HIVE 增加修改删除字段
HIVE 增加修改删除字段非分区表增加字段修改字段(修改字段名称、类型、注释、顺序)删除字段分区表新增字段非分区表增加字段增加字段可以使我们在所有字段之后和分区字段之间增加一个字段使用格式ALTER TABLE table_nameADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)[CASCADE|RESTRICT
非分区表
增加字段
增加字段可以使我们在所有字段之后和分区字段之间增加一个字段

使用格式
ALTER TABLE table_name
ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
[CASCADE|RESTRICT] -- (Note: Hive 1.1.0 and later)
使用示例,在 user_info 中增加 user_addr 字段,现有的表数据如下:

ALTER TABLE user_info ADD COLUMNS (user_addr string COMMENT '用户地址');

当我增加新的字段 user_addr 后,新增字段前的数据该列显示为 NULL ,那么如果我们新增一条数据呢?
INSERT INTO TABLE user_info
SELECT '003' as user_id, 'jack' as user_name, '34' as age, '广东深圳' as user_addr
;
结论:非分区表新增字段后,原有数据的该字段会显示为 NULL,新增的数据会按新增的数据进行展示

还没结束,我们向 user_info 再新增 user_appr 字段的时候再加下这两个 CASCADE、RESTRICT 属性,看看会发生什么
ALTER TABLE user_info ADD COLUMNS (user_appr string COMMENT '用户偏好') CASCADE;

添加 CASCADE 后执行失败,说明非分区表再添加字段时不能加CASCADE
ALTER TABLE user_info ADD COLUMNS (user_appr string COMMENT '用户偏好') RESTRICT;

添加RESTRICT 后执行成功,该语法具体含义后面再述
修改字段(修改字段名称、类型、注释、顺序)
修改前

修改字段 user_addr 的字段名称为 user_address
ALTER TABLE user_info CHANGE user_addr user_address string;

修改 user_address 的顺序,将该段放置在 user_appr 后
# 不支持,执行报错
# 语义:将user_address 更改为 user_address,类型为 string,放置在 user_appr 后面
ALTER TABLE user_info CHANGE is_active is_active string AFTER user_appr;
修改 is_active 字段的类型为 string,修改前为 int
ALTER TABLE user_info CHANGE is_active is_active string;
修改 user_address 字段的中文注释
ALTER TABLE user_info CHANGE user_address user_address STRING COMMENT '修改字段注释';
注意:以上的修改,仅仅是实现了修改元数据,实际的 HDFS 文件并没有修改,这个很关键
删除字段
HIVE 不能直接删除字段,且删除字段的操作有很大的局限性,一般尽量删除后面的字段,但是如果直接从中间删除,可能会出出现错位的情况。而且尽量不要有删除字段的操作

-- 示例:删除 user_age 字段
ALTER TABLE user_info REPLACE COLUMNS (user_id STRING, user_name STRING);
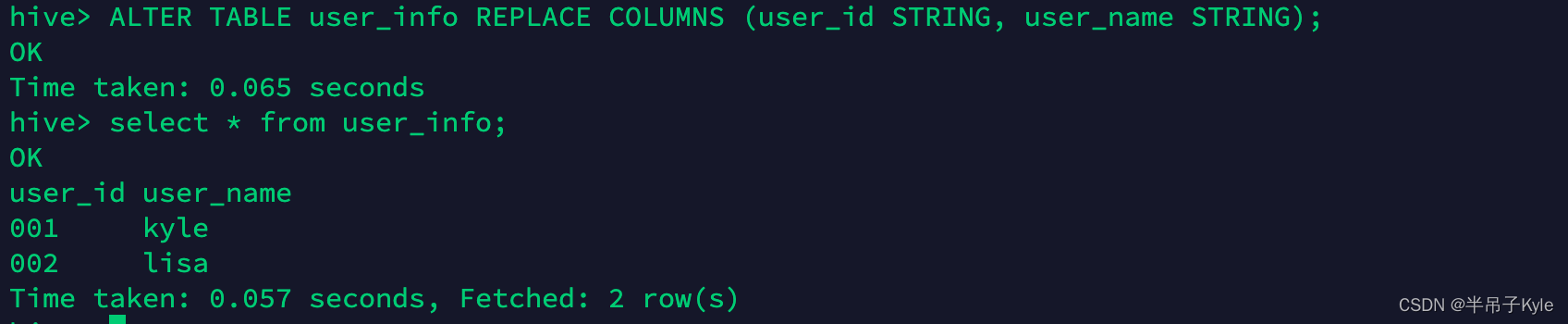
看到结果,我们发现 user_age 字段确实已经被移除了,这时我们如果执行添加 user_age 会发生什么情况
ALTER TABLE user_info ADD COLUMNS (user_age STRING COMMENT '用户年龄');

添加字段后,我们发现,之前该列的数据重新恢复了,并不是我们期望的 NULL 。因此,我们可以得出结论:HIVE 删除字段只是修改了元数据而已,真实的文件数据并没有被删除
分区表
新增字段
首先我们创建一张分区表
CREATE TABLE IF NOT EXISTS cust_info
(
user_id string COMMENT '用户ID'
,user_name string COMMENT '用户姓名'
,user_age string COMMENT '用户年龄'
)
COMMENT '客户信息表'
PARTITIONED BY (ds STRING COMMENT'分区')
;
INSERT OVERWRITE TABLE cust_info partition(ds = '20220223')
SELECT '001' as user_id, 'kyle' as user_name, '23' as user_age
UNION ALL
SELECT '002' as user_id, 'lisa' as user_name, '25' as user_age
;
我们新增一个字段 user_addr 字段试试
ALTER TABLE cust_info ADD COLUMNS (user_addr string COMMENT '用户地址')
;
新增完毕后,我们发现 20220223 分区中的数据 user_addr 列已经出现了,而且该列的值全部为 NULL

不符合我们的期望,我们来重新对该分区覆盖插入数据,并对该分区插入数据,对该列赋值
INSERT OVERWRITE TABLE cust_info partition(ds = '20220223')
SELECT '001' as user_id, 'kyle' as user_name, '23' as user_age, '中国深圳' as user_addr
UNION ALL
SELECT '002' as user_id, 'lisa' as user_name, '25' as user_age, '中国北京' as user_addr
;
插入数据后重新查看,发现该列的值仍然为 NULL ,这是怎么回事

看下官方的文档

大概的意思为:新增字段时,默认为 RESTRICT ,这样只会修改元数据,并不会对历史分区生效,因此在刷历史数据的时候不生效。为了对历史分区生效,需要增加 CASCADE。只对历史分区有影响,新建分区则没有影响
我们删除表结构,然后重新插入数据并执行新增字段操作试试
ALTER TABLE cust_info ADD COLUMNS (user_addr string COMMENT '用户地址') CASCADE
;

历史分区数据重新刷入成功
另外一种方法:先删除分区,然后重新插入数据(我司的解决办法)
修改字段(change column)
HIVE ALTER COLUMN 官方介绍
SPARK ALTER COLUMN 官方介绍
注意,博主使用的是 HIVE ON MR - HIVE 2.1
语法介绍
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type
[COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
This command will allow users to change a column’s name, data type, comment, or position, or an arbitrary combination of them. The PARTITION clause is available in Hive 0.14.0 and later; see Upgrading Pre-Hive 0.13.0 Decimal Columns for usage. A patch for Hive 0.13 is also available (see HIVE-7971).
通过该语法用户可以修改字段的名称、类型、注释、分区,可以组合修改
注意,CASCADE 和 RESTRICT(默认) 的区别,CASCADE不仅修改元数据,还将作用于历史分区。RESTRICT仅修改元数据,但是会对新建的分区生效
使用示例
-- 先建表插数
CREATE TABLE IF NOT EXISTS customer_info
(
user_id string COMMENT '用户ID'
,user_name string COMMENT '用户姓名'
,user_age int COMMENT '用户年龄'
)
COMMENT '客户信息表'
PARTITIONED BY (ds STRING COMMENT'分区')
;
INSERT OVERWRITE TABLE customer_info partition(ds = '20220223')
SELECT '001' as user_id, 'kyle' as user_name, 23 as user_age
UNION ALL
SELECT '002' as user_id, 'lisa' as user_name, 25 as user_age
;
-- 修改 user_id 字段为 id
ALTER TABLE customer_info CHANGE user_id id string;

-- 修改 age 字段类型为 string, 并且修改字段顺序到 user_name 之后
ALTER TABLE customer_info CHANGE user_age age int AFTER user_name;

-- 分区表修改的语法
SET hive.exec.dynamic.partition = true;
ALTER TABLE customer_info PARTITION (ds) CHANGE COLUMN age user_age DECIMAL(38,18);
替换字段(replace column)
REPLACE COLUMNS 删除所有现有的字段列表并替换为新的字段列表。 这只能用于具有本地的序列化 SerDe(DynamicSerDe、MetadataTypedColumnsetSerDe、LazySimpleSerDe 和 ColumnarSerDe)的表。
使用示例
-- 先建表插数
CREATE TABLE IF NOT EXISTS customer_info
(
user_id string COMMENT '用户ID'
,user_name string COMMENT '用户姓名'
,user_age int COMMENT '用户年龄'
)
COMMENT '客户信息表'
PARTITIONED BY (ds STRING COMMENT'分区')
;
INSERT INTO customer_info partition(ds = '20220223') VALUES('001', 'kyle', 23),('002', 'jack', 24);
INSERT INTO customer_info partition(ds = '20220224') VALUES('003', 'lisa', 23);
-- 将三个字段全部替换
ALTER TABLE customer_info REPLACE COLUMNS (ecif string, name string COMMENT 'new comment', age_info int);

-- 只替换一个字段看下是什么情况
ALTER TABLE customer_info REPLACE COLUMNS (user_id string);
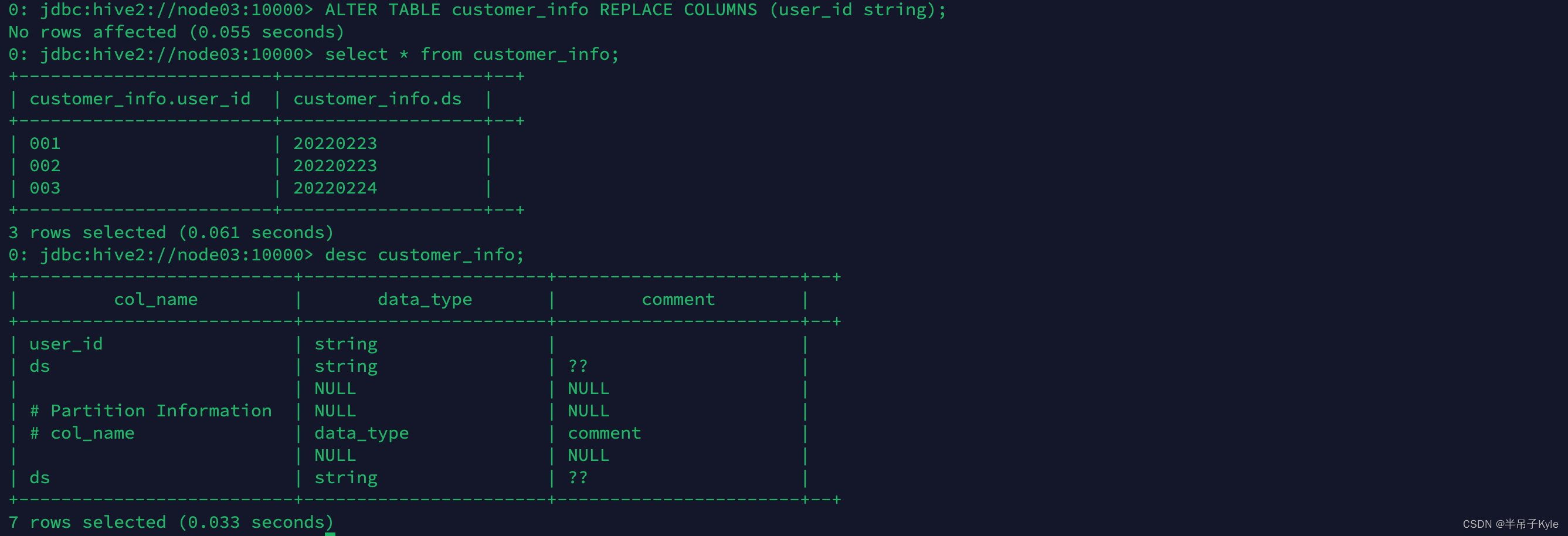
这个语法使用的场景很少,用通俗易懂的解释就是:用新的字段列表替换旧的字段列表,一定要注意对应的字段类型相同,否则会报错,和 SPARK 的语法使用起来有区别,SPARK 把分区字段也算做可替换的字段了

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)