DBEAVER导入导出的一些细节
今天真的想吐槽dbeaver。你说,你要那么多参数干什么?导入导出的功能在这个地方。还有这个地方:导出全表用前两个,导出函数用第三个。然后是下一个。导出的第一个是导出格式。其中我经常导出的是SQL、CSV。反正很强大。FETCH size:缓存大小。就是说:我一次SQL缓存1000行。当你读完这1000行的时候再继续执行。导出格式。我以CSV为例,导出的时候是以什么为分隔?这个是以逗号为分隔。还有
导入导出的功能位置。
数据库右键,有导入和导出功能。
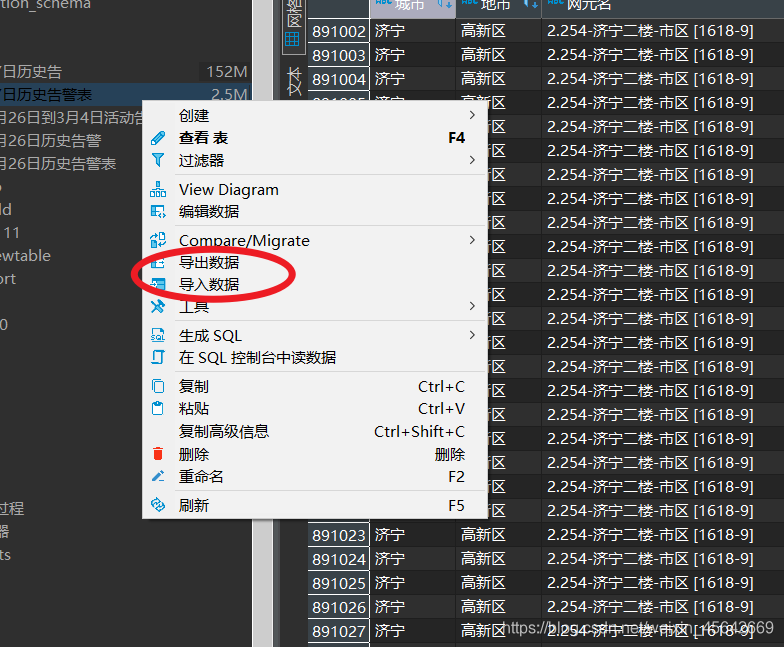
sql执行位置也存在:
导出全表用前两个,导出函数用第三个。
导入:
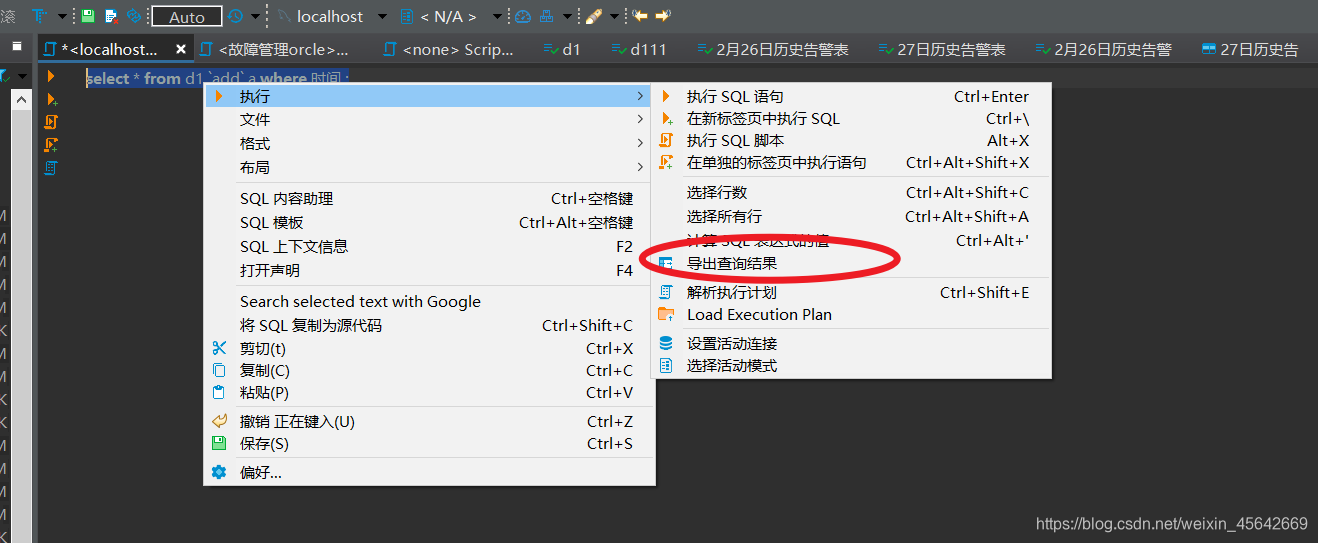
 导出的第一个是导出格式。其中我经常导出的是SQL、CSV。
导出的第一个是导出格式。其中我经常导出的是SQL、CSV。
不支持EXCEL格式
提速方式
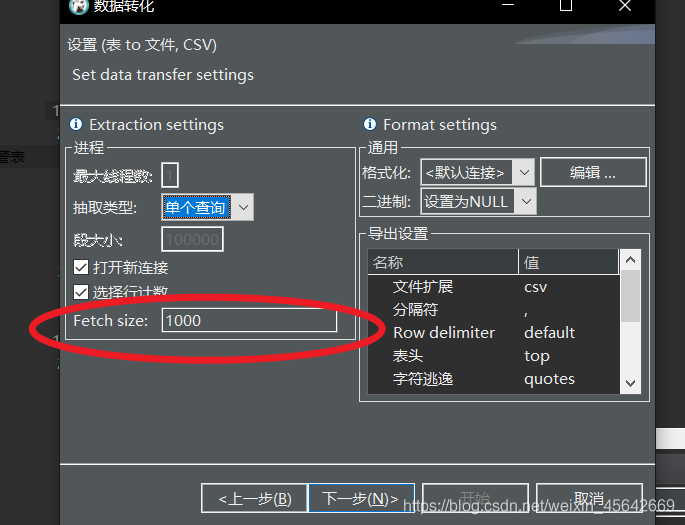
FETCH size:缓存大小。如果过大会异常,过小会太慢
设置FETCH size 1000, 就是说:我一次SQL缓存1000行。当你读完这1000行的时候再继续执行。
在计算机上开辟能读取1000行的缓存区,当这个行数满了以后写磁盘。
更新:本人执行的时候,50W行一般设置为20W行(本人16G内存i7-8750,性能差的请酌情减少),1000行时间都浪费在刷磁盘上了。
可以修改参数,所以dbeaver导入导出的时候速度是最快的。我跑过100M/的内网读写速度(ORACLE,主键索引)
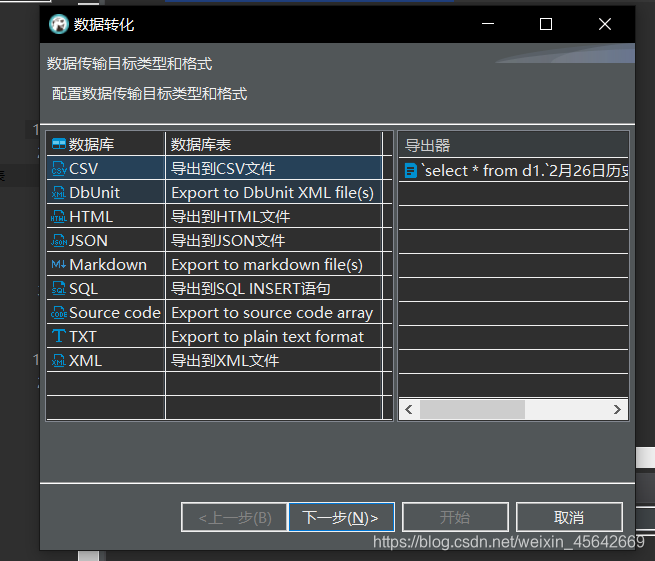
设置导出格式
我以CSV为例,导出的时候可以配置分隔符。
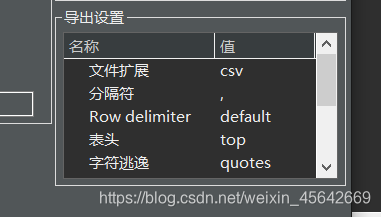 更新:
更新:
使用这个字符可以将所有文件转化为字符串(dbeeaver汉化似乎有点差……)

修改文件编码、文件名、时间格式
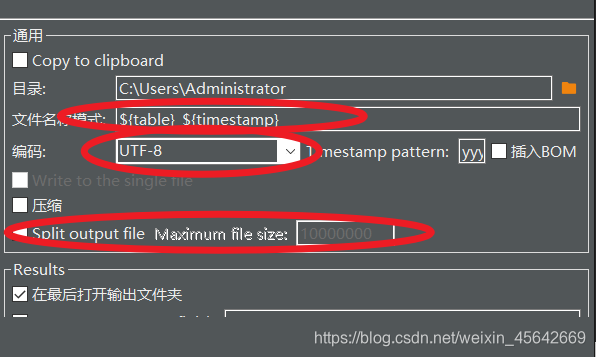
文件名,这个文件名现在是正则匹配的。
然后是分区,当文件大小大于这个值的时候分成多个文件。
然后中间是编码。如果不是GBK格式,在EXCEL里面会乱码。
CSV格式的文件不是GBK格式在EXCEL中会乱码!!!!!!!!!!!!!!
导入
导入之前,要做这么几个设置: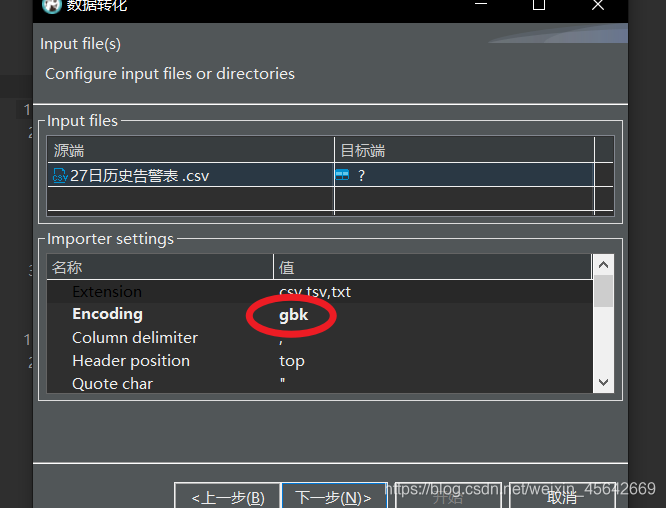 编码要导入,不然的话就会乱码。
编码要导入,不然的话就会乱码。
注意:这个工具需要设置一行的最小长度,设置大一点!!
还有这两个: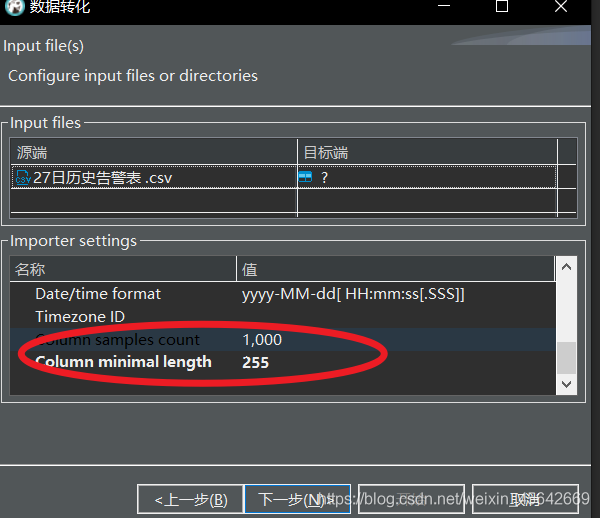 其中第一个参数说:先预读多大的字符串,然后和格式进行比对。
其中第一个参数说:先预读多大的字符串,然后和格式进行比对。
bug / 特性
dbeaver系统会自动选择前XX行(就是column samples count)最大值作为列宽。
如果第XX+ 1行宽度超限,那就直接BUG,导入崩溃。
有人说:我找不到啊。
右边有个滑动框,拉到底。
将宽度设置为最大字段varchar(XX)长度。
更新bug:如果里面有两个标题列或者某一行的数据有问题,会直接崩溃。
比如,某一行定义为int,导入数据“张三”,会直接在哪一行终止导入。
所以要写大,写个255没问题。如果你有超过255字符的长字符串,还要手工指定。
不然也会报错。
你要修改COLumns的参数,不然的话会导致格式不匹配。如果有一个特别长的,还要手工修改宽度,不然报错。
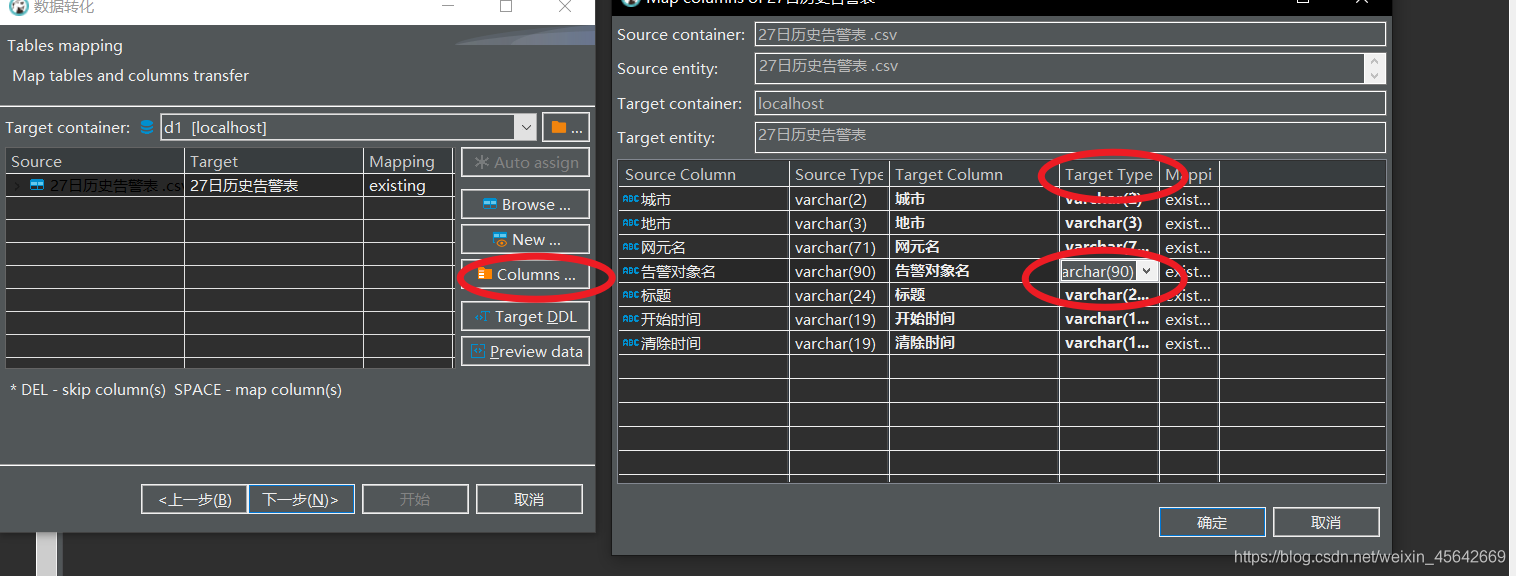
然后就可以开始导入了。
锁表风险
导入的时候如果该列不存在,dbeaver会新增一个列。
这会导致修改表结构,如果是大表会当场锁表并且耗费资源,而且不可逆。
(千万千万注意!!!!!!!!!!!!如果是生产库有几亿条数据,导入的时候就崩了!!!!而且我没有发现任何提示!!!!!!!)
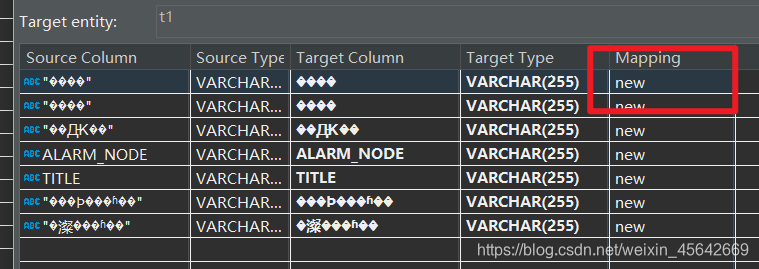 这个算一个很坑的地方。
这个算一个很坑的地方。
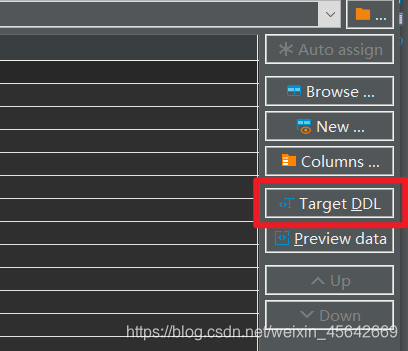
需要保证:查看列,里面没有NEW。或者查看DDL,保证里面没有语句。
问题:概率会时间解析失败,需要手写日期解析器。
如果你的时间格式不规范,会解析的时间错误,比如1900打头(解析年失败)或者直接为空(全部解析失败)
看的时候记住:千万别在有实际业务的表格进行导入导出,概率锁表。
应该新增一个表格,然后通过该表格进行insert。
NAVICAT时间解析也是一样,1900打头(解析年失败)或者直接为空(全部解析失败)。但是支持EXCEL。
dbeaver的问题:
- 没有导出提示,导出多少没有进度条。Navicat有
- 想要退出导出,必须要关闭导出,而关闭导出如果网络不好很慢很卡。
- 需要配置大量参数,不适合小白导出。
- 不支持EXCEL的导入导出。
- 不支持批量数据的导入导出,只支持一个文件。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 20
20 1
1- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)