网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html一、数据结构索引是一种特殊的数据结构。可以帮助我们快速查询到数据。(1)二叉树二叉树是一种特殊的树,每个节点最多有两个子节点,值从左到右依次递增。例如:当想查询值为11的数据时,如果没有索引要按顺序查找多次,有索引只查
mysql索引原理
首先介绍一款可以帮助理解数据结构的网站:Data Structure Visualization

一、数据结构
索引是一种特殊的数据结构。可以帮助我们快速查询到数据。
(1)二叉树
二叉树是一种特殊的树,每个节点最多有两个子节点,值从左到右依次递增。
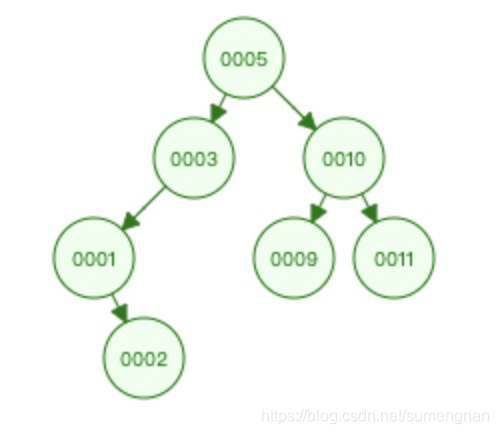
例如:当想查询值为11的数据时,如果没有索引要按顺序查找多次,有索引只查三次,加速了查询数据。
问:为什么索引的数据结构不用二叉树?
因为当值依次递增插入时,二叉树会退化成链表,对加快查询没有任何作用。
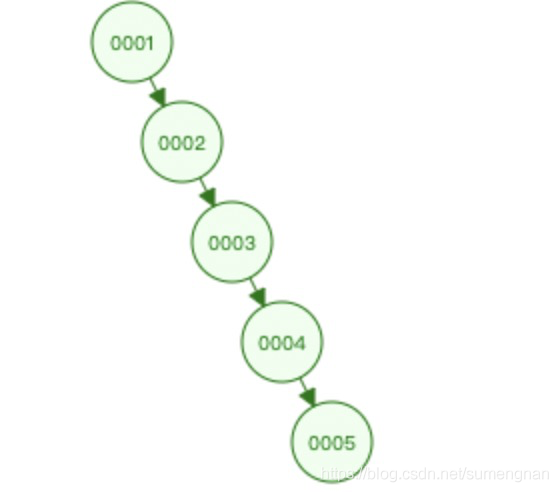
时间复杂度(代码执行的次数):O(N)
(2)红黑树(自平衡二叉查找树)
特点:
- 每个节点只能是红色或黑色。
- 跟节点必须是黑色。
- 红色的节点,它的叶节点只能是黑色。
- 从任一节点到其叶子节点的所有路径都包含相同数目的黑色节点。
当数据插入时,红黑树通过旋转和变色来达到平衡。这样就弥补了二叉树退化成链表的尴尬
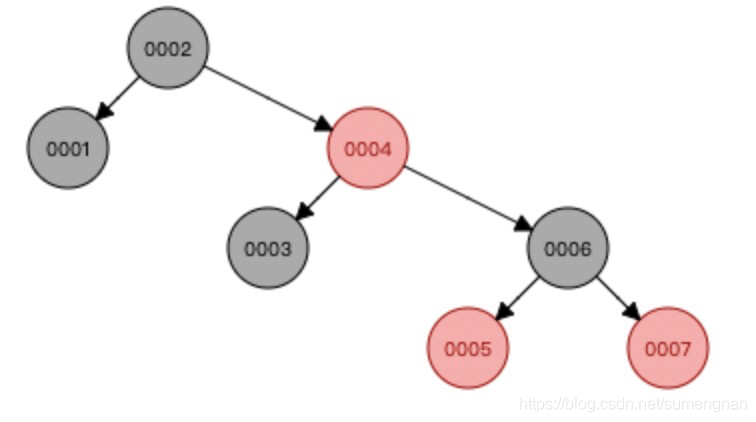
问:为什么索引的数据结构不用红黑树?
因为当值依次递增插入时树的高度会变得特别高。就例如上图查询0007只用3次,那查询70000呢?几乎要用30000次。效率会变得特别低。
时间复杂度为:O(log2N)
(3)B树(多路平衡搜索树)
特点:
- 一个节点可以有多个元素
- 叶节点具有相同的深度,叶节点的指针为空
- 所有索引元素不重复
- 节点中的数据索引从左到右递增排列
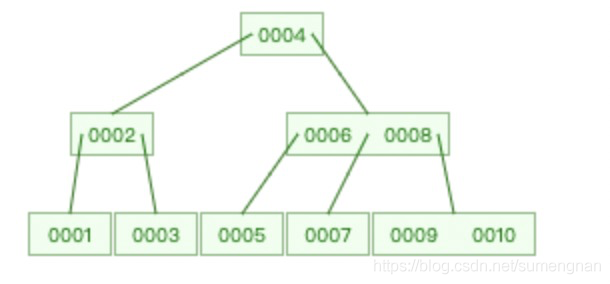
问:为什么索引的数据结构不用B树?
虽然B树相对于红黑树,树的高度降低了,但是随着数据量的增多,树的高度还是会变得很高,效率会变得特别低。而且对范围查找也不方便。
(4)B+树
特点:
- 非叶子节点不存储data,只存储索引(冗余),可以放多个索引。
- 叶子节点包含所有的索引字段
- 叶子节点用指针连接,提高区间访问性能(注意是单向指针。)
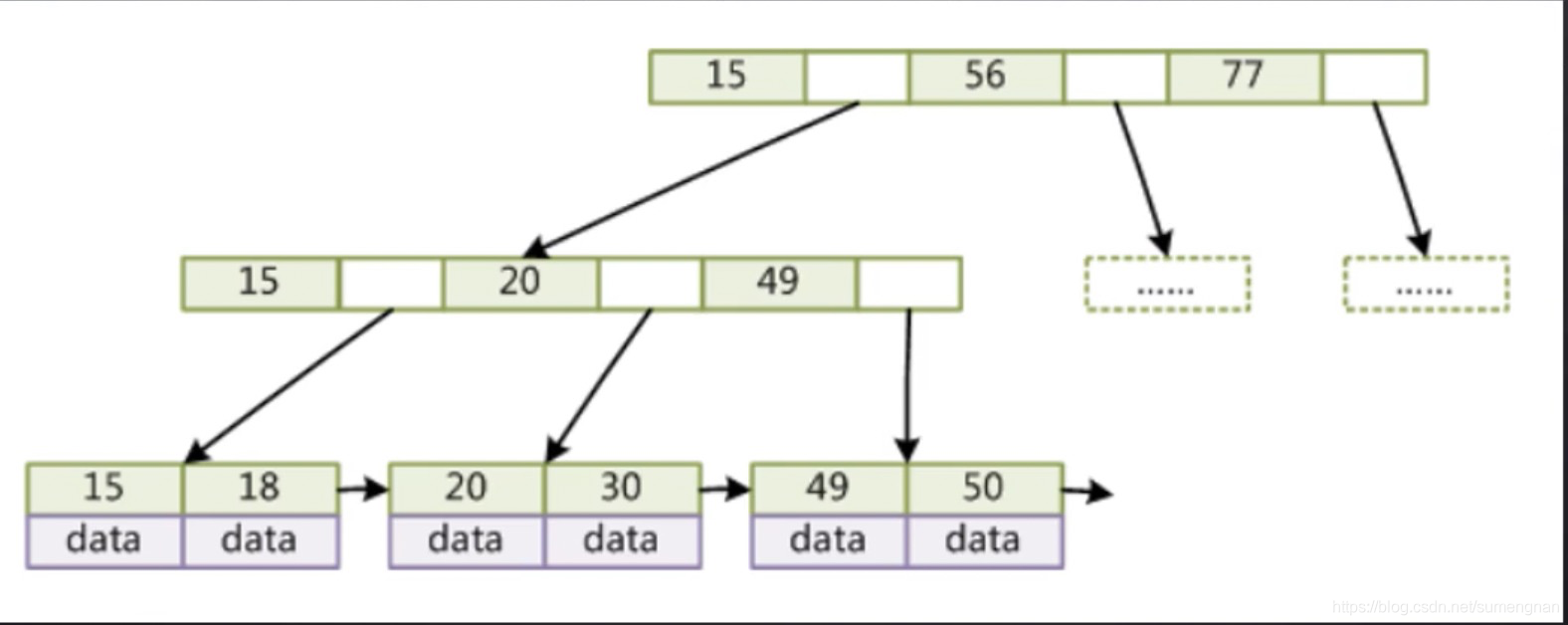
(5)mysql B+树
mysql使用的是B+树,但是不完全是。对原B+树做了一些改造,例如:
- 叶子节点改成双向指针,提高范围查询效率。
- 忘了
(5)hash
可以通过对某一值做hash运算,可以快速确定数据存放地址,查询到数据。但是缺点也很明显,不支持范围查询<>。几乎不用
问:为什么innodb表必须有主键?
因为innodb表的索引结构是B+树,而B+树是基于索引来存储数据的。所有的数据全部保存在B+树的叶子节点上。
问:如果没有主键会怎么样?
innodb引擎会查找并选择第一个没有null值的列,作为主键索引。如果没有,则会使用隐藏列作为主键。
问:为什么推荐使用整形自增主键而不用uuid?
优点:
- 节约空间
- 插入效率高(由于B+树遵循左小右大,所以自增插入数据总是在最右侧插入。而uuid则不一定,如果页16k已经写满了,那只能把页中的数据向后移,在空位中插入。频繁的移动分页会造成碎片,后续需要使用OPTIMIZE TABLE来进行碎片整理)
问:为什么非主键索引结构叶子节点存储的是主键值?
非主键索引存储主键值,是为了当数据变动时,不需要修改各非主键索引的值,只需修改主键索引叶子结点的数据即可。减少了重复操作,即提高性能。
二、Innodb页底层结构
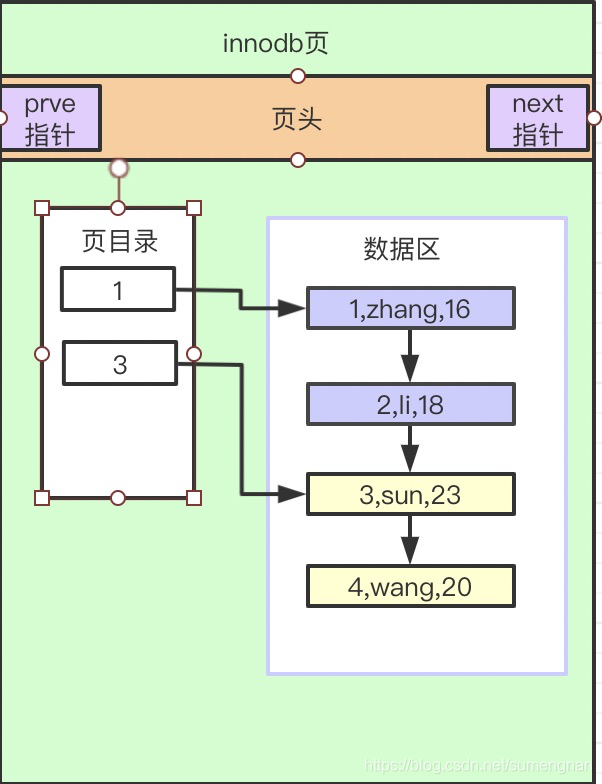
分成三个部分
- 页头:包含前后页的指针
- 页目录:包含数据区(分组)的最小id值,方便通过指针查询到数据
- 数据区:用于存放数据,指针依次向下。
为什么要引入页目录?
比如:我要查询id为4的数据,需要从上到下查询4次。把数据区的数据分组,页目录存储每组数据最小的id值。那么我只需要通过目录3,查询2次即可。提高了查询效率。
当一页存满之后,数据会存放到下一页,通过双向指针连接,如图:
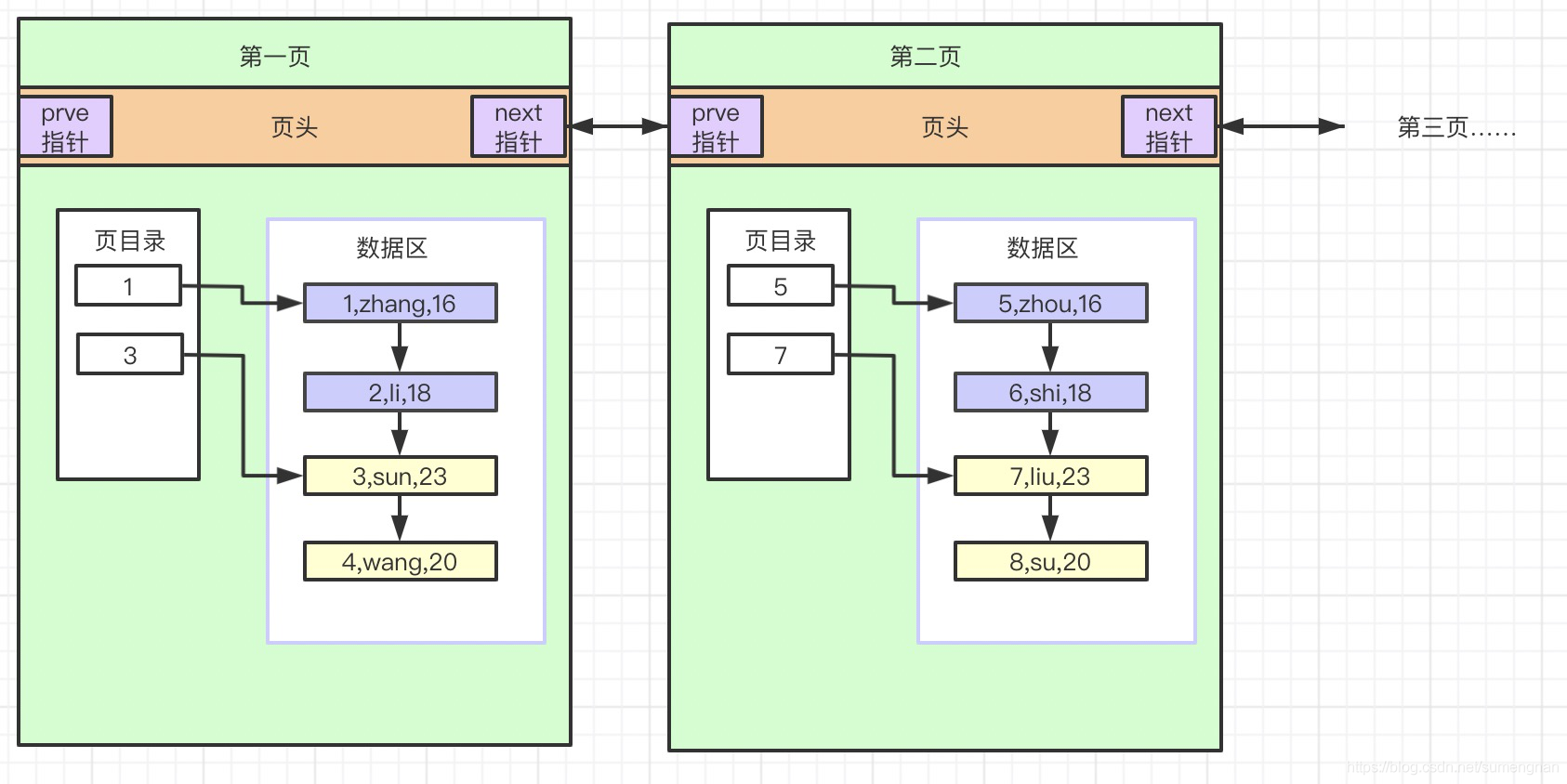
当数据越存越多,最终多个页组成了链表。例如:我要查询1000,如果从第1页开始查询,一页一页遍历效率就太慢了(这就是全表扫描)
那怎么办?当然还是用类似页目录的方式了:如图:
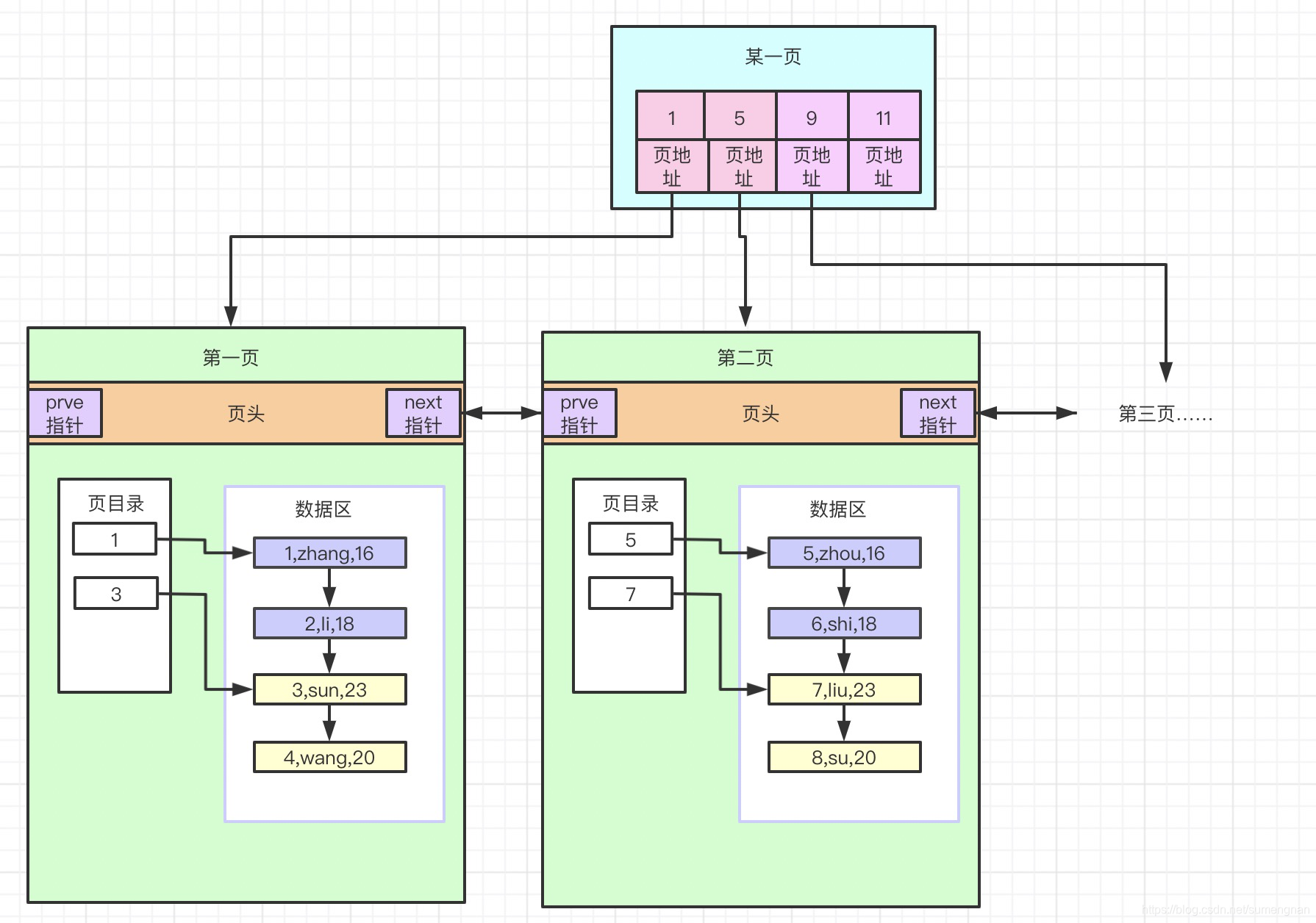
到这里就可以大致看出来了,这个结构就是上面说的B+树。每一页即B+树的一个节点
三、主键索引底层结构
问:索引文件对应系统位置在哪?
在mysql目录的data目录下某个数据库名的文件夹下

myisam引擎:包含frm(结构文件)、MYD(data数据文件)、MYI(index索引文件)
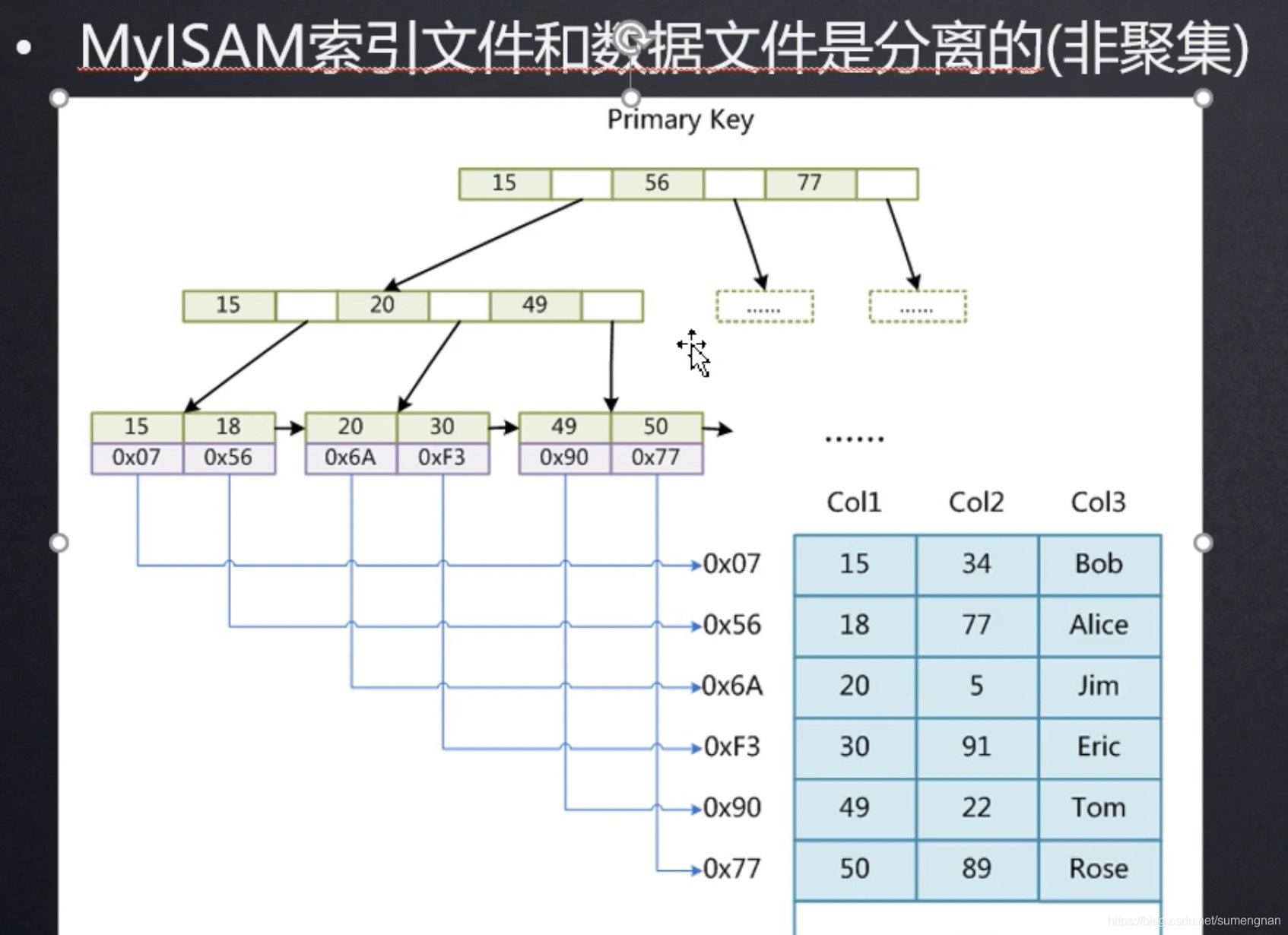
innodb引擎包含frm(结构文件)、idb(索引+数据文件)
innodb索引文件和数据文件在一起的(聚集索引)
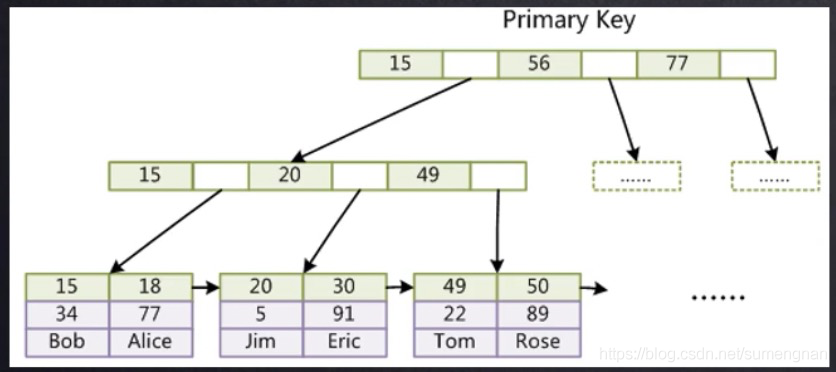
此处可以看出innodb比myisam引擎少一次磁盘io操作(不需要再去MYD文件取数据),可以说性能好一些。
四、组合索引结构
explain
主要关注type字段和row字段
type字段值包括:const、eq_ref、ref、range、index、all
row表示扫描的行数、尽量越少越好。关联查询时使用小表驱动大表的方式
索引失效
- 使用!=、is null、or关键字
- 使用like时%加在左边
- 组合索引没有满足最左匹配原则
- in的数量太多,也可能导致索引失效
- where条件后面=左边,也就是对字段进行算数运算或函数操作
- ……
最左匹配原则
五、Innodb共享表和独享表
共享表:在mysql目录的data目录下ibdata1文件,如图:

- 优点:所有数据及索引全部存放在ibdata1文件中
- 缺点:在表中做了大量删除操作,ibdata文件不会变小,表空间中会产生大量空隙。对于经常删除操作的这类应用不适合共享表
独享表:在mysql目录的data目录下的某个数据库名的文件夹下,如图:
- 优点:
- 可以实现单表在不同的数据库中移动
- 空间可以回收(drop/truncate table方式操作表空间不能自动回收)
- 不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理
- 缺点:单表增加比共享空间方式更大。
修改成独享表方法:查看mysql参数
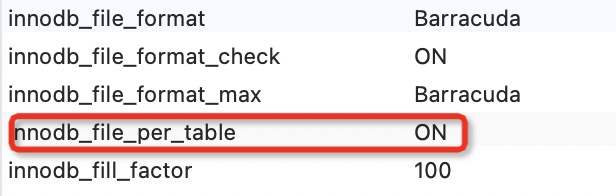
my.cnf设置添加参数
- innodb_file_per_table=1 为使用独占表空间
- innodb_file_per_table=0 为使用共享表空间
myisam表需要先转换成innodb:alter table table_name engine=innodb;
索引回表和全表扫描

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)