什么是kafka、kafka的应用场景、Kafka基本知识
Kafka 最初由LinkedIn公司开发的,并于 2010 年贡献给了 Apache 基金会,之后成为 Apache 顶级项目。目前 Kafka 已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。目前越来越多的开源分布式处理系统如 Cloudera、 Storm、 Spark、 Flink 等都支持与 Kafka 集成 。Kafka之所以受
1、什么是kafka
Kafka 最初由LinkedIn公司开发的,并于 2010 年贡献给了 Apache 基金会,之后成为 Apache 顶级项目。
目前 Kafka 已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。
目前越来越多的开源分布式处理系统如 Cloudera、 Storm、 Spark、 Flink 等都支持与 Kafka 集成 。
Kafka之所以受到越来越多的青睐,与它所“扮演 ”的三大角色是分不开的 :
-
消息系统: Kafka 和传统的消息系统(也称作消息中间件)都具备系统解稿、冗余存储、流量削峰、缓冲、异步通信、扩展性、 可恢复性等功能。与此同时, Kafka 还提供了大多数消息系统难以实现的
消息顺序性保障及回溯消费的功能。 -
存储系统: Kafka
把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险 。 也正是得益于Kafka 的消息持久化功能和多副本机制,我 们可以把 Kafka 作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置 为“永久”或启用主题的日志压缩功能即可 。 -
流式处理平台: Kafka 不仅为每个流行的流式处理框架提供了可靠的数据来源,还提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作 。
2、kafka的应用场景
-
日志收集:一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
-
消息系统:解耦和生产者和消费者、缓存消息等。
-
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到 hadoop、数据仓库中做离线分析和挖掘。
-
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
3、Kafka基本知识
一个典型的 Kafka 体系架构包括若干 Producer、若干 Broker、若干 Consumer,以及一个ZooKeeper集群,如图所示。 其中 ZooKeeper是 Kafka用来负责集群元数据的管理、控制器的选举等操作的(包括集群 、 broker、主题、 分区等 内容) 。 Producer 将消息发送到 Broker,Broker 负责将收到的消息存储到磁盘中,而Consumer 负责从 Broker 订阅并消费消息。
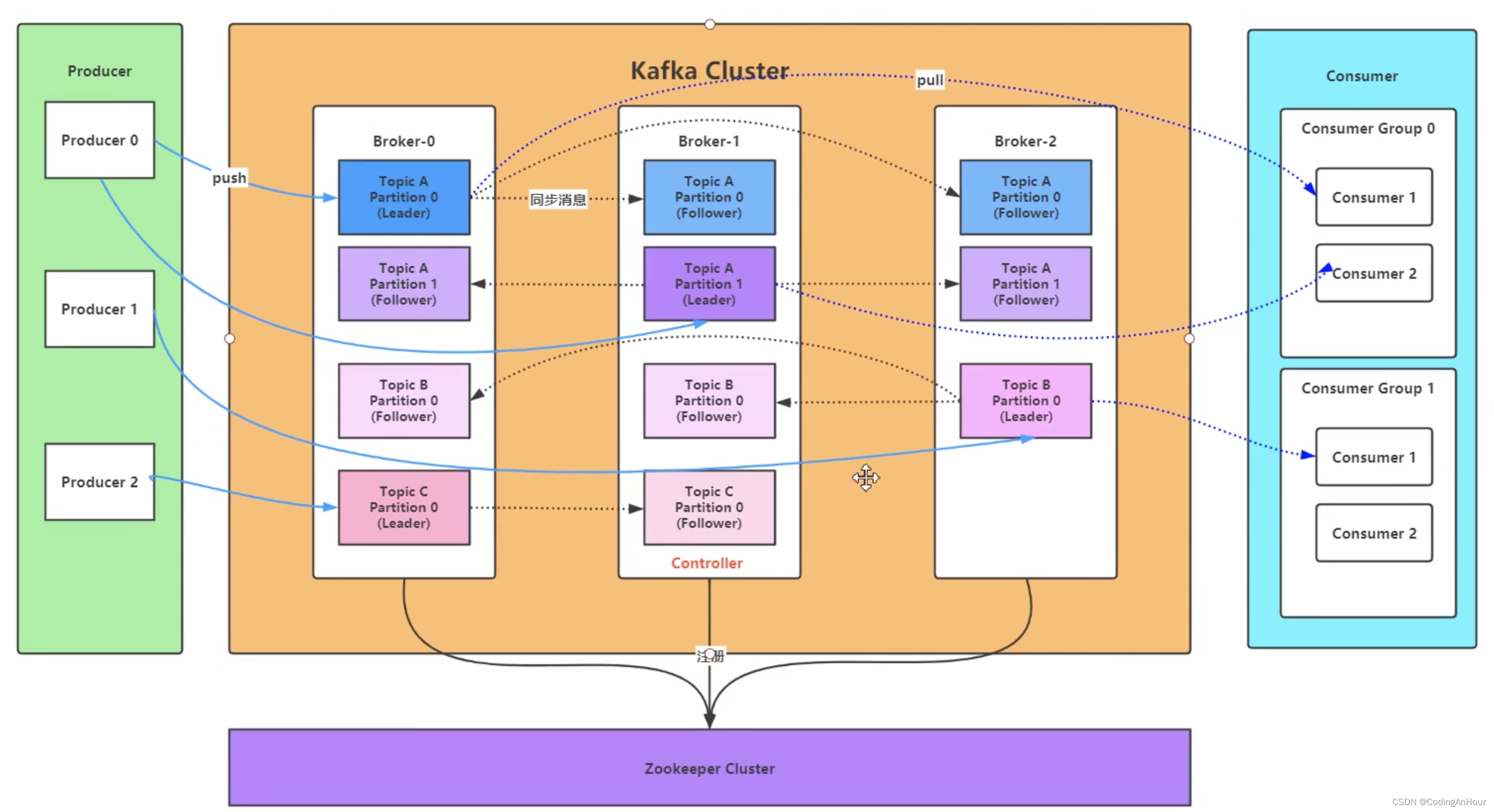
3.1、Broker(可以理解为消息的服务端)
- 服务代理节点。对于 Kafka 而言, Broker 可以简单地看作一个独立的 Kafka 服务节点或 Kafka服务实例;
- 当消息生产者将消息推送到broker集群中,消费者进行消费;
- Broker会将节点信息注册到zookeeper中;

3.2、Topic
- Kafka中的消息以主题为单位进行归类,生产者负责将消息发送到特定的Topic(发送到 Kafka 集群中的每一条消息都要指定一个Topic),而消费者负责订阅Topic并进行消费。
- Topic是一个逻辑上的概念,它还可以细分为多个分区,一个分区只属于单个Topic,很多时 候也会把分区称为主题分区( Topic-Partition)。
同一主题下的不同分区包含的消息是不同的, 分区在存储层面可以看作一个可追加的日志( Log)文件,消息在被追加到分区日志、文件的时候都会分配一个特定的偏移量(offset)。offset是消息在分区中的唯一标识, Kafka通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka保证的是分区有序而不是主题有序。一个主题可以横跨多个 broker,以此来提供比单个 broker 更强大的性能 。
3.3、Producer
消息生产者,向Broker发送消息的客户端
-
生产者生产消息持久化机制参数
- acks=0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。
- acks=1: 至少要等待leader已经成功将数据写入本地log,但是不需要等待所有follower是否成功写入。就可以继续发送下一
- acks=-1或all: 需要等待 min.insync.replicas(默认为1,推荐配置大于等于2) 这个参数配置的副本个数都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的数据保证。一般除非是金融级别,或跟钱打交道的场景才会使用这种配置。
-
retries 消息重试机制,在这种情况下, retries参数的值决定了生产者可以重发消息的次数,如果达到这个次数,生产者会放弃重试并返回错误。默认情况下,生产者会在每次重试之间等待100ms ,可以通过retry.backoff.ms 参数来配置时间间隔。
-
retry.backoff.ms:重试间隔时长
-
buffer.memory:设置发送消息的本地缓冲区,如果设置了该缓冲区,消息会先发送到本地缓冲区,可以提高消息发送性能,默认值是33554432,即32MB
-
batch.size:kafka本地线程会从缓冲区取数据,批量发送到broker,设置批量发送消息的大小,默认值是16384,即16kb,就是说一个batch满了16kb就发送出去
-
linger.ms:默认值是0,意思就是消息必须立即被发送,但这样会影响性能;一般设置10毫秒左右,就是说这个消息发送完后会进入本地的一个batch,如果10毫秒内,这个batch满了16kb就会随batch一起被发送出去;如果10毫秒内,batch没满,那么也必须把消息发送出去,不能让消息的发送延迟时间太长
3.4、Consumer
-
消息消费者,从Broker读取消息的客户端
-
Kafka 消费端也具备一定的容灾能力。 Consumer 使用拉 (Pull)模式从服务端拉取消息, 并且保存消费的具体位置 , 当消费者宕机后恢复上线时可以根据之前保存的消费位置重新拉取 需要的消息进行消费 ,这样就不会造成消息丢失 。
-
queue模式:所有的consumer都位于同一个consumer group 下。
-
publish-subscribe模式:所有的consumer都有着自己唯一的consumer group
-
auto.offset.reset:当消费主题的是一个新的消费组,或者指定offset的消费方式,offset不存在,那么应该如何消费
latest(默认) :只消费自己启动之后发送到主题的消息
earliest:第一次从头开始消费,以后按照消费offset记录继续消费,这个需要区别于consumer.seekToBeginning(每次都从头开始消费)
3.4、ConsumerGroup
每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个 Consumer Group中只能有一个Consumer能够消费该消息
3.5、Partition(分区)
-
物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的,
Kafka保证的是分区有序而不是主题有序 -
Kafka 为分区引入了多副本 (Replica) 机制, 通过增加副本数量可以提升容灾能力。
同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“一主多从”的关系,其中 leader副本负责处理读写请求, follower副本只负责与 leader副本的 消息同步。副本处于不同的 broker 中 ,当 leader 副本出现故障时,从 follower 副本中重新选举新的 leader副本对外提供服务。
进入kafka的bin目录,我是docker安装的在/opt/bitnami/kafka/bin
创建一个topic 设置副本因子3 分区3;其中一zookeeper指定了 Kafka所连接的 ZooKeeper服务地址,–topic指定了所要创建主题的名称, --replication-factor 指定了副本因子, --partitions 指定了分区个数,–create 是创建主题的动作指令
./kafka-topics.sh --create --zookeeper 192.168.0.113:2181 --replication-factor 3 --partitions 3 --topic test
查看topic test;–describe展示主题的更多具体信息
./kafka-topics.sh --describe --zookeeper 192.168.0.113:2181 --topic test

如上图中,test的topic分区数一共有3个,副本数有3个
- 分区0:Leader副本在broker.id=2的节点上
- Replicas:副本分别在broker.id=2 4 3 的节点上
- Isr:保持一定程度同步的副本id
消息会先发送到 leader副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)