重磅升级!TDengine3.0正式发布
可以支持 10 亿个设备采集的数据、100 个节点;支持存储与计算分离,引入计算节点,并重构了整个计算引擎;完善并优化了对消息队列、流式计算和缓存的支持,引入事件驱动的流式计算!
2022 年 8 月 13 日,TDengine 3.0 正式发布了!经过一年多的努力研发,我们终于可以骄傲地宣布这一消息。
这是一次重磅升级,TDengine 3.0 是真正的云原生时序数据库(Time-Series Database,TSDB)。
我们先来整体看一下 3.0 的几大亮点:
TDengine 面市以来,从 1.0 到 2.0,从核心功能开源到集群功能开源,得到了大量商业客户和社区用户的高度认可,全球安装的 TDengine 运行实例数已经接近 14 万,每天有超过 1000 人次克隆代码,在全球开发者中产生了一定的影响力。日常有大量的社区开发者基于自己的业务需求,提出 issue,贡献功能,社区非常活跃。
作为一款开源的时序数据库产品,TDengine 已经广泛应用于物联网、工业互联网、车联网、金融、IT 运维监控等场景。目前已经有大量的企业客户和社区用户将 TDengine 部署在其核心业务场景中。用户场景越多,TDengine 得到的用户需求和反馈越多,正是这些需求和反馈在推动着 TDengine 不断演进。
经常关注 TDengine 的用户应该都很熟悉了,我们已经发布了上百篇用户案例,这都是企业客户和开源用户的第一手实践经验。有心的读者都会发现,在每篇用户案例的末尾,用户也毫不讳言在使用 TDengine 过程中遇到的问题,更是提出了对 TDengine 的更多期待。这都是 TDengine 优化迭代的动力。
下面我们详细看一下 TDengine 3.0 的核心功能。
1. 云原生
TDengine 3.0 可以充分利用云计算平台以及分布式系统的优势。作为一款云原生,而不只是能在云上运行的时序数据库,TDengine 3.0 具备云原生数据库的几大特点:水平扩展性(Scalability)、弹性(Elasticity)、韧性(Resiliency)、可观测性(Observability)以及运维自动化(Automation)。我们就结合 TDengine 的逻辑架构,依次看看它是如何实现这几大特点的。
水平扩展性(Scalability)
TDengine 通过数据采集点和时间两个维度对大数据进行切分,从而实现了水平扩展能力,既支持分片,也支持分区。通过将每个数据采集点的元数据分布在各个 vnode 里,而不是存放在中心点,我们解决了困扰时序数据库的高基数(High Cardinality)问题。TDengine 具有超强的水平扩展能力,为获得更多的数据处理能力,只需要加入更多的数据节点即可。通过测试,我们可以验证,在 10 亿时间线,100 个数据节点的情况下,整个 TDengine 性能还能得到很好的保证。
弹性(Elasticity)
作为一个云原生数据库,TDengine 3.0 支持 scale up / scale down。为支持存储的弹性,如果插入的延时已经超过一定阈值或者性能不够,TDengine 会将一个 vnode 拆分成两个,从而分配更多的系统资源给数据写入操作。另一方面,在能够保证延时与性能的情况下,TDengine 也可以把多个 vnode 合并成一个,以节省系统资源。
为支持计算的弹性,TDengine 3.0 引入了计算节点 qnode。对于简单的查询,比如获得某张表的原始数据或卷曲数据(rollup data),对应的 vnode 将完成所有的操作,无需 qnode 的参与。但对于一个需要排序、分组或其他需要计算资源的操作,查询的执行过程中,一个或多个 qnode 将被调用。在具体的部署中,qnode 可以运行在容器里,它的启停完全由 mnode 根据系统负载情况决定。
通过引入 qnode,TDengine 3.0 成为一个理想的时序数据分析平台,包括实时数据分析和批分析。
韧性(Resiliency)
TDengine 的韧性是通过其高可靠与高可用设计来实现的。TDengine 采用 Database 实现中传统的方法 WAL(Write Ahead Log) 来保证数据的高可靠。TDengine 通过多副本以及 RAFT 一致性协议,保证 vnode 和 mnode 的高可用性。
可观测性(Observability)
TDengine 会采集各种指标来监测自身的运行是否正常,这些指标包括 CPU、内存、磁盘、流量、请求次数、延时等。我们提供了 Grafana 的看板 TDinsight,以实现这些指标的可视化与报警。
TDengine 还有一个配套模块 taosKeeper,能够将采集的指标发送到其他监测工具(如 Prometheus),便于将对 TDengine 的监测集成到已有的可观测系统。
运维自动化(Automation)
TDengine 可以用二进制包或 Docker 镜像进行安装,也支持通过 Kubernetes 来部署和管理集群。其集群的管理完全可以通过脚本自动化进行,让运营和维护变得简单。
2. 极简的时序数据平台
熟悉 TDengine 的用户,可能已经使用过其连续查询、缓存和消息队列等功能。在 3.0 中,我们又重新设计并优化了相关功能。
特别是流式计算,除连续查询外,3.0 还支持事件驱动的流计算,而且采用 SQL 语法,支持自定义函数,让流计算的学习成本几乎为零。例如,我们可以用如下语句创建流式计算,它会自动创建名为 avg_vol 的超级表,此流计算以一分钟为时间窗口、30 秒为前向增量统计这些电表的平均电压,并将来自 meters 表的数据的计算结果写入 avg_vol 表,不同 partition 的数据会分别创建子表并写入不同子表。
CREATE STREAM avg_vol_s INTO avg_vol AS
SELECT _wstartts, count(*), avg(voltage) FROM meters PARTITION BY tbname INTERVAL(1m) SLIDING(30s);消息队列方面,可指定各种过滤条件,应用可以仅仅订阅满足条件的数据,而且对外提供的 API 与 Kafka 类似,简单易用。
在时序数据处理平台的通用设计中,逻辑图一般如下所示:
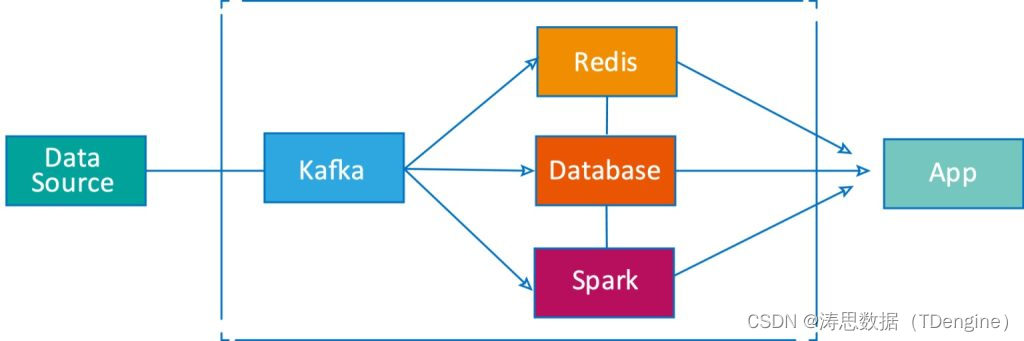
而通过对缓存、流式计算、消息队列的支持,采用 TDengine 的时序数据处理系统,不再需要集成 Kafka、Redis、Spark 和 Flink 等软件,技术架构将大为简化,部署、运营维护成本将大为降低。逻辑结构可以直接简化为:

由此可见,TDengine 不只是一个时序数据库,还是一个极简的时序数据处理平台。
3. 便捷的数据分析能力
TDengine 3.0 重新设计了计算引擎,支持标准 SQL,支持嵌套查询,支持自定义函数,支持 Information Schema 系统数据库;针对时序数据的处理进行扩展,提供累计求和、时间加权平均、移动平均、变化率、session/state 窗口等众多时序数据分析功能;通过标签快速索引,通过分区、分片技术,通过计算节点的弹性伸缩,支持对海量时序数据的多维度的高效聚合分析。
有了新的计算引擎的加持,特别是计算与存储的分离的支持,TDengine 不仅能实时地处理数据的写入和查询,也能作为强大的时序数据分析工具。
更多细节,可以参阅相关说明:https://github.com/taosdata/TDengine。
借助 TDengine 3.0 的云原生能力,用户可以更方便地利用云平台的能力,简化部署和维护,进一步降本增效;极简的时序数据平台和强大的分析功能,也能帮助用户简化业务架构、简化应用设计,降低系统的维护成本,提升处理效率。
架构升级,先人一步,赶快点击下载链接,感受 TDengine 3.0 带来的全新体验吧。
想了解更多 TDengine Database的具体细节,欢迎大家在GitHub上查看相关源代码。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 2
2 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)