MySQL优化
MySQL优化方向:在设计上:字段类型,存储引擎,范式在功能上:索引,缓存,分库分表在架构上:集群,主从复制,负载均衡,读写分离SQL优化1.插入优化大量数据采用批量插入形式事务设置手动提交,MySQL默认是自动提交,意味着每写一个SQL事务就自动提交,可能会频繁的涉及事务开始和提交,所以建议手动提交2.order by优化Using filesort:通过表的索引或者全表扫描,读取到满足条件的数
MySQL优化方向:
在设计上:字段类型,存储引擎,范式
在功能上:索引,缓存,分库分表
在架构上:集群,主从复制,负载均衡,读写分离
SQL优化
1.插入优化
- 大量数据采用批量插入形式
- 事务设置手动提交,MySQL默认是自动提交,意味着每写一个SQL事务就自动提交,可能会频繁的涉及事务开始和提交,所以建议手动提交
2.order by优化
- Using filesort:通过表的索引或者全表扫描,读取到满足条件的数据行,然后在排序缓冲区 sort buffer 中完成排序,所以返回的数据不是通过索引直接返回的,这样的排序形式就叫filesort
- Using index:通过有序索引顺序扫描直接返回有序数据,这种情况不需要额外的排序,所以效率比较高
- 根据多字段排序时,遵循左前缀原则
3.group by优化
group by进行分组
在分组操作时,可以通过索引来提高效率,索引使用也要满足左前缀原则
4.limit优化
limit用来限制检索数据范围,一般用于分页功能
比如:检索数据为limit 2000000,10。此时需要MySQL排序前2000010记录仅仅返回2000000-2000010间的数据,其他数据丢弃,查询排序的代价比太大
优化思路:一般分页查询时,通过创建覆盖索引能够比较好的提高性能,可以通过创建覆盖索引加子查询的形式进行优化
select * from student s,(select SID from student order by SID limit 2000000,10) s1
where s.SID=s1.SID;覆盖索引:
查询列要被所有的索引覆盖到,就是select的数据列只用从索引(只查询一个索引树)中就能够获取到
select SID from student where Sname="18";//覆盖索引
select Ssex from student where Sname="18";//非覆盖索引5.count优化
myisam存储引擎是把表的总行数存储在磁盘上,因此count(*)直接获取结果,效率比较高
innodb存储引擎执行count(*),需要将数据一行一行读取出来,然后累计结果,效率较低
count()的几种用法:
count(*),count(1),count(主键),count(字段)
- count(*):innodb引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加
- count(1):innodb引擎遍历整张表,但不取值,服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加
- count(主键):innodb引擎遍历整张表,把每一行的主键都取出来,返回给服务层,服务层拿到主键直接按行进行累加(主键不可能为空)
- count(字段):没有not null约束,innodb引擎遍历整张表,把每一行的字段都取出来,判断是否为null,若不为null,按行进行累加
扩展:explain 中Extra字段说明
using index:SQL所需要的返回值所有列数据均在一颗索引树上,即无需访问实际的行记录
using where:SQL使用了where过滤条件
注:使用了where条件的SQL,并不代表不需要优化,需要进一步判断explain执行计划中type的类型,如果type为all,表示进行了全表扫描,则需要优化,否则不需要优化
using index condition:说明检索确实命中索引,但不是所有的列都在索引树上,还有需要访问实际的行记录,这个SQL语句性能也很高,但不如using index
using filesort:得到的所有的结果集,需要进行文件排序,SQL语句性能很差,需要优化
索引优化
explain分析查询SQL
索引设计需要遵循的原则:
- 给区分度比较高的字段创建索引,比如:学号,身份证号
- 给经常需要排序、分组和多表联合操作的字段创建索引
- 给经常作为查询条件的字段创建索引
- 索引的数据不宜过多
- 对于多列索引,优先指定最左侧的列
- 删除不使用或者很少使用的索引
- 索引失效的场景:not in,like“%li”,<>等
大表拆分优化
分库分表:
分库:将以前存在于一个数据库实例中的数据拆分成多个数据库实例,部署在不同的服务器上
分表:将以前存在于一张表上的数据拆分成多个表
分库是为了解决服务器资源受单机限制,顶不住高并发的问题,把请求分发到多台服务器降低服务器的压力
分表是为了解决单张表数据量过大,查询效率慢的问题
如何分库
分库一般按照业务划分,比如订单库,用户库
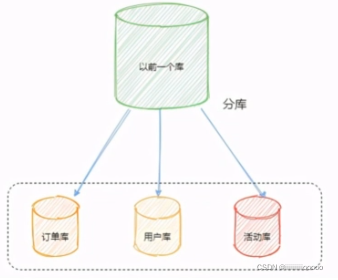
分库会带来问题:
事务问题:无法保证事务完整性,采用分布式事务
连接join问题:跨库无法join:1.在业务代码上进行关联 2.适当冗余字段
如何分表
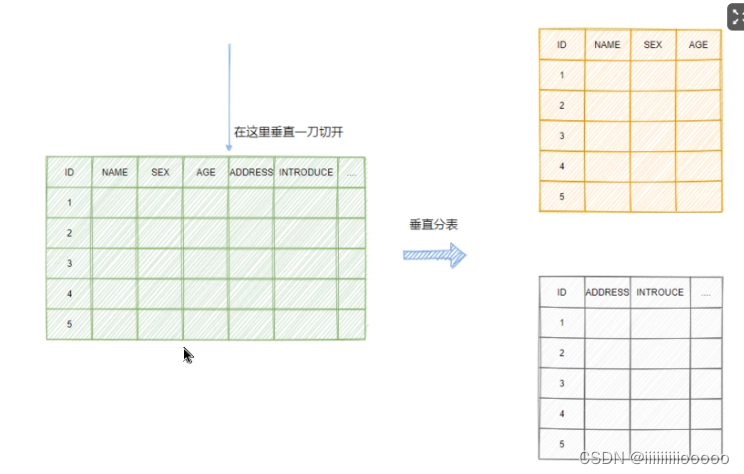
垂直分表:把一些不常用的大字段剥离出去
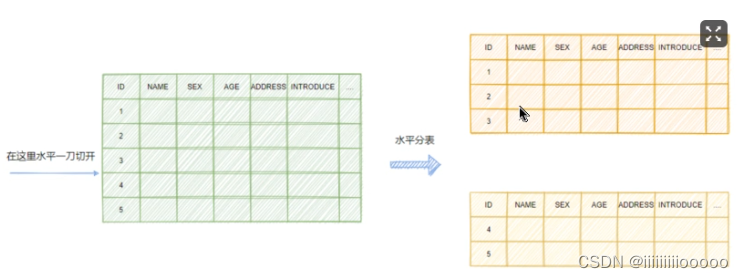
水平分表:则是因为一张表内的数据太多了,上文提到数据越多B+树就越高,访问的性能越差,所以进行水平拆分
分表带来问题:
排序、count、分页问题:在业务代码上将数据进行排序、count、分页处理
路由问题:分表路由问题:hash路由、范围路由
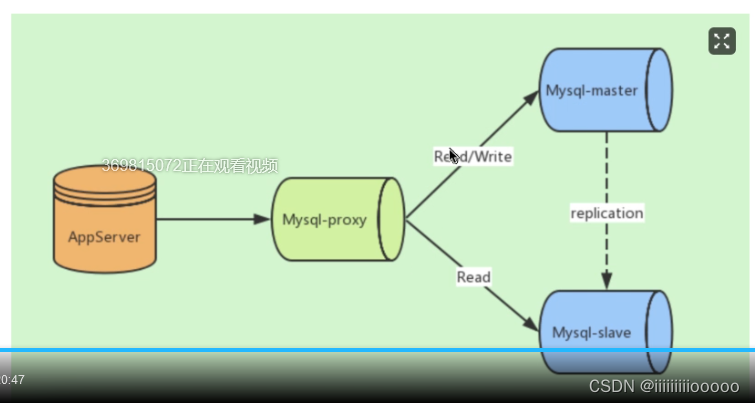
集群架构主从复制
通常采用数据库集群方案来解决高并发问题,也满足高可用,在多个数据库上一旦一个数据库宕机后,可以将请求分发到其他服务器上,可以持续提供服务
MySQL通过主从复制来实现读写分离,负载均衡等功能
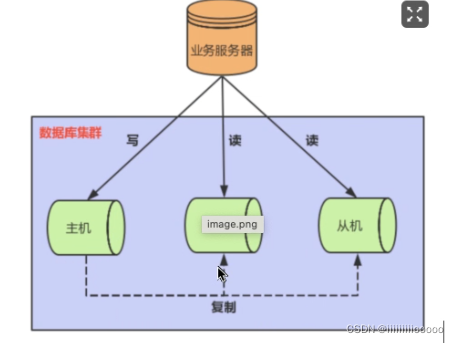
binlog二进制日志
undo log 、redo log
MySQL集群中主从复制通过binlog将数据从主库同步到从库
binlog默认是不开启的
通过命令查看
show variables like "log_%";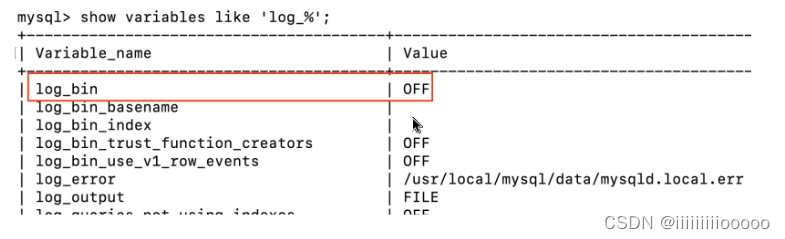
开启binlog日志,通过修改配置文件,MySQL server启动时会自动加载配置文件,Windows下my.ini文件,Linux下是my.conf文件,在打开的文件中在[mysql]上添加配置,保存并重启MySQL server服务器,默认就采用给定的日志文件
binglog_format=ROW配置文件写完需要重启服务器:systrmctl restart mysql
通过show variables like "log_%"命令,如果log_bin为ON则表示开启二进制日志
主从复制原理

MySQL主从复制需要三个线程,master(log dump thread),slave(I/O thread,SQL thread)
master
- log dump thread:当主库中有数据更新时,主库就会根据按照设置的binlog格式,将此次更新的事件类型写入到主库的binlog文件中,此时主库会创建log dump线程通知slave有数据更新,当I/O线程请求日志内容时,会将此时的binlog名称和当前更新的位置同时传给slave的I/O线程
slave
- I/O线程:该线程会连接到master,向log dump线程请求一份指定binlog文件位置的副本,并将请求回来的binlog存到本地的relay log中,relay log 和binlog日志一样是记录了数据更新的事件,他也是按照递增后缀名的方式,产生多个relay log(host_name_relay_bin.000001)文件,slave会使用一个index文件(host_name_relay_bin.index)来追踪当前正在使用的relay log文件。
- SQL线程:该线程检测到relay log有更新后,会读取并在本地做redo操作,把发生在主库的事件在本地重新执行一遍,来保证主从数据同步
此外,如果有一个relay log文件中的全部事件都执行完毕,那么SQL线程会自动将该relay log文件删除掉
集群成熟方案
数据库中间件:常用的有MySQL Proxy、MyCat以及ShardingSphere等等
- MySQL Proxy:是官方提供的MySQL中间件产品可以实现负载均衡,读写分离等,是一个基于服务器端的代理
- MyCat:是一款基于阿里开源产品Cobar而研发的,基于java语言编写的开源数据库插件
- ShardingSphere:是一套开源的分布式数据库中间件解决方案,它由ShardingJDBC、Sharding-Proxy、Sharding-Sidecar(计划中)这三款相互独立的产品组成

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)