OLAP与OLTP的区别?
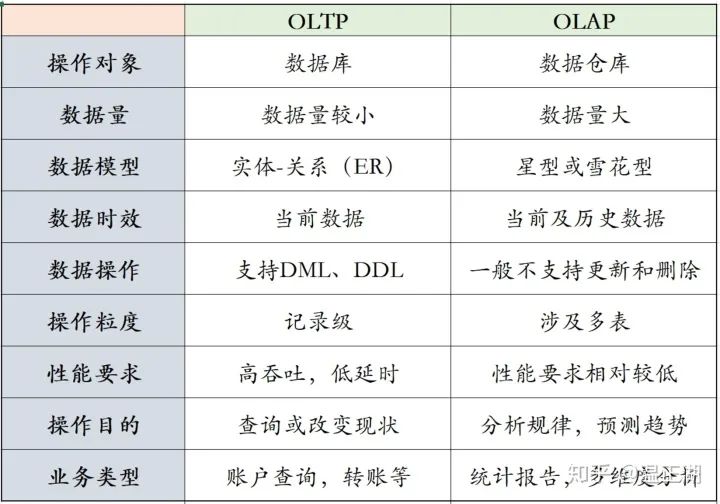
1. OLAP与OLTP的区别?OLTP(Online transaction processing):在线/联机事务处理。典型的OLTP类操作都比较简单,主要是对数据库中的数据进行增删改查,操作主体一般是产品的用户。OLAP(Online analytical processing):指联机分析处理。通过分析数据库中的数据来得出一些结论性的东西。比如给老总们看的报表,用于进行市场开拓的用户行为统
1. OLAP与OLTP的区别?
OLTP(Online transaction processing):在线/联机事务处理。典型的OLTP类操作都比较简单,主要是对数据库中的数据进行增删改查,操作主体一般是产品的用户。
OLAP(Online analytical processing):指联机分析处理。通过分析数据库中的数据来得出一些结论性的东西。比如给老总们看的报表,用于进行市场开拓的用户行为统计,不同维度的汇总分析结果等等。操作主体一般是运营、销售和市场等团队人员。
单次OLTP处理的数据量比较小,所涉及的表非常有限,一般仅一两张表。而OLAP是为了从大量的数据中找出某种规律性的东西,经常用到count()、sum()和avg()等聚合方法,用于了解现状并为将来的计划/决策提供数据支撑,所以对多张表的数据进行连接汇总非常普遍。
为了表示跟OLTP的数据库(database)在数据量和复杂度上的不同,一般称OLAP的操作对象为数据仓库(data warehouse),简称数仓。数据库仓库中的数据,往往来源于多个数据库,以及相应的业务日志。
2. MySQL等OLTP数据库能处理OLAP业务吗?
MySQL一般作为OLTP数据库使用,也能执行一些OLAP操作,但这不是MySQL擅长的领域。虽然OLTP和OLAP都是通过SQL来执行,但SQL语句只是描述了我想要什么,而并没有说明应该怎么做(不考虑hint等),即确定最优的执行计划。由于OLTP操作比较简单,所涉及的表也少,因此不需要相应的数据库具有强大的执行优化能力,比如说MySQL在查询优化这块就比较弱,但这其实没有给它的大规模普及使用造成多大伤害。
当然,MySQL也在快速进步,尤其是最新的8.0版本,在查询优化模块添加了很多众望所归的功能特性,包括窗口函数,通用表达式和更强大的Join能力等。
而OLAP类操作不一样,没有强大的执行计划产生和优化能力,执行这类操作肯定不会有多高的效率,甚至会寸步难行。当然,如果总数据量较小,SQL也相对简单,那MySQL也是能够应付的。在MySQL高可用实例的从库做些报表类查询也有不少案例。
3. OLAP的查询跟OLTP查询具体有那些不一样?
OLTP查询一般仅涉及单表,点查为主,返回的是记录本身或该记录的多个列。即使是范围查询,基本上也会通过limit来限制返回的记录数。
而OLAP则不同,表中单条记录本身并不是查询所关心的,比较典型的特点包括有聚合类算子、涉及多表Join。这些操作都非常耗计算资源,而且数据仓库相比数据库在数据量上大很多,因此,OLAP类查询经常表现为cpu-bound而不是io-bound。
OLTP和OLAP发展到现在已经比较成熟,业界也有些公认的benchmark来进行性能评估。对于OLTP来说,有sysbench和tpcc测试套件,对于OLAP来说,有tpch和tpcds 2种。
4. 是否有可能将OLAP和OLTP统一起来?
目前有个趋势是将OLTP和OLAP相融合,在同一个系统中同时提供TP和AP 2种服务,即HTAP产品,国内的数据库创业公司PingCAP的TiDB即是其中的佼佼者。
但由于两者服务类型相差甚大,完全融合是很难的,如何解决AP业务对要求更高实时性和稳定性的TP业务带来影响,如何同时提供2种服务且2种服务与业界其他系统相比具备足够竞争力,这些都是很大的挑战。
在目前的HTAP系统中,一般通过存储层的数据多副本来进行针对AP和TP业务的不同方式的优化,使用多个副本来以行存方式更好满足TP业务,通过增加一个副本来以列存方式为AP业务提供服务。
在存储系统上,配置独立的计算/查询系统,分别满足TP和AP不同的要求。比如TP系统很重要的一个特点就是事务的ACID,而AP系统更加关心分布式并行查询能力。
5. 数仓有哪些基础知识和概念?
OLAP的查询语句比OLTP更复杂,显然是因为两则操作的数据集和目的都是不一样的。数据库模型是2维的关系-实体模型。而数仓则是多维立方体模型。
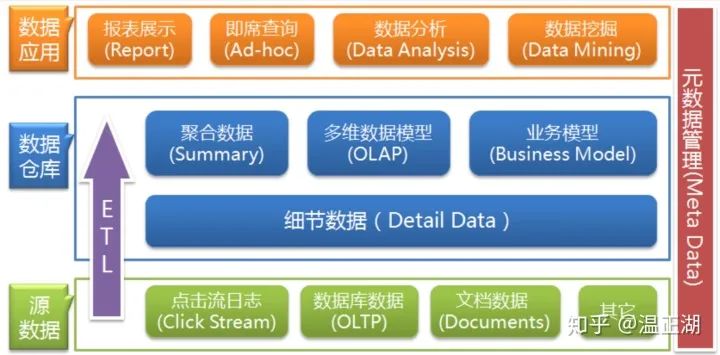
02 说说数仓中数据的前世今生?
1. 数仓中的数据从何而来?
OLAP对应的数据载体叫做数据仓库,因为它不是数据的生产者,其中的数据都是从其他地方搬运过来的,而搬运和清洗的过程就是ETL流程(Extract-Transform-Load,即数据抽取、转换和加载)。
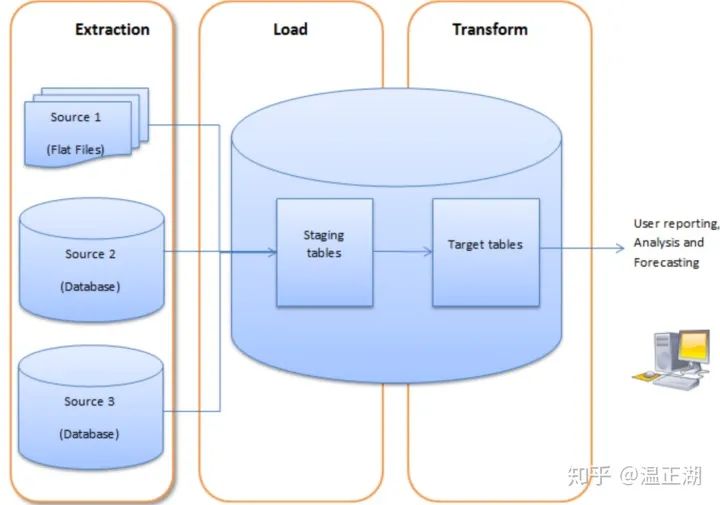
这些数据归纳起来大体有3种:
-
结构化数据:一般来自于数据库,比如MySQL等关系型数据库的表中保存的记录(rows)。即承担OLTP功能的数据载体。这类数据最好处理,因为数据表达方式作为规范,约束性最好;
-
半结构化数据:该部分数据来源较多,包括用户行为日志(如app的页面访问记录)、平台或管理服务日志(tomcat、mysql等服务日志)等等,也包括存储于MongoDB等NoSQL数据库中的记录(Docs等)。这些数据一般以Json或XML等形式存在,在ETL时难度较大。
-
非结构化数据:包括图片、音频、视频和网页等,这些数据非常复杂,信息量也很大,一般不会直接抽取出来直接保存到数仓中,而是记录他们的元数据信息(metadata),举图片为例,可能保存该图片的产生时间、格式、大小等等,至于图片本身,一般通过url链接保存在对象或文件存储系统中。
2. 数仓的作用有哪些?
-
进行交互式/即席查询(ad-hoc);
-
用于报表类查询(BI Reporting);
-
进行数据分析类查询(Data Analytics);
-
用于数据挖掘类查询(Data Mining);
3. 数据在数仓中是如何组织的?
数仓中数据的存在方式跟数仓索要发挥的作用息息相关,即该数仓要承载什么样的业务模型。
基于业务模型设计对应的数据仓库的数据模型,进而针对性实现不同的ETL操作将外部数据经过不同程度的过滤、聚合等处理之后引入到数仓之中。
4. 什么是多维数据模型?
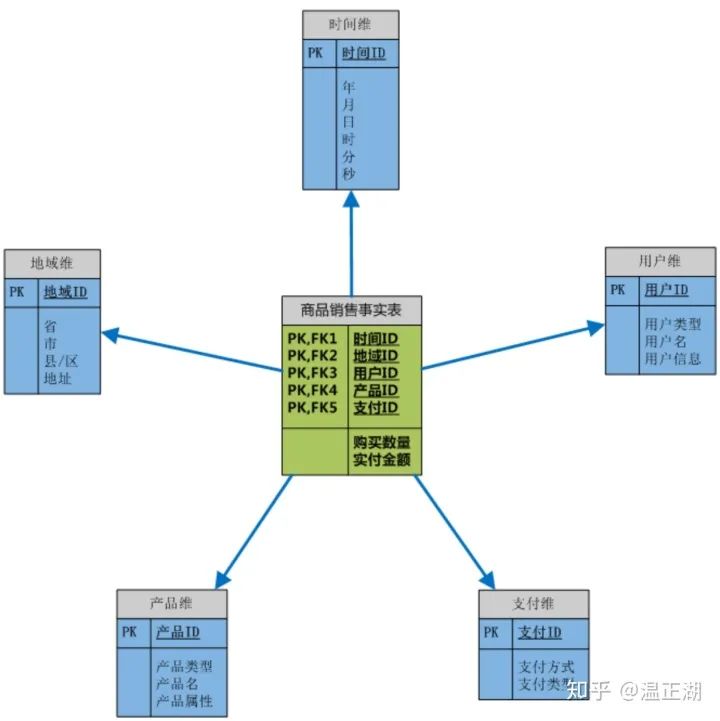
上图为一个采用简单星型模型组织起来的多维数据模型,用来存储商品销售情况。在这张图中的6个表又可分为2种类型,分别是最中间的事实表,和围绕其展开的维度表。
事实表(Fact Table)用来记录具体事件,包含了每个事件的具体要素,以及具体发生的事情。事实表是主干,简明扼要得介绍一个事实。例子中就通过一条事实表记录说明了某个地方(地域ID)的某人(用户ID)在某个时间(时间ID)通过某种方式(支付ID)买了某产品(产品ID)。
维度表(Dimension Table )是依赖事实表而存在的,每个维度表都是对事实表中的每个列/字段进行展开描述。
比如事实表中的用户ID,就可以进一步展开成一张维度表,记录该用户ID实体的用户名、联系信息、地址信息、年龄、性别和注册方式等等;
一般来说,对于数仓,事实表的增删改操作相比维度表更为频繁,模型建立后,维度表中的数据保持相对稳定。
通过事实表和维度表组织起来的数仓多维数据模型,相比原本分散在数据库等各处的数据,能够有更有目的更高效的查询效率,比如可以查询汇总地域维度中某个省的商品销售情况,也可以通过时间维度分析每个季度的某类商品销售趋势。将多个维度表跟事实表进行不同程度的连接,可以展开得到各种各样的分析结果,满足商品运营等数据使用者的不同需求。
7.数据立方体及其常见操作
数据立方体(Data Cube)在进行OLAP查询时,基于数据立方体的多维分析操作包括:
钻取(Drill-down):是往更细粒度深挖。从上一个层次到下一层,即深入该层内部。比如书籍中可以分计算机、数理化、文史地等。
上卷(Roll-up):与钻取往深度挖相反,即从细粒度数据向上层聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据。上面的钻取和上卷通过摊薄和加厚来改变维度的粒度。
而切片和切块相似,是对维度进行筛选,获取其中一部分相同的样本。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或浙江一个省粒度进行分析。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据。与切片不同的是,切块的粒度更大,会选择一个维度中某个区间或范围的值,而不仅仅是某个值。
旋转(Pivot):维的位置的互换,就像是二维表的行列转换。旋转并未减少或增加要分析的样本。而是根据不同的目的,改变了分析的角度。

为开发者提供学习成长、分享交流、生态实践、资源工具等服务,帮助开发者快速成长。
更多推荐



 72
72 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)