ES中SQL查询详解
本文主要介绍了Elasticsearch SQL的使用。如果你对DSL查询语句不熟悉,那么采用SQL查询索引数据将是一个非常简单,0门槛入门的好方法。1、注意ES在6.3版本之后才原生支持SQL查询。2、可以通过translate API将sql语句转为DSL语句。3、ES的SQL查询提供对自查询的简单支持。4、通过SHOW FUNCTIONS可以查看ES的SQL查询支持的函数。5、ES的SQL查
一、Elasticsearch SQL简介
Elasticsearch SQL 是一个 X-Pack 组件,它允许对 Elasticsearch 实时执行类似 SQL 的查询。无论是使用 REST 接口、命令行还是 JDBC,任何客户机都可以使用 SQL 在 Elasticsearch 中本地搜索和聚合数据。我们可以把 Elasticsearch SQL 看作一个翻译器,它同时理解 SQL 和 Elasticsearch,并且通过 Elasticsearch 的功能,可以方便地实时读取和处理数据。
官方文档:
根据版本级别的特征支持说明:https://www.elastic.co/cn/subscriptions
免费开源的版本中,已经提供了对Elasticsearch SQL API功能的支持。
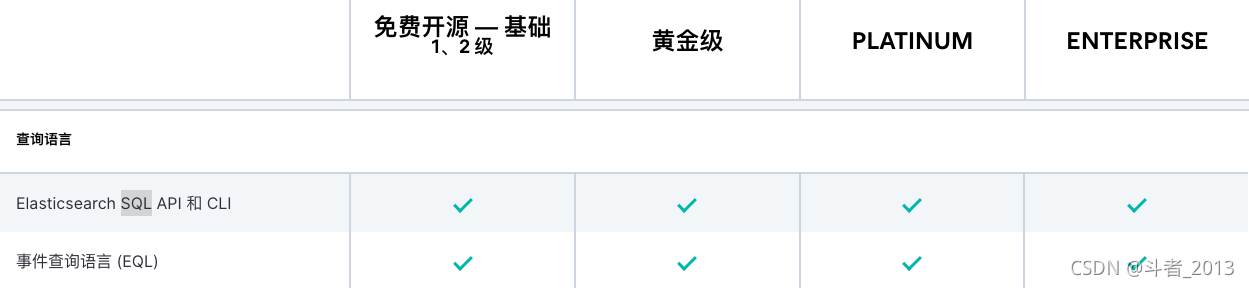
我们通过对官网链接的版本号修改会发现:
1、6.3版本还能正常访问到sql-overview相关介绍
https://www.elastic.co/guide/en/elasticsearch/reference/6.3/sql-overview.html#sql-introduction
2、切换成6.2后,出现页面不可用的提示。
https://www.elastic.co/guide/en/elasticsearch/reference/6.2/sql-overview.html#sql-introduction
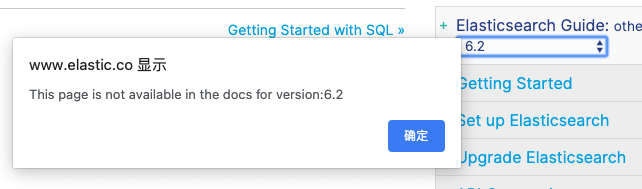
可以初步得出结论,ES6.3之后的版本才提供免费的Elasticsearch SQL的特性。
二、X-Pack 组件说明
2019年5月21日,Elastic官方发布消息: Elastic Stack 新版本6.8.0 和7.1.0的核心安全功能现免费提供。
这意味着用户现在能够对网络流量进行加密、创建和管理用户、定义能够保护索引和集群级别访问权限的角色,并且使用 Spaces 为 Kibana提供全面保护。
免费提供的核心安全功能如下:
1)TLS 功能。 可对通信进行加密;
2)文件和原生 Realm。 可用于创建和管理用户;
3)基于角色的访问控制。 可用于控制用户对集群 API 和索引的访问权限;通过针对 Kibana Spaces 的安全功能,还可允许在Kibana 中实现多租户。
1、X-Pack演变

1)5.X版本之前:没有x-pack,是独立的:security安全,watch查看,alert警告等独立单元。
2)5.X版本:对原本的安全,警告,监视,图形和报告做了一个封装,形成了x-pack。
3)6.3 版本之前:需要额外安装。
4)6.3版本及之后:已经集成在一起发布,无需额外安装,基础安全属于付费黄金版内容。
5)6.8.0和7 .1版本:基础安全免费。
2、X-Pack包含的特性
2018年2月28日X-Pack 特性的所有代码开源,主要包含:
Security、Monitoring、Alerting、Graph、Reporting、专门的 APM UI、Canvas、Elasticsearch SQL、Search Profiler、Grok Debugger、Elastic Maps Service zoom levels 以及 Machine Learning。
3、开源!=免费
2019年5月21日免费开放了文章开头的基础安全功能,在这之前的版本都是仅有1个月的适用期限的。
如下功能点仍然是收费的。
付费黄金版&白金版提供功能:
- 审核日志
- IP 筛选
- LDAP、PKI*和活动目录身份验证
- Elasticsearch 令牌服务
付费白金版提供安全功能:
- 单点登录身份验证(SAML、Kerberos*)
- 基于属性的权限控制
- 字段和文档级别安全性
- 第三方整合(自定义身份验证和授权 Realm)
- 授权 Realm
- 静态数据加密支持
三、Elasticsearch SQL入门使用
1、创建索引
PUT /library/book/_bulk?refresh
{"index":{"_id": "Leviathan Wakes"}}
{"name": "Leviathan Wakes", "author": "James S.A. Corey", "release_date": "2011-06-02", "page_count": 561}
{"index":{"_id": "Hyperion"}}
{"name": "Hyperion", "author": "Dan Simmons", "release_date": "1989-05-26", "page_count": 482}
{"index":{"_id": "Dune"}}
{"name": "Dune", "author": "Frank Herbert", "release_date": "1965-06-01", "page_count": 604}
2、使用sql查询索引数据
POST /_sql?format=txt
{
"query": "SELECT * FROM library WHERE release_date < '2000-01-01'"
}
响应结果:
author | name | page_count | release_date
---------------+---------------+---------------+------------------------
Dan Simmons |Hyperion |482 |1989-05-26T00:00:00.000Z
Frank Herbert |Dune |604 |1965-06-01T00:00:00.000Z
3、响应的数据格式化
主要有如下格式化类型:
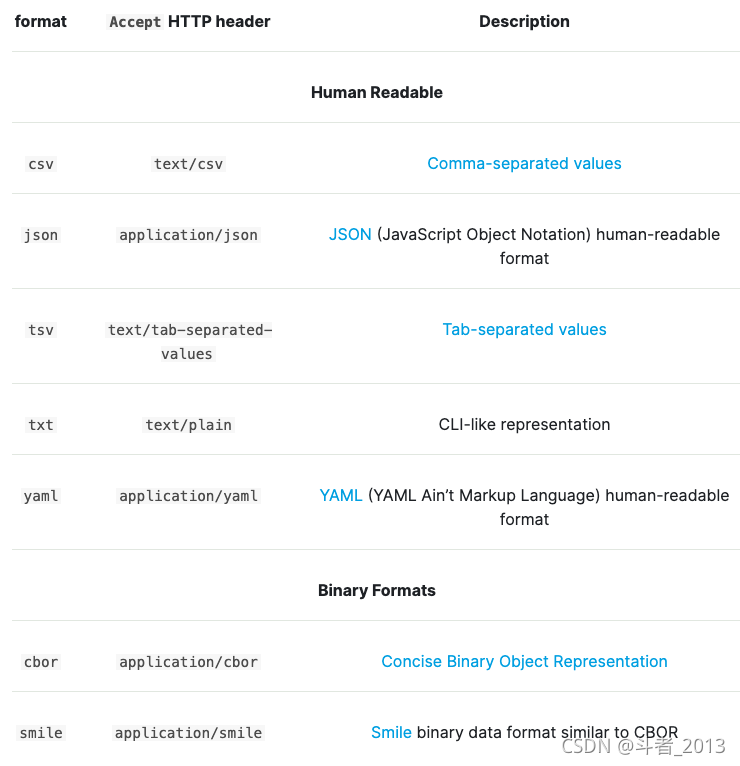
其中用的最多的主要是csv、json、text。
JSON:
POST /_sql?format=json
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 5
}
响应结果:
{
"columns": [
{"name": "author", "type": "text"},
{"name": "name", "type": "text"},
{"name": "page_count", "type": "short"},
{"name": "release_date", "type": "datetime"}
],
"rows": [
["Peter F. Hamilton", "Pandora's Star", 768, "2004-03-02T00:00:00.000Z"],
["Vernor Vinge", "A Fire Upon the Deep", 613, "1992-06-01T00:00:00.000Z"],
["Frank Herbert", "Dune", 604, "1965-06-01T00:00:00.000Z"],
["Alastair Reynolds", "Revelation Space", 585, "2000-03-15T00:00:00.000Z"],
["James S.A. Corey", "Leviathan Wakes", 561, "2011-06-02T00:00:00.000Z"]
],
"cursor": "sDXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAAEWWWdrRlVfSS1TbDYtcW9lc1FJNmlYdw==:BAFmBmF1dGhvcgFmBG5hbWUBZgpwYWdlX2NvdW50AWYMcmVsZWFzZV9kYXRl+v///w8="
}
CSV:
POST /_sql?format=csv
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 5
}
响应结果:
author,name,page_count,release_date
Peter F. Hamilton,Pandora's Star,768,2004-03-02T00:00:00.000Z
Vernor Vinge,A Fire Upon the Deep,613,1992-06-01T00:00:00.000Z
Frank Herbert,Dune,604,1965-06-01T00:00:00.000Z
Alastair Reynolds,Revelation Space,585,2000-03-15T00:00:00.000Z
James S.A. Corey,Leviathan Wakes,561,2011-06-02T00:00:00.000Z
4、sql查询中使用filter
POST /_sql?format=txt
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"filter": {
"range": {
"page_count": {
"gte" : 100,
"lte" : 200
}
}
},
"fetch_size": 5
}
5、参数传递
可以直接将参数组装成完整的SQL语句,也可以使用?占位符来传参。
POST /_sql?format=txt
{
"query": "SELECT YEAR(release_date) AS year FROM library WHERE page_count > ? AND author = ? GROUP BY year HAVING COUNT(*) > ?",
"params": [300, "Frank Herbert", 0]
}
6、使用运行时字段
POST _sql?format=txt
{
"runtime_mappings": {
"release_day_of_week": {
"type": "keyword",
"script": """
emit(doc['release_date'].value.dayOfWeekEnum.toString())
"""
}
},
"query": """
SELECT * FROM library WHERE page_count > 300 AND author = 'Frank Herbert'
"""
}
响应结果:
author | name | page_count | release_date |release_day_of_week
---------------+---------------+---------------+------------------------+-------------------
Frank Herbert |Dune |604 |1965-06-01T00:00:00.000Z|TUESDAY
7、Sql查询语句转为DSL查询语句
POST /_sql/translate
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 10
}
响应结果:
{
"size": 10,
"_source": false,
"fields": [
{
"field": "author"
},
{
"field": "name"
},
{
"field": "page_count"
},
{
"field": "release_date",
"format": "strict_date_optional_time_nanos"
}
],
"sort": [
{
"page_count": {
"order": "desc",
"missing": "_first",
"unmapped_type": "short"
}
}
]
}
8、Sql支持的函数
查看支持的所有函数:
SHOW FUNCTIONS;
查看支持的天数相关函数:
SHOW FUNCTIONS LIKE '%DAY%';
name | type
---------------+---------------
DAY |SCALAR
DAYNAME |SCALAR
DAYOFMONTH |SCALAR
DAYOFWEEK |SCALAR
DAYOFYEAR |SCALAR
DAY_NAME |SCALAR
DAY_OF_MONTH |SCALAR
DAY_OF_WEEK |SCALAR
DAY_OF_YEAR |SCALAR
HOUR_OF_DAY |SCALAR
ISODAYOFWEEK |SCALAR
ISO_DAY_OF_WEEK|SCALAR
MINUTE_OF_DAY |SCALAR
TODAY |SCALAR
Elasticsearch SQL 提供了一整套内置的操作符和函数:
官网说明:sql-functions

9、子查询支持
使用子选择(SELECT x FROM (SELECT y))在很小程度上是受支持的: Elasticsearch SQL 可以将任何子选择“扁平化”为单个 SELECT。
SELECT * FROM (SELECT first_name, last_name FROM emp WHERE last_name NOT LIKE '%a%') WHERE first_name LIKE 'A%' ORDER BY 1;
first_name | last_name
---------------+---------------
Alejandro |McAlpine
Anneke |Preusig
Anoosh |Peyn
Arumugam |Ossenbruggen
注意⚠️:
如果子查询中包含 GROUP BY 或 HAVING 或封闭的 SELECT语句,这些比 SELECT X FROM (SELECT ...) WHERE [simple_condition]更复杂的查询,目前不支持。
更多ES中SQL查询的限制,可以查看官网说明SQL Limitations
10、SQL分页查询支持
1)使用limit限制返回记录数:
POST /_sql?format=txt
{
"query": "SELECT * FROM library limit 2"
}
2)使用top函数限制返回记录数:
POST /_sql?format=txt
{
"query": "SELECT top 2 * FROM library"
}
3)使用fetch_size参数限制返回记录数:
POST /_sql?format=txt
{
"query": "SELECT * FROM library",
"fetch_size":2
}
4)采用limit结合自查询进行分页查询:
POST /_sql?format=txt
{
"query": "SELECT * FROM (SELECT * FROM library limit 2) limit 1"
}
5)通过游标访问下一页:
说明:
在采用CSV, TSV 和 TXT 格式化返回时, 会返回一个游标值cursor,通过游标值我们可以继续访问下一页。
这种方式非常时候大数据量的分页返回。
POST /_sql?format=json
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 5
}
响应结果:
```csharp
{
"columns": [
{"name": "author", "type": "text"},
{"name": "name", "type": "text"},
{"name": "page_count", "type": "short"},
{"name": "release_date", "type": "datetime"}
],
"rows": [
["Peter F. Hamilton", "Pandora's Star", 768, "2004-03-02T00:00:00.000Z"],
["Vernor Vinge", "A Fire Upon the Deep", 613, "1992-06-01T00:00:00.000Z"],
["Frank Herbert", "Dune", 604, "1965-06-01T00:00:00.000Z"],
["Alastair Reynolds", "Revelation Space", 585, "2000-03-15T00:00:00.000Z"],
["James S.A. Corey", "Leviathan Wakes", 561, "2011-06-02T00:00:00.000Z"]
],
"cursor": "sDXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAAEWWWdrRlVfSS1TbDYtcW9lc1FJNmlYdw==:BAFmBmF1dGhvcgFmBG5hbWUBZgpwYWdlX2NvdW50AWYMcmVsZWFzZV9kYXRl+v///w8="
}
通过游标访问下一页:
POST /_sql?format=json
{
"cursor": "sDXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAAEWYUpOYklQMHhRUEtld3RsNnFtYU1hQQ==:BAFmBGRhdGUBZgVsaWtlcwFzB21lc3NhZ2UBZgR1c2Vy9f///w8="
}
四、Elasticsearch和SQL对应关系
虽然 SQL 和 Elasticsearch 对于数据的组织方式(以及不同的语义)有不同的术语,但本质上它们的用途是相同的。
| SQL | Elasticsearch | 说明 |
|---|---|---|
| column | field | 在 Elasticsearch 字段时,SQL 将这样的条目调用为 column。注意,在 Elasticsearch,一个字段可以包含同一类型的多个值(本质上是一个列表) ,而在 SQL 中,一个列可以只包含一个表示类型的值。Elasticsearch SQL 将尽最大努力保留 SQL 语义,并根据查询的不同,拒绝那些返回多个值的字段。 |
| row | document | 列和字段本身不存在; 它们是行或文档的一部分。两者的语义略有不同: 行row往往是严格的(并且有更多的强制执行),而文档往往更灵活或更松散(同时仍然具有结构)。 |
| table | index | 在 SQL 还是 Elasticsearch 中查询针对的目标 |
| schema | 无 | 在关系型数据库中,schema 主要是表的名称空间,通常用作安全边界。Elasticsearch没有为它提供一个等价的概念。 |
总结
本文主要介绍了Elasticsearch SQL的使用。如果你对DSL查询语句不熟悉,那么采用SQL查询索引数据将是一个非常简单,0门槛入门的好方法。
1、注意ES在6.3版本之后才原生支持SQL查询。
2、可以通过translate API将sql语句转为DSL语句。
3、ES的SQL查询提供对自查询的简单支持。
4、通过SHOW FUNCTIONS可以查看ES的SQL查询支持的函数。
5、ES的SQL查询可以通过游标cursor实现分页查询。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 4
4 0
0- 0



 已为社区贡献37条内容
已为社区贡献37条内容

所有评论(0)