Oracle数据库SQL优化详解
Oracle数据库SQL优化1. Oracle SQL优化概述2. Oracle SQL优化详解2.1 Oracle 查询阻塞2.2 Oracle 查询耗时 SQL2.3.Oracle 查看执行计划2.4.Oracle 查看收集统计信息2.5.Oracle 查询优化器 -- 改写查询语句2.6.Oracle 查询优化器 -- 访问路径2.7.Oracle 查询优化器 -- 表连接方法2.8.Ora
Oracle数据库SQL优化
- 1. Oracle SQL优化概述
- 2. Oracle SQL优化详解
- 2.1 Oracle 查询阻塞
- 2.2 Oracle 查询耗时 SQL
- 2.3.Oracle 查看执行计划
- 2.4.Oracle 查看收集统计信息
- 2.5.Oracle 查询优化器 -- 改写查询语句
- 2.6.Oracle 查询优化器 -- 访问路径
- 2.7.Oracle 查询优化器 -- 表连接方法
- 2.8.Oracle 索引
- 2.9.Oracle 视图
- 2.10.Oracle 减少数据库访问次数
- 2.11 Oracle 面向对象
- 2.12 Oracle 分开执行耗时操作
- 2.13 Oracle 子程序内联
- 2.14 Oracle 动态 SQL
- 2.15 Oracle 避免在查询中使用函数
- 2.16 Oracle 指定子程序 OUT 或 IN OUT 参数为引用传递
- 2.17 Oracle 尽量少用循环语句
- 2.18 Oracle 数据类型使用注意事项
- 2.19 Oracle 字符串处理
- 2.20 Oracle 短路评估
- 2.21 Oracle 并发更新大表
1. Oracle SQL优化概述
我们所执行的sql语句Oracle并不会直接去执行,而是经过数据库优化器优化以后再去执行。但是毕竟Oracle优化器也不是万能的,也有Oracle自身无法实现的优化语句,这就需要我们在书写sql语句的时候需要注意。注意SQL规范有助于避免SQL性能问题,也能避免不必要的异常。
对于Oracle的sql语句优化也是有序可循的,按照步骤依次分析梳理,找出根源所在,针对性优化才有效果,而不是盲目来一通,以下是简单梳理优化步骤。
Oracle 查询阻塞,查询耗时 SQL,查看执行计划,查看收集统计信息,查询优化器 – 改写查询语句,查询优化器 – 访问路径,查询优化器 – 表连接方法,索引,视图,减少数据库访问次数,面向对象,分开执行耗时操作,子程序内联,动态 SQL,避免在查询中使用函数,指定子程序 OUT 或 IN OUT 参数为引用传递,尽量少用循环语句,数据类型使用注意事项,字符串处理,短路评估,并发更新大表。
2. Oracle SQL优化详解
2.1 Oracle 查询阻塞
如果你的 SQL 或系统突然 hang 了,很有可能是因为一个 session 阻塞了另一个 session,如何查询是否发生阻塞了呢?看看下面的 SQL吧。
-- 如果你的 SQL 或系统突然 hang 了,很有可能是因为一个 session 阻塞了另一个 session,如何查询是否发生阻塞了呢?看看下面的 SQL吧。
select
blocksession.sid as block_session_sid,
blocksession.serial# as block_session_serial#,
blocksession.username as block_session_username,
blocksession.osuser as block_session_osuser,
blocksession.machine as block_session_machine,
blocksession.status as block_session_status,
blockobject.object_name as blocked_table,
waitsession.sid as wait_session_sid,
waitsession.serial# as wait_session_serial#,
waitsession.username as wait_session_username,
waitsession.osuser as wait_session_osuser,
waitsession.machine as wait_session_machine,
waitsession.status as wait_session_status
from
v$lock blocklock,
v$lock waitlock,
v$session blocksession,
v$session waitsession,
v$locked_object lockedobject,
dba_objects blockobject
where
blocklock.block = 1
and blocklock.sid != waitlock.sid
and blocklock.id1 = waitlock.id1
and blocklock.id2 = waitlock.id2
and blocklock.sid = blocksession.sid
and waitlock.sid = waitsession.sid
and lockedobject.session_id = blocksession.sid
and lockedobject.object_id = blockobject.object_id;
-- 如果上面的语句返回了结果,表明发生了阻塞,这个时候你可以把使用 blocksession 的程序停掉。
-- 如果还是不能解决问题,那只能让 DBA 帮你把 blocksession kill 掉,如何 kill 呢? 试一试下面的语句吧。
ALTER SYSTEM KILL SESSION '<block_session_sid>,<block_session_serial#>';
ALTER SYSTEM KILL SESSION '113,55609';
如果没有发生阻塞,系统就是很慢,该怎么办呢?在" Oracle 查询耗时 SQL"找答案吧。
2.2 Oracle 查询耗时 SQL
当你的系统变慢时,如何查询系统中最耗时的 SQL 呢?试一试下面的 SQL 吧。
select * from (
select * from V$SQLSTATS
-- 最耗时的 SQL
-- ELAPSED_TIME 指的是总耗时(毫秒),平均耗时 = ELAPSED_TIME/EXECUTIONS
-- order by ELAPSED_TIME DESC
-- 查询执行次数最多的 SQL
-- order by EXECUTIONS DESC
-- 读硬盘最多的 SQL
-- order by DISK_READS DESC
-- 最费 CPU 的 SQL
-- order by BUFFER_GETS DESC
) where rownum <=50;
一旦查询到耗时 SQL,你需要查看一下它们的执行计划才能知道它们为什么慢,不知道如何查询执行计划?看看这里吧 <Oracle 查看执行计划>。
2.3.Oracle 查看执行计划
我们可以通过 EXPLAIN PLAN 语句生成执行计划,该语句把执行计划保存到一个叫做 PLAN_TABLE 的表中,我们可以通过查询这个表来查看执行计划。下面是一个简单例子。
查看执行计划的两种方式:1.EXPLAIN PLAN。2.autotrace。3.plsql查看执行计划菜单或者F5查看。
1.EXPLAIN PLAN
-- 生成执行计划
EXPLAIN PLAN
SET STATEMENT_ID = 'test'
FOR
select * from employees where employee_id < 10;
-- 由于 PLAN_TABLE 表非常复杂,Oracle 提供下面的方式察看执行计划
SELECT PLAN_TABLE_OUTPUT FROM TABLE(DBMS_XPLAN.DISPLAY('PLAN_TABLE', 'test', 'ALL'));
-- 如果你想察看更多细节,你也可以直接查询表
select * from plan_table where statement_id = 'test'
2.autotrace
如果你使用的是 sqlplus 工具,你还可以通过它提供了 autotrace 功能来查看执行计划,你只需要下面的两步,非常简单,下面是一个简单的例子。
-- 第一步: 打开 autotrace
SQL> set autotrace on
-- 第二步: 执行 SQL 语句
SQL> select * from test;
3.plsql查看执行计划菜单或者F5
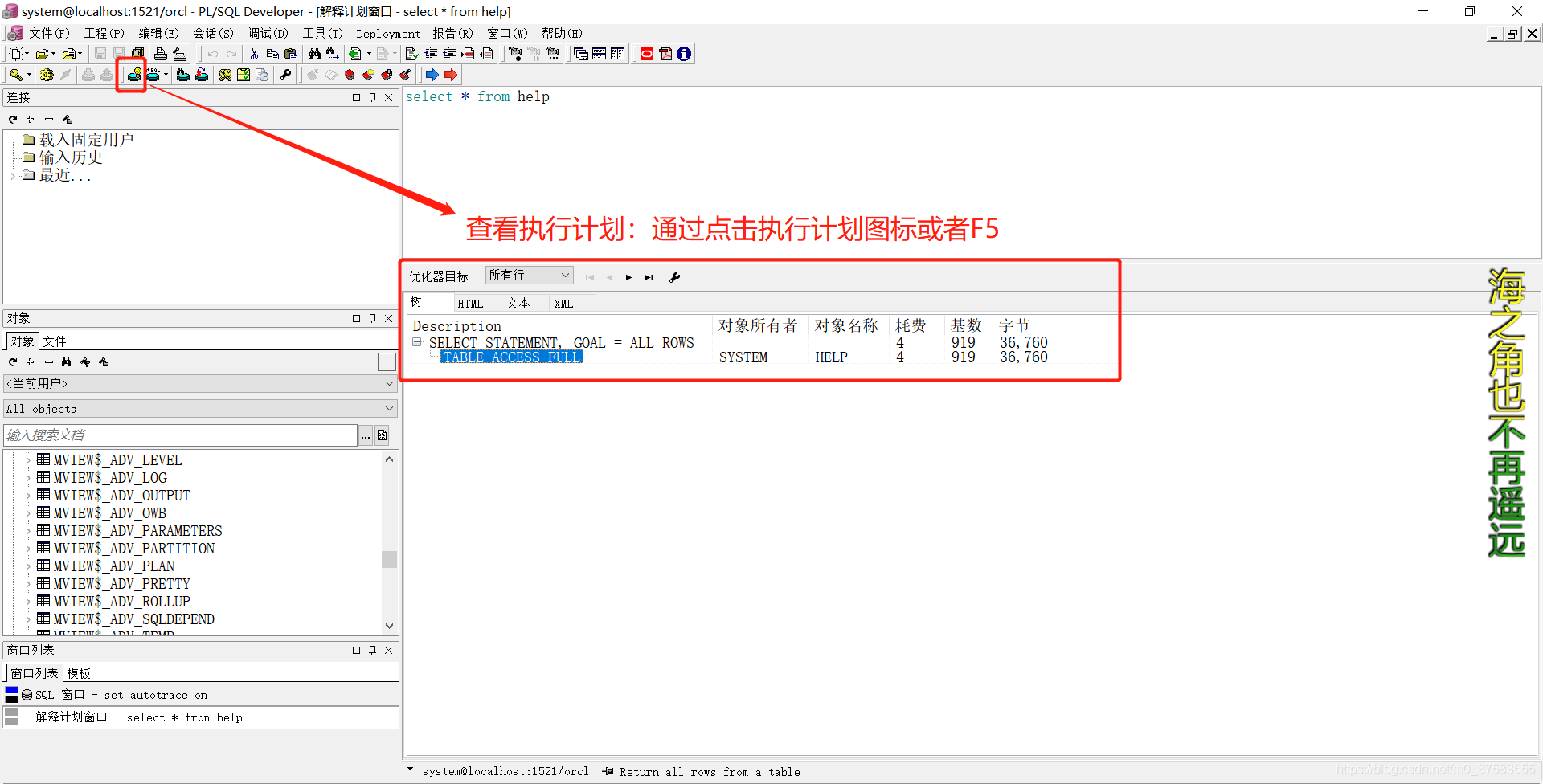
4.V$SQL_PLAN
上面查看执行计划的方式有一个缺陷,它们必须由人触发,随着执行环境,时间,统计信息等的不同,执行计划有可能不同,有没有办法查看已经执行过 SQL 的执行计划呢?答案是肯定的,下面是一个简单的例子。
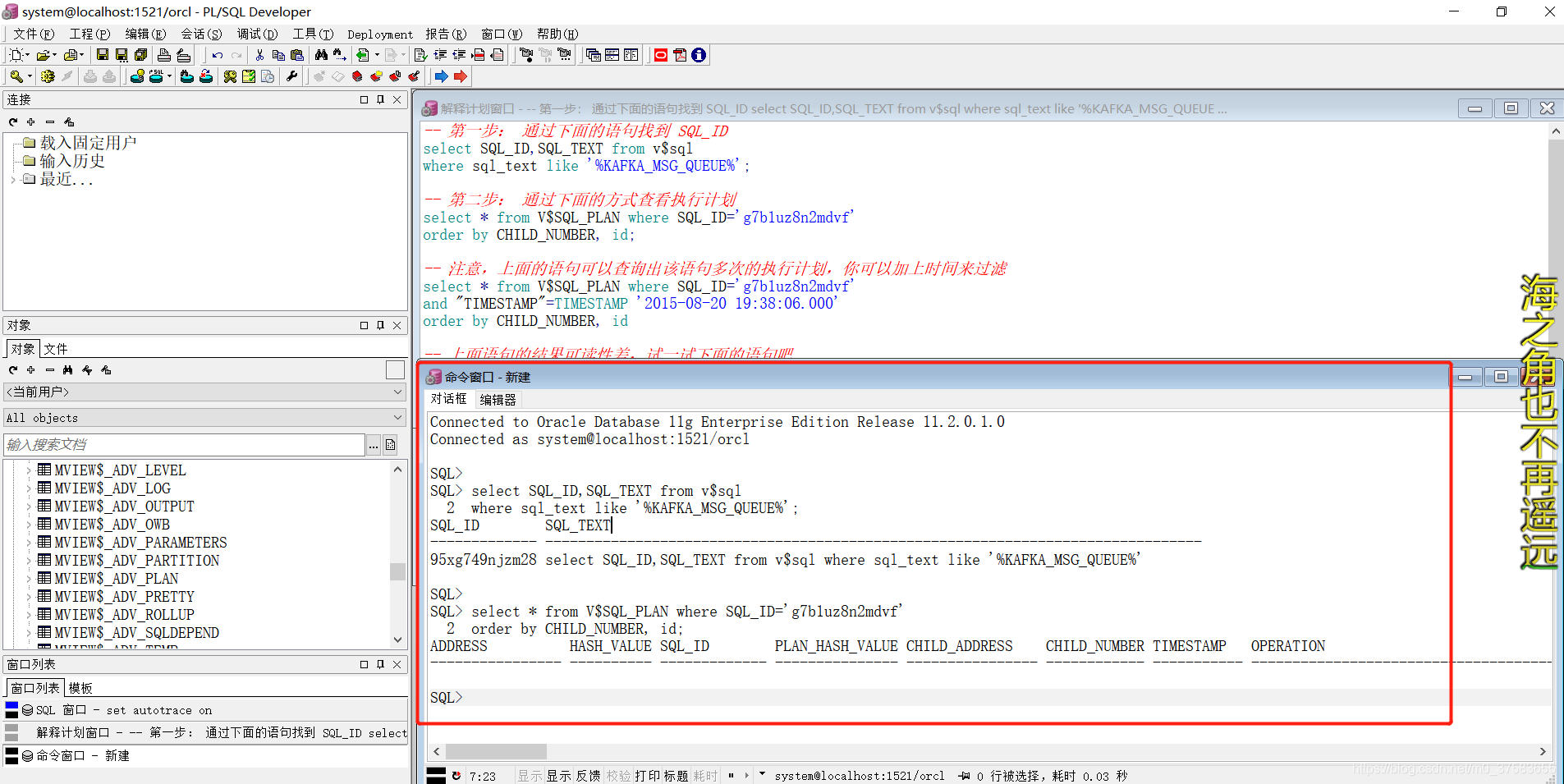
-- 第一步: 通过下面的语句找到 SQL_ID
select SQL_ID,SQL_TEXT from v$sql
where sql_text like '%KAFKA_MSG_QUEUE%';
-- 第二步: 通过下面的方式查看执行计划
select * from V$SQL_PLAN where SQL_ID='g7b1uz8n2mdvf'
order by CHILD_NUMBER, id;
-- 注意,上面的语句可以查询出该语句多次的执行计划,你可以加上时间来过滤
select * from V$SQL_PLAN where SQL_ID='g7b1uz8n2mdvf'
and "TIMESTAMP"=TIMESTAMP '2015-08-20 19:38:06.000'
order by CHILD_NUMBER, id
-- 上面语句的结果可读性差,试一试下面的语句吧
select '| Operation |Object Name | Rows | Bytes| Cost |'
as "Explain Plan in library cache:" from dual
union all
select rpad('| '||substr(lpad(' ',1*(depth-1))||operation||
decode(options, null,'',' '||options), 1, 35), 36, ' ')||'|'||
rpad(decode(id, 0, '----------------------------',
substr(decode(substr(object_name, 1, 7), 'SYS_LE_', null, object_name)
||' ',1, 30)), 31, ' ')||'|'|| lpad(decode(cardinality,null,' ',
decode(sign(cardinality-1000), -1, cardinality||' ',
decode(sign(cardinality-1000000), -1, trunc(cardinality/1000)||'K',
decode(sign(cardinality-1000000000), -1, trunc(cardinality/1000000)||'M',
trunc(cardinality/1000000000)||'G')))), 7, ' ') || '|' ||
lpad(decode(bytes,null,' ',
decode(sign(bytes-1024), -1, bytes||' ',
decode(sign(bytes-1048576), -1, trunc(bytes/1024)||'K',
decode(sign(bytes-1073741824), -1, trunc(bytes/1048576)||'M',
trunc(bytes/1073741824)||'G')))), 6, ' ') || '|' ||
lpad(decode(cost,null,' ', decode(sign(cost-10000000), -1, cost||' ',
decode(sign(cost-1000000000), -1, trunc(cost/1000000)||'M',
trunc(cost/1000000000)||'G'))), 8, ' ') || '|' as "Explain plan"
from v$sql_plan sp
where sp.SQL_ID='g7b1uz8n2mdvf'
and "TIMESTAMP"=TIMESTAMP '2015-08-20 19:38:06.000';
2.4.Oracle 查看收集统计信息
统计信息相当于情报,对 Oracle 至关重要,如果统计信息不准确,Oracle 就会做出错误的判断。那如何查看统计信息呢?试一试下面的 SQL 吧。
-- 查看表统计信息
select * from DBA_TABLES where OWNER = 'HR' and TABLE_NAME = 'TEST';
select * from DBA_TAB_STATISTICS where OWNER = 'HR' and TABLE_NAME = 'TEST';
-- 查看列统计信息
select * from DBA_TAB_COL_STATISTICS where OWNER = 'HR' and TABLE_NAME = 'TEST';
-- 查看索引统计信息
select * from DBA_IND_STATISTICS where OWNER = 'HR' and TABLE_NAME = 'TEST';
通常,Oracle 会在每天固定时间段自动维护统计信息。但是对于某些表,这是远远不够的,如:某些表每天都需要清空,然后重新导入。这个时候,我们需要手动收集统计信息。
-- 方法1: 使用 DBMS_STATS.GATHER_TABLE_STATS 手动收集存储过程
DBMS_STATS.GATHER_TABLE_STATS('HR', 'ORDERS');
-- 方法2:删除并锁定统计信息,如果没有统计信息,Oracle 会动态收集统计信息
BEGIN
DBMS_STATS.DELETE_TABLE_STATS('HR','ORDERS');
DBMS_STATS.LOCK_TABLE_STATS('HR','ORDERS');
END;
Oracle 推荐我们使用方法1。 除此之外,DBMS_STATS 包还提供了下面的存储过程用来收集统计信息。
GATHER_INDEX_STATS 收集索引统计信息
GATHER_TABLE_STATS 收集指定表,列,索引的统计信息
GATHER_SCHEMA_STATS 收集指定模式下所有对象的统计信息
GATHER_SYSTEM_STATS 收集系统统(I/O,CUP)计信息
GATHER_DICTIONARY_STATS 收集 SYS, SYSTEM 模式下对象的统计信息
GATHER_DATABASE_STATS 收集所有数据库对象的统计信息
GATHER_FIXED_OBJECTS_STATS 收集 FIXED 对象的统计信息
DBMS_STATS 包还提供许多子程序让我们可以对统计信息进行操作,如:查询,删除,锁定,恢复等,更多详情你可以参考 PL/SQL Packages and Types 手册。
2.5.Oracle 查询优化器 – 改写查询语句
当我们执行一条查询语句的时候,我们只告诉 Oracle 我们想要哪些数据,至于数据在哪里,怎么找,那是查询优化器的事情,优化器需要改写查询语句,决定访问路径(如:全表扫描,快速全索引扫描,索引扫描),决定表联接顺序等。至于选择哪种方式,优化器需要根据数据字典做出判断。
那优化器如何改写查询语句呢?
第一种方法叫合并视图,如果你的查询语句中引用了视图,那么优化器会把视图合并到查询中,下面是一个简单的例子,需要注意的是优化器也不是神,如果你的视图包含集合操作符,聚合函数,Group by 等,优化器也傻了,不知道如何合并了。
-- 视图定义
CREATE VIEW employees_50_vw AS
SELECT employee_id, last_name, job_id, salary, commission_pct, department_id
FROM employees
WHERE department_id = 50;
-- 查询语句
SELECT employee_id
FROM employees_50_vw
WHERE employee_id > 150;
-- 合并视图后的查询语句
SELECT employee_id
FROM employees
WHERE department_id = 50
AND employee_id > 150;
第二种方法叫谓词推进(Predicate Pushing),对于那些无法执行合并视图的查询语句,Oracle 会把查询语句中的条件挪到视图中,下面是一个简单的例子。
-- 视图定义
CREATE VIEW all_employees_vw AS
(SELECT employee_id, last_name, job_id, commission_pct, department_id FROM employees)
UNION
(SELECT employee_id, last_name, job_id, commission_pct, department_id FROM contract_workers);
-- 查询语句的查询语句
SELECT last_name
FROM all_employees_vw
WHERE department_id = 50;
-- 谓词推进
SELECT last_name
FROM (
SELECT employee_id, last_name, job_id, commission_pct, department_id FROM employees
WHERE department_id=50 -- 注意此处
UNION
SELECT employee_id, last_name, job_id, commission_pct, department_id FROM contract_workers
WHERE department_id=50 -- 注意此处
);
第三种方法是将非嵌套子查询转化为表连接。下面是一个简单的例子。需要注意的是,并不是所有的非嵌套子查询都能转化为表连接,对于下面的例子而言,如果 customers.cust_id 不是主键,转化后会产生笛卡尔集。
-- 非嵌套子查询
SELECT *
FROM sales
WHERE cust_id IN (SELECT cust_id FROM customers);
-- 表连接
SELECT sales.*
FROM sales, customers
WHERE sales.cust_id = customers.cust_id;
第四种方法是使用物化视图改写查询,物化视图是将一个查询的结果集保存在一个表中,如果你的查询语句和某个物化视图兼容,那么 Oracle 就可以直接从物化视图中取得数据。
2.6.Oracle 查询优化器 – 访问路径
全表扫描(full table scans)
不要以为全表扫描就一定慢, 全表扫描时, 由于数据块在磁盘中是连续的,Oracle 可以一次读取多个块来提高查询效率,至于多少个块,是由 DB_FILE_MULTIBLOCK_READ_COUNT 决定的。所以,如果你需要返回一个表的大部分数据,全表扫描要比索引扫描快。除此之外,Oracle 会自动对小表进行全表扫描,那什么是小表呢?就是语句块小于 DB_FILE_MULTIBLOCK_READ_COUNT 定义的值。
如果你想让 Oracle 使用全表扫描,你也可以通过下面的方式指示 Oracle 使用全表扫描。
select /* FULL(t)*/ * from test t where col = 'test';
索引扫描(index scans)
你有没有想过,我们通过索引扫描时,如何通过索引定位到表中的位置呢?答案是通过 Rowid, Rowid 是 Oracle 内部使用的,用来标示行存储地址,所以通过 Rowid 定位行记录是最快的。有一点特别需要注意,Oracle 读写磁盘的最小单位是块,一个块可能包含多行,所以全表扫描还是索引扫描取决于访问块的百分比,而不是行的百分比。假设我们现在需要访问 3 行,这 3 行可能在一个块中,也可能在两个块中,还可能在三个块中,很明显,最理想的情况是在一个块中,Oracle 使用索引聚簇因子(index clustering factor)来衡量这种特性。索引聚簇因子越高,表明 Oracle 通过 Rowid 访问行的代价就越高。此外,Oracle 会根据索引类型的不同,是否排序,采用不同的索引扫描方式。
唯一索引扫描(Index Unique Scans)
如果你的查询条件有等价操作符(=),且恰好能用到唯一索引,那么 Oracle 会采用唯一索引扫描,当然你也可以通过下面的方式建议 Oracle 采用哪个索引。
select /* INDEX(t test_id_pk)*/ * from test t where col = 'test';
索引范围扫描(Index Range Scans)
如果你的查询条件有范围操作符(>,>=,<,<=,like ‘abc%’),且恰好能用到索引,那么 Oracle 会采用索引范围扫描,当然你也可以通过下面的方式建议 Oracle 采用哪个索引。
select /* INDEX(t test_id_pk)*/ * from test t where col = 'test';
索引降序范围扫描(Index Range Scans Descending)
如果你的查询条件有范围操作符且要求用索引列排序,那么 Oracle 会采用索引降序范围扫描,这样做的好处是 Oracle 可以省略排序这个非常耗时的步骤。当然你也可以通过下面的方式建议 Oracle 采用索引降序范围扫描。
如果你的索引是升序的。
select /* INDEX_DESC(t test_id_pk)*/ * from test t where col = 'test';
如果你的索引是降序的。
select /* INDEX_ASC(t test_id_pk)*/ * from test t where col = 'test';
索引跳跃扫描(Index Skip Scans)
如果你的索引是复合索引,也就是索引包含多个列,如下所示。
CREATE INDEX cust_idx ON customers (gender, email);
全索引扫描(Full Scans)
如果你的查询需要排序或分组,且排序或分组用到的列恰好是索引列,那么 Oracle 会采用全索引扫描,由于索引列是有序的,这样 Oracle 可以省略排序这个非常耗时的步骤。
快速全索引扫描(Fast Full Index Scans)
如果你要查询的所有列都包含在索引中,Oracle 就不需要访问表了,这样 Oracle 就可能通过并行和一次读取多个块来提高查询索引的效率。你也可以通过下面的方式建议 Oracle 采用快速全索引扫描。
select /* INDEX_FFS(t test_id_pk)*/ * from test t where col = 'test';
索引连接扫描(Index Joins)
如果你的表有多个索引,恰好你要查询的所有列包含在这些索引中,Oracle 就不需要访问表了,Oracle 只需要把这些索引连接起来。你也可以通过下面的方式建议 Oracle 采用索引连接。
select /* INDEX_JOIN(t test_id_idx test_name_idx)*/ * from test t where col = 'test';
位图索引扫描(Bitmap Indexes)
索引聚簇扫描(Indexed Cluster Access)
如果你的表包含在了某个索引聚簇中,Oracle 会使用索引聚簇来执行查询。
select /* INDEX_COMBINE(t test_idx1 test_idx2)*/ * from test t where col = 'test';
Hash 聚簇扫描(Hash Cluster Access)
如果你的表包含在了某个Hash 聚簇中,Oracle 会使用 Hash 聚簇来执行查询。
采样扫描(Sample Table Scans)
如果你的查询语句包含 SAMPLE 子句,那么 Oracle 会使用 采样扫描。
2.7.Oracle 查询优化器 – 表连接方法
循环嵌套连接,小表驱动大表,避免笛卡尔积的出现。
循环嵌套连接(Nested Loop Joins)。
SELECT e.first_name, e.last_name, e.salary, d.department_name
FROM hr.employees e, hr.departments d
WHERE d.department_name IN ('Marketing', 'Sales')
AND e.department_id = d.department_id;
对于循环嵌套,你可以把表想象成数组,Oracle 会采用如下的方式执行查询。
String[] departments = {};
String[] employees = {};
// 外层循环
for(String dep: departments) {
// 内层循环
for(String emp: employees) {
}
}
很明显,如果 employees 很大且没有索引,外层循环每执行一次都需要全表扫描 employees,这是不可接受的。所以循环嵌套表连接方式适合那些内层循环数据量少且有索引的情形。
当然,你也可以通过下面的方式建议 Oracle 采用循环嵌套连接方式。
-- USE_NL
SELECT /*+ USE_NL(e d) */ e.first_name, e.last_name, e.salary, d.department_name
FROM hr.employees e, hr.departments d
WHERE d.department_name IN ('Marketing', 'Sales')
AND e.department_id = d.department_id;
--USE_NL_WITH_INDEX,指定 e 为内层循环表
SELECT /*+ USE_NL_WITH_INDEX(e) */ e.first_name, e.last_name, e.salary, d.department_name
FROM hr.employees e, hr.departments d
WHERE d.department_name IN ('Marketing', 'Sales')
AND e.department_id = d.department_id;
--USE_NL_WITH_INDEX,指定 e 为内层循环表,同时指定索引
SELECT /*+ USE_NL_WITH_INDEX(e emp_dep_id_idx) */ e.first_name, e.last_name, e.salary, d.department_name
FROM hr.employees e, hr.departments d
WHERE d.department_name IN ('Marketing', 'Sales')
AND e.department_id = d.department_id;
你还可以通过下面的方式建议 Oracle 不要采用循环嵌套连接方式。
SELECT /*+ NO_USE_NL(e d) */ e.first_name, e.last_name, e.salary, d.department_name
FROM hr.employees e, hr.departments d
WHERE d.department_name IN ('Marketing', 'Sales')
AND e.department_id = d.department_id;
2.8.Oracle 索引
要正确使用索引,避免索引失效,创建适当的索引。
不可否认,提高性能最直接有效的方式就是创建索引,正因为如此,好多人把它当做救命的良药,随意创建索引,殊不知维护索引的代价是非常大的。Oracle 官方给了一个大约的数字,维护一个索引所需要的代价大约是操作本身的 3 倍。另外,索引也有好多种类型,不同的索引适应的场景也不同。
1.索引组织表(Index-Organized Tables)
创建索引时,如何选择索引列呢?其实就是查询用到的列,包括 SELECT,WHERE,JOIN, ORDER 等用到的列,但是列的顺序是有讲究的,应该把那些重复值最少的列放在最前面。如果你创建一个索引包含一个表的所有列,那么你应该将该表创建为索引组织表(IOT),如果一个表的列比较少,这么做是可以的。对于列多的表,千万别这么干。因为索引组织表的记录存储在索引的叶子节点上,当我们向表中插入数据时,Oracle 为了维护索引需要移动数据,这会大大降低插入速度。下面是一个简单的例子。
CREATE TABLE test
(
id NUMBER(10),
name VARCHAR2(30),
CONSTRAINT pk_test PRIMARY KEY (id)
) ORGANIZATION INDEX;
2.B 树索引(B-Tree Indexes)
B 树索引是默认的索引类型,特别适合主键,或重复值比较少的列或列的组合,如何判断重复值得多少呢?看看下面的公式吧,下面的值越高越好,主键是 1.0
SELECT COUNT(DISTINCT COLUMN) / COUNT(*) FROM TEST;
下面是一个简单的例子。
--普通索引
CREATE INDEX test_idx_name ON test (name);
--唯一索引
CREATE UNIQUE INDEX test_idx_id ON test (id);
3.位图索引(Bitmap Indexes)
位图索引和 B 树索引正好相反,非常适合重复值比较多的列,最好是只有几项,如:国籍,性别,省份等等,而且这些值基本上不会频繁更新。注意,频繁更新的列不适合位图索引,如,订单表有个列表示是否被处理,只有两个值,YES, NO。下面是一个简单的例子。
--位图索引
CREATE BITMAP INDEX test_idx_country ON test (country);
CREATE BITMAP INDEX test_idx_gender ON test (gender);
CREATE BITMAP INDEX test_idx_province ON test (province);
4.基于函数的索引(Function-based Indexes)
在索引字段上使用函数会使索引失效,有时候,我们可以通过把它转化为范围扫描来避免这个问题,但是,有时候,我们必须要使用函数,如:忽略大小写查询,这个时候,我们可以在创建基于函数的索引,如下是一个简单的例子。
CREATE INDEX test_idx ON test(UPPER(NAME));
5.分区索引(Partitioned Indexes)
分区索引的思想是将大的索引分成多个小索引,这样索引扫描时就可以减少IO。对于普通表,我们可以创建下面两种类型的分区索引。
-- 范围全局分区索引
CREATE INDEX test_idx ON test (amount)
GLOBAL PARTITION BY RANGE (amount)
(
PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (2500),
PARTITION p3 VALUES LESS THAN (MAXVALUE)
);
-- 哈希(散列)全局分区索引
CREATE INDEX cust_last_name_ix ON customers (cust_last_name)
GLOBAL PARTITION BY HASH (cust_last_name)
PARTITIONS 4;
对于分区表,除了可以创建上面两种类型的分区索引外,我们还可以给某个表分区或所有分区创建分区索引。
-- 创建分区表
CREATE TABLE test
(
id number,
year number,
month number
)
PARTITION BY RANGE (year)
(
PARTITION p1 VALUES LESS THAN (2013),
PARTITION p2 VALUES LESS THAN (2014),
PARTITION p3 VALUES LESS THAN (2015),
PARTITION p4 VALUES LESS THAN (3000)
);
-- 给所有表分区创建分区索引
CREATE INDEX test_idx ON test (year, month) LOCAL;
-- 给 p1分区创建分区索引
CREATE INDEX test_idx ON test (year, month) LOCAL (PARTITION p1);
6.反向索引(Reverse Key Indexes)
反向索引就是将正常的键值头尾调换后再进行存储,比如原值是’abc’,将会以’cba’形式进行存储,为什么要这样做呢?原因是有些值是根据一定的规则生成的,如时间,序列等,当我们插入大量数据时,它们都需要同时插入到索引的某个区域,Oracle 称之为热点区域(hot spot),如果我们使用反向存储,可以有效的避免这个问题,但是有利就有弊,我们不能使用反向索引进行范围扫描,所以使用它要慎重。这里给我们一个非常重要的启示,在设计自动生成的值时,如果有可能,每两次生成的值范围要广。
7.复合索引
复合索引就是有多个列的索引,索引列的顺序很关键,如果索引包含 A,B,C 三列,而你的查询条件只包含 B,C 两列,Oracle 就无法使用索引。
重建索引
如果让你重建索引该怎么办呢?大多数人都会先删除索引,然后再创建新索引,其实通过下面的方式重建索引更快,因为 Oracle 可以利用现有的索引重建索引。
ALTER INDEX ... REBUILD
有关索引的视图
如果让你查询一下某个表都定义了哪些索引该怎么办呢?呵呵,很简单,只需查询一下下面的视图即可。
all_indexes
all_ind_columns
all_ind_expressions
all_ind_partitions
all_ind_subpartitions
all_ind_statistics
那如果让你查询一下某个索引是否被用到,该怎么办呢?首先,你需要让 Oracle 帮你监控一下索引,等过一段时间后,你可以查询下面的视图查看索引是否被用到。
-- 让 Oracle 监控索引
ALTER INDEX <indx name> MONITORING USAGE;
-- 查询是否被用到
select * from v$object_usage
2.9.Oracle 视图
视图有好多优点,如它可以简化开发。但是有一点特别需要注意,最好不要使用多个视图做联合查询,因为优化器将很难优化这样的查询。
2.10.Oracle 减少数据库访问次数
连接数据库是非常耗时的,虽然应用程序会采用连接池技术,但与数据库交互依然很耗时,这就要求我们尽量用一条语句干完所有的事,尤其要避免把 SQL 语句写在循环中,如果你遇到这样的人,应该毫不犹豫给他两个耳光
2.11 Oracle 面向对象
我们都知道,传统数据库都是关系型数据库,随着 Java 和 面向对象的流行,Oracle也与时俱进,加入了面向对象的特性,最典型的就是嵌套表,嵌套表使查询变得复杂,同时它的性能也不如传统表好。
2.12 Oracle 分开执行耗时操作
首先,我们看一个故事,联合利华引进了一条香皂包装生产线,结果发现这条生产线有个缺陷:常常会有盒子里没装入香皂。总不能把空盒子卖给顾客啊,他们只得请了一个学自动化的博士后设计一个方案来分拣空的香皂盒。博士后拉起了一个十几人的科研攻关小组,综合采用了机械、微电子、自动化、X射线探测等技术,花了几十万,成功解决了问题。每当生产线上有空香皂盒通过,两旁的探测器会检测到,并且驱动一只机械手把空皂盒推走。
中国南方有个乡镇企业也买了同样的生产线,老板发现这个问题后大为发火,找了个小工来说:你他妈给老子把这个搞定,不然你给老子爬出去。小工很快想出了办法:他在生产线旁边放了台风扇猛吹,空皂盒自然会被吹走。
还有一个故事,美国宇航局发现圆珠笔在失重环境下无法使用, 结果花了2千万美刀研制出了失重环境下可用的圆珠笔, 而苏联人一直用铅笔。
这两个故事给我们一个很重要的启示,性能问题都是由于资源竞争导致的,所以,一个简单的想法就是尽量分开执行耗时的操作。这看似一个最简单不过的道理,但是随着软件变得越来越大,到最后可能没有人知道什么时候执行什么操作时合适的。
2.13 Oracle 子程序内联
如果子程序 A 调用 B,内联可以把 B 的代码合并到 A 中,从而减少子程序调用,提高性能,下面是一个简单的例子。
-- 子程序 A
PROCEDURE A
IS
BEGIN
-- 指定下面的子程序 B 内联
PRAGMA INLINE (B, 'YES')
B(1);
-- 注意此处的子程序不会内联
B(2);
END A;
-- 子程序 B
PROCEDURE B (x PLS_INTEGER)
IS
BEGIN
DBMS_OUTPUT.PUT_LINE(x);
END B;
如果你觉得在每一个子程序调用前加上 PRAGMA INLINE 在麻烦,你可以将编译参数 PLSQL_OPTIMIZE_LEVEL 设置为 3 (默认值是2),这样 Oracle 会把每一个子程序调用都内联。
2.14 Oracle 动态 SQL
如果你还不知道什么是动态 SQL,请参考 PL/SQL 动态 SQL
如果有可能,尽量不要使用动态 SQL,动态 SQL需要运行时编译,影响性能。如果一定要使用动态 SQL,Oracle 推荐我们优先使用 EXECUTE IMMEDIATE,它要比 DBMS_SQL 性能更好。
2.15 Oracle 避免在查询中使用函数
一个查询可能要搜索上百万行数据,在查询中使用函数就可能被调用上百万次,这会严重影响性能,下面是一个简单的例子。
-- 创建表
CREATE TABLE Department
(
Department_Id NUMBER(9,0),
Department_Name VARCHAR2(40)
);
CREATE TABLE Employee
(
Employee_id NUMBER(9,0),
Employee_Name VARCHAR2(40),
Department_Id NUMBER(9,0)
);
-- 定义函数
CREATE OR REPLACE FUNCTION getDepartmentNameById(
DepartmentId number
)
RETURN varchar2
AS
DepartmentName VARCHAR2(40);
BEGIN
select Department_Name into DepartmentName from Department where Department_Id = DepartmentId;
return DepartmentName;
END;
-- 查询 SQL -- 使用函数
SELECT getDepartmentNameById(Department_Id) DepartmentName, Employee_Name FROM Employee;
-- 查询 SQL -- 使用表连接
SELECT
d.Department_Name,
e.Employee_Name
FROM
Department d,
Employee e
WHERE
d.Department_Id = e.Department_Id;
2.16 Oracle 指定子程序 OUT 或 IN OUT 参数为引用传递
通常,子程序的 OUT 或 IN OUT 参数为值传递,为了防止程序可能发生的异常,Oracle 将它保存到临时变量中,当程序正常退出时,Oracle 把临时变量中值赋给实际参数,异常退出时,保持实际参数不变。当OUT 或 IN OUT 参数返回大批量数据时,由于使用了临时变量导致占用大量内存,这时我们可以在参数的后面加上 NOCOPY 来提示Oracle使用引用传递.
PROCEDURE test (infor IN OUT NOCOPY Collection) IS
BEGIN
NULL;
END;
2.17 Oracle 尽量少用循环语句
下面是一个使用循环语句删除表记录的例子。
DECLARE
TYPE NumList IS TABLE OF NUMBER;
emps NumList := NumList(10, 30, 70);
BEGIN
FOR i IN emps.FIRST..emps.LAST LOOP
DELETE FROM employees WHERE employee_id = emps(i);
END LOOP;
END;
在你的工作中,千万别写出上面的语句,否则应该毫不犹豫的给自己两个耳光,应该使用批处理的方式,如下:
DECLARE
TYPE NumList IS TABLE OF NUMBER;
emps NumList := NumList(10, 30, 70);
BEGIN
-- FORALL 语句批量执行下面的语句
FORALL i IN emps.FIRST..emps.LAST
DELETE FROM employees WHERE employee_id = emps(i);
END;
或使用 TABLE 表达式,如下:
CREATE OR REPLACE TYPE number_table AS TABLE OF NUMBER;
DECLARE
emps number_table := number_table(10, 30, 70);
BEGIN
DELETE FROM employees WHERE employee_id IN (SELECT COLUMN_VALUE FROM TABLE(emps));
END;
2.18 Oracle 数据类型使用注意事项
Oracle 支持 NUMBER,BINARY_FLOAT, BINARY_DOUBLE 等数值数据类型,NUMBER 更精确,BINARY_FLOAT 或 BINARY_DOUBLE 更高效,所以如果有可能,尽量优先使用 BINARY_FLOAT 或 BINARY_DOUBLE
此外,PL/SQL 还支持好多它们的子类型,有些子类型是由约束的,如不允许 NULL,尽量不要使用约束多的子类型,因为在运行时, Oracle 需要额外的检查,确保它们没有违反约束。
在运行时,Oracle 会自动进行数据类型转换,如下面的语句把一个字符串赋值给一个数值类型的变量,Oracle 是不会抱错的.
declare
x PLS_INTEGER;
begin
x := '1';
end;
应该尽量避免这种情况,如果一个变量是从一个表中获取的,我们应该定义这个变量的类型为 TABLE_NAME.COLUMN_NAME%TYPE
2.19 Oracle 字符串处理
如果你需要处理复杂字符串,尽量不要自己编写函数,Oracle 提供了大量的字符串函数供我们使用。点击此处察看 Oracle 支持哪些函数。
如果还是不能满足你的要求,我们还可以使用正则表达式。可以说正则表达式几乎没有处理不了的字符串问题。如果你还不知道什么是正则表达式,点击此处(正则表达式精萃),如果你不知道如何在 Oracle 中使用正则表达式, 点击此处察看如何使用正则表达式。
2.20 Oracle 短路评估
Oracle 按照从左到右的顺序评估条件表达式,一旦确定结果就停止后面的评估,所以我们应该尽量将轻量级的条件放在最左边。
IF (x > 10) OR function(parameter) THEN
2.21 Oracle 并发更新大表
如果你有一个很大的表要更新,千万别想着一次搞定,如果你这么干了,你会发现需要很长时间,最后的结果也不一定成功,为什么呢? 第一,Oracle 需要锁定整个表,这个过程中极有可能发生死锁。第二,Oracle 需要更多的日志文件用于回滚。第三,一旦发生点小问题会导致一个老鼠害一锅汤。那该怎么办呢?答案是分段执行,少量多次并发执行,下面是一个简单的例子。
DECLARE
l_sql_stmt VARCHAR2(1000);
BEGIN
-- 第一步: 创建任务
DBMS_PARALLEL_EXECUTE.CREATE_TASK ('task_test');
-- 第二步: 根据 ROWID 切块, 每次 100 行
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID('task_test', 'TRADE', 'EMPLOYEES', true, 100);
-- 第三步: 并发执行下面的 SQL
l_sql_stmt := 'update /*+ ROWID (dda) */ EMPLOYEES e SET e.salary = e.salary + 10 WHERE rowid BETWEEN :start_id AND :end_id';
DBMS_PARALLEL_EXECUTE.RUN_TASK('task_test', l_sql_stmt, DBMS_SQL.NATIVE, parallel_level => 10);
-- 第四步: 删除任务
DBMS_PARALLEL_EXECUTE.DROP_TASK('task_test');
END;
另外多提一句,关于性能优化涉及面非常广,不仅仅是数据库SQL上的优化,设计架构高性能架构的类似秒杀系统需要多方面考虑,从前端静态页面,DNS加速,带宽,服务器性能,中间件性能,数据库性能,SQL只是其中一环。最后,感谢shangboerds老师,转载于shangboerds文章后验证补充。
SQL优化规范
sql优化规范
Oracle SQL 优化精萃
MySQL执行计划Explain详解
MySQL数据库索引及失效场景

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 18
18 1
1- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)