mongoDB的三种基础备份方法
简单的介绍了mongoDB备份的三种方法
目录
一、物理备份-快照
使用快照进行备份是最常用的一种方法,很多企业的备份产品都是基于此(爱数、commvault等)。下面以爱数的备份原理图为例。
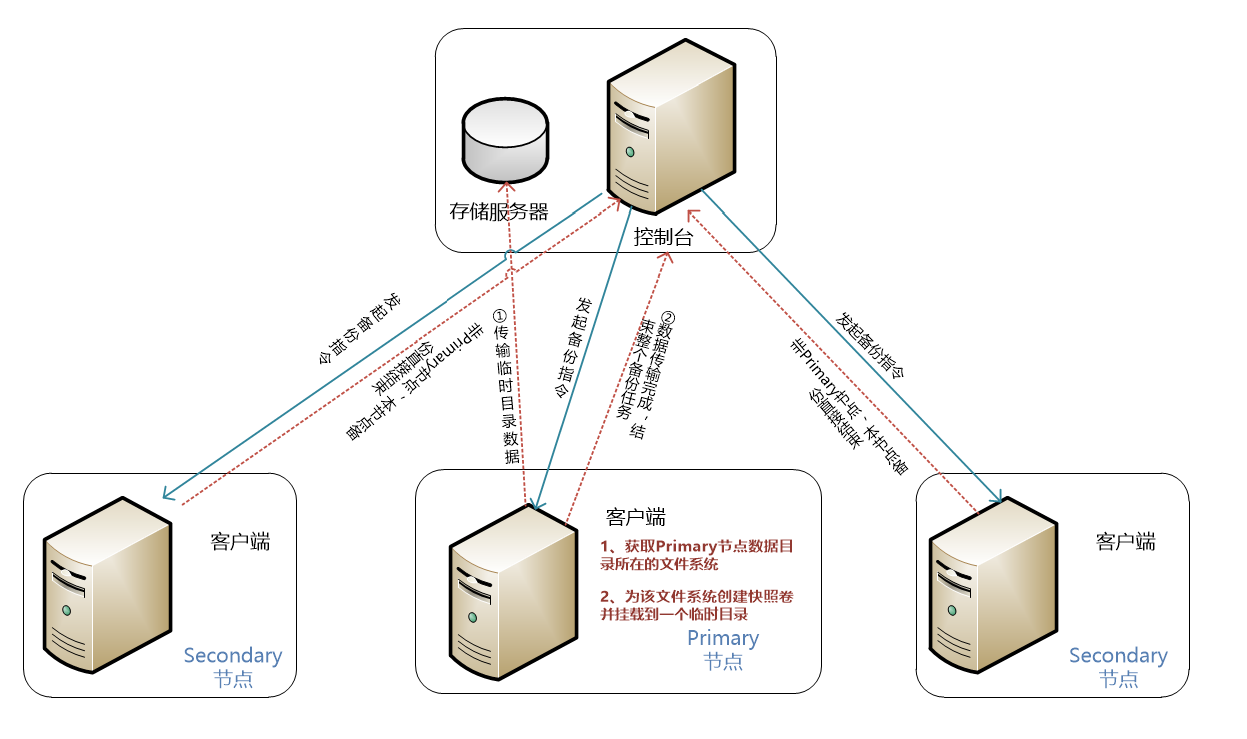
- 管理控制台启动备份任务。
- 控制台向各物理客户端的发送备份命令,各个客户端查找本机节点是否为 Primary(主)节点,如果不是 Primary(主)节点,该节点备份任务结束。
- Primary(主)节点所在客户端获取 MongoDB 数据目录所在的文件系统,为该文件系统创建快照卷并挂载到一个临时目录。
- 客户端传输该临时目录的数据到存储服务器。
- 客户端完成备份,上报任务备份情况到管理控制台,结束整个备份任务。
该方法的主要有点是速度快,使用方便。
缺点也比较明显:
1、副本集内所有的主机都必须保留 > 500MB 的VG卷空间。虽然只有主节点进行备份操作,但在副本集架构下所有节点都有可能成为主节点。
2、无法实现增量备份,理由很简单,其无法确定数据的变动,无法明确这个时间点的数据与上一次备份时间的的数据具体发生了哪些变化(当然一些牛逼的公司确实是做出来了,比如阿里)。
3、只能对mongod实例下的所有数据库进行集体备份,无法实现细粒度的数据库备份。
4、快照的数据恢复也是比较繁琐的,特别是异地恢复。
二、物理备份-数据文件拷贝
这种方法也是比较简单直接的,直接将mongoDB数据目录下所有的数据拷贝出来。但有几点需要注意。
1、拷贝操作发生前需要对数据库进行加锁操作。加锁后无法对数据库进行写操作,可能会影响正常业务。拷贝完成后记得解锁。
2、恢复时主机的环境与备份时需要尽可能的一致,包括数据库版本、操作系统等等。而且需要停止mongod实例。
这种方法的缺点与快照类似。具体的操作,示例如下所示:
# 进入mongo shell
db.fsyncLock()
# 退回到linux shell
# 将mongo的dbpath全部拷贝到缓存目录
cp -R /var/lib/mongo/* /backup
# 进入mongo shell
db.fsyncUnlock()三、逻辑备份-mongodump
mongodump是mongo集成的备份与恢复工具,功能也是十分的强大,其与mongorestore配合可以完成大多数场景的数据备份。不过在使用之前需要仔细的阅读相关文档,并实际操作测试其功能特性。而且需要注意,随着不同数据库的版本迭代,该工具的一些功能也会随之变化。
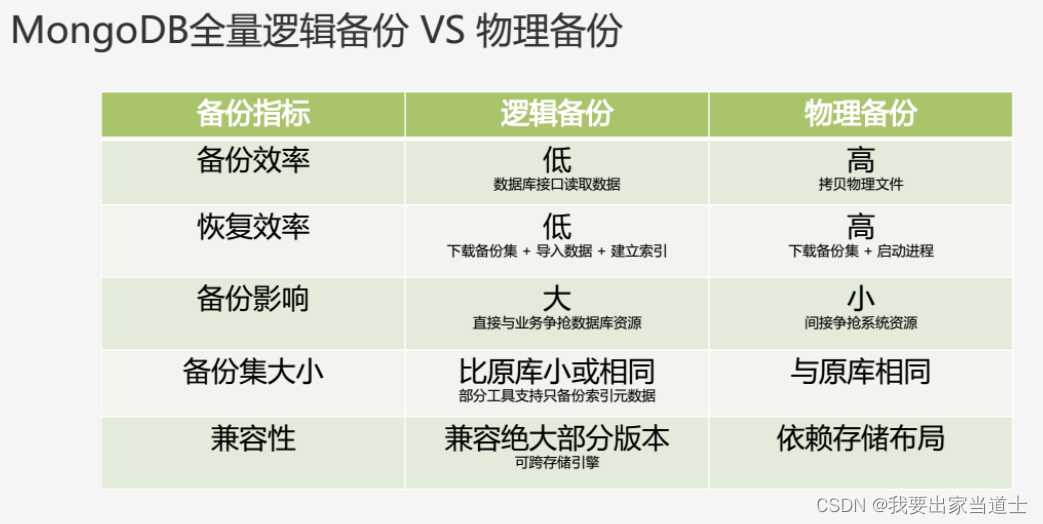
使用mongodump可以对数据库进行全量备份与增量备份,这个可以在网上搜到很多脚本例子。但其还是存在一些功能缺陷,不过好在其在github上开放了源码,用户可以基于其源码根据自己的需求进行修改。
他俩的还一个缺点就是性能太低了,远不如物理备份。所以很多厂商在做产品时都不会考虑它。
由于篇幅的问题(懒),该工具的具体的使用方法见下面的链接mongodump — MongoDB Manual
mongorestore — MongoDB Manual

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)